Отслеживание экспериментов машинного обучения Azure Databricks с помощью MLflow и Машинное обучение Azure
MLflow — это библиотека с открытым кодом для управления жизненным циклом экспериментов машинного обучения. Вы можете использовать MLflow для интеграции Azure Databricks с Машинное обучение Azure, чтобы обеспечить лучшие возможности обоих продуктов.
В этой статье рассматриваются следующие вопросы:
- Необходимые библиотеки, необходимые для использования MLflow с Azure Databricks и Машинное обучение Azure.
- Как отслеживать запуск Azure Databricks с помощью MLflow в Машинное обучение Azure.
- Как регистрировать модели с помощью MLflow, чтобы получить их зарегистрированы в Машинное обучение Azure.
- Развертывание и использование моделей, зарегистрированных в Машинное обучение Azure.
Необходимые компоненты
- Пакет
azureml-mlflow, который обрабатывает подключение с Машинное обучение Azure, включая проверку подлинности. - Рабочее пространство и кластер Azure Databricks.
- Рабочая область Машинного обучения Azure.
Узнайте, какие права доступа требуются для выполнения операций MLflow в рабочей области.
Примеры записных книжек
Модели обучения в Azure Databricks и их развертывание в репозитории Машинное обучение Azure демонстрирует, как обучать модели в Azure Databricks и развертывать их в Машинное обучение Azure. В нем также описывается отслеживание экспериментов и моделей с помощью экземпляра MLflow в Azure Databricks. В нем описывается использование Машинное обучение Azure для развертывания.
Установка библиотек
Чтобы установить библиотеки в кластере, выполните следующее:
Перейдите на вкладку "Библиотеки" и нажмите кнопку "Установить".
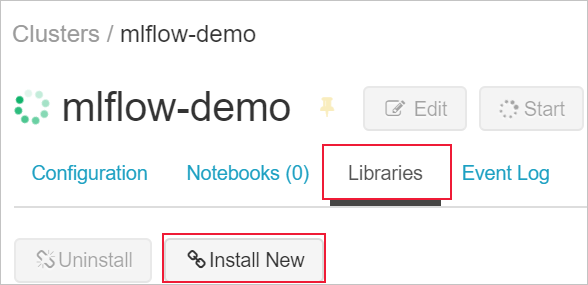
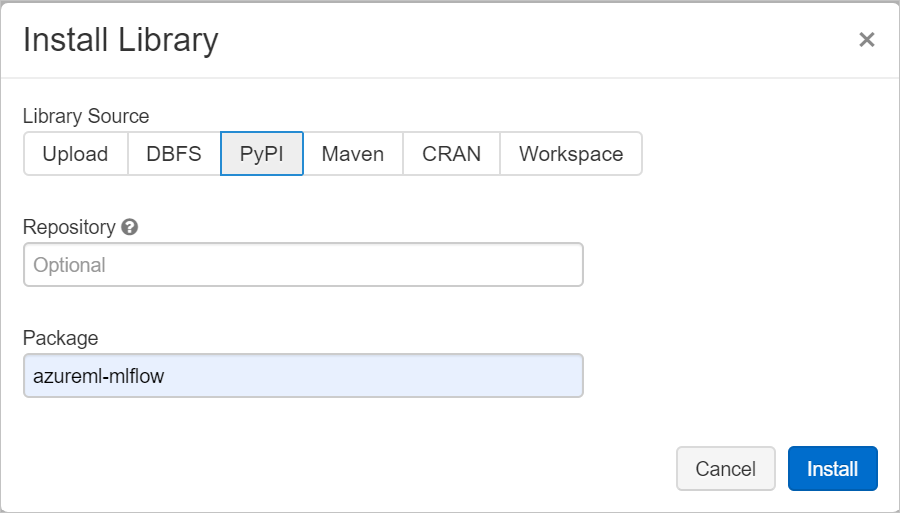
В поле "Пакет" введите azureml-mlflow и выберите "Установить". Повторите этот шаг, чтобы установить другие пакеты в кластер для эксперимента.
Отслеживание выполнений Azure Databricks с использованием MLflow
Вы можете настроить Azure Databricks для отслеживания экспериментов с помощью MLflow двумя способами:
- Подключение в рабочих областях Azure Databricks и Машинного обучения Azure (двойное отслеживание)
- Отслеживание исключительно в службе Машинного обучения Azure
По умолчанию при связывании рабочей области Azure Databricks для вас настроено двойное отслеживание.
