Обработка данных с помощью пулов Apache Spark (не рекомендуется)
ОБЛАСТЬ ПРИМЕНЕНИЯ: Пакет SDK для Python версии 1
Пакет SDK для Python версии 1
Предупреждение
Интеграция Azure Synapse Analytics с Машинное обучение Azure, доступная в пакете SDK для Python версии 1, устарела. Пользователи по-прежнему могут использовать рабочую область Synapse, зарегистрированную в Машинное обучение Azure, в качестве связанной службы. Однако новую рабочую область Synapse больше нельзя зарегистрировать в Машинном обучении Azure в качестве связанной службы. Мы рекомендуем использовать бессерверные вычислительные ресурсы Spark и подключенные пулы Synapse Spark, доступные в CLI версии 2 и пакете SDK Для Python версии 2. Дополнительные сведения см. на странице https://aka.ms/aml-spark.
В этой статье вы узнаете, как интерактивно выполнять задачи обработки данных в выделенном сеансе Synapse, на базе Azure Synapse Analytics, в записной книжке Jupyter. Эти задачи зависят от пакета SDK для Python Машинное обучение Azure. Дополнительные сведения о конвейерах Машинное обучение Azure см. в статье "Как использовать Apache Spark (на базе Azure Synapse Analytics) в конвейере машинного обучения (предварительная версия)". Дополнительные сведения об использовании Azure Synapse Analytics с рабочей областью Synapse см. в серии начала работы Azure Synapse Analytics.
Машинное обучение Azure и интеграция Azure Synapse Analytics
Интеграция Azure Synapse Analytics с Машинное обучение Azure (предварительная версия) позволяет подключить пул Apache Spark, поддерживаемый Azure Synapse, для интерактивного изучения и подготовки данных. Благодаря этой интеграции вы можете иметь выделенный вычислительный ресурс для обработки данных в масштабе, все в одной записной книжке Python, используемой для обучения моделей машинного обучения.
Необходимые компоненты
Подготовьте среду разработки к установке пакета SDK для Машинного обучения Azure или используйте вычислительный экземпляр Машинного обучения Azure с уже установленным пакетом SDK.
Создание пула Apache Spark с помощью портал Azure, веб-инструментов или Synapse Studio
