Управление входными и выходными данными для компонентов и конвейеров
Машинное обучение Azure конвейеры поддерживают входные и выходные данные как на уровне компонента, так и на уровне конвейера. В этой статье описываются входные и выходные данные конвейера и компонентов, а также управление ими.
На уровне компонента входные и выходные данные определяют интерфейс компонента. Выходные данные одного компонента можно использовать в качестве входных данных для другого компонента в том же родительском конвейере, что позволяет передавать данные или модели между компонентами. Эта взаимосоединение представляет поток данных в конвейере.
На уровне конвейера можно использовать входные и выходные данные для отправки заданий конвейера с различными входными или параметрами данных, например learning_rate. Входные и выходные данные особенно полезны при вызове конвейера через конечную точку REST. Вы можете назначить различные значения входным данным конвейера или получить доступ к выходным данным различных заданий конвейера. Дополнительные сведения см. в разделе "Создание заданий и входных данных" для конечных точек пакетной службы.
Типы входных и выходных данных
Следующие типы поддерживаются как входные, так и выходные данные компонентов или конвейеров:
типы данных; Дополнительные сведения см. в разделе Типы данных.
uri_fileuri_foldermltable
Типы моделей.
mlflow_modelcustom_model
Для входных данных также поддерживаются следующие примитивные типы:
- Примитивные типы
stringnumberintegerboolean
Выходные данные типа примитива не поддерживаются.
Примеры входных и выходных данных
Эти примеры относятся к конвейеру регрессии данных такси Нью-Йорка в репозитории GitHub Машинное обучение Azure.
- Компонент обучения имеет входные
numberданные с именемtest_split_ratio. - Компонент подготовки имеет выходные
uri_folderданные типа. Исходный код компонента считывает CSV-файлы из входной папки, обрабатывает файлы и записывает обработанные CSV-файлы в выходную папку. - Компонент обучения имеет выходные
mlflow_modelданные типа. Исходный код компонента сохраняет обученную модель с помощьюmlflow.sklearn.save_modelметода.
Сериализация выходных данных
Использование выходных данных или моделей сериализует выходные данные и сохраняет их в виде файлов в расположении хранилища. Последующие действия могут получить доступ к файлам во время выполнения задания, установив это расположение хранилища или загрузив файлы в вычислительной файловой системе.
Исходный код компонента должен сериализовать выходной объект, который обычно хранится в памяти в файлы. Например, можно сериализовать кадр данных Pandas в CSV-файл. Машинное обучение Azure не определяет стандартные методы для сериализации объектов. Вы можете выбрать предпочитаемые методы сериализации объектов в файлы. В нижнем компоненте можно выбрать способ десериализации и чтения этих файлов.
Пути ввода и вывода типа данных
Для входных и выходных данных ресурса данных необходимо указать параметр пути, указывающий на расположение данных. В следующей таблице показаны поддерживаемые расположения данных для Машинное обучение Azure входных и выходных данных конвейера с path примерами параметров.
| Расположение | Входные данные | Выходные данные | Пример |
|---|---|---|---|
| Путь к локальному компьютеру | ✓ | ./home/<username>/data/my_data |
|
| Путь к общедоступному серверу http/s | ✓ | https://raw.githubusercontent.com/pandas-dev/pandas/main/doc/data/titanic.csv |
|
| Путь к службе хранилища Azure | * | wasbs://<container_name>@<account_name>.blob.core.windows.net/<path>or abfss://<file_system>@<account_name>.dfs.core.windows.net/<path> |
|
| Путь к хранилищу данных Машинное обучение Azure | ✓ | ✓ | azureml://datastores/<data_store_name>/paths/<path> |
| Путь к ресурсу данных | ✓ | ✓ | azureml:my_data:<version> |
* Использование служба хранилища Azure напрямую не рекомендуется для ввода, так как для чтения данных может потребоваться дополнительная конфигурация удостоверения. Лучше использовать Машинное обучение Azure пути хранилища данных, которые поддерживаются в различных типах заданий конвейера.
