Настройка AutoML для обучения моделей компьютерного зрения с помощью Python (версия 1)
ОБЛАСТЬ ПРИМЕНЕНИЯ: Пакет SDK для Python версии 1
Пакет SDK для Python версии 1
Внимание
Для использования некоторых команд Azure CLI, приведенных в этой статье, используйте расширение azure-cli-ml (версия 1) для Машинного обучения Azure. Поддержка расширения версии 1 будет прекращена 30 сентября 2025 г. Вы можете установить и использовать расширение версии 1 до этой даты.
Рекомендуется перейти на расширение ml (версия 2) до 30 сентября 2025 г. Дополнительные сведения о расширении версии 2 см. на странице расширения CLI для Azure ML и пакета SDK для Python версии 2.
Внимание
Эта функция сейчас доступна в виде общедоступной предварительной версии. Эта предварительная версия предоставляется без соглашения об уровне обслуживания. Некоторые функции могут не поддерживаться или их возможности могут быть ограничены. Дополнительные сведения см. в статье Дополнительные условия использования Предварительных версий Microsoft Azure.
В этой статье вы научитесь обучать модели компьютерного зрения на данных изображений с помощью автоматизированного машинного обучения в пакете SDK Python для Машинного обучения Azure.
Автоматизированное машинное обучение поддерживает обучение моделей для задач компьютерного зрения, например для классификация изображений, обнаружения объектов и сегментации экземпляров. Создание моделей AutoML для задач компьютерного зрения в настоящее время поддерживается на основе пакета SDK Машинного обучения Azure для Python. Доступ к результатам экспериментальных запусков, моделям и выходным данным можно получить из пользовательского интерфейса Студии машинного обучения Azure. Дополнительные сведения об автоматизированном машинном обучении для задач компьютерного зрения на данных изображений.
Примечание.
Автоматизированное машинное обучение для задач компьютерного зрения доступны только через пакет SDK Python для Машинного обучения Azure.
Необходимые компоненты
Рабочая область Машинного обучения Azure. Сведения о создании рабочей области см. в разделе Создание ресурсов рабочей области.
Установленный пакет SDK Python для Машинного обучения Azure. Чтобы установить пакет SDK:
Создайте вычислительный экземпляр, предварительно настроенный для рабочих процессов ML, который автоматически устанавливает пакет SDK. Дополнительные сведения см. в статье Создание вычислительного экземпляра для Машинного обучения Azure и управление им.
Установите пакет
automlсамостоятельно, следуя инструкции по установке пакета SDK по умолчанию.
Примечание.
Только Python 3.7 и 3.8 совместимы с автоматизированной поддержкой машинного обучения для задач компьютерного зрения.
Выберите тип задачи
Автоматизированное машинное обучение для изображений поддерживает следующие типы задач:
| Тип задачи | Синтаксис конфигурации изображений в AutoML |
|---|---|
| классификация изображений. | ImageTask.IMAGE_CLASSIFICATION |
| классификация изображений с несколькими метками | ImageTask.IMAGE_CLASSIFICATION_MULTILABEL |
| обнаружение объектов изображений | ImageTask.IMAGE_OBJECT_DETECTION |
| сегментация экземпляров изображений | ImageTask.IMAGE_INSTANCE_SEGMENTATION |
Этот тип задачи является обязательным и передается с помощью параметра task в AutoMLImageConfig.
Например:
from azureml.train.automl import AutoMLImageConfig
from azureml.automl.core.shared.constants import ImageTask
automl_image_config = AutoMLImageConfig(task=ImageTask.IMAGE_OBJECT_DETECTION)
Данные для обучения и проверки
Чтобы создавать модели компьютерного зрения с помощью автоматизированного машинного обучения, необходимо добавить помеченные данные изображений в качестве входных данных для обучения модели в виде Табличного набора данных Машинного обучения Azure. Можно использовать либо TabularDataset, экспортированный из проекта маркировки данных, либо создать новый TabularDataset с помеченными данными для обучения.
Если данные обучения имеют другой формат (например, pascal VOC или COCO), можно применить вспомогательные скрипты, входящие в пример записных книжек, чтобы преобразовать данные в JSONL. Дополнительные сведения о подготовке данных для задач компьютерного зрения с помощью автоматизированного машинного обучения.
