Исключения OutOfMemoryError для Apache Spark в Azure HDInsight
В этой статье описываются действия по устранению неполадок и возможные способы исправления проблем, возникающих при использовании компонентов Apache Spark в кластерах Azure HDInsight.
Сценарий: исключение OutOfMemoryError для Apache Spark
Проблема
Сбой приложения Apache Spark с необработанным исключением OutOfMemoryError. Возможно, появляется сообщение об ошибке следующего вида:
ERROR Executor: Exception in task 7.0 in stage 6.0 (TID 439)
java.lang.OutOfMemoryError
at java.io.ByteArrayOutputStream.hugeCapacity(Unknown Source)
at java.io.ByteArrayOutputStream.grow(Unknown Source)
at java.io.ByteArrayOutputStream.ensureCapacity(Unknown Source)
at java.io.ByteArrayOutputStream.write(Unknown Source)
at java.io.ObjectOutputStream$BlockDataOutputStream.drain(Unknown Source)
at java.io.ObjectOutputStream$BlockDataOutputStream.setBlockDataMode(Unknown Source)
at java.io.ObjectOutputStream.writeObject0(Unknown Source)
at java.io.ObjectOutputStream.writeObject(Unknown Source)
at org.apache.spark.serializer.JavaSerializationStream.writeObject(JavaSerializer.scala:44)
at org.apache.spark.serializer.JavaSerializerInstance.serialize(JavaSerializer.scala:101)
at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:239)
at java.util.concurrent.ThreadPoolExecutor.runWorker(Unknown Source)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(Unknown Source)
at java.lang.Thread.run(Unknown Source)
ERROR SparkUncaughtExceptionHandler: Uncaught exception in thread Thread[Executor task launch worker-0,5,main]
java.lang.OutOfMemoryError
at java.io.ByteArrayOutputStream.hugeCapacity(Unknown Source)
...
Причина
Наиболее вероятной причиной этого исключения является нехватка памяти кучи, выделенной для виртуальных машин Java. Эти виртуальные машины Java запускаются как исполнители или драйверы в рамках приложения Apache Spark.
Разрешение
Определите максимальный объем данных, которые обрабатывает приложение Spark. Оцените размер, исходя из максимального размера входных данных, промежуточных данных, создаваемых при преобразовании входных данных, и выходных данных, получаемых при дальнейшем преобразовании промежуточных данных. Если начальная оценка недостаточна, слегка увеличьте размер и выполняйте итерации, пока ошибки памяти не исчезнут.
Убедитесь, что в кластере HDInsight, который должен использоваться, достаточно ресурсов, таких как память и количество ядер, для работы приложения Spark. Это можно определить, просмотрев в разделе "Метрики кластера" пользовательского интерфейса YARN кластера и сравнив значения параметров Используемая память и Всего памяти, Используемые виртуальные ядра и Всего виртуальных ядер.

Установите соответствующие значения для следующих конфигураций Spark. Сбалансируйте требования приложения с помощью доступных ресурсов в кластере. Эти значения не должны превышать 90 % доступной памяти и ядер, которые рассматриваются YARN, а также должны соответствовать минимальному требованию к памяти приложения Spark:
spark.executor.instances (Example: 8 for 8 executor count) spark.executor.memory (Example: 4g for 4 GB) spark.yarn.executor.memoryOverhead (Example: 384m for 384 MB) spark.executor.cores (Example: 2 for 2 cores per executor) spark.driver.memory (Example: 8g for 8GB) spark.driver.cores (Example: 4 for 4 cores) spark.yarn.driver.memoryOverhead (Example: 384m for 384MB)Общий объем памяти, используемый всеми исполнителями =
spark.executor.instances * (spark.executor.memory + spark.yarn.executor.memoryOverhead)Общий объем памяти, используемый драйвером =
spark.driver.memory + spark.yarn.driver.memoryOverhead
Сценарий: ошибка пространства кучи Java при попытке открыть сервер журнала Apache Spark
Проблема
При открытии событий на сервере журнала Spark появляется следующее сообщение об ошибке:
scala.MatchError: java.lang.OutOfMemoryError: Java heap space (of class java.lang.OutOfMemoryError)
Причина
Эта проблема часто возникает из-за недостатка ресурсов при открытии больших файлов событий Spark. Размер кучи Spark по умолчанию устанавливается равным 1 ГБ, но для больших файлов событий Spark может потребоваться больше места.
