Использование параллельных заданий в конвейерах
ОБЛАСТЬ ПРИМЕНЕНИЯ: Расширение машинного обучения Azure CLI версии 2 (current)Python SDK azure-ai-ml версии 2 (current)
Расширение машинного обучения Azure CLI версии 2 (current)Python SDK azure-ai-ml версии 2 (current)
В этой статье объясняется, как использовать интерфейс командной строки версии 2 и пакет SDK Python версии 2 для выполнения параллельных заданий в конвейерах Машинное обучение Azure. Параллельные задания ускоряют выполнение заданий путем распределения повторяющихся задач в мощных вычислительных кластерах с несколькими узлами.
Инженеры машинного обучения всегда имеют требования к масштабированию для своих задач обучения или вывода. Например, когда специалист по обработке и анализу данных предоставляет один сценарий для обучения модели прогнозирования продаж, инженеры машинного обучения должны применить эту задачу обучения к каждому отдельному хранилищу данных. Проблемы этого процесса горизонтального масштабирования включают длительные периоды выполнения, которые вызывают задержки и непредвиденные проблемы, требующие ручного вмешательства для поддержания выполнения задачи.
Основной задачей параллелизации Машинное обучение Azure является разделение одной последовательной задачи на мини-пакеты и отправка этих мини-пакетов в несколько вычислений для параллельного выполнения. Параллельные задания значительно сокращают сквозное время выполнения, а также автоматически обрабатывают ошибки. Рассмотрите возможность использования Машинное обучение Azure параллельного задания для обучения многих моделей на основе секционированных данных или ускорения крупномасштабных задач вывода пакета.
Например, в сценарии, где выполняется модель обнаружения объектов в большом наборе изображений, Машинное обучение Azure параллельные задания позволяют легко распространять образы для параллельного выполнения пользовательского кода в определенном вычислительном кластере. Параллелизация может значительно сократить затраты на время. Машинное обучение Azure параллельные задания также могут упростить и автоматизировать процесс, чтобы сделать его более эффективным.
Необходимые компоненты
- У вас есть учетная запись Машинное обучение Azure и рабочая область.
- Общие сведения о конвейерах Машинное обучение Azure.
- Установите Azure CLI и расширение
ml. Дополнительные сведения см. в разделе Установка, настройка и использование CLI (версия 2). Расширениеmlавтоматически устанавливает при первом запускеaz mlкоманды. - Узнайте, как создавать и запускать конвейеры и компоненты Машинное обучение Azure с помощью ИНТЕРФЕЙСА командной строки версии 2.
Создание и запуск конвейера с помощью параллельного шага задания
Параллельное задание Машинное обучение Azure можно использовать только как шаг в задании конвейера.
Ниже приведены примеры запуска задания конвейера с помощью параллельного задания в конвейере в репозитории Машинное обучение Azure примеров.
Подготовка к параллелизации
Для этого шага параллельного задания требуется подготовка. Вам нужен скрипт записи, реализующий предопределенные функции. Кроме того, необходимо задать атрибуты в определении параллельных заданий, которые:
- Определите и привязите входные данные.
- Задайте метод деления данных.
- Настройте вычислительные ресурсы.
- Вызовите скрипт записи.
В следующих разделах описывается подготовка параллельного задания.
Объявление параметра ввода и деления данных
Для параллельного задания требуется разделить один основной вход и обрабатываться параллельно. Основной формат входных данных может быть табличным или списком файлов.
Различные форматы данных имеют разные типы входных данных, режимы ввода и методы деления данных. В следующей таблице описаны параметры:
| Формат данных | Тип Ввода | Режим ввода | Метод деления данных |
|---|---|---|---|
| Список файлов | mltable или uri_folder |
ro_mount или download |
По размеру (количеству файлов) или по секции |
| Табличные данные | mltable |
direct |
По размеру (предполагаемому физическому размеру) или по секции |
Примечание.
Если в качестве основных входных данных используются табличные mltable данные, необходимо:
- Установите библиотеку в вашей среде, как в строке
mltable9 этого файла conda. - Укажите файл спецификации MLTable в указанном пути с заполненным разделом
transformations: - read_delimited:. Примеры см. в статье "Создание ресурсов данных и управление ими".