Предупреждение
Для этой возможности создание TabularDatasets на основе данных в формате JSONL поддерживается только с использованием пакета SDK. Создание набора данных посредством пользовательского интерфейса в настоящее время не поддерживается. Сейчас пользовательский интерфейс не распознает тип данных StreamInfo, который используется для URL-адресов изображений в формате JSON.
Примечание.
Набор данных для обучения должен иметь по крайней мере 10 образовй, чтобы иметь возможность отправить запуск AutoML.
Примеры схемы JSONL
Структура Табличных наборов данных зависит от поставленной задачи. Для типов задач компьютерного зрения она состоит из следующих полей:
| Поле | Description |
|---|---|
image_url |
Содержит путь к файлу в виде объекта StreamInfo |
image_details |
Сведения о метаданных изображения включают высоту, ширину и формат. Это поле является необязательным, поэтому оно может существовать или не существовать. |
label |
Представление JSON метки изображения на основе типа задачи. |
Ниже приведен пример файла JSONL для классификации изображений:
{
"image_url": "AmlDatastore://image_data/Image_01.png",
"image_details":
{
"format": "png",
"width": "2230px",
"height": "4356px"
},
"label": "cat"
}
{
"image_url": "AmlDatastore://image_data/Image_02.jpeg",
"image_details":
{
"format": "jpeg",
"width": "3456px",
"height": "3467px"
},
"label": "dog"
}
Нижеприведенный код представляет собой пример файла JSONL для классификации объектов:
{
"image_url": "AmlDatastore://image_data/Image_01.png",
"image_details":
{
"format": "png",
"width": "2230px",
"height": "4356px"
},
"label":
{
"label": "cat",
"topX": "1",
"topY": "0",
"bottomX": "0",
"bottomY": "1",
"isCrowd": "true",
}
}
{
"image_url": "AmlDatastore://image_data/Image_02.png",
"image_details":
{
"format": "jpeg",
"width": "1230px",
"height": "2356px"
},
"label":
{
"label": "dog",
"topX": "0",
"topY": "1",
"bottomX": "0",
"bottomY": "1",
"isCrowd": "false",
}
}
Использование данных
Когда данные стали доступны в формате JSONL, можно создать Табличный набор данных с помощью следующего кода:
ws = Workspace.from_config()
ds = ws.get_default_datastore()
from azureml.core import Dataset
training_dataset = Dataset.Tabular.from_json_lines_files(
path=ds.path('odFridgeObjects/odFridgeObjects.jsonl'),
set_column_types={'image_url': DataType.to_stream(ds.workspace)})
training_dataset = training_dataset.register(workspace=ws, name=training_dataset_name)
Автоматизированное машинное обучение не накладывают ограничений на размер данных для обучения или проверки для задач компьютерного зрения. Максимальный размер набора данных ограничен уровнем хранилища за набором данных (т. е. хранилище больших двоичных объектов). Минимального количества изображений или меток не существует. Однако рекомендуется начинать с минимального количества в 10–15 примеров на метку, чтобы обеспечить достаточную обученную выходную модель. Чем больше общее количество меток и классов, тем больше примеров потребуется для каждой метки.
Данные обучения являются обязательными и передаются с помощью параметра training_data. При необходимости можно указать другой Табличный набор данных в качестве набора данных для проверки, который будет использоваться для модели с параметром validation_data для AutoMLImageConfig. Если проверочный набор данных не указан, по умолчанию будет использоваться 20% данных обучения для проверки, если не передать аргумент validation_size с другим значением.
Например:
from azureml.train.automl import AutoMLImageConfig
automl_image_config = AutoMLImageConfig(training_data=training_dataset)
Вычисление для запуска эксперимента
Предоставьте целевой объект вычислений для автоматизированного машинного обучения, чтобы провести обучение модели. Модели автоматизированного машинного обучения для задач компьютерного зрения нуждаются в SKU GPU и поддерживают семейства NC и ND. Для ускорения обучения мы рекомендуем использовать серию NCsv3 (с GPU версии 100). Целевой объект вычислений с SKU виртуальной машины с несколькими GPU использует несколько GPU, что также ускоряет обучение. Кроме того, при настройке целевого объекта вычислений с несколькими узлами можно ускорить обучение модели с помощью параллелизма при настройке гиперпараметров для модели.
