Использование моделей основы Open Source, которые курируются Машинное обучение Azure
Из этой статьи вы узнаете, как настроить, оценить и развернуть базовые модели в каталоге моделей.
Вы можете быстро протестировать любую предварительно обученную модель с помощью формы вывода образца на карточке модели, предоставляя собственные примеры входных данных для тестирования результата. Кроме того, карточка модели для каждой модели включает краткое описание модели и ссылки на примеры для вывода на основе кода, тонкой настройки и оценки модели.
Как оценить базовые модели с помощью собственных тестовых данных
Вы можете оценить модель Foundation для тестового набора данных с помощью формы оценки пользовательского интерфейса или с помощью примеров на основе кода, связанных с карточкой модели.
Оценка с помощью студии
Вы можете вызвать форму "Оценка модели", нажав кнопку "Оценить " на карточке модели для любой базовой модели.
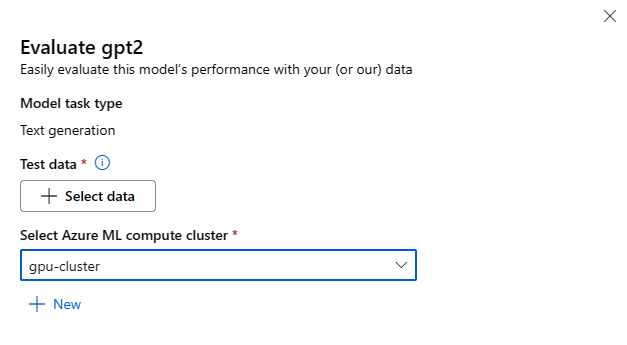
Каждую модель можно оценить для конкретной задачи вывода, для которую будет использоваться модель.
Тестовые данные:
- Передайте тестовые данные, которые вы хотите использовать для оценки модели. Вы можете отправить локальный файл (в формате JSONL) или выбрать существующий зарегистрированный набор данных из рабочей области.
- После выбора набора данных необходимо сопоставить столбцы из входных данных на основе схемы, необходимой для задачи. Например, сопоставлять имена столбцов, соответствующие ключам "предложение" и "метка" для классификации текста

Вычисления.
Укажите Машинное обучение Azure вычислительный кластер, который вы хотите использовать для точной настройки модели. Оценка должна выполняться на вычислительных ресурсах GPU. Убедитесь, что у вас есть достаточная квота вычислений для используемых номеров SKU вычислений.
Нажмите кнопку " Готово " в форме "Оценка", чтобы отправить задание оценки. После завершения задания можно просмотреть метрики оценки для модели. На основе метрик оценки вы можете решить, хотите ли вы точно настроить модель с помощью собственных обучающих данных. Кроме того, можно решить, хотите ли вы зарегистрировать модель и развернуть ее в конечной точке.
Оценка с помощью примеров на основе кода
Чтобы предоставить пользователям возможность приступить к оценке модели, мы опубликовали примеры (записные книжки Python и примеры CLI) в разделе Примеры оценки в репозитории Git azureml-examples. Каждая карточка модели также ссылается на примеры оценки для соответствующих задач
Настройка базовых моделей с помощью собственных обучающих данных
Чтобы повысить производительность модели в рабочей нагрузке, может потребоваться выполнить тонкую настройку базовой модели, используя собственные обучающие данные. Эти базовые модели можно легко настроить с помощью параметров точной настройки в студии или с помощью примеров на основе кода, связанных с картой модели.
Точное настройка с помощью студии
Вы можете вызвать форму параметров точной настройки, нажав кнопку "Точно настроить" на карточке модели для любой базовой модели.