Двойной отслеживания в Azure Databricks и Машинное обучение Azure
Связывание рабочей области Azure Databricks с рабочей областью Машинное обучение Azure позволяет отслеживать данные эксперимента в рабочей области Машинное обучение Azure и рабочей области Azure Databricks одновременно. Эта конфигурация называется двойной отслеживанием.
Двойное отслеживание в включенной частной ссылке Машинное обучение Azure рабочей области в настоящее время не поддерживается. Настройте монопольное отслеживание с помощью рабочей области Машинного обучения Azure.
Двойное отслеживание в настоящее время не поддерживается в Microsoft Azure под управлением 21Vianet. Настройте монопольное отслеживание с помощью рабочей области Машинного обучения Azure.
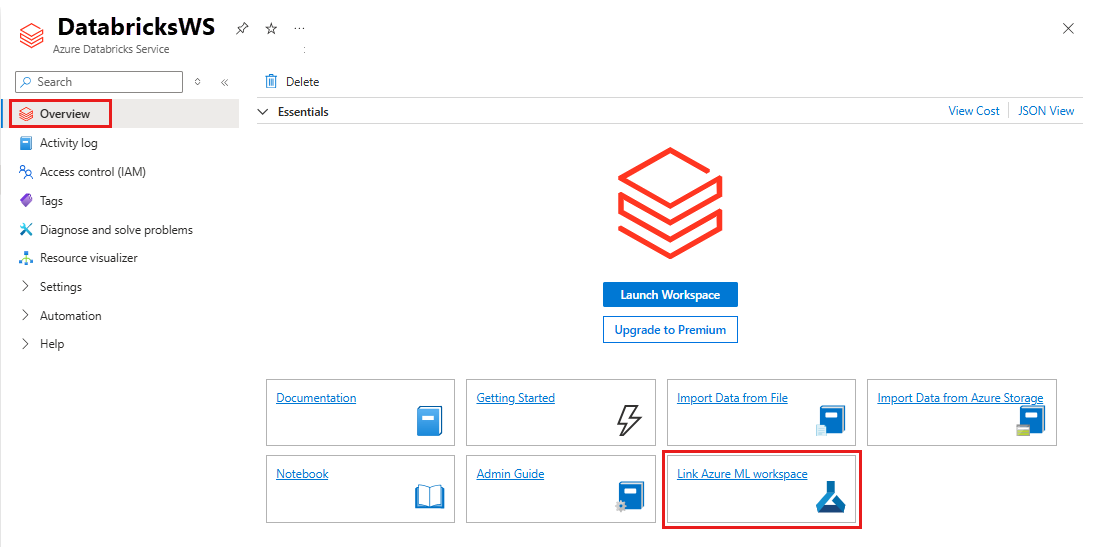
Чтобы связать рабочую область Azure Databricks с новой или существующей Машинное обучение Azure рабочей областью:
Войдите на портал Azure.
Перейдите на страницу обзора рабочей области Azure Databricks.
Выберите ссылку Машинное обучение Azure рабочей области.

После связывания рабочей области Azure Databricks с рабочей областью Машинное обучение Azure отслеживание MLflow автоматически отслеживается в следующих местах:
- в связанной рабочей области Машинного обучения Azure;
- Исходная рабочая область Azure Databricks.
Затем MLflow можно использовать в Azure Databricks таким же образом, как и вы. В следующем примере задается имя эксперимента как обычно в Azure Databricks и начинается ведение журнала некоторых параметров.
import mlflow
experimentName = "/Users/{user_name}/{experiment_folder}/{experiment_name}"
mlflow.set_experiment(experimentName)
with mlflow.start_run():
mlflow.log_param('epochs', 20)
pass
Примечание.
В отличие от отслеживания, реестры моделей не поддерживают регистрацию моделей одновременно в Машинное обучение Azure и Azure Databricks. Дополнительные сведения см. в разделе "Регистрация моделей в реестре с помощью MLflow".
