Обработка и анализ данных с помощью виртуальной машины Windows, предназначенной для обработки и анализа данных
Windows Виртуальная машина для обработки и анализа данных (DSVM) — это мощная среда разработки для обработки и анализа данных, которая поддерживает задачи исследования и моделирования данных. Среда поставляется с предварительно созданными и предварительно подготовленными с помощью нескольких популярных средств аналитики данных, которые упрощают анализ локальных, облачных или гибридных развертываний.
Работа DSVM выполняется при тесной интеграции со службами Azure. Он может считывать и обрабатывать данные, уже хранящиеся в Azure, в Azure Synapse (ранее — хранилище данных SQL), Azure Data Lake, служба хранилища Azure или Azure Cosmos DB. Также эта виртуальная машина позволяет использовать инновационные возможности других аналитических инструментов, например машинное обучение Azure.
В этой статье вы узнаете, как использовать DSVM для обработки задач обработки и анализа данных и взаимодействия с другими службами Azure. Это пример задач, которые могут охватывать DSVM:
- Используйте Jupyter Notebook для экспериментов с данными в браузере с помощью Python 2, Python 3 и Microsoft R. (Microsoft R — это корпоративная версия R, предназначенная для обеспечения высокой производительности).)
- Изучение данных и разработка моделей локально в DSVM с помощью Microsoft Машинное обучение Server и Python.
- Администрирование ресурсов Azure с помощью портал Azure или PowerShell.
- Расширьте дисковое пространство и поделитесь большими наборами данных или кодом во всей команде, используя Файлы Azure общий доступ в качестве подключаемого диска на виртуальной машине DSVM.
- Поделитесь кодом с командой с помощью GitHub. Доступ к репозиторию с предварительно установленными клиентами Git: Git Bash и графическим интерфейсом Git.
- Доступ к службам данных и аналитики Azure:
- Хранилище BLOB-объектов Azure
- Azure Cosmos DB
- Azure Synapse (ранее — Хранилище данных SQL)
- База данных SQL Azure
- Создайте отчеты и панель мониторинга с помощью экземпляра Power BI Desktop, предварительно установленного на dsVM, и разверните их в облаке.
- Установите дополнительные средства на виртуальной машине.
Примечание.
Для многих категорий хранилищ данных и аналитических служб, перечисленных в этой статье, предусмотрено взимание дополнительной платы за использование. Дополнительные сведения см. на странице ценообразования Azure.
Необходимые компоненты
- Подписка Azure. Если у вас еще нет подписки Azure, создайте бесплатную учетную запись, прежде чем начинать работу.
- Подготовленный DSVM на портал Azure. Дополнительные сведения см. в разделе "Создание ресурса виртуальной машины ".
Примечание.
Мы рекомендуем использовать модуль Azure Az PowerShell для взаимодействия с Azure. Чтобы начать работу, см. статью Установка Azure PowerShell. Дополнительные сведения см. в статье Перенос Azure PowerShell с AzureRM на Az.
Использование записных книжек Jupyter
Записная книжка Jupyter обеспечивает представление среды IDE на основе браузера для изучения и моделирования данных. В Jupyter Notebook можно использовать Python 2, Python 3 или R.
Чтобы запустить записную книжку Jupyter, нажмите значок Jupyter Notebook либо в меню Пуск, либо на рабочем столе. В командной строке DSVM можно также запустить команду jupyter notebook из каталога, на котором размещены существующие записные книжки или где вы хотите создать новые записные книжки.
После запуска Jupyter перейдите /notebooks в каталог. В этом каталоге размещаются примеры записных книжек, которые предварительно упакованы в DSVM. Вы можете:
- Выбрать записную книжку, чтобы посмотреть ее код.
- Нажмите клавиши SHIFT+ВВОД, чтобы запустить каждую ячейку.
- Выберите "Выполнить ячейку>", чтобы запустить всю записную книжку.