Настройка параметров:
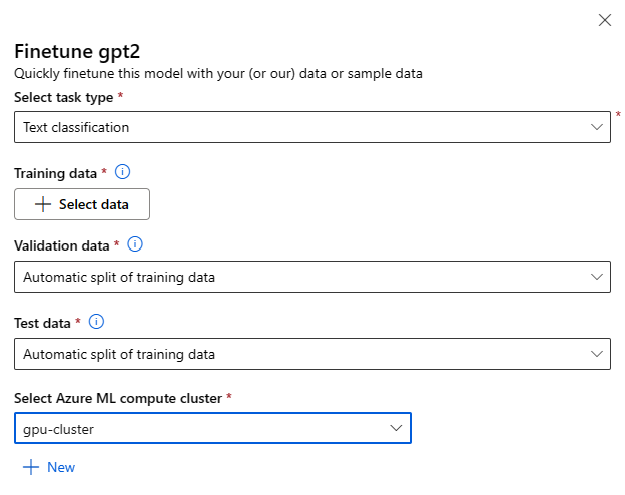
Тип задачи точной настройки
- Каждая предварительно обученная модель из каталога моделей может быть точно настроена для определенного набора задач (например, классификация текста, классификация маркеров, ответы на вопросы). Выберите задачу, используемую в раскрывающемся списке.
Обучающие данные
Передайте обучающие данные, которые вы хотите использовать для точной настройки модели. Вы можете отправить локальный файл (в формате JSONL, CSV или TSV) или выбрать существующий зарегистрированный набор данных из рабочей области.
После выбора набора данных необходимо сопоставить столбцы из входных данных на основе схемы, необходимой для задачи. Например: сопоставление имен столбцов, соответствующих ключам "предложение" и "метка" для классификации текста

- Данные проверки: передайте данные, которые вы хотите использовать для проверки модели. При выборе автоматического разделения резервируется автоматическое разделение обучающих данных для проверки. Кроме того, можно предоставить другой набор данных проверки.
- Тестовые данные. Передайте тестовые данные, которые вы хотите использовать для оценки точно настроенной модели. При выборе автоматического разделения резервируется автоматическое разделение обучающих данных для тестирования.
- Вычисление. Укажите Машинное обучение Azure вычислительный кластер, который вы хотите использовать для точной настройки модели. Для точной настройки необходимо выполнить вычислительные ресурсы GPU. При точной настройке рекомендуется использовать вычислительные номера SKU с gpu A100 / V100. Убедитесь, что у вас есть достаточная квота вычислений для используемых номеров SKU вычислений.
- Нажмите кнопку "Готово " в форме точной настройки, чтобы отправить задание точной настройки. После завершения задания можно просмотреть метрики оценки для точно настроенной модели. Затем можно зарегистрировать выходные данные точно настроенной модели с помощью задания тонкой настройки и развернуть эту модель в конечной точке для вывода.
Настройка с помощью примеров на основе кода
В настоящее время Машинное обучение Azure поддерживает тонкую настройку моделей для следующих языковых задач.
- Классификация текстов
- Классификация токенов
- Ответы на вопросы
- Сводка
- Перевод текста
Чтобы пользователи могли быстро приступить к настройке, мы опубликовали примеры (как записные книжки Python, так и примеры ИНТЕРФЕЙСА командной строки) для каждой задачи в примерах репозитория Git Git Finetune. Каждая карточка модели также содержит ссылки на примеры тонкой настройки для поддерживаемых задач тонкой настройки.
Развертывание базовых моделей в конечных точках для вывода
Вы можете развернуть базовые модели (предварительно обученные модели из каталога моделей и точно настроенных моделей, после регистрации в рабочей области) в конечную точку, которую затем можно использовать для вывода. Поддерживается развертывание как для бессерверных API, так и для управляемых вычислений. Эти модели можно развернуть с помощью мастера развертывания пользовательского интерфейса или с помощью примеров на основе кода, связанных с карточкой модели.
Развертывание с помощью студии
Вы можете вызвать форму развертывания пользовательского интерфейса, нажав кнопку "Развернуть " на карточке модели для любой базовой модели и выбрав бессерверный API с помощью безопасности содержимого ИИ Azure или управляемых вычислений без безопасности содержимого ИИ Azure.

Параметры развертывания
Так как скрипт оценки и среда автоматически включены в базовую модель, необходимо указать номер SKU виртуальной машины для использования, количество экземпляров и имя конечной точки, используемое для развертывания.
