Интеграция потока запросов с DevOps для приложений на основе LLM
Машинное обучение Azure поток запроса — это удобный и удобный для разработчика метод разработки и итерации потоков для разработки и итерации потоков для разработки приложений на основе больших языковых моделей (LLM). Поток запросов предоставляет пакет SDK и CLI, расширение Visual Studio Code и пользовательский интерфейс разработки потока. Эти средства упрощают разработку локального потока, запуск локального потока и запуск оценки и переход потоков между локальными и облачными рабочими областями.
Вы можете объединить возможности потока запросов и кода с операциями разработчика (DevOps), чтобы улучшить рабочие процессы разработки приложений на основе LLM. В этой статье рассматривается интеграция потока запросов и DevOps для приложений на основе LLM Машинное обучение Azure.
На следующей схеме показано взаимодействие локальной и облачной разработки потока запросов с DevOps.

Необходимые компоненты
Рабочая область Машинного обучения Azure. Чтобы создать его, см. статью "Создание ресурсов для начала работы".
Локальная среда Python с установленным пакетом SDK для Python Машинное обучение Azure версии 2, созданной с помощью инструкций по началу работы.
Примечание.
Эта среда отличается от среды, в которой сеанс вычислений используется для запуска потока, который определяется как часть потока. Дополнительные сведения см. в разделе "Управление сеансом вычислений потока запросов" в Студия машинного обучения Azure.
Visual Studio Code с установленными расширениями потока Python и запроса.

Использование интерфейса кода в потоке запросов
Разработка приложений на основе LLM обычно следует стандартизованному процессу проектирования приложений, который включает репозитории исходного кода и конвейеры непрерывного развертывания (CI/CD). Этот процесс способствует упрощению разработки, управления версиями и совместной работы среди участников группы.
Интеграция DevOps с интерфейсом кода потока запросов предлагает разработчикам кода более эффективный процесс итерации GenAIOps или LLMOps со следующими ключевыми функциями и преимуществами:
Поток управления версиями в репозитории кода. Файлы потоков можно определить в формате YAML, и они остаются в соответствии с ссылочными исходными файлами в той же структуре папок.
Интеграция потокового выполнения с конвейерами CI/CD. Вы можете легко интегрировать поток запросов в конвейеры CI/CD и процесс доставки с помощью интерфейса командной строки или пакета SDK для автоматического запуска потока запросов.
Плавный переход между локальным и облачным. Вы можете легко экспортировать папку потока в локальный или вышестоящий репозиторий кода для управления версиями, локальной разработки и общего доступа. Вы также можете легко импортировать папку потока обратно в Машинное обучение Azure для дальнейшего создания, тестирования и развертывания с помощью облачных ресурсов.
Доступ к коду потока запроса
Каждый поток запроса содержит структуру папок потока, содержащую основные файлы кода, определяющие поток. Структура папок упорядочивает поток, упрощая более плавные переходы между локальными и облачными.
Машинное обучение Azure предоставляет общую файловую систему для всех пользователей рабочей области. При создании потока соответствующая папка потока автоматически создается и хранится в каталоге Users/username>/<promptflow.

Работа с файлами кода потока
После создания потока в Студия машинного обучения Azure вы можете просматривать, изменять и управлять файлами потока в разделе "Файлы" страницы разработки потока. Любые изменения, внесенные в файлы, отражаются непосредственно в хранилище общей папки.

Папка потока на основе LLM содержит следующие ключевые файлы.
flow.dag.yaml — это основной файл определения потока в формате YAML. Этот файл является неотъемлемой частью разработки и определения потока запроса. Файл содержит сведения о входных данных, выходных данных, узлах, инструментах и вариантах, которые использует поток.
Файлы исходного кода, управляемые пользователем, в формате Python (.py) или Jinja 2 (.jinja2) настраивают средства и узлы в потоке. Средство Python использует файлы Python для определения пользовательской логики Python. Средство запроса и средство LLM используют файлы Jinja 2 для определения контекста запроса.
Файлы, такие как служебные программы и файлы данных, могут быть включены в папку потока вместе с исходными файлами.
Чтобы просмотреть и изменить необработанный код потока.dag.yaml и исходных файлов в редакторе файлов, включите режим необработанного файла.