Если вы хотите проверить размер файлов, которые вы пытаетесь загрузить, можно выполнить следующие команды:
hadoop fs -du -s -h wasb:///hdp/spark2-events/application_1503957839788_0274_1/
**576.5 M** wasb:///hdp/spark2-events/application_1503957839788_0274_1
hadoop fs -du -s -h wasb:///hdp/spark2-events/application_1503957839788_0264_1/
**2.1 G** wasb:///hdp/spark2-events/application_1503957839788_0264_1
Разрешение
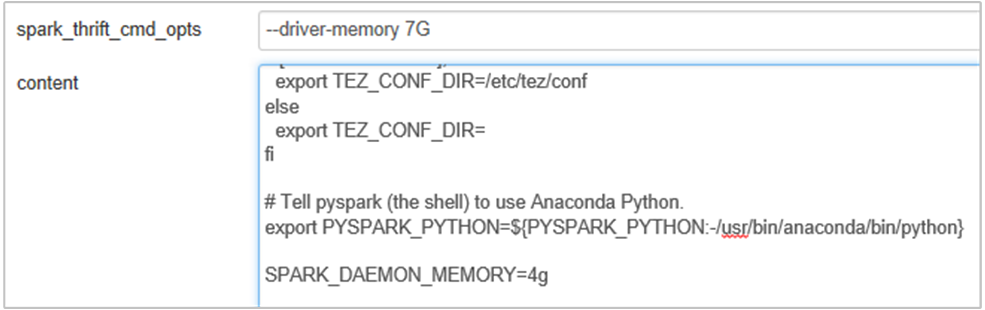
Можно увеличить объем памяти сервера журнала Spark, отредактировав свойство SPARK_DAEMON_MEMORY в конфигурации Spark и перезапустив все службы.
Это можно сделать в пользовательском интерфейсе браузера Ambari, выбрав раздел Spark2/Config/Advanced spark2-env.
Добавьте следующее свойство, чтобы изменить объем памяти сервера журнала Spark с 1 ГБ на 4 ГБ: SPARK_DAEMON_MEMORY=4g.
Не забудьте перезапустить все затронутые службы из Ambari.
Сценарий: сервер Livy не запускается в кластере Apache Spark
Проблема
Не удается запустить сервер Livy в Apache Spark [(Spark 2.1 в Linux (HDI 3.6)]. Попытка перезапуска приводит к следующему стеку ошибок в журналах Livy:
17/07/27 17:52:50 INFO CuratorFrameworkImpl: Starting
17/07/27 17:52:50 INFO ZooKeeper: Client environment:zookeeper.version=3.4.6-29--1, built on 05/15/2017 17:55 GMT
17/07/27 17:52:50 INFO ZooKeeper: Client environment:host.name=10.0.0.66
17/07/27 17:52:50 INFO ZooKeeper: Client environment:java.version=1.8.0_131
17/07/27 17:52:50 INFO ZooKeeper: Client environment:java.vendor=Oracle Corporation
17/07/27 17:52:50 INFO ZooKeeper: Client environment:java.home=/usr/lib/jvm/java-8-openjdk-amd64/jre
17/07/27 17:52:50 INFO ZooKeeper: Client environment:java.class.path= <DELETED>
17/07/27 17:52:50 INFO ZooKeeper: Client environment:java.library.path= <DELETED>
17/07/27 17:52:50 INFO ZooKeeper: Client environment:java.io.tmpdir=/tmp
17/07/27 17:52:50 INFO ZooKeeper: Client environment:java.compiler=<NA>
17/07/27 17:52:50 INFO ZooKeeper: Client environment:os.name=Linux
17/07/27 17:52:50 INFO ZooKeeper: Client environment:os.arch=amd64
17/07/27 17:52:50 INFO ZooKeeper: Client environment:os.version=4.4.0-81-generic
17/07/27 17:52:50 INFO ZooKeeper: Client environment:user.name=livy
17/07/27 17:52:50 INFO ZooKeeper: Client environment:user.home=/home/livy
17/07/27 17:52:50 INFO ZooKeeper: Client environment:user.dir=/home/livy
17/07/27 17:52:50 INFO ZooKeeper: Initiating client connection, connectString=<zookeepername1>.cxtzifsbseee1genzixf44zzga.gx.internal.cloudapp.net:2181,<zookeepername2>.cxtzifsbseee1genzixf44zzga.gx.internal.cloudapp.net:2181,<zookeepername3>.cxtzifsbseee1genzixf44zzga.gx.internal.cloudapp.net:2181 sessionTimeout=60000 watcher=org.apache.curator.ConnectionState@25fb8912
17/07/27 17:52:50 INFO StateStore$: Using ZooKeeperStateStore for recovery.
17/07/27 17:52:50 INFO ClientCnxn: Opening socket connection to server 10.0.0.61/10.0.0.61:2181. Will not attempt to authenticate using SASL (unknown error)