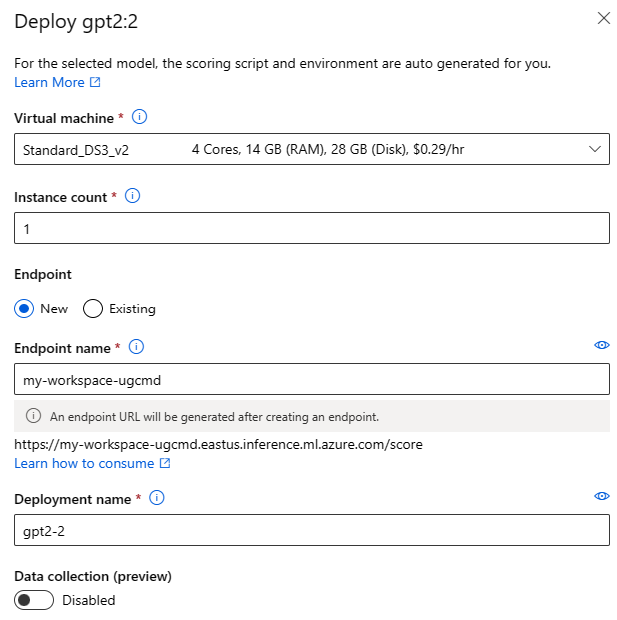
Общая квота
Если вы развертываете модель Llama-2, Phi, Nemotron, Mistral, Dolly или Deci-DeciLM из каталога моделей, но не имеет достаточно квоты для развертывания, Машинное обучение Azure позволяет использовать квоту из общего пула квот в течение ограниченного времени. Для получения дополнительной информации по общим квотам см. Общие квоты службы "Машинное обучение" Azure.

Развертывание с помощью примеров на основе кода
Чтобы пользователи могли быстро приступить к развертыванию и выводу, мы опубликовали примеры в примерах вывода в репозитории Git azureml-examples. Опубликованные примеры включают записные книжки Python и примеры ИНТЕРФЕЙСА командной строки. Каждая карточка модели также ссылается на примеры вывода для вывода в режиме реального времени и пакетного вывода.
Импорт базовых моделей
Если вы хотите использовать модель с открытым исходным кодом, не включенную в каталог моделей, импортируйте ее из Hugging Face в рабочую область Машинное обучение Azure. Hugging Face — это библиотека с открытым исходным кодом для обработки естественного языка (NLP), которая предоставляет предварительно обученные модели для популярных задач NLP. В настоящее время поддерживается импорт моделей для следующих задач, если модель соответствует требованиям, перечисленным в записной книжке импорта модели:
- Маска заливки
- Классификация маркеров
- Ответы на вопросы
- резюмирование
- Создание текста
- Классификация текстов
- перевод;
- Классификация изображений
- Текст к изображению
Примечание.
Модели из Hugging Face применяются к сторонним условиям лицензии, доступным на странице сведений об обнимаемой модели лица. Вы несете ответственность за соблюдение условий лицензии модели.
Нажмите кнопку Импорт в правом верхнем углу каталога моделей, чтобы использовать записную книжку импорта модели.