Примечание.
Если вы используете вычислительный экземпляр в качестве целевого объекта вычислений, убедитесь, что одновременно несколько заданий AutoML не выполняются. Кроме того, убедитесь, что max_concurrent_iterations в ресурсах эксперимента задано значение 1.
Целевой объект вычислений является обязательным параметром и передается с помощью параметра compute_target для AutoMLImageConfig. Например:
from azureml.train.automl import AutoMLImageConfig
automl_image_config = AutoMLImageConfig(compute_target=compute_target)
Настройка алгоритмов модели и гиперпараметров
Благодаря поддержке задач компьютерного зрения можно управлять алгоритмом модели и гиперпараметрами sweep. Эти алгоритмы модели и гиперпараметры передаются в качестве пространства параметров для очистки.
Алгоритм модели является обязательным и передается через параметр model_name. Можно указать один model_name или выбрать из нескольких.
Поддерживаемые алгоритмы модели
В следующей таблице перечислены поддерживаемые модели для каждой задачи компьютерного зрения.
| Задача | Алгоритмы модели | Синтаксис строкового литералаdefault_model* обозначено звездочкой * |
|---|---|---|
| Классификация изображений (несколько классов и несколько меток) |
MobileNet: легкие модели для мобильных приложений ResNet: остаточные сети ResNeSt: сети разделенного внимания SE-ResNeXt50: сети сжатия и возбуждения ViT: сети преобразователя зрения |
mobilenetv2 resnet18 resnet34 resnet50 resnet101 resnet152 resnest50 resnest101 seresnext vits16r224 (небольшой) vitb16r224* (базовая) vitl16r224 (крупный) |
| Обнаружение объектов | YOLOv5: одна модель обнаружения объектов этапа Более быстрая версия RCNN ResNet FPN: две модели обнаружения объектов этапа RetinaNet ResNet FPN: дисбаланс класса адресов с фокусом потери Примечание: см. model_sizeгиперпараметр для размеров модели YOLOv5. |
yolov5* fasterrcnn_resnet18_fpn fasterrcnn_resnet34_fpn fasterrcnn_resnet50_fpn fasterrcnn_resnet101_fpn fasterrcnn_resnet152_fpn retinanet_resnet50_fpn |
| Сегментация экземпляров | MaskRCNN ResNet FPN | maskrcnn_resnet18_fpn maskrcnn_resnet34_fpn maskrcnn_resnet50_fpn* maskrcnn_resnet101_fpn maskrcnn_resnet152_fpn maskrcnn_resnet50_fpn |
В дополнение к управлению алгоритмом модели можно также настроить гиперпараметры, используемые для обучения модели. Хотя многие из показанных гиперпараметров не зависят от модели, существуют экземпляры, в которых гиперпараметры зависят от конкретной задачи или конкретной модели. Дополнительные сведения о доступных гиперпараметрах для этих экземпляров.
Дополнение данных
Как правило, производительность модели глубокого обучения часто можно повысить за счет дополнительных данных. Расширение данных — это практический метод для повышения размера и изменчивости набора данных, который помогает предотвратить переполнение и повысить общую способность модели к невидимым данным. Автоматизированное машинное обучение применяет различные методы приращения данных на основе задачи компьютерного зрения, прежде чем передать входные изображения в модель. В настоящее время отсутствует видимый гиперпараметр для управления приращениями данных.
| Задача | Затронутый набор данных | Примененные методики приращения данных |
|---|---|---|
| Классификации изображений (с несколькими классами и с несколькими метками) | Обучение Проверка и проверка |
Случайное изменение размера и обрезка, горизонтальное переворачивание, изменение цвета (яркость, контрастность, насыщенность и оттенок), нормализация с использованием среднего и стандартного отклонения ImageNet с помощью среднего и стандартного отклонения ImageNet Изменение размера, обрезка по центру, нормализация |
| Обнаружение объектов, сегментация экземпляров | Обучение Проверка и проверка |
Случайное обрезка вокруг ограничивающих прямоугольник, развертывание, горизонтальное перевернутое, нормализация, изменение размера Нормализация, изменение размера |
| Обнаружение объектов с использованием yolov5 | Обучение Проверка и проверка |
Мозаика, случайные аффины (поворот, перевод, масштабирование, стриж), горизонтальный перевернутый Изменение размера киноформата "Letterbox" |
Настройка параметров эксперимента
Перед выполнением большой очистки для поиска оптимальных моделей и гиперпараметров рекомендуется использовать значения по умолчанию, чтобы получить первые базовые показатели. Далее можно изучить несколько гиперпараметров для одной и той же модели, прежде чем приступать к нескольким моделями и их параметрами. Таким образом, можно использовать более итеративный подход, поскольку при использовании нескольких моделей и нескольких гиперпараметров для каждого из них размер области поиска растет экспоненциально, а для поиска оптимальных конфигураций требуется больше итераций.