17/07/27 17:52:50 INFO ClientCnxn: Socket connection established to 10.0.0.61/10.0.0.61:2181, initiating session
17/07/27 17:52:50 INFO ClientCnxn: Session establishment complete on server 10.0.0.61/10.0.0.61:2181, sessionid = 0x25d666f311d00b3, negotiated timeout = 60000
17/07/27 17:52:50 INFO ConnectionStateManager: State change: CONNECTED
17/07/27 17:52:50 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
17/07/27 17:52:50 INFO AHSProxy: Connecting to Application History server at headnodehost/10.0.0.67:10200
Exception in thread "main" java.lang.OutOfMemoryError: unable to create new native thread
at java.lang.Thread.start0(Native Method)
at java.lang.Thread.start(Thread.java:717)
at com.cloudera.livy.Utils$.startDaemonThread(Utils.scala:98)
at com.cloudera.livy.utils.SparkYarnApp.<init>(SparkYarnApp.scala:232)
at com.cloudera.livy.utils.SparkApp$.create(SparkApp.scala:93)
at com.cloudera.livy.server.batch.BatchSession$$anonfun$recover$2$$anonfun$apply$4.apply(BatchSession.scala:117)
at com.cloudera.livy.server.batch.BatchSession$$anonfun$recover$2$$anonfun$apply$4.apply(BatchSession.scala:116)
at com.cloudera.livy.server.batch.BatchSession.<init>(BatchSession.scala:137)
at com.cloudera.livy.server.batch.BatchSession$.recover(BatchSession.scala:108)
at com.cloudera.livy.sessions.BatchSessionManager$$anonfun$$init$$1.apply(SessionManager.scala:47)
at com.cloudera.livy.sessions.BatchSessionManager$$anonfun$$init$$1.apply(SessionManager.scala:47)
at scala.collection.TraversableLike$$anonfun$map$1.apply(TraversableLike.scala:244)
at scala.collection.TraversableLike$$anonfun$map$1.apply(TraversableLike.scala:244)
at scala.collection.mutable.ResizableArray$class.foreach(ResizableArray.scala:59)
at scala.collection.mutable.ArrayBuffer.foreach(ArrayBuffer.scala:47)
at scala.collection.TraversableLike$class.map(TraversableLike.scala:244)
at scala.collection.AbstractTraversable.map(Traversable.scala:105)
at com.cloudera.livy.sessions.SessionManager.com$cloudera$livy$sessions$SessionManager$$recover(SessionManager.scala:150)
at com.cloudera.livy.sessions.SessionManager$$anonfun$1.apply(SessionManager.scala:82)
at com.cloudera.livy.sessions.SessionManager$$anonfun$1.apply(SessionManager.scala:82)
at scala.Option.getOrElse(Option.scala:120)
at com.cloudera.livy.sessions.SessionManager.<init>(SessionManager.scala:82)
at com.cloudera.livy.sessions.BatchSessionManager.<init>(SessionManager.scala:42)
at com.cloudera.livy.server.LivyServer.start(LivyServer.scala:99)
at com.cloudera.livy.server.LivyServer$.main(LivyServer.scala:302)
at com.cloudera.livy.server.LivyServer.main(LivyServer.scala)
## using "vmstat" found we had enough free memory
Причина
java.lang.OutOfMemoryError: unable to create new native thread выделение ОС не может назначать больше собственных потоков виртуальным машинам. Подтверждено, что это исключение вызвано превышением числа потоков для каждого процесса.