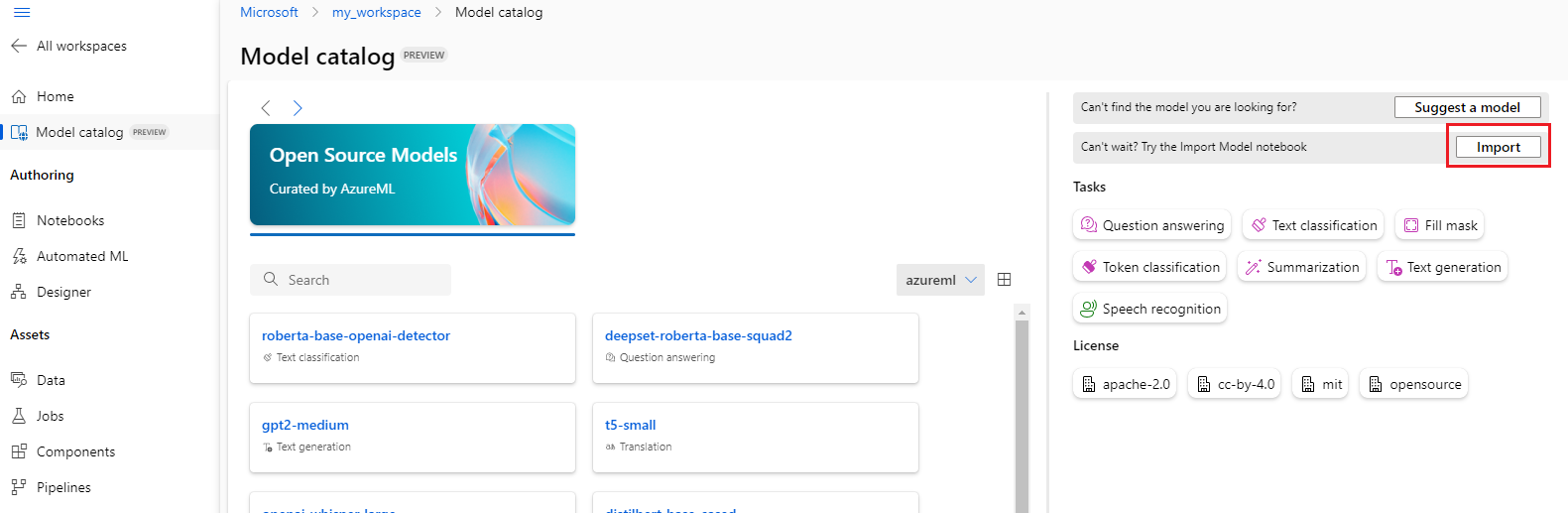
Записная книжка импорта модели также включена в репозиторий Git azureml-examples здесь.
Чтобы импортировать модель, необходимо передать MODEL_ID модель из Hugging Face. Просмотрите модели в концентраторе распознавания лиц Hugging и определите модель для импорта. Убедитесь, что тип задачи модели является одним из поддерживаемых типов задач. Скопируйте идентификатор модели, который доступен в URI страницы или можно скопировать с помощью значка копирования рядом с именем модели. Назначьте его переменной "MODEL_ID" в записной книжке импорта модели. Например:
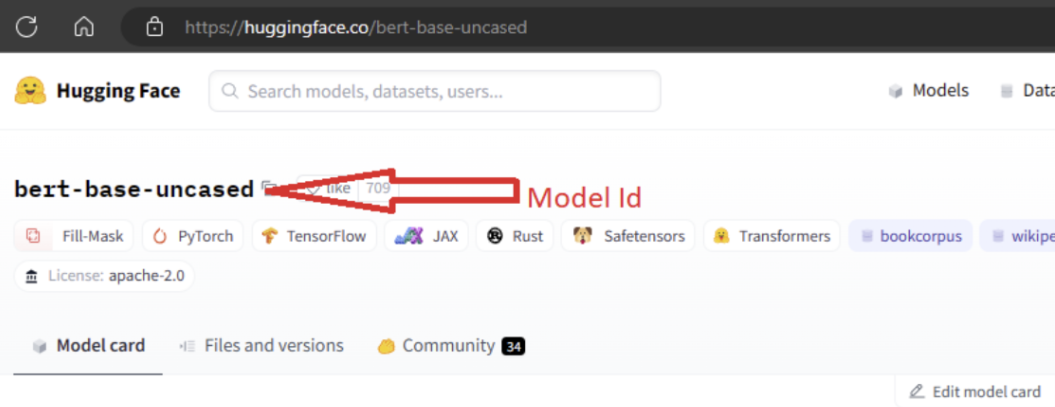
Для выполнения импорта модели необходимо предоставить вычислительные ресурсы. Выполнение импорта модели приводит к импорту указанной модели из hugging Face и зарегистрировано в рабочей области Машинное обучение Azure. Затем эту модель можно настроить или развернуть в конечной точке для вывода.
Подробнее
- Изучите каталог моделей в Студия машинного обучения Azure. Для изучения каталога требуется рабочая область Машинное обучение Azure.
- Изучение каталога моделей и коллекций