Создание заданий и входных данных для пакетных конечных точек
При использовании конечных точек пакетной службы в Машинное обучение Azure можно выполнять длительные пакетные операции с большими объемами входных данных. Данные могут находиться в разных местах, например в разных регионах. Некоторые типы конечных точек пакетной службы также могут получать литеральные параметры в качестве входных данных.
В этой статье описывается, как указать входные данные параметров для конечных точек пакетной службы и создать задания развертывания. Этот процесс поддерживает работу с данными из различных источников, таких как ресурсы данных, хранилища данных, учетные записи хранения и локальные файлы.
Необходимые компоненты
Конечная точка и развертывание пакетной службы. Сведения о создании этих ресурсов см. в статье "Развертывание моделей MLflow в пакетных развертываниях в Машинное обучение Azure".
Разрешения для запуска развертывания пакетной конечной точки. Для запуска развертывания можно использовать роли azureML Специалист по обработке и анализу данных, участника и владельца. Сведения о конкретных разрешениях, необходимых для определений пользовательских ролей, см. в разделе "Авторизация" в конечных точках пакетной службы.
Учетные данные для вызова конечной точки. Дополнительные сведения см. в разделе "Установка проверки подлинности".
Доступ на чтение входных данных из вычислительного кластера, где развернута конечная точка.
Совет
Для некоторых ситуаций требуется использовать хранилище данных без учетных данных или внешнюю учетную запись служба хранилища Azure в качестве входных данных. В этих сценариях убедитесь, что вы настраиваете вычислительные кластеры для доступа к данным, так как управляемое удостоверение вычислительного кластера используется для подключения учетной записи хранения. У вас по-прежнему есть детализированный контроль доступа, так как для чтения базовых данных используется удостоверение задания (вызывающий объект).
Установка проверки подлинности
Чтобы вызвать конечную точку, требуется действительный маркер Microsoft Entra. При вызове конечной точки Машинное обучение Azure создает задание пакетного развертывания под удостоверением, связанным с маркером.
- Если вы используете Машинное обучение Azure CLI (версии 2) или пакет SDK Машинное обучение Azure для Python версии 2 для вызова конечных точек, вам не нужно вручную получить маркер Microsoft Entra. Во время входа система проходит проверку подлинности удостоверения пользователя. Он также извлекает и передает маркер для вас.
- При использовании REST API для вызова конечных точек необходимо вручную получить маркер.
Вы можете использовать собственные учетные данные для вызова, как описано в следующих процедурах.
Используйте Azure CLI для входа с помощью интерактивной проверки подлинности или кода устройства:
az login
Дополнительные сведения о различных типах учетных данных см. в разделе "Запуск заданий с использованием различных типов учетных данных".
Создание базовых заданий
Чтобы создать задание из пакетной конечной точки, необходимо вызвать конечную точку. Вызов можно выполнить с помощью интерфейса командной строки Машинное обучение Azure, пакета SDK Машинное обучение Azure для Python или вызова REST API.
В следующих примерах показаны основы вызова для конечной точки пакетной службы, которая получает одну папку входных данных для обработки. Примеры, связанные с различными входными и выходными данными, см. в разделе "Общие сведения о входных и выходных данных".
invoke Используйте операцию в конечных точках пакетной службы:
az ml batch-endpoint invoke --name $ENDPOINT_NAME \
--input https://azuremlexampledata.blob.core.windows.net/data/heart-disease-uci/data
Вызов определенного развертывания
Конечные точки пакетной службы могут размещать несколько развертываний в одной конечной точке. Конечная точка по умолчанию используется, если пользователь не указывает в противном случае. Для изменения используемого развертывания можно использовать следующие процедуры.
Используйте аргумент --deployment-name или -d укажите имя развертывания:
az ml batch-endpoint invoke --name $ENDPOINT_NAME \
--deployment-name $DEPLOYMENT_NAME \
--input https://azuremlexampledata.blob.core.windows.net/data/heart-disease-uci/data
Настройка свойств задания
Некоторые свойства задания можно настроить во время вызова.