Кроме того, вы можете получить доступ ко всем папкам и файлам потока на странице "Записные книжки Студия машинного обучения Azure".

Скачивание и возврат кода потока запроса
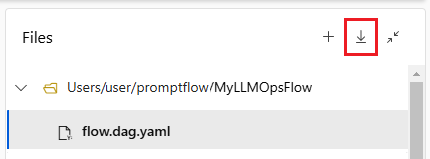
Чтобы проверить поток в репозитории кода, экспортируйте папку потока из Студия машинного обучения Azure на локальный компьютер. Щелкните значок скачивания в разделе "Файлы " страницы разработки потока, чтобы скачать ZIP-пакет, содержащий все файлы потока. Затем вы можете проверить этот файл в репозитории кода или распакуйте его для локальной работы с файлами.
Дополнительные сведения об интеграции DevOps с Машинное обучение Azure см. в статье об интеграции Git для Машинное обучение Azure.
Разработка и тестирование локально
При уточнении и настройке потока или запроса во время итеративной разработки можно выполнять несколько итераций локально в репозитории кода. Версия сообщества VS Code, расширение потока запроса VS Code и локальный пакет SDK для потоков запросов и CLI упрощают чистую локальную разработку и тестирование без привязки Azure.
Локальная работа позволяет быстро вносить и тестировать изменения без необходимости обновлять основной репозиторий кода каждый раз. Дополнительные сведения и рекомендации по использованию локальных версий см. в сообществе GitHub потока запроса.
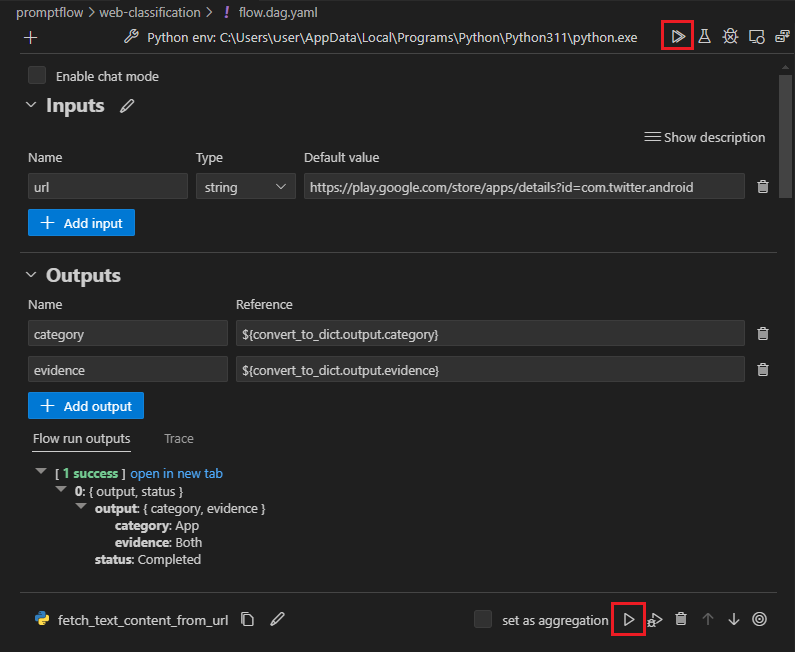
Использование расширения потока запроса VS Code
Используя расширение VS Code потока запросов, вы можете легко создать поток локально в редакторе VS Code с аналогичным интерфейсом пользовательского интерфейса, как в облаке.
Чтобы изменить файлы локально в VS Code с расширением потока запроса:
В VS Code с включенным расширением потока запроса откройте папку потока запроса.
Откройте файл flow.dag.yaml и выберите ссылку визуального редактора в верхней части файла.