- Создание записной книжки; Щелкните значок Jupyter (верхний левый угол), нажмите кнопку "Создать ", а затем выберите язык записной книжки (также известный как ядра).
Примечание.
В настоящее время поддерживаются ядра Python 2.7, Python 3.6, R, Julia и PySpark в Jupyter. Ядро R поддерживает программирование как в формате R с открытым исходным кодом, так и в Microsoft R. В записной книжке можно просматривать данные, создавать модель и тестировать эту модель с помощью выбранной библиотеки.
Изучение данных и разработка моделей с помощью Microsoft Machine Learning Server
Примечание.
Поддержка автономного сервера Машинное обучение закончилась 1 июля 2021 г. Мы удалили его из образов DSVM после 30 июня 2021 года. Существующие развертывания по-прежнему могут получить доступ к программному обеспечению, но поддержка закончилась после 1 июля 2021 года.
Вы можете использовать R и Python для аналитики данных непосредственно в DSVM.
Для R можно использовать Инструменты R для Visual Studio. Корпорация Майкрософт предоставляет другие библиотеки в дополнение к ресурсу CRAN R с открытым исходным кодом. Эти библиотеки позволяют масштабируемой аналитике и возможности анализировать массы данных, превышающие ограничения размера памяти параллельного фрагментированного анализа.
Для Python можно использовать интегрированную среду разработки ( например, Visual Studio Community Edition), которая имеет предварительно установленное расширение Инструменты Python для Visual Studio (PTVS). По умолчанию в PTVS настроена только корневая среда Conda Python 3.6. Чтобы включить Anaconda Python 2.7, выполните следующие действия.
- Создайте пользовательские среды для каждой версии. Выберите "Сервис>Python Tools>Python", а затем выберите +Custom в Visual Studio Community Edition.
- Укажите описание и задайте путь префикса среды как c:\anaconda\envs\python2 для Anaconda Python 2.7.
- Выберите Автоматическое обнаружение>Применить, чтобы сохранить настройки окружения.
Дополнительные сведения о создании сред Python см. в ресурсе документации по PTVS.
Теперь можно создать проект Python. Выберите "Файл>нового>проекта>Python" и выберите тип приложения Python, которое вы хотите создать. Среду Python для текущего проекта можно задать для требуемой версии (Python 2.7 или 3.6), щелкнув правой кнопкой мыши среды Python, а затем выбрав "Добавить и удалить среды Python". Дополнительные сведения о работе с PTVS см. в документации по продукту.
Управление ресурсами Azure
DSVM позволяет создавать решение аналитики локально на виртуальной машине. При этом также предоставляется доступ к службам на облачной платформе Azure. Azure предоставляет несколько служб, включая вычислительные ресурсы, хранилище, аналитику данных и многое другое, которые можно администрировать и получать доступ из dsVM.
У вас есть два доступных варианта администрирования подписки Azure и облачных ресурсов:
Посетите портал Azure в браузере.
Используйте скрипты PowerShell. Запустите Azure PowerShell из ярлыка на рабочем столе или из меню "Пуск ". Дополнительные сведения см. в ресурсе документации по Microsoft Azure PowerShell.
Расширение хранилища с помощью общих файловых систем
Специалисты по обработке и анализу данных могут использовать большие наборы данных, код или другие ресурсы вместе с участниками группы. DSVM имеет около 45 ГБ доступного пространства. Чтобы развернуть хранилище, можно использовать Файлы Azure и подключить его к одному или нескольким экземплярам DSVM или получить к нему доступ с помощью REST API. Вы также можете использовать портал Azure или использовать Azure PowerShell для добавления дополнительных выделенных дисков данных.
Примечание.
Максимальное пространство в общей папке Azure составляет 5 ТБ. Каждый файл имеет ограничение размера 1 ТБ.