Примечание.
В настоящее время можно настроить свойства задания только в пакетных конечных точках с развертываниями компонентов конвейера.
Настройка имени эксперимента
Чтобы настроить имя эксперимента, используйте следующие процедуры.
Используйте аргумент --experiment-name , чтобы указать имя эксперимента:
az ml batch-endpoint invoke --name $ENDPOINT_NAME \
--experiment-name "my-batch-job-experiment" \
--input https://azuremlexampledata.blob.core.windows.net/data/heart-disease-uci/data
Общие сведения о входных и выходных данных
Конечные точки пакетной службы предоставляют устойчивый API, который потребители могут использовать для создания пакетных заданий. Тот же интерфейс можно использовать для указания входных и выходных данных, которые ожидает развертывание. Используйте входные данные для передачи сведений, необходимых конечной точке для выполнения задания.
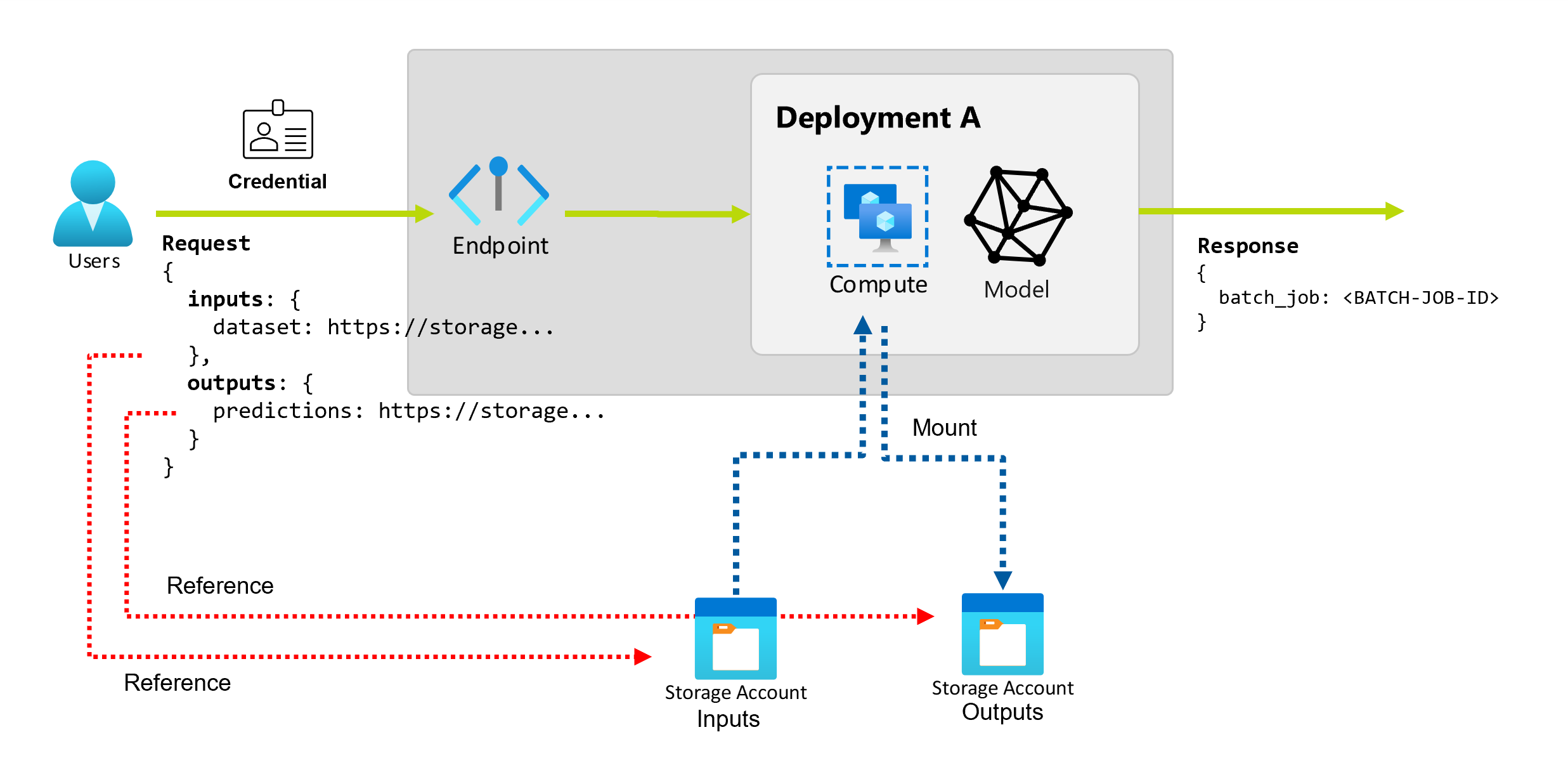
Конечные точки пакетной службы поддерживают два типа входных данных:
- Входные данные или указатели на определенное расположение хранилища или Машинное обучение Azure ресурс
- Литеральные входные данные или литеральные значения, такие как числа или строки, которые необходимо передать в задание
Количество и тип входных и выходных данных зависит от типа пакетного развертывания. Для развертываний моделей всегда требуется один вход данных и вывод одного выходных данных. Входные данные литерала не поддерживаются в развертываниях моделей. В отличие от этого, развертывания компонентов конвейера предоставляют более общую конструкцию для создания конечных точек. В развертывании компонента конвейера можно указать любое количество входных данных, литеральных входных данных и выходных данных.
В следующей таблице перечислены входные и выходные данные для пакетных развертываний:
| Тип развертывания | Количество входных данных | Поддерживаемые типы входных данных | Количество выходных данных | Поддерживаемые типы вывода |
|---|---|---|---|---|
| Развертывание модели | 1 | Входные данные | 1 | Выходные данные |
| Развертывание компонента конвейера | 0-N | Входные данные и литеральные входные данные | 0-N | Выходные данные |