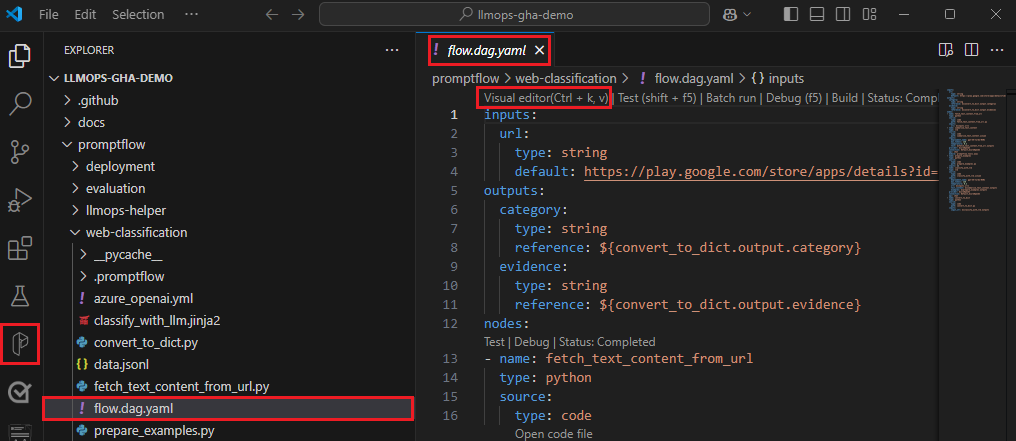
Используйте визуальный редактор потока запросов, чтобы внести изменения в поток, например настроить запросы в вариантах или добавить дополнительные узлы.
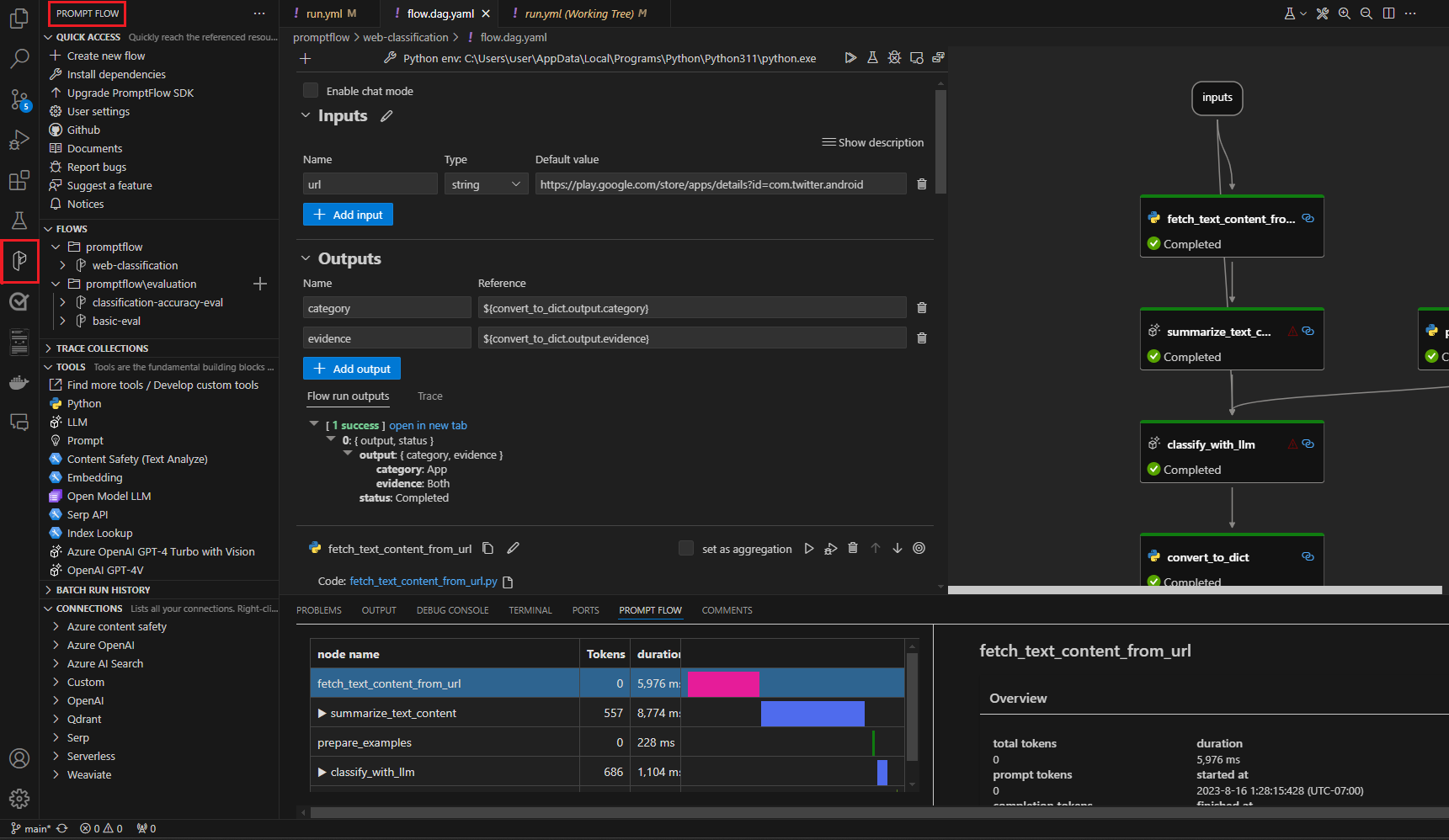
Чтобы протестировать поток, выберите значок запуска в верхней части визуального редактора или протестируйте любой узел, щелкните значок запуска в верхней части узла.