Если вы хотите использовать значения гиперпараметров по умолчанию для заданного алгоритма (скажем, yolov5), можно указать конфигурацию для образа AutoML, как показано ниже:
from azureml.train.automl import AutoMLImageConfig
from azureml.train.hyperdrive import GridParameterSampling, choice
from azureml.automl.core.shared.constants import ImageTask
automl_image_config_yolov5 = AutoMLImageConfig(task=ImageTask.IMAGE_OBJECT_DETECTION,
compute_target=compute_target,
training_data=training_dataset,
validation_data=validation_dataset,
hyperparameter_sampling=GridParameterSampling({'model_name': choice('yolov5')}),
iterations=1)
После построения базовой модели может потребоваться оптимизировать производительность модели, чтобы обработать алгоритм модели и пространство параметров. Следующий пример конфигурации можно использовать для очистки гиперпараметров для каждого алгоритма, выбрав из диапазона значений для learning_rate, оптимизатора, lr_scheduler и т. д., чтобы создать модель с оптимальной основной метрикой. Если значения гиперпараметров не указаны, для указанного алгоритма используются значения по умолчанию.
Основная метрика
Основная метрика, используемая для оптимизации модели и настройки гиперпараметров, зависит от типа задачи. Использование других значений первичной метрики сейчас не поддерживается.
accuracyдля IMAGE_CLASSIFICATIONiouдля IMAGE_CLASSIFICATION_MULTILABELmean_average_precisionдля IMAGE_OBJECT_DETECTIONmean_average_precisionдля IMAGE_INSTANCE_SEGMENTATION
Бюджет эксперимента
При необходимости можно указать максимальный бюджет времени для службы зрения AutoML, используя experiment_timeout_hours — количество времени в часах до завершения эксперимента. Если значение не указано, время ожидания эксперимента по умолчанию составляет семь дней (максимум 60 дней).
Очистка гиперпараметров модели
При обучении моделей компьютерного зрения производительность модели в значительной степени зависит от выбранных значений гиперпараметров. Часто может потребоваться настроить гиперпараметры, чтобы добиться оптимальной производительности. Благодаря поддержке задач компьютерного зрения в автоматизированном машинном обучении можно очистить гиперпараметры, чтобы найти оптимальные параметры для модели. Эта функция применяет возможности настройки гиперпараметров в Машинном обучении Azure. Инструкции по настройке гиперпараметров.
определение пространства поиска параметров;
Можно определить алгоритмы модели и гиперпараметры, чтобы очистить пространство параметров.
- Список поддерживаемых алгоритмов модели для каждого типа задач см. в разделе Настройка алгоритмов модели и гиперпараметров.
- См. гиперпараметры для каждого типа задач компьютерного зрения в разделе Гиперпараметры для задач компьютерного зрения.
- См. дополнительные сведения о поддерживаемых дистрибутивах для дискретных и непрерывных гиперпараметров.
Методы выборки для очистки
При очистке гиперпараметров необходимо указать метод выборки, используемый для очистки заданного пространства параметров. Сейчас поддерживаются следующие методы выборки с параметром hyperparameter_sampling:
Примечание.
В настоящее время только случайные выборки и выборка сетки поддерживают условные пространства гиперпараметров.
Политика преждевременного завершения
Вы можете автоматически завершать плохо работающие запуски в рамках политики досрочного завершения. Досрочное завершение позволяет повысить вычислительную эффективность с экономией вычислительных ресурсов, которые в противном случае были бы потрачены на менее удачные конфигурации. Автоматизированное ML для изображений поддерживают следующую политику досрочного завершения с помощью параметра early_termination_policy. Если политика завершения не указана, все конфигурации выполняются до полного завершения.