Отслеживание исключительно в рабочей области Машинное обучение Azure
Если вы предпочитаете управлять отслеживаемыми экспериментами в централизованном расположении, можно настроить отслеживание MLflow для отслеживания только в вашей рабочей области Машинного обучения Azure. Преимущество этой конфигурации состоит в том, что она упрощает развертывание с помощью параметров развертывания Машинного обучения Azure.
Предупреждение
Для рабочей области Машинного обучения Azure с включенным приватным каналом необходимо развернуть Azure Databricks в собственной сети (внедрение виртуальной сети), чтобы обеспечить надлежащее подключение.
Настройте URI отслеживания MLflow, чтобы указывать исключительно на Машинное обучение Azure, как показано в следующем примере:
Настройка URI отслеживания
Получите URI отслеживания для рабочей области.
ОБЛАСТЬ ПРИМЕНЕНИЯ:
 расширение машинного обучения Azure CLI версии 2 (текущее)
расширение машинного обучения Azure CLI версии 2 (текущее)Войдите и настройте рабочую область.
az account set --subscription <subscription> az configure --defaults workspace=<workspace> group=<resource-group> location=<location>Вы можете получить URI отслеживания с помощью
az ml workspaceкоманды.az ml workspace show --query mlflow_tracking_uri
Настройте универсальный код ресурса (URI) отслеживания.
set_tracking_uri()Метод указывает URI отслеживания MLflow на этот URI.import mlflow mlflow.set_tracking_uri(mlflow_tracking_uri)
Совет
При работе с общими средами, например с кластером Azure Databricks, кластером Azure Synapse Analytics или аналогичным образом, можно задать переменную MLFLOW_TRACKING_URI среды на уровне кластера. Этот подход позволяет автоматически настроить URI отслеживания MLflow, чтобы указать Машинное обучение Azure для всех сеансов, выполняемых в кластере, а не для каждого сеанса.
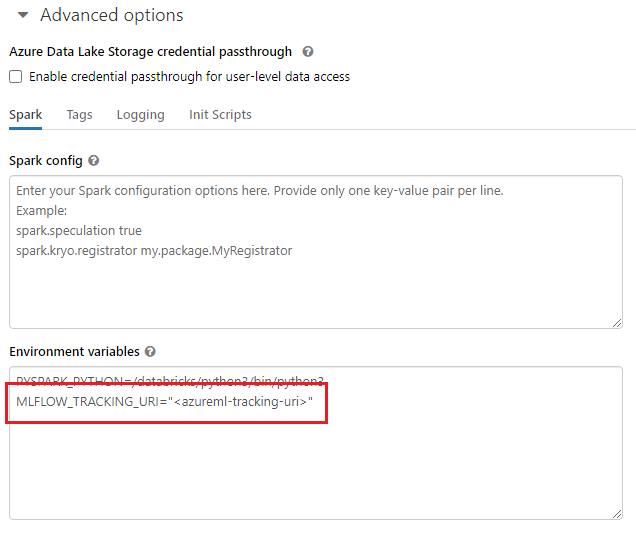
После настройки переменной среды все эксперименты, выполняемые в таком кластере, отслеживаются в Машинное обучение Azure.
Настройка проверки подлинности
После настройки отслеживания настройте проверку подлинности в связанной рабочей области. По умолчанию подключаемый модуль Машинное обучение Azure для MLflow открывает браузер для интерактивного запроса учетных данных. Другие способы настройки проверки подлинности для MLflow в рабочих областях Машинное обучение Azure см. в статье "Настройка MLflow для Машинное обучение Azure: настройка проверки подлинности".
Для интерактивных заданий, в которых есть пользователь, подключенный к сеансу, можно полагаться на интерактивную проверку подлинности, поэтому дальнейшие действия не требуются.
Предупреждение
Интерактивная проверка подлинности браузера блокирует выполнение кода при запросе учетных данных. Этот подход не подходит для проверки подлинности в автоматических средах, таких как задания обучения. Рекомендуется настроить другой режим проверки подлинности.
Для таких сценариев, когда требуется автоматическое выполнение, необходимо настроить субъект-службу для взаимодействия с Машинное обучение Azure.
import os
os.environ["AZURE_TENANT_ID"] = "<AZURE_TENANT_ID>"
os.environ["AZURE_CLIENT_ID"] = "<AZURE_CLIENT_ID>"
os.environ["AZURE_CLIENT_SECRET"] = "<AZURE_CLIENT_SECRET>"
Совет
При работе с общими средами рекомендуется настроить эти переменные среды на вычислительных ресурсах. Рекомендуется управлять ими в качестве секретов в экземпляре Azure Key Vault.