Этот скрипт Azure PowerShell создает общую папку Файлы Azure:
# Authenticate to Azure.
Connect-AzAccount
# Select your subscription
Get-AzSubscription –SubscriptionName "<your subscription name>" | Select-AzSubscription
# Create a new resource group.
New-AzResourceGroup -Name <dsvmdatarg>
# Create a new storage account. You can reuse existing storage account if you want.
New-AzStorageAccount -Name <mydatadisk> -ResourceGroupName <dsvmdatarg> -Location "<Azure Data Center Name For eg. South Central US>" -Type "Standard_LRS"
# Set your current working storage account
Set-AzCurrentStorageAccount –ResourceGroupName "<dsvmdatarg>" –StorageAccountName <mydatadisk>
# Create an Azure Files share
$s = New-AzStorageShare <<teamsharename>>
# Create a directory under the file share. You can give it any name
New-AzStorageDirectory -Share $s -Path <directory name>
# List the share to confirm that everything worked
Get-AzStorageFile -Share $s
Вы можете подключить общую папку Файлы Azure на любой виртуальной машине в Azure. Мы рекомендуем разместить виртуальную машину и учетную запись хранения в одном центре обработки данных Azure, чтобы избежать задержек и расходов на передачу данных. Эти команды Azure PowerShell подключают диск на dsVM:
# Get the storage key of the storage account that has the Azure Files share from the Azure portal. Store it securely on the VM to avoid being prompted in the next command.
cmdkey /add:<<mydatadisk>>.file.core.windows.net /user:<<mydatadisk>> /pass:<storage key>
# Mount the Azure Files share as drive Z on the VM. You can choose another drive letter if you want.
net use z: \\<mydatadisk>.file.core.windows.net\<<teamsharename>>
Вы можете получить доступ к этому диску, как и любой обычный диск на виртуальной машине.
Совместное использование кода в GitHub
Репозиторий кода GitHub содержит примеры кода и источники кода для многих средств, общих для сообщества разработчиков. Git выступает в качестве технологии для отслеживания и хранения версий файлов кода. GitHub также служит платформой для создания собственного репозитория. Собственный репозиторий может хранить общий код и документацию вашей команды, реализовывать управление версиями и управлять разрешениями на доступ для заинтересованных лиц, желающих просматривать и вносить свой вклад в код. GitHub поддерживает совместную работу в команде, использование кода, разработанного сообществом, и вклад кода обратно в сообщество. Дополнительные сведения о GitHub см. на страницах справки Git.
DSVM загружается с клиентскими инструментами в командной строке и в графическом интерфейсе для доступа к репозиторию GitHub. Средство командной строки Git Bash работает с Git и GitHub. В среде Visual Studio, которая установлена на виртуальной машине DSVM, имеются расширения Git. В меню "Пуск" и на рабочем столе есть значки для этих инструментов.
git clone Используйте команду для скачивания кода из репозитория GitHub. Чтобы скачать репозиторий для обработки и анализа данных, опубликованный корпорацией Майкрософт, в текущий каталог, выполните следующую команду в Git Bash:
git clone https://github.com/Azure/DataScienceVM.git
Visual Studio может обрабатывать ту же операцию клонирования. На этом снимке экрана показано, как получить доступ к средствам Git и GitHub в Visual Studio:

Вы можете работать с доступными github.com ресурсами в репозитории GitHub. Дополнительные сведения см. в ресурсе памятки GitHub.
Доступ к службам данных и службам аналитики Azure
Хранилище BLOB-объектов Azure
Хранилище BLOB-объектов Azure — это надежная облачная служба хранилища как для больших, так и для небольших ресурсов данных. В этом разделе описывается перемещение данных в хранилище BLOB-объектов и доступ к данным, хранящимся в большом двоичном объекте Azure.
Необходимые компоненты
Учетная запись хранения BLOB-объектов Azure, созданная в портал Azure.
Убедитесь, что средство AzCopy командной строки предустановлено с помощью следующей команды:
C:\Program Files (x86)\Microsoft SDKs\Azure\AzCopy\azcopy.exeКаталог, на котором размещена azcopy.exe, уже находится в переменной среды PATH, поэтому при запуске этого средства можно избежать ввода полного пути команды. Дополнительные сведения о средстве AzCopy см. в документации по AzCopy.