Дополнительные сведения о настройке политики досрочного завершения для очистки гиперпараметров.
Ресурсы для очистки
Вы можете контролировать ресурсы, затраченные на очистку гиперпараметров путем указания iterations и max_concurrent_iterations для очистки.
| Параметр | Подробности |
|---|---|
iterations |
Обязательный параметр для максимального количества конфигураций для очистки. Требуется целое число от 1 до 1000. При изучении только гиперпараметров по умолчанию для заданного алгоритма модели присвойте этому параметру значение 1. |
max_concurrent_iterations |
Максимальное количество запусков, которые могут выполняться параллельно. Если значение не указано, все запуски запускаются параллельно. Значение должно быть целым числом от 1 до 100. ПРИМЕЧАНИЕ: Количество параллельных прогонов зависит от ресурсов, доступных в заданном целевом объекте вычисления. Убедитесь, что целевой объект вычислений имеет доступные ресурсы для требуемого уровня параллелизма. |
Примечание.
Пример конфигурации полной очистки см. в этом учебнике.
Аргументы
В качестве аргументов можно передать фиксированные параметры или параметры, которые не изменяются во время очистки пространства параметра. Аргументы передаются в пары "имя-значение", а имя при этом должно иметь префикс в виде двойного дефиса.
from azureml.train.automl import AutoMLImageConfig
arguments = ["--early_stopping", 1, "--evaluation_frequency", 2]
automl_image_config = AutoMLImageConfig(arguments=arguments)
Добавочное обучение (необязательно)
По завершении обучения вы можете продолжить обучение модели, загрузив контрольную точку обученной модели. Для добавочного обучения можно использовать тот же набор данных или другой.
Для добавочного обучения доступны два варианта. Вы можете:
- Передать идентификатор запуска, из которого требуется загрузить контрольную точку.
- Передать контрольные точки через FileDataset.
Передать контрольную точку через идентификатор запуска
Чтобы найти идентификатор запуска нужной модели, можно использовать следующий код.
# find a run id to get a model checkpoint from
target_checkpoint_run = automl_image_run.get_best_child()
Чтобы передать контрольную точку через идентификатор запуска, необходимо использовать параметр checkpoint_run_id.
automl_image_config = AutoMLImageConfig(task='image-object-detection',
compute_target=compute_target,
training_data=training_dataset,
validation_data=validation_dataset,
checkpoint_run_id= target_checkpoint_run.id,
primary_metric='mean_average_precision',
**tuning_settings)
automl_image_run = experiment.submit(automl_image_config)
automl_image_run.wait_for_completion(wait_post_processing=True)
Передача контрольной точки через FileDataset
Чтобы передать контрольную точку через FileDataset, необходимо использовать параметры checkpoint_dataset_id и checkpoint_filename.
# download the checkpoint from the previous run
model_name = "outputs/model.pt"
model_local = "checkpoints/model_yolo.pt"
target_checkpoint_run.download_file(name=model_name, output_file_path=model_local)
# upload the checkpoint to the blob store
ds.upload(src_dir="checkpoints", target_path='checkpoints')
# create a FileDatset for the checkpoint and register it with your workspace
ds_path = ds.path('checkpoints/model_yolo.pt')
checkpoint_yolo = Dataset.File.from_files(path=ds_path)
checkpoint_yolo = checkpoint_yolo.register(workspace=ws, name='yolo_checkpoint')
automl_image_config = AutoMLImageConfig(task='image-object-detection',
compute_target=compute_target,
training_data=training_dataset,
validation_data=validation_dataset,
checkpoint_dataset_id= checkpoint_yolo.id,
checkpoint_filename='model_yolo.pt',
primary_metric='mean_average_precision',
**tuning_settings)
automl_image_run = experiment.submit(automl_image_config)
automl_image_run.wait_for_completion(wait_post_processing=True)
Выполнение прогона
Когда объект AutoMLImageConfig будет готов, можно отправлять эксперимент.
ws = Workspace.from_config()
experiment = Experiment(ws, "Tutorial-automl-image-object-detection")
automl_image_run = experiment.submit(automl_image_config)
Выходные данные и метрики вычисления
При запуске автоматизированного машинного обучения создаются файлы выходной модели, метрики вычисления, журналы и артефакты развертывания, такие как файл оценки, и файл среды, который можно просмотреть на вкладке выходных данных, журналов и метрик дочерних запусков.