Режимы ввода и вывода типа данных
Для входных и выходных данных типа данных можно выбрать несколько режимов загрузки, отправки и подключения, чтобы определить способ доступа к данным целевого объекта вычислений. В следующей таблице показаны поддерживаемые режимы для различных типов входных и выходных данных.
| Тип | upload |
download |
ro_mount |
rw_mount |
direct |
eval_download |
eval_mount |
|---|---|---|---|---|---|---|---|
uri_folder ввод |
✓ | ✓ | ✓ | ||||
uri_file ввод |
✓ | ✓ | ✓ | ||||
mltable ввод |
✓ | ✓ | ✓ | ✓ | ✓ | ||
uri_folder выпуск |
✓ | ✓ | |||||
uri_file выпуск |
✓ | ✓ | |||||
mltable выпуск |
✓ | ✓ | ✓ |
rw_mount В ro_mount большинстве случаев рекомендуется использовать режимы или режимы. Дополнительные сведения см. в разделе "Режимы".
Входные и выходные данные в графах конвейера
На странице задания конвейера в Студия машинного обучения Azure входные и выходные данные компонентов отображаются как небольшие круги, называемые портами ввода и вывода. Эти порты представляют поток данных в конвейере. Выходные данные уровня конвейера отображаются в фиолетовых полях для простой идентификации.
На следующем снимке экрана из графа конвейера регрессии данных такси Нью-Йорка показаны многие компоненты и входные данные конвейера.

При наведении указателя мыши на порт ввода и вывода отображается тип.
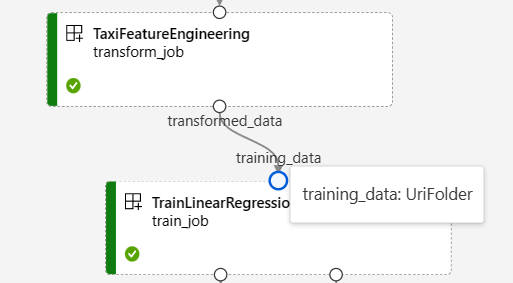
Граф конвейера не отображает примитивные входные данные типа. Эти входные данные отображаются на вкладке "Параметры" панели обзора задания конвейера для входных данных уровня конвейера или на панели компонентов для входных данных на уровне компонента. Чтобы открыть панель компонентов, дважды щелкните компонент в графе.

При редактировании конвейера в конструкторе студии входные и выходные данные конвейера находятся на панели интерфейса конвейера, а входные и выходные данные компонентов находятся на панели компонентов.
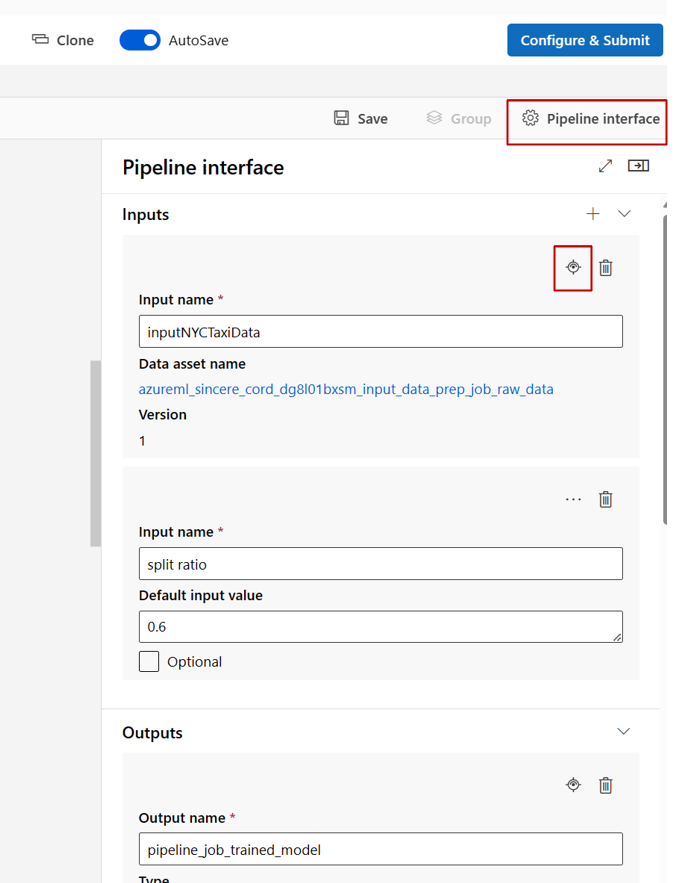
Повышение уровня входных и выходных данных компонентов на уровне конвейера
Повышение входных и выходных данных компонента на уровне конвейера позволяет перезаписать входные и выходные данные компонента при отправке задания конвейера. Эта возможность особенно полезна для активации конвейеров с помощью конечных точек REST.