Например, в Azure Databricks можно использовать секреты в переменных среды, как показано в конфигурации кластера. AZURE_CLIENT_SECRET={{secrets/<scope-name>/<secret-name>}} Дополнительные сведения о реализации этого подхода в Azure Databricks см. в статье "Справочник по секрету в переменной среды" или в документации по вашей платформе.
Эксперимент имен в Машинное обучение Azure
При настройке MLflow для исключительно отслеживания экспериментов в рабочей области Машинное обучение Azure соглашение об именовании экспериментов необходимо следовать одному из них, используемому Машинное обучение Azure. В Azure Databricks эксперименты называются путем сохранения эксперимента, например /Users/alice@contoso.com/iris-classifier. Однако в Машинное обучение Azure укажите имя эксперимента напрямую. Тот же эксперимент будет называться iris-classifier напрямую.
mlflow.set_experiment(experiment_name="experiment-name")
Отслеживание параметров, метрик и артефактов
После этой конфигурации можно использовать MLflow в Azure Databricks таким же образом, как и для использования. Дополнительные сведения см. в разделе "Журнал и просмотр метрик" и файлов журналов.
Модели журналов с помощью MLflow
После обучения модели можно вести ее журнал на сервере отслеживания с помощью метода mlflow.<model_flavor>.log_model(). <model_flavor> ссылается на платформу, связанную с моделью. Узнайте, какие разновидности модели поддерживаются.
В следующем примере регистрируется модель, созданная с помощью библиотеки Spark MLLib.
mlflow.spark.log_model(model, artifact_path = "model")
Вкус spark не соответствует тому, что вы обучаете модель в кластере Spark. Вместо этого он следует из используемой платформы обучения. Модель можно обучить с помощью TensorFlow с Spark. Вариант использования будет tensorflow.
Ведение журналов моделей осуществляется внутри отслеживаемого запуска. Это означает, что модели доступны как в Azure Databricks, так и в Машинное обучение Azure (по умолчанию) или исключительно в Машинное обучение Azure, если вы настроили URI отслеживания для указания на него.
Внимание
Параметр registered_model_name не указан. Дополнительные сведения об этом параметре и реестре см. в разделе "Регистрация моделей в реестре с помощью MLflow".
Регистрация моделей в реестре с помощью MLflow
В отличие от отслеживания, реестры моделей не могут работать одновременно в Azure Databricks и Машинное обучение Azure. Они должны использовать один или другой. По умолчанию реестры моделей используют рабочую область Azure Databricks. Если вы решили настроить отслеживание MLflow только для отслеживания в рабочей области Машинное обучение Azure, реестр моделей — это рабочая область Машинное обучение Azure.
Если вы используете конфигурацию по умолчанию, следующий код регистрирует модель внутри соответствующих запусков Azure Databricks и Машинное обучение Azure, но регистрирует ее только в Azure Databricks.
mlflow.spark.log_model(model, artifact_path = "model",
registered_model_name = 'model_name')
- Если зарегистрированная модель с именем не существует, метод регистрирует новую модель, создает версию 1 и возвращает
ModelVersionобъект MLflow. - Если зарегистрированная модель с таким именем уже существует, метод создает новую версию модели и возвращает объект Version.
Использование реестра Машинное обучение Azure с MLflow
Если вы хотите использовать реестр моделей Машинное обучение Azure вместо Azure Databricks, рекомендуется настроить отслеживание MLflow только для отслеживания в рабочей области Машинное обучение Azure. Этот подход устраняет неоднозначность регистрации моделей и упрощает настройку.
Если вы хотите продолжать использовать возможности двойного отслеживания, но регистрировать модели в Машинное обучение Azure, можно указать MLflow использовать Машинное обучение Azure для реестров моделей, настроив URI реестра моделей MLflow. Этот универсальный код ресурса (URI) имеет тот же формат и значение, что и MLflow, отслеживающий URI.
mlflow.set_registry_uri(azureml_mlflow_uri)
Примечание.