Вы можете объявить основные входные данные с input_data атрибутом в параллельном задании YAML или Python, а также привязать данные к определенному input параллельному заданию с помощью ${{inputs.<input name>}}. Затем вы определяете атрибут деления данных для основных входных данных в зависимости от метода деления данных.
| Метод деления данных | Attribute name | Тип атрибута | Пример задания |
|---|---|---|---|
| По размеру | mini_batch_size |
строка | Прогнозирование пакетной службы Iris |
| По секции | partition_keys |
список строк | Прогнозирование продаж апельсинового сока |
Настройка вычислительных ресурсов для параллелизации
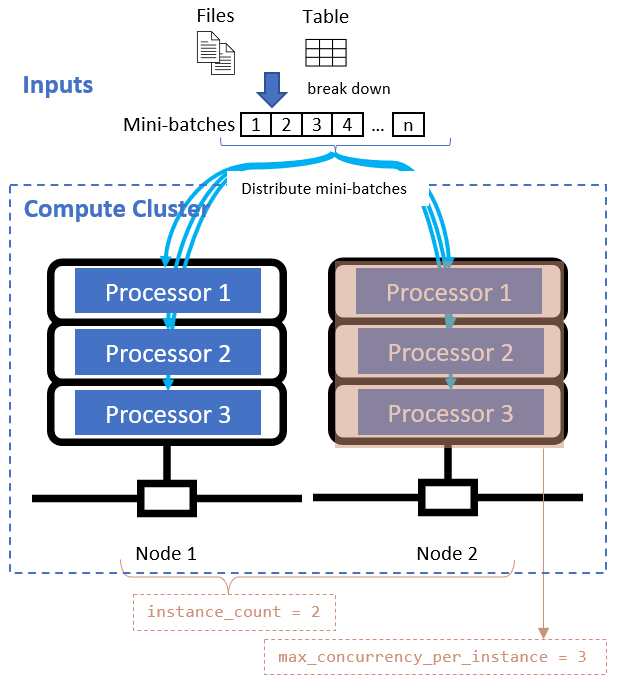
После определения атрибута деления данных настройте вычислительные ресурсы для параллелизации, задав instance_count атрибуты и max_concurrency_per_instance атрибуты.
| Attribute name | Type | Описание | Default value |
|---|---|---|---|
instance_count |
integer | Число узлов, используемых для задания. | 1 |
max_concurrency_per_instance |
integer | Количество процессоров на каждом узле. | Для вычислений GPU: 1. Для вычислений ЦП: количество ядер. |
Эти атрибуты работают вместе с указанным вычислительным кластером, как показано на следующей схеме:
Вызов скрипта записи
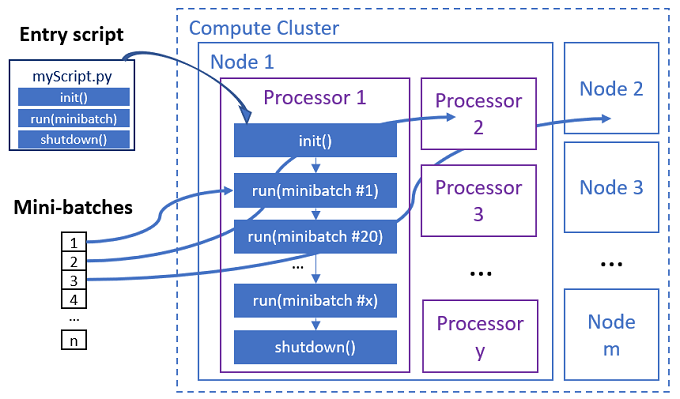
Скрипт записи — это один файл Python, реализующий следующие три предопределенные функции с пользовательским кодом.
| Имя функции | Обязательное поле | Description | Входные данные | Возврат |
|---|---|---|---|---|
Init() |
Y | Общая подготовка перед запуском мини-пакетов. Например, используйте эту функцию для загрузки модели в глобальный объект. | -- | -- |
Run(mini_batch) |
Y | Реализует основную логику выполнения для мини-пакетов. | mini_batch — это кадр данных pandas, если входные данные являются табличными данными или списком путей к файлу, если входные данные являются каталогом. |
Кадры данных, список или кортеж. |
Shutdown() |
N | Необязательная функция для выполнения пользовательских очистки перед возвратом вычислительных ресурсов в пул. | -- | -- |
Внимание
Чтобы избежать исключений при анализе аргументов в Init() или Run(mini_batch) функциях, используйте parse_known_args вместо parse_argsнего. См. пример iris_score скрипта записи с анализатором аргументов.
Внимание
Для Run(mini_batch) функции требуется возврат кадра данных, списка или элемента кортежа. Параллельное задание использует количество возвращаемых элементов для измерения успешности элементов в этом мини-пакете. Мини-пакетное число должно быть равно счетчику возвращаемого списка, если все элементы обработаны.
Параллельное задание выполняет функции в каждом процессоре, как показано на следующей схеме.