azureml-synapseУстановите пакет (предварительная версия) с помощью этого кода:pip install azureml-synapseСвязывание рабочей области Машинное обучение Azure с рабочей областью Azure Synapse Analytics с помощью пакета SDK для Python Машинное обучение Azure или Студия машинного обучения Azure
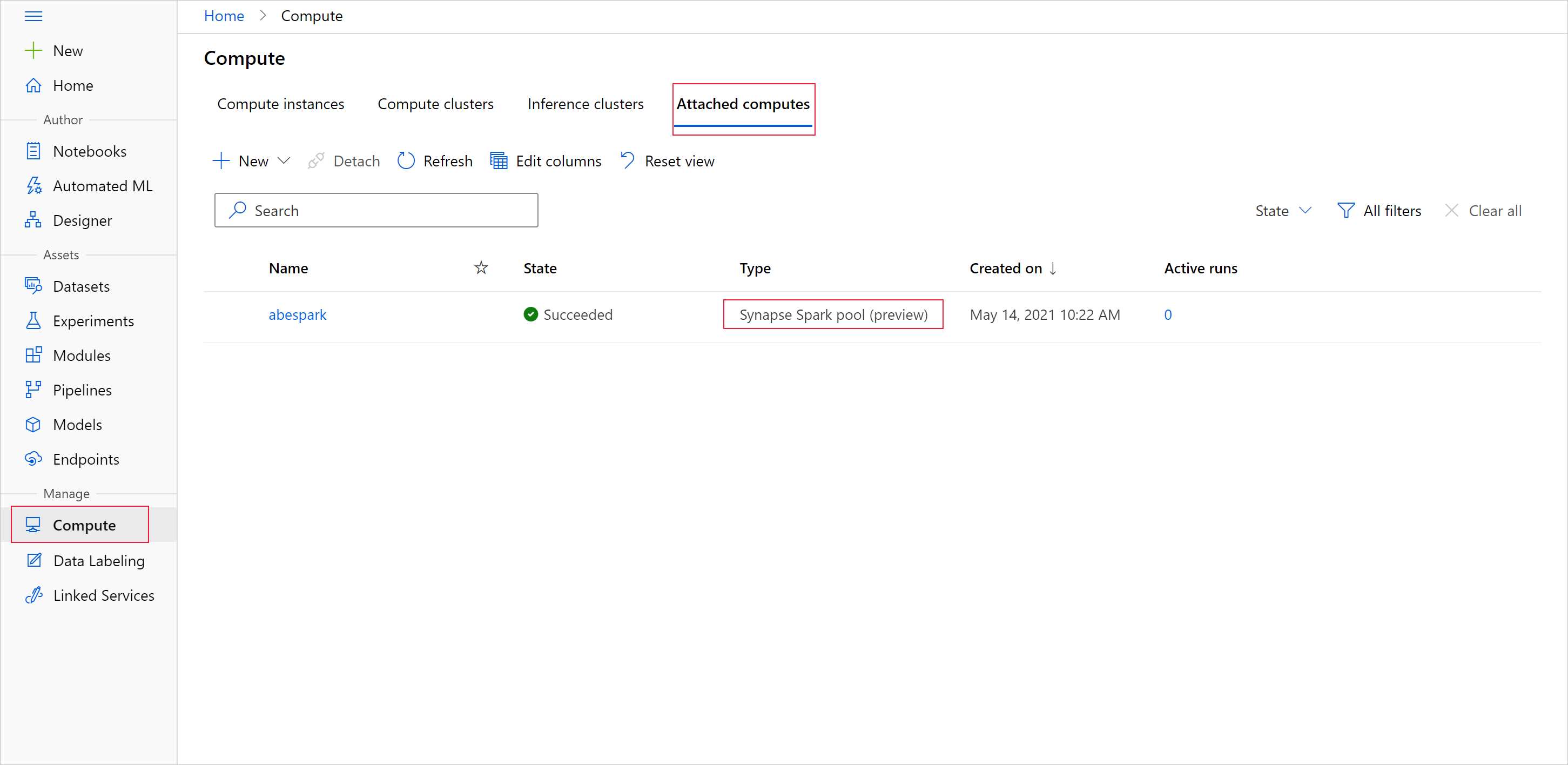
Подключение пула Synapse Spark в качестве целевого объекта вычислений
Запуск пула Spark Synapse для задач первичной обработки данных
Чтобы начать подготовку данных с пулом Apache Spark, укажите присоединенное имя вычислений Spark Synapse. Это имя можно найти с помощью Студия машинного обучения Azure на вкладке "Подключенные вычисления".
Внимание
Чтобы продолжить использование пула Apache Spark, необходимо указать, какой вычислительный ресурс следует использовать во всех задачах обработки данных. Используйте %synapse для отдельных строк кода и %%synapse для нескольких строк:
%synapse start -c SynapseSparkPoolAlias
После запуска сеанса можно проверить метаданные сеанса:
%synapse meta
Вы можете указать среду машинного обучения Azure, которая будет использоваться во время сеанса Apache Spark. Вступят в силу будут только зависимости Conda, указанные в среде. Образы Docker не поддерживаются.
Предупреждение
Зависимости Python, указанные в зависимостях Conda окружения, не поддерживаются в пулах Apache Spark. В настоящее время поддерживаются только фиксированные версии Python, sys.version_info чтобы проверить версию Python в скрипте.
Этот код создаетmyenv переменную среды, чтобы установить azureml-core версию 1.20.0 и numpy версию 1.17.0 перед началом сеанса. Эту среду позднее можно включить в выражение start сеанса Apache Spark.
from azureml.core import Workspace, Environment
# creates environment with numpy and azureml-core dependencies
ws = Workspace.from_config()
env = Environment(name="myenv")
env.python.conda_dependencies.add_pip_package("azureml-core==1.20.0")
env.python.conda_dependencies.add_conda_package("numpy==1.17.0")
env.register(workspace=ws)
Чтобы начать подготовку данных с пулом Apache Spark в пользовательской среде, укажите имя пула Apache Spark и среду для использования во время сеанса Apache Spark. Вы можете указать идентификатор подписки, группу ресурсов рабочей области машинного обучения и имя рабочей области машинного обучения.