Совет
Входные и выходные данные всегда именуются. Каждое имя служит ключом для идентификации данных и передачи значения во время вызова. Так как развертывания модели всегда требуют одного входного и выходного данных, имена игнорируются во время вызова в развертываниях моделей. Можно назначить имя, которое лучше всего описывает вариант использования, например sales_estimation.
Изучение входных данных
Входные данные ссылаются на входные данные, указывающие на расположение размещения данных. Так как конечные точки пакетной службы обычно используют большие объемы данных, входные данные не передаются в рамках запроса на вызов. Вместо этого необходимо указать расположение, в котором должна находиться конечная точка пакетной службы. Входные данные подключены и передаются в целевой вычислительный экземпляр для повышения производительности.
Конечные точки пакетной службы могут считывать файлы, расположенные в следующих типах хранилища:
-
Машинное обучение Azure ресурсы данных, включая типы папок (
uri_folder) и файлов (uri_file). - Машинное обучение Azure хранилища данных, включая Хранилище BLOB-объектов Azure, Data Lake Storage 1-го поколения Azure и Azure Data Lake Storage 2-го поколения.
- учетные записи служба хранилища Azure, включая хранилище BLOB-объектов, Data Lake Storage 1-го поколения и Data Lake Storage 2-го поколения.
- Локальные папки и файлы данных при использовании интерфейса командной строки Машинное обучение Azure или пакета SDK Машинное обучение Azure для Python для вызова конечных точек. Но локальные данные передаются в хранилище данных по умолчанию вашей рабочей области Машинное обучение Azure.
Внимание
Уведомление об устаревших ресурсах: ресурсы данных типа FileDataset (V1) устарели и будут прекращены в будущем. Существующие конечные точки пакетной службы, использующие эту функцию, будут продолжать работать. Но нет поддержки наборов данных версии 1 в конечных точках пакетной службы, созданных с помощью:
- Версии Машинное обучение Azure CLI версии 2 ( 2.4.0 и более поздних версий).