См. следующие примеры скриптов записи:
- Идентификация изображения для списка файлов изображений
- Классификация ирисов для табличных данных ириса
Чтобы вызвать скрипт записи, задайте следующие два атрибута в определении параллельного задания:
| Attribute name | Type | Описание: |
|---|---|---|
code |
строка | Локальный путь к каталогу исходного кода для отправки и использования для задания. |
entry_script |
строка | Файл Python, содержащий реализацию предопределенных параллельных функций. |
Пример шага параллельного задания
Следующий параллельный шаг задания объявляет входной тип, режим и метод деления данных, привязывает входные данные, настраивает вычисления и вызывает скрипт записи.
batch_prediction:
type: parallel
compute: azureml:cpu-cluster
inputs:
input_data:
type: mltable
path: ./neural-iris-mltable
mode: direct
score_model:
type: uri_folder
path: ./iris-model
mode: download
outputs:
job_output_file:
type: uri_file
mode: rw_mount
input_data: ${{inputs.input_data}}
mini_batch_size: "10kb"
resources:
instance_count: 2
max_concurrency_per_instance: 2
logging_level: "DEBUG"
mini_batch_error_threshold: 5
retry_settings:
max_retries: 2
timeout: 60
task:
type: run_function
code: "./script"
entry_script: iris_prediction.py
environment:
name: "prs-env"
version: 1
image: mcr.microsoft.com/azureml/openmpi4.1.0-ubuntu20.04
conda_file: ./environment/environment_parallel.yml
Рассмотрите параметры автоматизации
Машинное обучение Azure параллельное задание предоставляет множество необязательных параметров, которые могут автоматически управлять заданием без вмешательства вручную. Эти параметры описаны в приведенной ниже таблице.
| Ключ | Тип | Описание | Допустимые значения | Default value | Задать в аргументе атрибута или программы |
|---|---|---|---|---|---|
mini_batch_error_threshold |
integer | Количество неудачных мини-пакетов, которые будут игнорироваться в этом параллельном задании. Если число неудачных мини-пакетов выше этого порогового значения, параллельное задание помечается как неудачное. Мини-пакет помечается как неудачный, если: — количество возвращаемых данных run() меньше числа входных данных мини-пакетной службы.— исключения перехватываются в пользовательском run() коде. |
[-1, int.max] |
-1, что означает, что игнорировать все неудачные мини-пакеты |
Атрибут mini_batch_error_threshold |
mini_batch_max_retries |
integer | Количество повторных попыток, когда мини-пакет завершается сбоем или истекает время ожидания. Если все повторные попытки завершаются ошибкой, мини-пакет помечается как неудачный для mini_batch_error_threshold вычисления. |
[0, int.max] |
2 |
Атрибут retry_settings.max_retries |
mini_batch_timeout |
integer | Время ожидания в секундах для выполнения пользовательской run() функции. Если время выполнения превышает это пороговое значение, мини-пакет прерывается и помечается как не удалось запустить повтор. |
(0, 259200] |
60 |
Атрибут retry_settings.timeout |
item_error_threshold |
integer | Пороговое значение неудачных элементов. Сбой элементов учитывается по числу входных данных и возвращается из каждого мини-пакета. Если сумма неудачных элементов выше этого порогового значения, параллельное задание помечается как неудачное. | [-1, int.max] |
-1, что означает игнорировать все сбои во время параллельного задания |
Аргумент программы--error_threshold |
allowed_failed_percent |
integer | mini_batch_error_thresholdАналогично, но использует процент неудачных мини-пакетов вместо количества. |
[0, 100] |
100 |
Аргумент программы--allowed_failed_percent |
overhead_timeout |
integer | Время ожидания в секундах для инициализации каждого мини-пакета. Например, загрузите мини-пакетные данные и передайте его в функцию run() . |
(0, 259200] |
600 |
Аргумент программы--task_overhead_timeout |
progress_update_timeout |
integer | Время ожидания в секундах для мониторинга хода выполнения мини-пакета. Если обновления хода выполнения не получены в течение этого параметра времени ожидания, параллельное задание помечается как неудачное. | (0, 259200] |
Динамически вычисляется другими параметрами | Аргумент программы--progress_update_timeout |
first_task_creation_timeout |
integer | Время ожидания в секундах для мониторинга времени между запуском задания и запуском первого мини-пакета. | (0, 259200] |
600 |
Аргумент программы--first_task_creation_timeout |
logging_level |