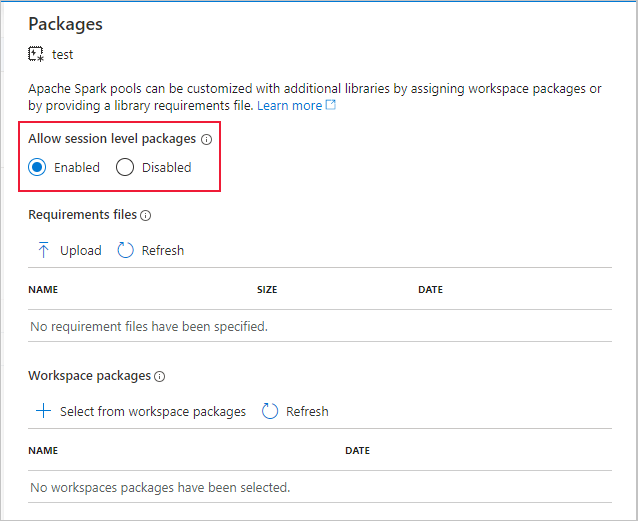
%synapse start -c SynapseSparkPoolAlias -e myenv -s AzureMLworkspaceSubscriptionID -r AzureMLworkspaceResourceGroupName -w AzureMLworkspaceName
Загрузка данных из хранилища
После запуска сеанса Apache Spark прочитайте данные, которые вы хотите подготовить. Загрузка данных поддерживается в хранилище BLOB-объектов Azure и Azure Data Lake Storage 1-го и 2-го поколений.
У вас есть два варианта загрузки данных из этих служб хранилища:
Прямая загрузка данных из хранилища с помощью пути к распределенной файловой системе Hadoop (HDFS)
Чтение данных из существующего набора данных Машинное обучение Azure
Для доступа к этим службам хранилища требуются разрешения читателя данных BLOB-объекта хранилища. Чтобы записать данные обратно в эти службы хранилища, требуется разрешение участника данных BLOB-объектов хранилища. Узнайте больше о разрешениях хранилища и ролях.
Загрузка данных с помощью пути к распределенным файлам Hadoop (HDFS)
Чтобы загрузить и считывать данные из хранилища с соответствующим путем HDFS, вам потребуются учетные данные проверки подлинности доступа к данным. Эти учетные данные различаются в зависимости от типа хранилища. В этом примере кода показано, как считывать данные из хранилища BLOB-объектов Azure в кадр данных Spark с помощью маркера подписанного URL-адреса (SAS) или ключа доступа:
%%synapse
# setup access key or SAS token
sc._jsc.hadoopConfiguration().set("fs.azure.account.key.<storage account name>.blob.core.windows.net", "<access key>")
sc._jsc.hadoopConfiguration().set("fs.azure.sas.<container name>.<storage account name>.blob.core.windows.net", "<sas token>")
# read from blob
df = spark.read.option("header", "true").csv("wasbs://demo@dprepdata.blob.core.windows.net/Titanic.csv")
В этом примере кода показано, как считывать данные из Azure Data Lake Storage поколения 1 (ADLS 1-го поколения) с учетными данными субъекта-службы:
%%synapse
# setup service principal which has access of the data
sc._jsc.hadoopConfiguration().set("fs.adl.account.<storage account name>.oauth2.access.token.provider.type","ClientCredential")
sc._jsc.hadoopConfiguration().set("fs.adl.account.<storage account name>.oauth2.client.id", "<client id>")
sc._jsc.hadoopConfiguration().set("fs.adl.account.<storage account name>.oauth2.credential", "<client secret>")
sc._jsc.hadoopConfiguration().set("fs.adl.account.<storage account name>.oauth2.refresh.url",
"https://login.microsoftonline.com/<tenant id>/oauth2/token")
df = spark.read.csv("adl://<storage account name>.azuredatalakestore.net/<path>")
В этом примере кода показано, как считывать данные из Azure Data Lake Storage 2-го поколения (ADLS 2-го поколения) с учетными данными субъекта-службы:
%%synapse
# setup service principal which has access of the data
sc._jsc.hadoopConfiguration().set("fs.azure.account.auth.type.<storage account name>.dfs.core.windows.net","OAuth")
sc._jsc.hadoopConfiguration().set("fs.azure.account.oauth.provider.type.<storage account name>.dfs.core.windows.net", "org.apache.hadoop.fs.azurebfs.oauth2.ClientCredsTokenProvider")
sc._jsc.hadoopConfiguration().set("fs.azure.account.oauth2.client.id.<storage account name>.dfs.core.windows.net", "<client id>")