Запустите инструмент Azure Storage Explorer. Его можно загрузить с веб-страницы обозревателя службы хранилища.


Перемещение данных из виртуальной машины в BLOB-объект Azure: AzCopy
Для перемещения данных между локальными файлами и хранилищем BLOB-объектов AzCopy можно использовать в командной строке или PowerShell:
AzCopy /Source:C:\myfolder /Dest:https://<mystorageaccount>.blob.core.windows.net/<mycontainer> /DestKey:<storage account key> /Pattern:abc.txt
- Замените папку C:\myfolder путем размещения файла в каталоге
- Замените mystorageaccount именем учетной записи хранения BLOB-объектов
- Замените mycontainer именем контейнера
- Замена ключа учетной записи хранения ключом доступа к хранилищу BLOB-объектов
Данные вашей учетной записи хранения находятся на портале Azure.
Выполните команду AzCopy в PowerShell или командной строке. Ниже приведены примеры команд AzCopy:
# Copy *.sql from a local machine to an Azure blob
"C:\Program Files (x86)\Microsoft SDKs\Azure\AzCopy\azcopy" /Source:"c:\Aaqs\Data Science Scripts" /Dest:https://[ENTER STORAGE ACCOUNT].blob.core.windows.net/[ENTER CONTAINER] /DestKey:[ENTER STORAGE KEY] /S /Pattern:*.sql
# Copy back all files from an Azure blob container to a local machine
"C:\Program Files (x86)\Microsoft SDKs\Azure\AzCopy\azcopy" /Dest:"c:\Aaqs\Data Science Scripts\temp" /Source:https://[ENTER STORAGE ACCOUNT].blob.core.windows.net/[ENTER CONTAINER] /SourceKey:[ENTER STORAGE KEY] /S
После выполнения команды AzCopy для копирования файла в большой двоичный объект Azure файл появится в обозревателе служба хранилища Azure.

Перемещение данных из виртуальной машины в BLOB-объект Azure: Обозреватель хранилищ Azure
Вы также можете передать данные из локального файла в виртуальной машине с помощью обозревателя служба хранилища Azure:
Чтобы отправить данные в контейнер, выберите целевой контейнер и нажмите кнопку "Отправить ".
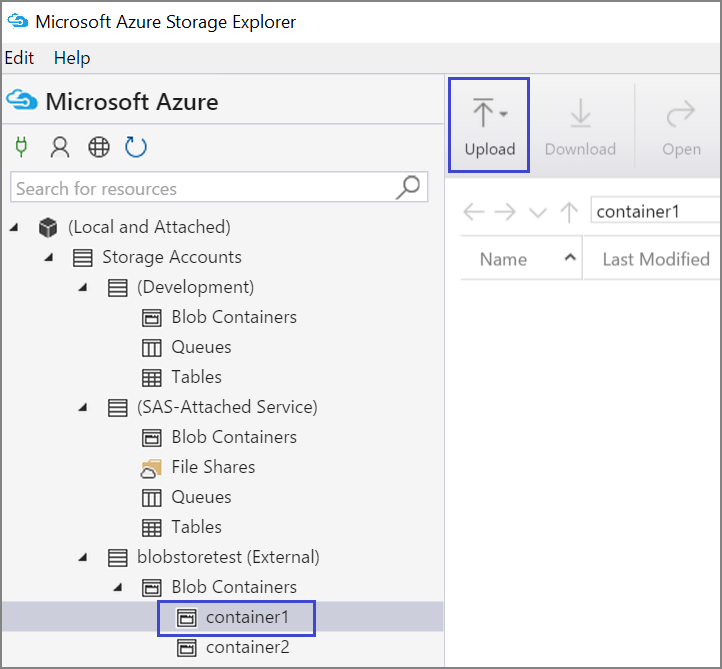
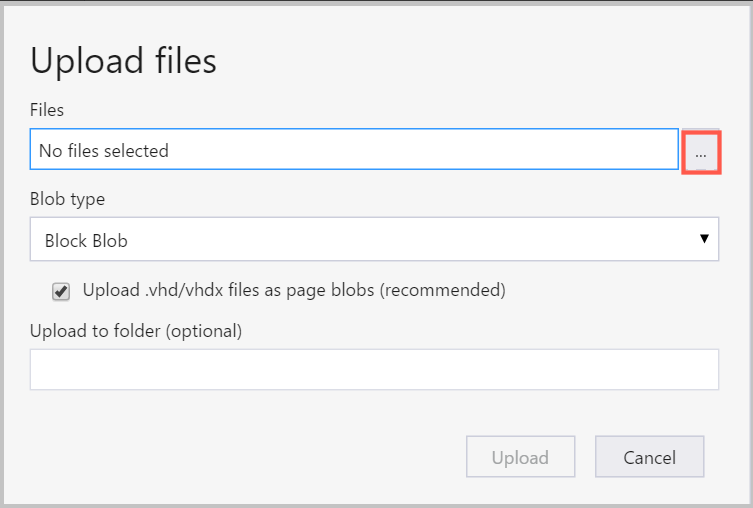
Справа от поля "Файлы " выберите многоточие (...), выберите один или несколько файлов для отправки из файловой системы и нажмите кнопку "Отправить ", чтобы начать отправку файлов.