В следующих примерах показано, как повысить уровень входных и выходных данных на уровне конвейера.
Следующий конвейер обеспечивает три входных и три выходных данных на уровне конвейера. Например, это входные данные уровня конвейера, pipeline_job_training_max_epocs так как он объявлен в inputs разделе на корневом уровне.
В train_job разделе имя max_epocs входных данных ссылается как ${{parent.inputs.pipeline_job_training_max_epocs}}на входные данные, что означает, что max_epocs train_jobвходные данные ссылаются на входные данные уровня pipeline_job_training_max_epocs конвейера.jobs Выходные данные конвейера повышаются с помощью той же схемы.
$schema: https://azuremlschemas.azureedge.net/latest/pipelineJob.schema.json
type: pipeline
display_name: 1b_e2e_registered_components
description: E2E dummy train-score-eval pipeline with registered components
inputs:
pipeline_job_training_max_epocs: 20
pipeline_job_training_learning_rate: 1.8
pipeline_job_learning_rate_schedule: 'time-based'
outputs:
pipeline_job_trained_model:
mode: upload
pipeline_job_scored_data:
mode: upload
pipeline_job_evaluation_report:
mode: upload
settings:
default_compute: azureml:cpu-cluster
jobs:
train_job:
type: command
component: azureml:my_train@latest
inputs:
training_data:
type: uri_folder
path: ./data
max_epocs: ${{parent.inputs.pipeline_job_training_max_epocs}}
learning_rate: ${{parent.inputs.pipeline_job_training_learning_rate}}
learning_rate_schedule: ${{parent.inputs.pipeline_job_learning_rate_schedule}}
outputs:
model_output: ${{parent.outputs.pipeline_job_trained_model}}
services:
my_vscode:
type: vs_code
my_jupyter_lab:
type: jupyter_lab
my_tensorboard:
type: tensor_board
log_dir: "outputs/tblogs"
# my_ssh:
# type: tensor_board
# ssh_public_keys: <paste the entire pub key content>
# nodes: all # Use the `nodes` property to pick which node you want to enable interactive services on. If `nodes` are not selected, by default, interactive applications are only enabled on the head node.
score_job:
type: command
component: azureml:my_score@latest
inputs:
model_input: ${{parent.jobs.train_job.outputs.model_output}}
test_data:
type: uri_folder
path: ./data
outputs:
score_output: ${{parent.outputs.pipeline_job_scored_data}}
evaluate_job:
type: command
component: azureml:my_eval@latest
inputs:
scoring_result: ${{parent.jobs.score_job.outputs.score_output}}
outputs:
eval_output: ${{parent.outputs.pipeline_job_evaluation_report}}
Полный пример можно найти в конвейере train-score-eval с зарегистрированными компонентами в репозитории Машинное обучение Azure примеров.
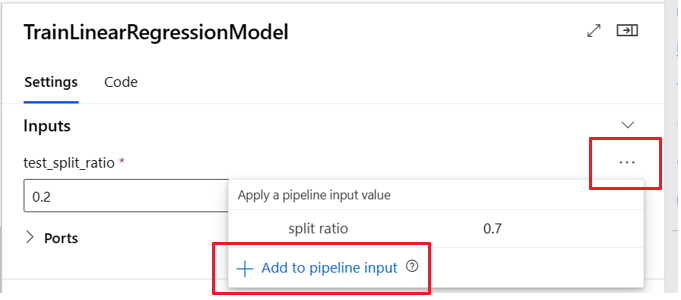
Определение необязательных входных данных
По умолчанию все входные данные являются обязательными и должны иметь значение по умолчанию или присваиваться значение при каждом отправке задания конвейера. Однако можно определить необязательные входные данные.
Примечание.
Необязательные выходные данные не поддерживаются.
Настройка необязательных входных данных может быть полезна в двух сценариях:
Если вы определяете необязательные входные данные или тип модели и не назначаете ему значение при отправке задания конвейера, компонент конвейера не имеет этой зависимости данных. Если входной порт компонента не связан с каким-либо компонентом или узлом модели или данными, конвейер вызывает компонент напрямую, а не ожидает предыдущей зависимости.