- Общедоступные версии REST API (2022-05-01 и более поздние версии).
Изучение входных данных литерала
Литеральные входные данные относятся к входным данным, которые могут представляться и разрешаться во время вызова, например строк, чисел и логических значений. Обычно используются литеральные входные данные для передачи параметров в конечную точку в рамках развертывания компонента конвейера. Конечные точки пакетной службы поддерживают следующие литеральные типы:
stringbooleanfloatinteger
Входные данные литерала поддерживаются только в развертываниях компонентов конвейера. Чтобы узнать, как указать конечные точки литерала, см. статью "Создание заданий с помощью литеральных входных данных".
Изучение выходных данных
Выходные данные ссылаются на расположение, в котором размещаются результаты пакетного задания. Каждый вывод имеет идентифицируемое имя, и Машинное обучение Azure автоматически назначает уникальный путь каждому именованному выходу. Если вам нужно указать другой путь.
Внимание
Конечные точки пакетной службы поддерживают только запись выходных данных в хранилищах данных хранилища BLOB-объектов. Если необходимо записать в учетную запись хранения с включенными иерархическими пространствами имен, например Data Lake Storage 2-го поколения, можно зарегистрировать службу хранилища в качестве хранилища BLOB-объектов, так как службы полностью совместимы. Таким образом можно записывать выходные данные из конечных точек пакетной службы в Data Lake Storage 2-го поколения.
Создание заданий с входными данными
В следующих примерах показано, как создавать задания при приеме входных данных из ресурсов данных, хранилищ данных и учетных записей служба хранилища Azure.
Использование входных данных из ресурса данных
Машинное обучение Azure ресурсы данных (ранее известные как наборы данных) поддерживаются в качестве входных данных для заданий. Выполните следующие действия, чтобы запустить задание пакетной конечной точки, использующее входные данные, хранящиеся в зарегистрированном ресурсе данных в Машинное обучение Azure.
Предупреждение
В настоящее время ресурсы данных таблицы типов (MLTable) не поддерживаются.
Создайте ресурс данных. В этом примере она состоит из папки, содержащей несколько CSV-файлов. Для параллельной обработки файлов используются пакетные конечные точки. Этот шаг можно пропустить, если данные уже зарегистрированы в качестве ресурса данных.
Создайте определение ресурса данных в файле YAML с именем heart-data.yml:
$schema: https://azuremlschemas.azureedge.net/latest/data.schema.json name: heart-data description: An unlabeled data asset for heart classification. type: uri_folder path: dataСоздайте ресурс данных:
az ml data create -f heart-data.yml
Настройте входные данные:
DATA_ASSET_ID=$(az ml data show -n heart-data --label latest | jq -r .id)Идентификатор ресурса данных имеет формат
/subscriptions/<subscription-ID>/resourceGroups/<resource-group-name>/providers/Microsoft.MachineLearningServices/workspaces/<workspace-name>/data/<data-asset-name>/versions/<data-asset-version>.Запустите конечную точку:
--setИспользуйте аргумент для указания входных данных. Сначала замените все дефисы в имени ресурса данных символами подчеркивания. Ключи могут содержать только буквенно-цифровые символы и символы подчеркивания.az ml batch-endpoint invoke --name $ENDPOINT_NAME \ --set inputs.heart_data.type="uri_folder" inputs.heart_data.path=$DATA_ASSET_IDДля конечной точки, которая служит развертыванием модели, можно использовать
--inputаргумент для указания входных данных, так как для развертывания модели всегда требуется только один вход данных.az ml batch-endpoint invoke --name $ENDPOINT_NAME --input $DATA_ASSET_IDАргумент
--set, как правило, создает длинные команды при указании нескольких входных данных. В таких случаях можно перечислить входные данные в файле, а затем ссылаться на файл при вызове конечной точки. Например, можно создать ФАЙЛ YAML с именем inputs.yml, содержащий следующие строки:inputs: heart_data: type: uri_folder path: /subscriptions/<subscription-ID>/resourceGroups/<resource-group-name>/providers/Microsoft.MachineLearningServices/workspaces/<workspace-name>/data/heart-data/versions/1Затем можно выполнить следующую команду, которая использует
--fileаргумент для указания входных данных:az ml batch-endpoint invoke --name $ENDPOINT_NAME --file inputs.yml
Использование входных данных из хранилища данных
Задания пакетного развертывания могут напрямую ссылаться на данные, которые хранятся в Машинное обучение Azure зарегистрированных хранилищах данных. В этом примере сначала вы отправляете некоторые данные в хранилище данных в рабочей области Машинное обучение Azure. Затем вы запускаете пакетное развертывание данных.