Чтение данных из BLOB-объекта Azure: Python ODBC
Библиотека BLOBService может считывать данные непосредственно из большого двоичного объекта, расположенного в Jupyter Notebook или в программе Python. Сначала нужно импортировать необходимые пакеты:
import pandas as pd
from pandas import Series, DataFrame
import numpy as np
import matplotlib.pyplot as plt
from time import time
import pyodbc
import os
from azure.storage.blob import BlobService
import tables
import time
import zipfile
import random
Подключите учетные данные учетной записи хранения BLOB-объектов и считывает данные из большого двоичного объекта:
CONTAINERNAME = 'xxx'
STORAGEACCOUNTNAME = 'xxxx'
STORAGEACCOUNTKEY = 'xxxxxxxxxxxxxxxx'
BLOBNAME = 'nyctaxidataset/nyctaxitrip/trip_data_1.csv'
localfilename = 'trip_data_1.csv'
LOCALDIRECTORY = os.getcwd()
LOCALFILE = os.path.join(LOCALDIRECTORY, localfilename)
#download from blob
t1 = time.time()
blob_service = BlobService(account_name=STORAGEACCOUNTNAME,account_key=STORAGEACCOUNTKEY)
blob_service.get_blob_to_path(CONTAINERNAME,BLOBNAME,LOCALFILE)
t2 = time.time()
print(("It takes %s seconds to download "+BLOBNAME) % (t2 - t1))
#unzip downloaded files if needed
#with zipfile.ZipFile(ZIPPEDLOCALFILE, "r") as z:
# z.extractall(LOCALDIRECTORY)
df1 = pd.read_csv(LOCALFILE, header=0)
df1.columns = ['medallion','hack_license','vendor_id','rate_code','store_and_fwd_flag','pickup_datetime','dropoff_datetime','passenger_count','trip_time_in_secs','trip_distance','pickup_longitude','pickup_latitude','dropoff_longitude','dropoff_latitude']
print 'the size of the data is: %d rows and %d columns' % df1.shape
Данные считываются в виде блока данных, как показано ниже:

Azure Synapse Analytics и базы данных
Azure Synapse Analytics — это эластичные данные "хранилище как услуга" с корпоративным классом SQL Server. В этом ресурсе описывается подготовка Azure Synapse Analytics. После подготовки Azure Synapse Analytics в этом пошаговом руководстве объясняется, как обрабатывать отправку, изучение и моделирование данных с помощью данных в Azure Synapse Analytics.