Совет
Сведения о том, как перейти к результатам выполнения задания, см. в разделе Просмотр результатов выполнения.
Определения и примеры диаграмм производительности и метрик, предоставляемых для каждого запуска, см. в статье Оценка результатов экспериментов автоматизированного машинного обучения
регистрация и развертывание модели.
После завершения выполнения можно зарегистрировать модель, созданную на основе лучшего запуска (конфигурации, которая привела к лучшей основной метрике)
best_child_run = automl_image_run.get_best_child()
model_name = best_child_run.properties['model_name']
model = best_child_run.register_model(model_name = model_name, model_path='outputs/model.pt')
После регистрации модели, которую вы хотите использовать, ее можно развернуть как веб-службу в Экземплярах контейнеров Azure (ACI) или Службе Azure Kubernetes (AKS). ACI является идеальным вариантом для тестирования развертываний, а AKS лучше подходит для крупномасштабного использования в рабочей среде.
В этом примере модель развертывается как веб-служба в AKS. Чтобы выполнить развертывание в AKS, сначала создайте вычислительный кластер AKS или используйте существующий кластер AKS. Для кластера развертывания можно использовать номера SKU для виртуальных машин GPU или процессора.
from azureml.core.compute import ComputeTarget, AksCompute
from azureml.exceptions import ComputeTargetException
# Choose a name for your cluster
aks_name = "cluster-aks-gpu"
# Check to see if the cluster already exists
try:
aks_target = ComputeTarget(workspace=ws, name=aks_name)
print('Found existing compute target')
except ComputeTargetException:
print('Creating a new compute target...')
# Provision AKS cluster with GPU machine
prov_config = AksCompute.provisioning_configuration(vm_size="STANDARD_NC6",
location="eastus2")
# Create the cluster
aks_target = ComputeTarget.create(workspace=ws,
name=aks_name,
provisioning_configuration=prov_config)
aks_target.wait_for_completion(show_output=True)
Затем можно определить конфигурацию вывода, которае описывает настройку веб-службы, содержащей модель. Скрипт оценки и среду можно использовать из обучающего запуска в конфигурации вывода.
from azureml.core.model import InferenceConfig
best_child_run.download_file('outputs/scoring_file_v_1_0_0.py', output_file_path='score.py')
environment = best_child_run.get_environment()
inference_config = InferenceConfig(entry_script='score.py', environment=environment)
Затем можно развернуть модель как веб-службу AKS.
# Deploy the model from the best run as an AKS web service
from azureml.core.webservice import AksWebservice
from azureml.core.webservice import Webservice
from azureml.core.model import Model
from azureml.core.environment import Environment
aks_config = AksWebservice.deploy_configuration(autoscale_enabled=True,
cpu_cores=1,
memory_gb=50,
enable_app_insights=True)
aks_service = Model.deploy(ws,
models=[model],
inference_config=inference_config,
deployment_config=aks_config,
deployment_target=aks_target,
name='automl-image-test',
overwrite=True)
aks_service.wait_for_deployment(show_output=True)
print(aks_service.state)
Кроме того, можно развернуть модель из пользовательского интерфейса студии Машинного обучения Azure. Перейдите к модели, которую вы хотите развернуть, на вкладке Модели запуска автоматизированного машинного обучения и выберите Развертывание.