Если для конвейера задано
continue_on_step_failure = Trueзначение, ноnode2используется необходимые входные данныеnode1,node2не выполняетсяnode1при сбое. Еслиnode1входные данные являются необязательными,node2выполняется даже в случаеnode1сбоя. На следующем графике показан этот сценарий.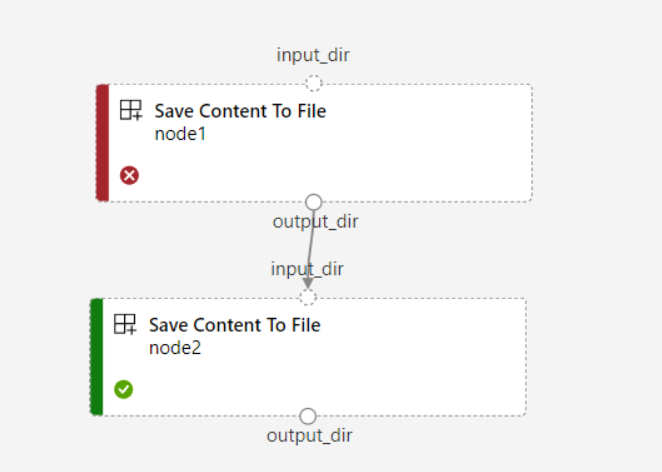
В следующем примере кода показано, как определить необязательные входные данные. Если входные данные заданы как optional = true, необходимо использовать $[[]] для использования входных данных командной строки, как в выделенных строках примера.
$schema: https://azuremlschemas.azureedge.net/latest/commandComponent.schema.json
name: train_data_component_cli
display_name: train_data
description: A example train component
tags:
author: azureml-sdk-team
type: command
inputs:
training_data:
type: uri_folder
max_epocs:
type: integer
optional: true
learning_rate:
type: number
default: 0.01
optional: true
learning_rate_schedule:
type: string
default: time-based
optional: true
outputs:
model_output:
type: uri_folder
code: ./train_src
environment: azureml://registries/azureml/environments/sklearn-1.5/labels/latest
command: >-
python train.py
--training_data ${{inputs.training_data}}
$[[--max_epocs ${{inputs.max_epocs}}]]
$[[--learning_rate ${{inputs.learning_rate}}]]
$[[--learning_rate_schedule ${{inputs.learning_rate_schedule}}]]
--model_output ${{outputs.model_output}}

Настройка путей вывода
По умолчанию выходные данные компонента хранятся в заданном {default_datastore} для конвейера azureml://datastores/${{default_datastore}}/paths/${{name}}/${{output_name}}. Если не задано, по умолчанию используется хранилище BLOB-объектов рабочей области.
Задание разрешается во время выполнения задания {name} и {output_name} является именем, определенным в компоненте YAML. Можно настроить место хранения выходных данных, определив выходной путь.
Файл pipeline.yml конвейера train-score-eval с зарегистрированными компонентами определяет конвейер с тремя выходными данными уровня конвейера. Для задания пользовательских путей вывода для pipeline_job_trained_model выходных данных можно использовать следующую команду.
# define the custom output path using datastore uri
# add relative path to your blob container after "azureml://datastores/<datastore_name>/paths"
output_path="azureml://datastores/{datastore_name}/paths/{relative_path_of_container}"
# create job and define path using --outputs.<outputname>
az ml job create -f ./pipeline.yml --set outputs.pipeline_job_trained_model.path=$output_path

Скачивание выходных данных
Выходные данные можно скачать на уровне конвейера или компонента.
Скачивание выходных данных уровня конвейера
Вы можете скачать все выходные данные задания или скачать определенные выходные данные.
# Download all the outputs of the job
az ml job download --all -n <JOB_NAME> -g <RESOURCE_GROUP_NAME> -w <WORKSPACE_NAME> --subscription <SUBSCRIPTION_ID>
# Download a specific output
az ml job download --output-name <OUTPUT_PORT_NAME> -n <JOB_NAME> -g <RESOURCE_GROUP_NAME> -w <WORKSPACE_NAME> --subscription <SUBSCRIPTION_ID>

Скачивание выходных данных компонента
Чтобы скачать выходные данные дочернего компонента, сначала перечислите все дочерние задания задания конвейера, а затем используйте аналогичный код для скачивания выходных данных.