Azure Cosmos DB
Azure Cosmos DB — это облачная база данных NoSQL. Он может обрабатывать документы JSON, например, и может хранить и запрашивать документы. В следующих примерах показано, как получить доступ к Azure Cosmos DB из DSVM:
На виртуальной машине DSVM должен быть установлен пакет SDK Python для Azure Cosmos DB. Чтобы обновить его, выполните в командной строке команду
pip install pydocumentdb --upgrade.Создайте учетную запись и базу данных Azure Cosmos DB на портале Azure.
Скачайте средство миграции данных Azure Cosmos DB из Центра загрузки Майкрософт и извлеките его в выбранный каталог.
Импортируйте данные JSON (данные вулкана), хранящиеся в общедоступном BLOB-объекте, в Azure Cosmos DB со следующими параметрами команды в средство миграции. (Используйте dtui.exe из каталога, в который установлен инструмент переноса данных Azure Cosmos DB.) Укажите исходное и целевое расположение с помощью следующих параметров:
/s:JsonFile /s.Files:https://data.humdata.org/dataset/a60ac839-920d-435a-bf7d-25855602699d/resource/7234d067-2d74-449a-9c61-22ae6d98d928/download/volcano.json /t:DocumentDBBulk /t.ConnectionString:AccountEndpoint=https://[DocDBAccountName].documents.azure.com:443/;AccountKey=[[KEY];Database=volcano /t.Collection:volcano1
После импортирования данных можно перейти в Jupyter и открыть записную книжку с названием DocumentDBSample. Он содержит код Python для доступа к Azure Cosmos DB и обработки некоторых базовых запросов. Дополнительные сведения о Azure Cosmos DB см. на странице документации по службе Azure Cosmos DB.
Использование отчетов и панелей мониторинга Power BI
Вы можете визуализировать JSON-файл Вулкана, описанный в предыдущем примере Azure Cosmos DB в Power BI Desktop, для визуального анализа данных. В этой статье Power BI приведены подробные инструкции. Ниже приведены шаги на высоком уровне:
- Откройте Power BI Desktop и нажмите кнопку "Получить данные". Укажите этот URL-адрес:
https://cahandson.blob.core.windows.net/samples/volcano.json. - Записи JSON, импортированные в виде списка, должны стать видимыми. Преобразуйте список в таблицу, чтобы Power BI работала с ней.
- Щелкните значок развертывания (стрелка), чтобы развернуть столбцы.
- Расположение — это поле записи . Разверните запись и выберите только координаты. Координата — это столбец списка.
- Добавьте новый столбец, чтобы преобразовать столбец координат списка в столбец с разделителями-запятыми LatLong. Используйте формулу
Text.From([coordinates]{1})&","&Text.From([coordinates]{0})для объединения двух элементов в поле списка координат. - Преобразуйте столбец "Повышение прав " в десятичное значение и нажмите кнопки "Закрыть " и "Применить ".
Приведенный ниже код можно использовать в качестве альтернативы приведенным выше шагам. Он выполняет скрипты, которые используются в Расширенный редактор в Power BI для записи преобразований данных на языке запросов:
let
Source = Json.Document(Web.Contents("https://cahandson.blob.core.windows.net/samples/volcano.json")),
#"Converted to Table" = Table.FromList(Source, Splitter.SplitByNothing(), null, null, ExtraValues.Error),
#"Expanded Column1" = Table.ExpandRecordColumn(#"Converted to Table", "Column1", {"Volcano Name", "Country", "Region", "Location", "Elevation", "Type", "Status", "Last Known Eruption", "id"}, {"Volcano Name", "Country", "Region", "Location", "Elevation", "Type", "Status", "Last Known Eruption", "id"}),
#"Expanded Location" = Table.ExpandRecordColumn(#"Expanded Column1", "Location", {"coordinates"}, {"coordinates"}),
#"Added Custom" = Table.AddColumn(#"Expanded Location", "LatLong", each Text.From([coordinates]{1})&","&Text.From([coordinates]{0})),
#"Changed Type" = Table.TransformColumnTypes(#"Added Custom",{{"Elevation", type number}})
in
#"Changed Type"
Теперь ваши данные находятся в модели данных Power BI. Экземпляр Power BI Desktop должен выглядеть следующим образом:

Вы можете начать создание отчетов и визуализаций с помощью модели данных. В этой статье Power BI объясняется, как создать отчет.