Использование пакета SDK для потока запроса и ИНТЕРФЕЙСА командной строки
Если вы предпочитаете работать непосредственно в коде или использовать Jupyter, PyCharm, Visual Studio или другую интегрированную среду разработки (IDE), вы можете напрямую изменить код YAML в файле flow.dag.yaml .

Затем можно активировать один поток для тестирования с помощью интерфейса командной строки запроса или пакета SDK в терминале, как показано ниже.
Чтобы активировать запуск из рабочего каталога, выполните следующий код:
pf flow test --flow <directory-name>
Возвращаемые значения — это журналы тестирования и выходные данные.

Отправка запусков в облако из локального репозитория
После удовлетворения результатов локального тестирования можно использовать интерфейс командной строки запроса или пакет SDK для отправки в облако из локального репозитория. Следующая процедура и код основаны на демонстрационном проекте веб-классификации в GitHub. Вы можете клонировать репозиторий проекта или скачать код потока запроса на локальный компьютер.
Установка пакета SDK потока запроса
Установите пакет SDK для потока запросов Azure или CLI, выполнив команду pip install promptflow[azure] promptflow-tools.
Если вы используете демонстрационный проект, получите пакет SDK и другие необходимые пакеты, установив requirements.txt с помощьюpip install -r <path>/requirements.txt.
Подключение к рабочей области Машинное обучение Azure
az login
Отправка потока и создание запуска
Подготовьте файл run.yml, чтобы определить конфигурацию для этого потока, выполняемую в облаке.
$schema: https://azuremlschemas.azureedge.net/promptflow/latest/Run.schema.json
flow: <path-to-flow>
data: <path-to-flow>/<data-file>.jsonl
column_mapping:
url: ${data.url}
# Define cloud compute resource
resources:
instance_type: <compute-type>
# If using compute instance compute type, also specify instance name
# compute: <compute-instance-name>
# Specify connections
<node-name>:
connection: <connection-name>
deployment_name: <deployment-name>
Вы можете указать имя подключения и развертывания для каждого средства в потоке, требующего подключения. Если имя подключения и развертывания не указано, средство использует подключение и развертывание в файле flow.dag.yaml . Используйте следующий код для форматирования подключений:
...
connections:
<node-name>:
connection: <connection-name>
deployment_name: <deployment-name>
...
Создайте запуск.
pfazure run create --file run.yml
Создание запуска потока оценки
Подготовьте файл run_evaluation.yml, чтобы определить конфигурацию для этого потока оценки в облаке.
$schema: https://azuremlschemas.azureedge.net/promptflow/latest/Run.schema.json
flow: <path-to-flow>
data: <path-to-flow>/<data-file>.jsonl
run: <id-of-base-flow-run>
column_mapping:
<input-name>: ${data.<column-from-test-dataset>}
<input-name>: ${run.outputs.<column-from-run-output>}
resources:
instance_type: <compute-type>
compute: <compute_instance_name>
connections:
<node-name>:
connection: <connection-name>
deployment_name: <deployment-name>
<node-name>:
connection: <connection-name>
deployment_name: <deployment-name>
Создайте запуск оценки.
pfazure run create --file run_evaluation.yml
Просмотр результатов выполнения
Отправка потока в облако возвращает URL-адрес облака выполнения. Вы можете открыть URL-адрес для просмотра результатов выполнения в Студия машинного обучения Azure. Для просмотра результатов выполнения можно также выполнить следующие команды CLI или SDK.