# List all child jobs in the job and print job details in table format
az ml job list --parent-job-name <JOB_NAME> -g <RESOURCE_GROUP_NAME> -w <WORKSPACE_NAME> --subscription <SUBSCRIPTION_ID> -o table
# Select the desired child job name to download output
az ml job download --all -n <JOB_NAME> -g <RESOURCE_GROUP_NAME> -w <WORKSPACE_NAME> --subscription <SUBSCRIPTION_ID>
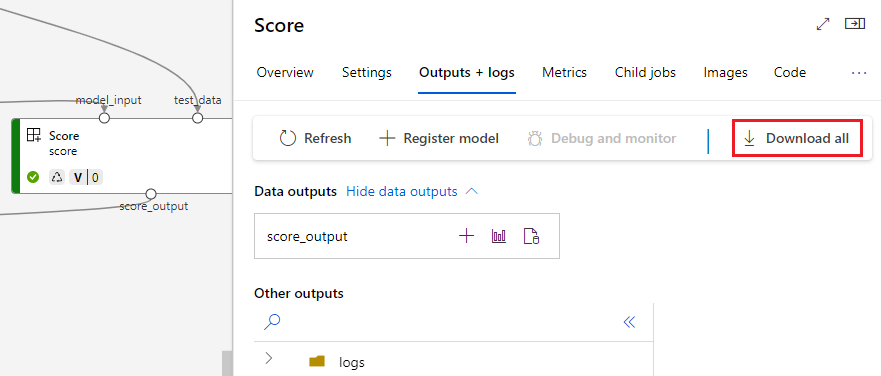
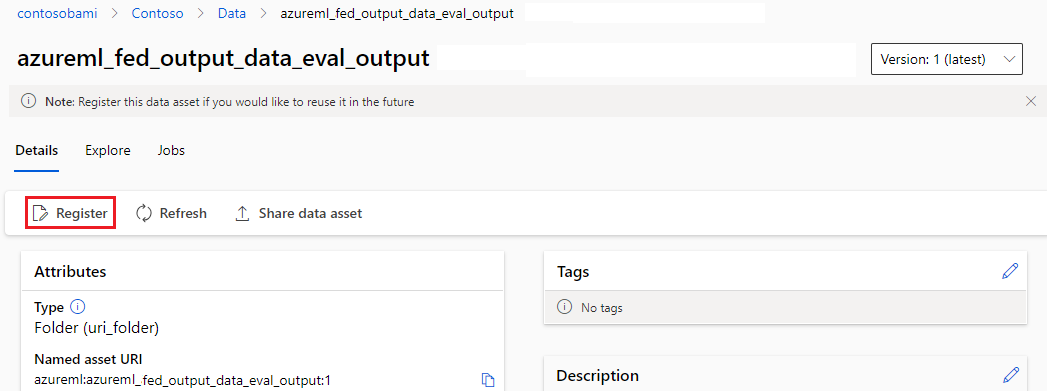
Регистрация выходных данных в качестве именованного ресурса
Вы можете зарегистрировать выходные данные компонента или конвейера в качестве именованного ресурса, назначив name и version выходные данные. Зарегистрированный ресурс можно перечислить в рабочей области с помощью пользовательского интерфейса студии, интерфейса командной строки или пакета SDK и ссылаться на нее в будущих заданиях рабочей области.
Регистрация выходных данных уровня конвейера
display_name: register_pipeline_output
type: pipeline
jobs:
node:
type: command
inputs:
component_in_path:
type: uri_file
path: https://dprepdata.blob.core.windows.net/demo/Titanic.csv
component: ../components/helloworld_component.yml
outputs:
component_out_path: ${{parent.outputs.component_out_path}}
outputs:
component_out_path:
type: mltable
name: pipeline_output # Define name and version to register pipeline output
version: '1'
settings:
default_compute: azureml:cpu-cluster
Регистрация выходных данных компонента
display_name: register_node_output
type: pipeline
jobs:
node:
type: command
component: ../components/helloworld_component.yml
inputs:
component_in_path:
type: uri_file
path: 'https://dprepdata.blob.core.windows.net/demo/Titanic.csv'
outputs:
component_out_path:
type: uri_folder
name: 'node_output' # Define name and version to register a child job's output
version: '1'
settings:
default_compute: azureml:cpu-cluster