Динамическое масштабирование DSVM
Вы можете масштабировать DSVM вверх и вниз, чтобы удовлетворить потребности проекта. Если виртуальную машину не нужно использовать по вечерам или в выходные дни, то ее работу можно завершить с помощью портала Azure.
Примечание.
Плата за вычисления взимается, если на виртуальной машине используется только кнопка завершения работы операционной системы. Вместо этого необходимо освободить dsVM с помощью портал Azure или Cloud Shell.
Для крупномасштабных проектов анализа может потребоваться больше ресурсов ЦП, памяти или диска. Если это так, вы можете найти виртуальные машины с разными числами ядер ЦП, емкостью памяти, типами дисков (включая твердотельные диски) и экземплярами на основе GPU для глубокого обучения, которые соответствуют вашим потребностям вычислений и бюджета. На странице цен На Виртуальные машины Azure отображается полный список виртуальных машин, а также их почасовые цены на вычисления.
Добавить еще инструменты
DSVM предлагает предварительно созданные средства, которые могут решать многие распространенные потребности аналитики данных. Они экономят время, так как вам не нужно отдельно устанавливать и настраивать среды. Они также экономит вам деньги, потому что вы оплачиваете только используемые вами ресурсы.
Вы можете использовать другие службы данных и аналитические службы Azure, упомянутые в этой статье, чтобы оптимизировать имеющуюся у вас среду, предназначенную для выполнения анализа. В некоторых случаях вам могут потребоваться другие средства, включая определенные собственные партнерские инструменты. У вас есть полный административный доступ на виртуальной машине, чтобы установить необходимые средства. Вы также можете установить другие пакеты в Python и R, которые не предварительно установлены. Для Python можно использовать conda или pip. Для R в консоли можно использовать install.packages() или в интегрированной среде разработки выбрать последовательно в меню Пакеты>Установить пакеты.
Глубокое обучение
Помимо примеров на основе платформы, вы можете получить набор комплексных пошаговых руководств, которые были проверены на dsVM. Эти пошаговые руководства помогут вам начать разработку приложений глубокого обучения в доменах анализа изображений и текста и языка.
Запуск нейронных сетей на разных платформах: В этом руководстве демонстрируется, как переносить код с одной платформы на другую. В нем также показано, как сравнивать модели и производительность среды выполнения в разных платформах.
Практическое руководство по созданию комплексного решения для обнаружения продуктов в изображениях: метод обнаружения изображений может находить и классифицировать объекты в изображениях. Эта технология может быть очень полезна во многих сферах бизнеса в реальной жизни. Например, розничные торговцы могут использовать этот метод для идентификации продукта, который клиент взял с полки. Эта информация помогает розничным магазинам управлять инвентаризацией продуктов.
Глубокое обучение для звуковых данных: В этом учебном руководстве показано, как подготовить модель глубокого обучения для распознавания звуковых событий в наборе данных городских звуков. Здесь также приводятся общие сведения о работе со звуковыми данными.
Классификация текстовых документов: В этом руководстве показано, как создать и обучить две архитектуры нейронных сетей: сеть, ориентированную на иерархию, и сеть долгой краткосрочной памяти (LSTM). Эти нейронные сети используют API Keras для глубокого обучения для классификации текстовых документов.
Итоги
В этой статье описана только часть задач, которые можно решать с помощью виртуальной машины Майкрософт, предназначенной для обработки и анализа данных. Существует множество средств, позволяющих сделать DSVM эффективной аналитической средой.