Потоковая передача журналов
pfazure run stream --name <run-name>
Просмотр выходных данных выполнения
pfazure run show-details --name <run-name>
Просмотр метрик выполнения оценки
pfazure run show-metrics --name <evaluation-run-name>
Интеграция с DevOps
Сочетание локальной среды разработки и системы управления версиями, таких как Git, обычно наиболее эффективно для итеративной разработки. Вы можете внести изменения и протестировать код локально, а затем зафиксировать изменения в Git. Этот процесс создает текущую запись изменений и предоставляет возможность вернуться к более ранним версиям при необходимости.
Если необходимо предоставить общий доступ к потокам в разных средах, их можно отправить в облачный репозиторий кода, например GitHub или Azure Repos. Эта стратегия позволяет получить доступ к последней версии кода из любого расположения и предоставляет средства для совместной работы и управления кодом.
Следуя этим рекомендациям, команды могут создавать удобную, эффективную и эффективную среду совместной работы для разработки потока запросов.
Например, сквозные конвейеры LLMOps, которые выполняют потоки веб-классификации, см. в разделе "Настройка конечных версий GenAIOps" с помощью потока запросов и GitHub и демонстрационного проекта веб-классификации GitHub.
Поток триггера выполняется в конвейерах CI
После успешного разработки и тестирования потока и его проверки в качестве начальной версии можно настроить и проверить итерации. На этом этапе можно активировать запуски потока, включая пакетное тестирование и выполнение вычислений, с помощью интерфейса командной строки потока запроса для автоматизации шагов в конвейере CI.
На протяжении всего жизненного цикла итерации потока можно использовать интерфейс командной строки для автоматизации следующих операций:
- Выполнение потока запроса после запроса на вытягивание
- Выполнение оценки потока запроса для обеспечения высокого качества результатов
- Регистрация моделей потоков запроса
- Развертывание моделей потоков запроса
Использование пользовательского интерфейса студии для непрерывной разработки
В любой момент разработки потока вы можете вернуться к пользовательскому интерфейсу Студия машинного обучения Azure и использовать облачные ресурсы и интерфейсы для внесения изменений в поток.
Чтобы продолжить разработку и работу с наиболее актуальными версиями файлов потока, вы можете получить доступ к терминалу на странице записной книжки и извлечь последние файлы потока из репозитория. Кроме того, вы можете напрямую импортировать локальную папку потока в виде нового проекта, чтобы легко перейти между локальной и облачной разработкой.

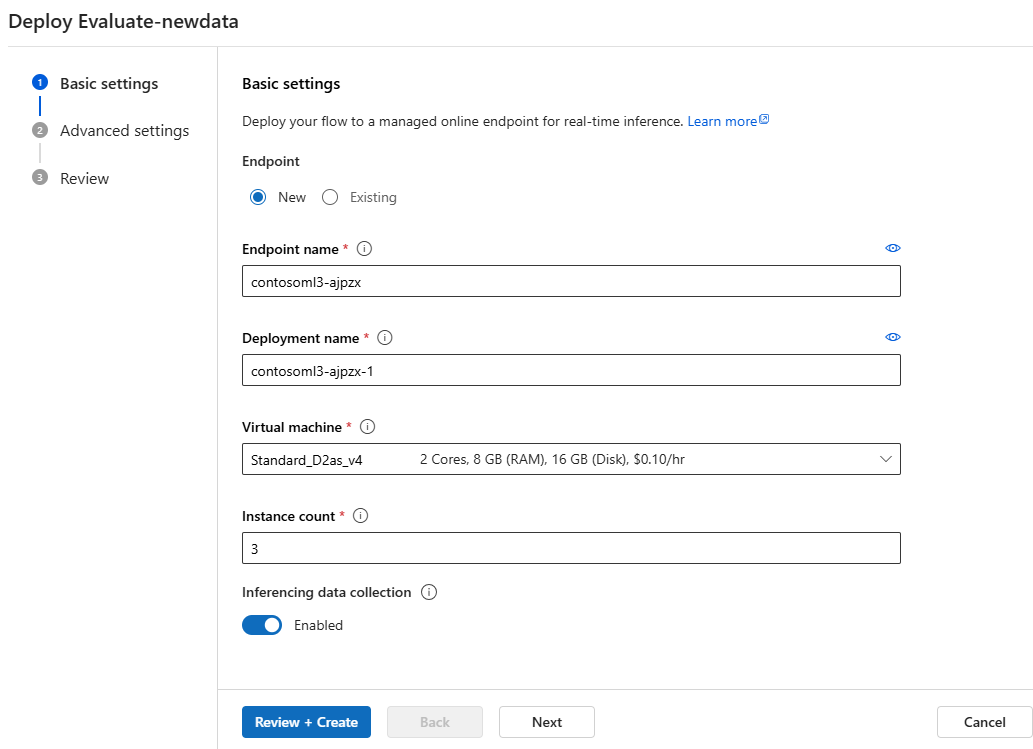