строка | Уровень журналов для дампа в файлы журналов пользователей. | INFO, WARNING или DEBUG |
INFO |
Атрибут logging_level |
append_row_to |
строка | Агрегирование всех возвращается из каждого запуска мини-пакета и выводит его в этот файл. Может ссылаться на один из выходных данных параллельного задания с помощью выражения. ${{outputs.<output_name>}} |
Атрибут task.append_row_to |
||
copy_logs_to_parent |
строка | Логический параметр, следует ли копировать ход выполнения задания, обзор и журналы в родительское задание конвейера. | True или False |
False |
Аргумент программы--copy_logs_to_parent |
resource_monitor_interval |
integer | Интервал времени в секундах для дампа использования ресурсов узла (например, ЦП или памяти) для записи папки в папке logs/sys/perf . Примечание. Журналы ресурсов частого дампа немного замедляют скорость выполнения. Задайте для этого значения значение, чтобы 0 остановить использование ресурсов дампа. |
[0, int.max] |
600 |
Аргумент программы--resource_monitor_interval |
В следующем примере кода обновляются следующие параметры:
batch_prediction:
type: parallel
compute: azureml:cpu-cluster
inputs:
input_data:
type: mltable
path: ./neural-iris-mltable
mode: direct
score_model:
type: uri_folder
path: ./iris-model
mode: download
outputs:
job_output_file:
type: uri_file
mode: rw_mount
input_data: ${{inputs.input_data}}
mini_batch_size: "10kb"
resources:
instance_count: 2
max_concurrency_per_instance: 2
logging_level: "DEBUG"
mini_batch_error_threshold: 5
retry_settings:
max_retries: 2
timeout: 60
task:
type: run_function
code: "./script"
entry_script: iris_prediction.py
environment:
name: "prs-env"
version: 1
image: mcr.microsoft.com/azureml/openmpi4.1.0-ubuntu20.04
conda_file: ./environment/environment_parallel.yml
program_arguments: >-
--model ${{inputs.score_model}}
--error_threshold 5
--allowed_failed_percent 30
--task_overhead_timeout 1200
--progress_update_timeout 600
--first_task_creation_timeout 600
--copy_logs_to_parent True
--resource_monitor_interva 20
append_row_to: ${{outputs.job_output_file}}
Создание конвейера с шагом параллельного задания
В следующем примере показано полное задание конвейера с встроенным шагом параллельного задания:
$schema: https://azuremlschemas.azureedge.net/latest/pipelineJob.schema.json
type: pipeline
display_name: iris-batch-prediction-using-parallel
description: The hello world pipeline job with inline parallel job
tags:
tag: tagvalue
owner: sdkteam
settings:
default_compute: azureml:cpu-cluster
jobs:
batch_prediction:
type: parallel
compute: azureml:cpu-cluster
inputs:
input_data:
type: mltable
path: ./neural-iris-mltable
mode: direct
score_model:
type: uri_folder
path: ./iris-model
mode: download
outputs:
job_output_file:
type: uri_file
mode: rw_mount
input_data: ${{inputs.input_data}}
mini_batch_size: "10kb"
resources:
instance_count: 2
max_concurrency_per_instance: 2
logging_level: "DEBUG"
mini_batch_error_threshold: 5
retry_settings:
max_retries: 2
timeout: 60
task:
type: run_function
code: "./script"
entry_script: iris_prediction.py
environment:
name: "prs-env"
version: 1
image: mcr.microsoft.com/azureml/openmpi4.1.0-ubuntu20.04
conda_file: ./environment/environment_parallel.yml
program_arguments: >-
--model ${{inputs.score_model}}
--error_threshold 5
--allowed_failed_percent 30
--task_overhead_timeout 1200
--progress_update_timeout 600
--first_task_creation_timeout 600
--copy_logs_to_parent True
--resource_monitor_interva 20
append_row_to: ${{outputs.job_output_file}}
Отправка задания конвейера
Отправьте задание конвейера с параллельным шагом с помощью az ml job create команды CLI:
az ml job create --file pipeline.yml
Проверка параллельного шага в пользовательском интерфейсе Студии
После отправки задания конвейера мини-приложение SDK или CLI предоставляет веб-URL-адрес графу конвейера в пользовательском интерфейсе Студия машинного обучения Azure.
Чтобы просмотреть результаты параллельного задания, дважды щелкните параллельный шаг в графе конвейера, перейдите на вкладку "Параметры" на панели сведений, разверните узел "Выполнить параметры", а затем разверните раздел Parallel.

Чтобы отладить сбой параллельного задания, выберите вкладку "Выходные данные и журналы", разверните папку журналов и проверьте, job_result.txt, чтобы понять, почему параллельное задание завершилось сбоем. Сведения о структуре ведения журнала параллельных заданий см . в readme.txt в той же папке.