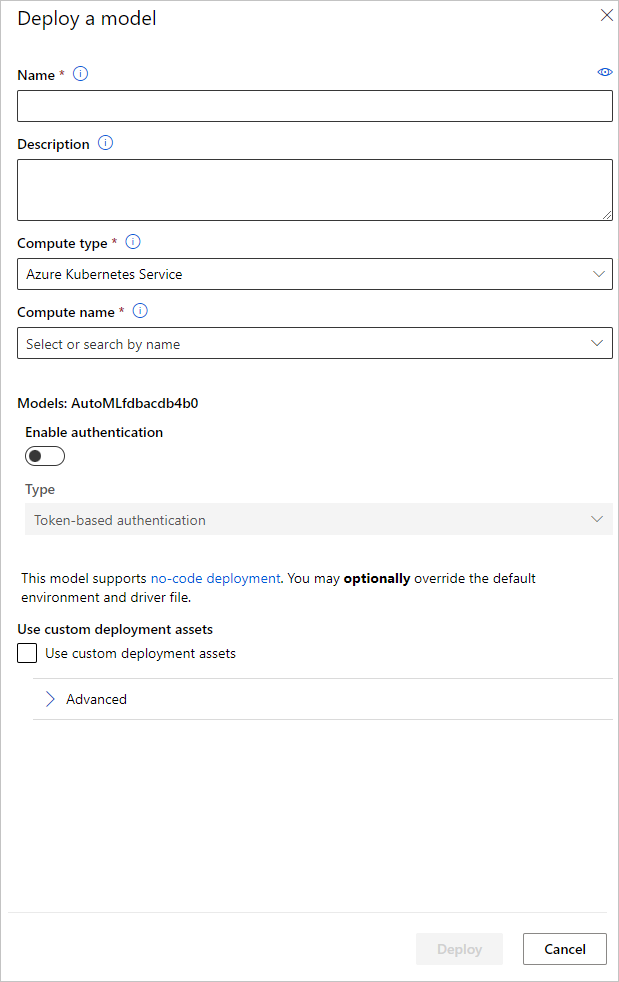
Вы можете настроить имя конечной точки развертывания модели и кластер вывода, который будет использоваться для развертывания модели, на панели Развертывание модели.
Обновление конфигурации вывода
На предыдущем этапе мы скачали файл outputs/scoring_file_v_1_0_0.py оценки из лучшей модели в локальный файл score.py и использовали его для создания объекта InferenceConfig. Этот скрипт можно изменить для изменения параметров вывода для конкретной модели, если это необходимо, после его загрузки и перед созданием InferenceConfig. Например, это раздел кода, который инициализирует модель в файле оценки:
...
def init():
...
try:
logger.info("Loading model from path: {}.".format(model_path))
model_settings = {...}
model = load_model(TASK_TYPE, model_path, **model_settings)
logger.info("Loading successful.")
except Exception as e:
logging_utilities.log_traceback(e, logger)
raise
...
Каждая из задач (и некоторые модели) имеет набор параметров в словаре model_settings. По умолчанию мы используем те же значения для параметров, которые использовались во время обучения и проверки. В зависимости от реакции на события, которая требуется при использовании модели для вывода, мы можем менять эти параметры. Ниже можно найти список параметров для каждого типа задачи и для каждой модели.
| Задача | Наименование параметра | По умолчанию |
|---|---|---|
| Классификации изображений (с несколькими классами и с несколькими метками) | valid_resize_sizevalid_crop_size |
256 224 |
| Обнаружение объектов | min_sizemax_sizebox_score_threshnms_iou_threshbox_detections_per_img |
600 1333 0,3 0,5 100 |
Обнаружение объектов с использованием yolov5 |
img_sizemodel_sizebox_score_threshnms_iou_thresh |
640 medium 0,1 0,5 |
| Сегментация экземпляров | min_sizemax_sizebox_score_threshnms_iou_threshbox_detections_per_imgmask_pixel_score_thresholdmax_number_of_polygon_pointsexport_as_imageimage_type |
600 1333 0,3 0,5 100 0,5 100 False JPG |
Подробное описание гиперпараметров, относящихся к задачам, см. в разделе Гиперпараметры задач компьютерного зрения в автоматизированном машинном обучении.
Если вы хотите использовать мозаичное заполнение и хотите управлять поведением мозаичного заполнения, доступны следующие параметры: tile_grid_size, tile_overlap_ratio и tile_predictions_nms_thresh. Дополнительные сведения об этих параметрах см. разделе Обучение модели обнаружения объектов с помощью AutoML.
Примеры записных книжек
Изучите подробные примеры кода и варианты использования в репозитории записных книжек GitHub для автоматизированных примеров машинного обучения. В папках с префиксом image- просмотрите примеры, связанные с созданием моделей компьютерного зрения.