Развертывание потока в качестве сетевой конечной точки
Последний шаг в рабочей среде — развертывание потока в качестве сетевой конечной точки в Машинное обучение Azure. Этот процесс позволяет интегрировать поток в приложение и сделать его доступным для использования. Дополнительные сведения о развертывании потока см. в статье "Развертывание потоков в Машинное обучение Azure управляемой конечной точке в сети" для вывода в режиме реального времени.
Совместная работа по разработке потоков
Совместная работа между участниками группы может быть важной при разработке приложения на основе LLM с помощью потока запроса. Участники группы могут создавать и тестировать один и тот же поток, работать над различными аспектами потока или вносить итеративные изменения и улучшения одновременно. Для совместной работы требуется эффективный и упрощенный подход к совместному использованию кода, отслеживанию изменений, управлению версиями и интеграции изменений в окончательный проект.
Пакет SDK для потока запросов и интерфейс командной строки и расширение потока запроса VS Code упрощают совместную работу с разработкой потока на основе кода в репозитории исходного кода. Вы можете использовать облачную систему управления версиями, например GitHub или Azure Repos, для отслеживания изменений, управления версиями и интеграции этих изменений в окончательный проект.
Следуйте рекомендациям по разработке для совместной работы
Настройте централизованный репозиторий кода.
Первый шаг процесса совместной работы включает настройку репозитория кода в качестве основы для кода проекта, включая код потока запроса. Этот централизованный репозиторий обеспечивает эффективную организацию, отслеживание изменений и совместную работу между участниками группы.
Создайте и протестируйте поток локально в VS Code с расширением потока запроса.
После настройки репозитория члены группы могут использовать VS Code с расширением потока запроса для локального разработки и единого входного тестирования потока. Стандартная интегрированная среда разработки способствует совместной работе нескольких членов, работающих над различными аспектами потока.
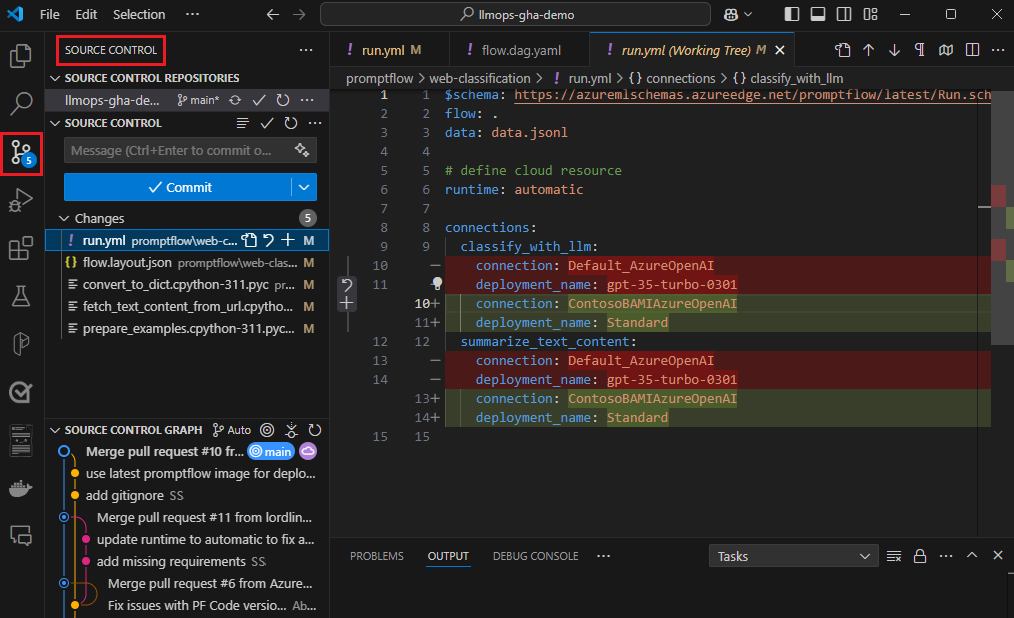
pfazureИспользуйте интерфейс командной строки или пакет SDK для отправки пакетных запусков и вычислений из локальных потоков в облако.После локальной разработки и тестирования члены команды могут использовать интерфейс командной строки командной строки или пакета SDK для отправки и оценки пакетных и ознакомительных запусков в облако. Этот процесс позволяет использовать облачные вычисления, постоянное хранилище результатов, создание конечных точек для развертываний и эффективное управление в пользовательском интерфейсе студии.