sc._jsc.hadoopConfiguration().set("fs.azure.account.oauth2.client.secret.<storage account name>.dfs.core.windows.net", "<client secret>")
sc._jsc.hadoopConfiguration().set("fs.azure.account.oauth2.client.endpoint.<storage account name>.dfs.core.windows.net",
"https://login.microsoftonline.com/<tenant id>/oauth2/token")
df = spark.read.csv("abfss://<container name>@<storage account>.dfs.core.windows.net/<path>")
Считывание данных из зарегистрированных наборов данных
Вы также можете разместить существующий зарегистрированный набор данных в рабочей области и выполнить подготовку данных, если преобразовать его в кадр данных Spark. В этом примере выполняется проверка подлинности в рабочей области, получение зарегистрированного табличного набора данных,blob_dset которое ссылается на файлы в хранилище BLOB-объектов и преобразует этот табличный набор данных в кадр данных Spark. При преобразовании наборов данных в кадры данных Spark можно использовать pyspark библиотеки для изучения и подготовки данных.
%%synapse
from azureml.core import Workspace, Dataset
subscription_id = "<enter your subscription ID>"
resource_group = "<enter your resource group>"
workspace_name = "<enter your workspace name>"
ws = Workspace(workspace_name = workspace_name,
subscription_id = subscription_id,
resource_group = resource_group)
dset = Dataset.get_by_name(ws, "blob_dset")
spark_df = dset.to_spark_dataframe()
Выполнение задач первичной обработки данных
После получения и изучения данных можно выполнять задачи обработки данных. Этот пример кода расширяется на примере HDFS в предыдущем разделе. На основе столбца "Выживший" он фильтрует данные в кадре df данных Spark и группах, которые перечислены по возрасту:
%%synapse
from pyspark.sql.functions import col, desc
df.filter(col('Survived') == 1).groupBy('Age').count().orderBy(desc('count')).show(10)
df.show()
Сохранение данных в хранилище и завершение сеанса Spark
После завершения изучения и подготовки данных сохраните подготовленные данные для последующего использования в учетной записи хранения в Azure. В этом примере кода подготовленные данные записываются обратно в хранилище BLOB-объектов Azure, перезаписав исходный Titanic.csv файл в каталоге training_data . Для записи обратно в хранилище требуются разрешения участника данных BLOB-объекта хранилища. Дополнительные сведения см. в статье "Назначение роли Azure для доступа к данным BLOB-объектов".
%% synapse
df.write.format("csv").mode("overwrite").save("wasbs://demo@dprepdata.blob.core.windows.net/training_data/Titanic.csv")
После завершения подготовки данных и сохранения подготовленных данных в хранилище завершите использование пула Apache Spark с помощью этой команды:
%synapse stop
Создание набора данных для представления подготовленных данных
Когда вы будете готовы использовать подготовленные данные для обучения модели, подключитесь к хранилищу с Машинное обучение Azure хранилищем данных и укажите файл или файл, который вы хотите использовать с набором данных Машинное обучение Azure.
Этот пример кода
- Предполагается, что вы уже создали хранилище данных, которое подключается к службе хранилища, в которой вы сохранили подготовленные данные.