Значение azureml_mlflow_uri получено таким же образом, как описано в разделе "Отслеживание MLflow" для отслеживания только в рабочей области Машинное обучение Azure.
Полный пример этого сценария см. в статье "Обучение моделей в Azure Databricks" и их развертывание на Машинное обучение Azure.
Развертывание и использование моделей, зарегистрированных в Машинное обучение Azure
Модели, зарегистрированные в службе "Машинное обучение Azure" с помощью MLflow, могут использоваться следующим образом:
- Конечная точка Машинное обучение Azure (в режиме реального времени и пакет). Это развертывание позволяет использовать Машинное обучение Azure возможности развертывания как в режиме реального времени, так и для пакетного вывода в Экземпляры контейнеров Azure, Azure Kubernetes или управляемых конечных точек вывода.
- Объекты модели MLFlow или определяемые пользователем функции Pandas (определяемые пользователем функции), которые можно использовать в записных книжках Azure Databricks в потоковых или пакетных конвейерах.
Развертывание моделей в конечных точках Машинного обучения Azure
Подключаемый azureml-mlflow модуль можно использовать для развертывания модели в рабочей области Машинное обучение Azure. Дополнительные сведения о том, как развертывать модели в разных целевых объектах , как развертывать модели MLflow.
Внимание
Чтобы развернуть модели, их необходимо зарегистрировать в реестре Машинного обучения Azure. Если ваши модели зарегистрированы в экземпляре MLflow в Azure Databricks, зарегистрируйте их еще раз в Машинное обучение Azure. Дополнительные сведения см. в статье "Обучение моделей в Azure Databricks" и их развертывание в Машинное обучение Azure
Развертывание моделей в Azure Databricks для пакетной оценки с помощью определяемых пользователем ресурсов
Для пакетной оценки можно выбрать кластеры Azure Databricks. С помощью Mlflow можно разрешить любую модель из реестра, к которому вы подключены. Обычно используется один из следующих методов:
- Если модель была обучена и создана с помощью таких
MLLibбиблиотек Spark, используйтеmlflow.pyfunc.spark_udfдля загрузки модели и ее использования в качестве UDF Spark Pandas для оценки новых данных. - Если модель не была обучена или создана с помощью библиотек Spark, либо для
mlflow.pyfunc.load_modelmlflow.<flavor>.load_modelзагрузки модели в драйвере кластера. Необходимо оркестрировать любое параллелизация или рабочее распределение, которое необходимо выполнить в кластере. MLflow не устанавливает библиотеку, требуемую для запуска модели. Эти библиотеки необходимо установить в кластере перед его запуском.
В следующем примере показано, как загрузить модель из реестра с именем uci-heart-classifier и использовать ее в качестве UDF Spark Pandas для оценки новых данных.
from pyspark.sql.types import ArrayType, FloatType
model_name = "uci-heart-classifier"
model_uri = "models:/"+model_name+"/latest"
#Create a Spark UDF for the MLFlow model
pyfunc_udf = mlflow.pyfunc.spark_udf(spark, model_uri)
Дополнительные способы ссылки на модели из реестра см. в разделе "Загрузка моделей из реестра".
После загрузки модели можно использовать эту команду для оценки новых данных.
#Load Scoring Data into Spark Dataframe
scoreDf = spark.table({table_name}).where({required_conditions})
#Make Prediction
preds = (scoreDf
.withColumn('target_column_name', pyfunc_udf('Input_column1', 'Input_column2', ' Input_column3', …))
)
display(preds)
Очистка ресурсов
Если вы хотите сохранить рабочую область Azure Databricks, но больше не требуется Машинное обучение Azure рабочей области, можно удалить рабочую область Машинное обучение Azure. Это действие приводит к отмене связи рабочей области Azure Databricks и рабочей области Машинное обучение Azure.
Если вы не планируете использовать зарегистрированные метрики и артефакты в рабочей области, удалите группу ресурсов, содержащую учетную запись хранения и рабочую область.
- На портале Azure найдите Группы ресурсов. В разделе "Службы" выберите группы ресурсов.
- В списке групп ресурсов найдите и выберите созданную группу ресурсов, чтобы открыть ее.
- На странице "Обзор" выберите "Удалить группу ресурсов".
- Чтобы проверить удаление, введите имя группы ресурсов.