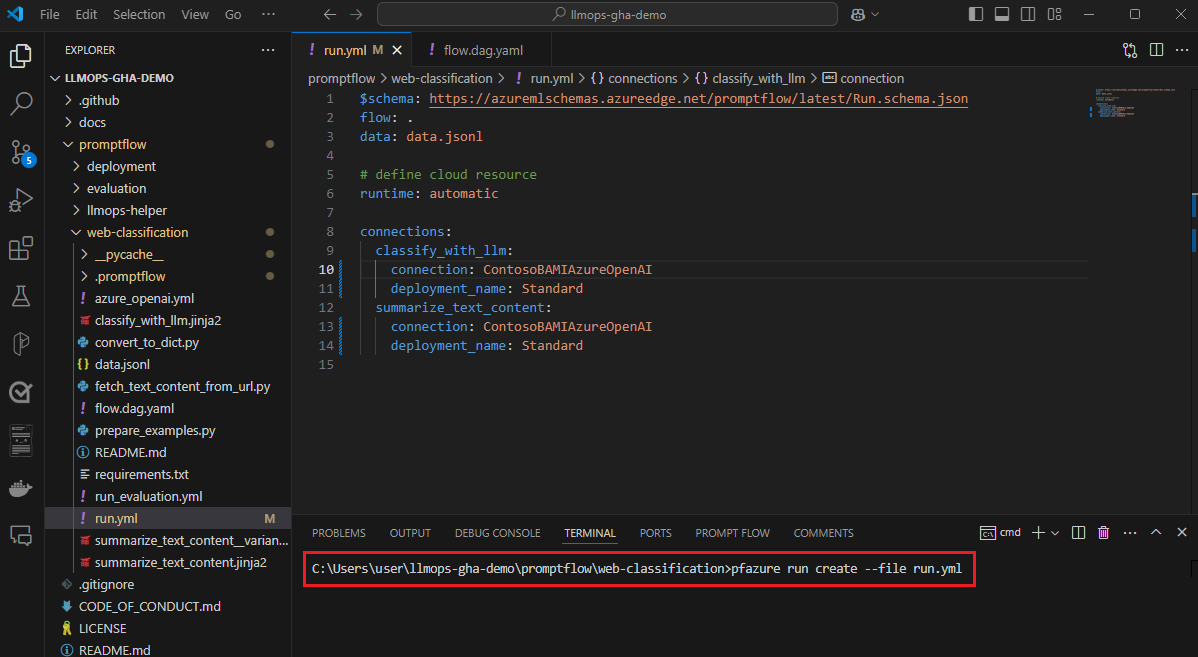
Просмотр результатов выполнения и управление ими в пользовательском интерфейсе рабочей области Студия машинного обучения Azure.
После отправки запусков в облако участники группы могут получить доступ к пользовательскому интерфейсу студии, чтобы просмотреть результаты и эффективно управлять экспериментами. Облачная рабочая область предоставляет централизованное расположение для сбора журналов выполнения, журналов, моментальных снимков, комплексных результатов и входных данных уровня экземпляра.