В этом примере используется хранилище данных по умолчанию, но можно использовать другое хранилище данных. В любой рабочей области Машинное обучение Azure имя хранилища данных BLOB-объектов по умолчанию — workspaceblobstore. Если вы хотите использовать другое хранилище данных на следующих шагах, замените workspaceblobstore на имя предпочтительного хранилища данных.
Отправьте примеры данных в хранилище данных. Примеры данных доступны в репозитории azureml-examples . Данные можно найти в папке sdk/python/endpoints/batch/deploy-models/heart-classifier-mlflow/data этого репозитория.
- В Студия машинного обучения Azure откройте страницу ресурсов данных для хранилища данных BLOB-объектов по умолчанию, а затем найдите имя своего контейнера BLOB-объектов.
- Используйте средство, например служба хранилища Azure Explorer или AzCopy, чтобы передать образец данных в папку с именем heart-disease-uci-unlabeled в этом контейнере.
Настройте входные данные:
Поместите путь к файлу
INPUT_PATHв переменную:DATA_PATH="heart-disease-uci-unlabeled" INPUT_PATH="azureml://datastores/workspaceblobstore/paths/$DATA_PATH"Обратите внимание, что
pathsпапка входит в входной путь. Этот формат указывает, что следующее значение — путь.Запустите конечную точку:
--setИспользуйте аргумент для указания входных данных:az ml batch-endpoint invoke --name $ENDPOINT_NAME \ --set inputs.heart_data.type="uri_folder" inputs.heart_data.path=$INPUT_PATHДля конечной точки, которая служит развертыванием модели, можно использовать
--inputаргумент для указания входных данных, так как для развертывания модели всегда требуется только один вход данных.az ml batch-endpoint invoke --name $ENDPOINT_NAME --input $INPUT_PATH --input-type uri_folderАргумент
--set, как правило, создает длинные команды при указании нескольких входных данных. В таких случаях можно перечислить входные данные в файле, а затем ссылаться на файл при вызове конечной точки. Например, можно создать ФАЙЛ YAML с именем inputs.yml, содержащий следующие строки:inputs: heart_data: type: uri_folder path: azureml://datastores/workspaceblobstore/paths/<data-path>Если данные есть в файле, используйте
uri_fileтип для входных данных.Затем можно выполнить следующую команду, которая использует
--fileаргумент для указания входных данных:az ml batch-endpoint invoke --name $ENDPOINT_NAME --file inputs.yml
Использование входных данных из учетной записи служба хранилища Azure
Машинное обучение Azure конечные точки пакетной службы могут считывать данные из облачных расположений в учетных записях служба хранилища Azure как общедоступных, так и частных. Выполните следующие действия, чтобы запустить задание пакетной конечной точки с данными в учетной записи хранения.
Дополнительные сведения о дополнительных необходимых конфигурациях для чтения данных из учетных записей хранения см. в разделе "Настройка вычислительных кластеров для доступа к данным".