- Извлекает существующее хранилище данных из
mydatastoreрабочей областиwsс помощью метода get(). - Создает FileDataset, чтобы ссылаться на подготовленные файлы данных,
train_dsрасположенные в каталогеmydatastoretraining_data. - Создает переменную
input1. В дальнейшем эта переменная может сделать файлы данных набора данных доступными для целевогоtrain_dsобъекта вычислений для задач обучения.
from azureml.core import Datastore, Dataset
datastore = Datastore.get(ws, datastore_name='mydatastore')
datastore_paths = [(datastore, '/training_data/')]
train_ds = Dataset.File.from_files(path=datastore_paths, validate=True)
input1 = train_ds.as_mount()
Использование ScriptRunConfig для отправки экспериментального запуска в пул Synapse Spark
Если вы готовы автоматизировать и запустить в производство задачи первичной обработки данных, можно отправить экспериментальный запуск в подключенный пул Synapse Spark с помощью объекта ScriptRunConfig. Аналогичным образом, если у вас есть конвейер Машинное обучение Azure, можно использовать SynapseSparkStep, чтобы указать пул Synapse Spark в качестве целевого объекта вычислений для этапа подготовки данных в конвейере. Доступность данных в пуле Synapse Spark зависит от типа набора данных.
- Для FileDataset можно использовать метод
as_hdfs(). При отправке запуска набор данных становится доступным для пула Synapse Spark в виде распределенной файловой системы Hadoop (HFDS) - Для TabularDataset можно использовать
as_named_input()метод.
Следующий пример кода
- Создает переменную
input2из FileDatasettrain_ds, созданную в предыдущем примере кода. - Создает переменную
outputс классомHDFSOutputDatasetConfiguration. После завершения выполнения этот класс позволяет сохранять выходные данные запуска в качестве набораtestданных вmydatastoreхранилище данных. В рабочей областиtestМашинное обучение Azure набор данных регистрируется под именем.registered_dataset - Настраивает параметры запуска, которые следует использовать для выполнения в пуле Synapse Spark
- Определяет параметры ScriptRunConfig для
- Использование скрипта
dataprep.pyдля выполнения - Укажите данные, используемые в качестве входных данных, и как сделать эти данные доступными для пула Synapse Spark
- Укажите место хранения выходных
outputданных
- Использование скрипта
from azureml.core import Dataset, HDFSOutputDatasetConfig
from azureml.core.environment import CondaDependencies
from azureml.core import RunConfiguration
from azureml.core import ScriptRunConfig
from azureml.core import Experiment
input2 = train_ds.as_hdfs()
output = HDFSOutputDatasetConfig(destination=(datastore, "test").register_on_complete(name="registered_dataset")
run_config = RunConfiguration(framework="pyspark")
run_config.target = synapse_compute_name
run_config.spark.configuration["spark.driver.memory"] = "1g"
run_config.spark.configuration["spark.driver.cores"] = 2
run_config.spark.configuration["spark.executor.memory"] = "1g"
run_config.spark.configuration["spark.executor.cores"] = 1
run_config.spark.configuration["spark.executor.instances"] = 1
conda_dep = CondaDependencies()
conda_dep.add_pip_package("azureml-core==1.20.0")
run_config.environment.python.conda_dependencies = conda_dep
script_run_config = ScriptRunConfig(source_directory = './code',
script= 'dataprep.py',
arguments = ["--file_input", input2,
"--output_dir", output],
run_config = run_config)
Дополнительные сведения о конфигурации Spark и общие сведения см. в run_config.spark.configuration документации по настройке SparkConfiguration Class и Apache Spark.
После настройки ScriptRunConfig объекта можно отправить запуск.
from azureml.core import Experiment
exp = Experiment(workspace=ws, name="synapse-spark")
run = exp.submit(config=script_run_config)
run
Дополнительные сведения, включая сведения о скрипте, используемом dataprep.py в этом примере, см. в примере записной книжки.
После подготовки данных его можно использовать в качестве входных данных для заданий обучения. В приведенном выше примере кода необходимо указать registered_dataset входные данные для заданий обучения.
Примеры записных книжек
Ознакомьтесь с этими примерами записных книжек для получения дополнительных концепций и демонстраций возможностей интеграции Azure Synapse Analytics и Машинное обучение Azure:
- Запустите интерактивный сеанс Spark из записной книжки в рабочей области Машинного обучения Azure.
- Отправьте экспериментальный запуск Машинного обучения Azure с пулом Synapse Spark в качестве целевого объекта вычислений.
Следующие шаги
- Train a model (Обучение модели).
- Обучение с помощью набора данных Машинного обучения Azure