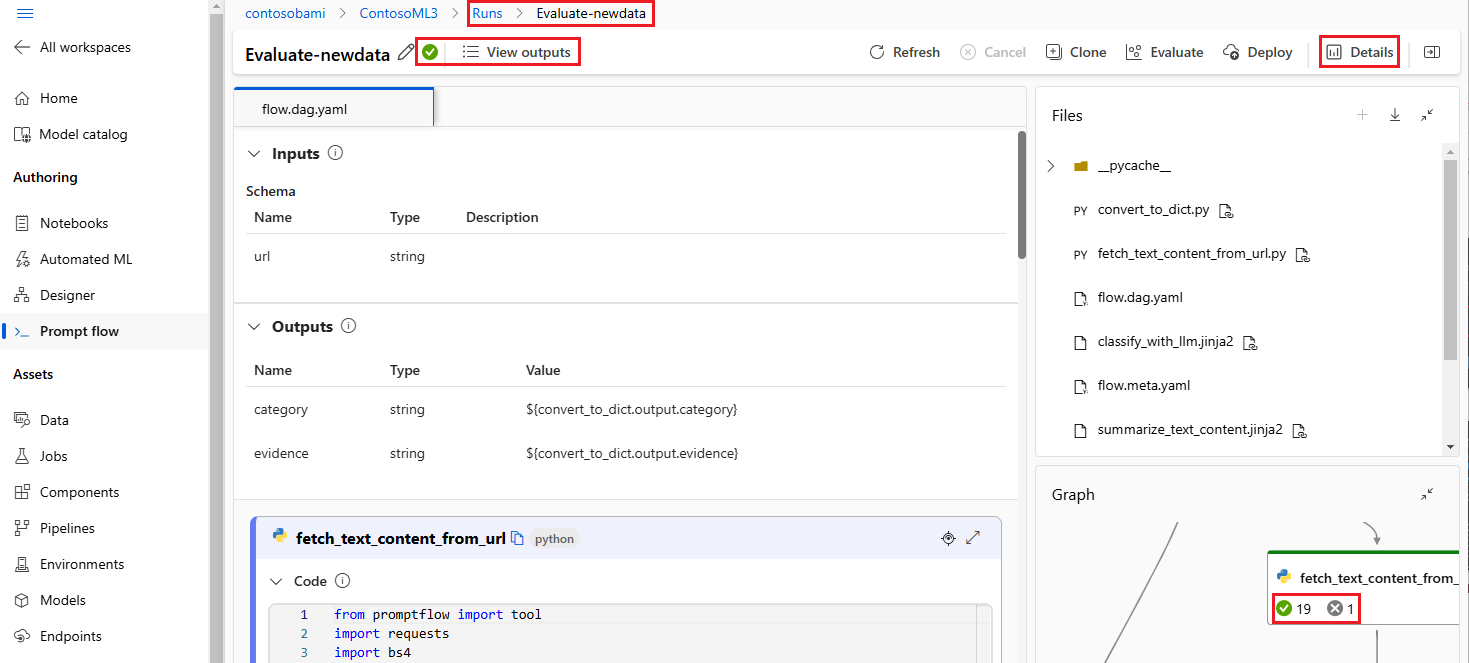
Используйте список запусков, который записывает весь журнал выполнения, чтобы легко сравнить результаты различных запусков, помогая в анализе качества и необходимых корректировках.
Продолжайте использовать локальную итеративную разработку.
После анализа результатов экспериментов члены группы могут вернуться в локальную среду и репозиторий кода для получения дополнительных возможностей разработки и точной настройки, а затем отправить последующие запуски в облако. Этот итеративный подход обеспечивает согласованное улучшение до тех пор, пока команда не будет удовлетворена качеством для производства.
Используйте одношаговую развертывание в рабочей среде в студии.
После того как команда полностью уверена в качестве потока, они могут легко развернуть его как онлайн-конечную точку в надежной облачной среде. Развертывание как онлайн-конечная точка может основываться на моментальном снимке запуска, что позволяет обеспечить стабильную и безопасную обслуживание, дальнейшее выделение ресурсов и отслеживание использования ресурсов, а также мониторинг журналов в облаке.
Мастер развертывания Студия машинного обучения Azure помогает легко настроить развертывание.