Настройте входные данные:
INPUT_DATAЗадайте переменную:INPUT_DATA="https://azuremlexampledata.blob.core.windows.net/data/heart-disease-uci/data"Если данные содержатся в файле, используйте следующий формат, чтобы определить входной путь:
INPUT_DATA="https://azuremlexampledata.blob.core.windows.net/data/heart-disease-uci/data/heart.csv"Запустите конечную точку:
--setИспользуйте аргумент для указания входных данных:az ml batch-endpoint invoke --name $ENDPOINT_NAME \ --set inputs.heart_data.type="uri_folder" inputs.heart_data.path=$INPUT_DATAДля конечной точки, которая служит развертыванием модели, можно использовать
--inputаргумент для указания входных данных, так как для развертывания модели всегда требуется только один вход данных.az ml batch-endpoint invoke --name $ENDPOINT_NAME --input $INPUT_DATA --input-type uri_folderАргумент
--set, как правило, создает длинные команды при указании нескольких входных данных. В таких случаях можно перечислить входные данные в файле, а затем ссылаться на файл при вызове конечной точки. Например, можно создать ФАЙЛ YAML с именем inputs.yml, содержащий следующие строки:inputs: heart_data: type: uri_folder path: https://azuremlexampledata.blob.core.windows.net/data/heart-disease-uci/dataЗатем можно выполнить следующую команду, которая использует
--fileаргумент для указания входных данных:az ml batch-endpoint invoke --name $ENDPOINT_NAME --file inputs.ymlЕсли данные есть в файле, используйте
uri_fileтип в файле inputs.yml для ввода данных.
Создание заданий с помощью литеральных входных данных
Развертывания компонентов конвейера могут принимать литеральные входные данные. Пример пакетного развертывания, содержащего базовый конвейер, см. в статье "Развертывание конвейеров с помощью конечных точек пакетной службы".
В следующем примере показано, как указать входные данные с именем score_modeтипа stringс значением append:
Поместите входные данные в YAML-файл, например один из именованных inputs.yml:
inputs:
score_mode:
type: string
default: append
Выполните следующую команду, которая использует --file аргумент для указания входных данных.
az ml batch-endpoint invoke --name $ENDPOINT_NAME --file inputs.yml
Аргумент можно также использовать --set для указания типа и значения по умолчанию. Но этот подход, как правило, создает длинные команды при указании нескольких входных данных:
az ml batch-endpoint invoke --name $ENDPOINT_NAME \
--set inputs.score_mode.type="string" inputs.score_mode.default="append"
Создание заданий с выходными данными
В следующем примере показано, как изменить расположение выходных данных с именем score. Для полноты пример также настраивает входные данные с именем heart_data.
В этом примере используется хранилище данных по умолчанию, workspaceblobstore. Но вы можете использовать любое другое хранилище данных в рабочей области, если это учетная запись хранения BLOB-объектов. Если вы хотите использовать другое хранилище данных, замените workspaceblobstore на приведенные ниже действия именем предпочтительного хранилища данных.
Получите идентификатор хранилища данных.
DATA_STORE_ID=$(az ml datastore show -n workspaceblobstore | jq -r '.id')Идентификатор хранилища данных имеет формат
/subscriptions/<subscription-ID>/resourceGroups/<resource-group-name>/providers/Microsoft.MachineLearningServices/workspaces/<workspace-name>/datastores/workspaceblobstore.Создайте выходные данные:
Определите входные и выходные значения в файле с именем inputs-and-outputs.yml. Используйте идентификатор хранилища данных в пути вывода. Для полноты также определите входные данные.
inputs: heart_data: type: uri_folder path: https://azuremlexampledata.blob.core.windows.net/data/heart-disease-uci/data outputs: score: type: uri_file path: <data-store-ID>/paths/batch-jobs/my-unique-pathПримечание.
Обратите внимание, как
pathsпапка входит в выходной путь. Этот формат указывает, что следующее значение — путь.Запустите развертывание:
--fileИспользуйте аргумент для указания входных и выходных значений:az ml batch-endpoint invoke --name $ENDPOINT_NAME --file inputs-and-outputs.yml