Когда сервер Livy завершается неожиданно, все подключения к кластерам Spark также завершаются, что означает, что все задания и связанные данные теряются. В механизме восстановления сеанса HDP 2.6 Livy сохраняет сведения о сеансе в Zookeeper для восстановления после перезапуска сервера Livy.
При отправке большого количества заданий через Livy в рамках высокого уровня доступности для сервера Livy хранятся эти состояния сеанса в ZK (в кластерах HDInsight) и восстанавливаются эти сеансы при перезапуске службы Livy. При перезапуске после неожиданного завершения Livy создает один поток на сеанс, и это накапливает некоторые сеансы для восстановления, что приводит к созданию слишком большого количества потоков.
Разрешение
Удалите все записи, выполнив следующие действия.
Получите IP-адреса узлов Zookeeper с помощью
grep -R zk /etc/hadoop/confВыше приведен список всех зоопарков для кластера
/etc/hadoop/conf/core-site.xml: <value><zookeepername1>.lnuwp5akw5ie1j2gi2amtuuimc.dx.internal.cloudapp.net:2181,<zookeepername2>.lnuwp5akw5ie1j2gi2amtuuimc.dx.internal.cloudapp.net:2181,<zookeepername3>.lnuwp5akw5ie1j2gi2amtuuimc.dx.internal.cloudapp.net:2181</value>Получение всех IP-адресов узлов zookeeper с помощью ping Или вы также можете подключиться к zookeeper из головного узла с помощью имени zookeeper
/usr/hdp/current/zookeeper-client/bin/zkCli.sh -server <zookeepername1>:2181После подключения к zookeeper выполните следующую команду, чтобы получить список всех сеансов, которые пытаются перезапустить.
В большинстве случаев список может включать в себя более чем 8000 сеансов ####
ls /livy/v1/batchСледующая команда позволяет удалить все сеансы, подлежащие восстановлению. #####
rmr /livy/v1/batch
Дождитесь завершения выполнения приведенной выше команды и возврата курсора в командную строку, а затем перезапустите службу Livy из Ambari, что должно произойти без ошибок.
Примечание.
DELETE сеанс Livy после завершения его выполнения. Сеансы пакетной службы Livy не будут удаляться автоматически сразу после завершения работы приложения Spark, что не является ошибкой. Сеанс Livy — это сущность, созданная запросом POST к серверу Livy REST. Для удаления этой сущности требуется вызвать DELETE. Или следует подождать запуска сборщика мусора.
Следующие шаги
Если вы не видите своего варианта проблемы или вам не удается ее устранить, дополнительные сведения можно получить, посетив один из следующих каналов.
Получите ответы специалистов Azure на сайте поддержки сообщества пользователей Azure.
Подпишитесь на @AzureSupport — официальный канал Microsoft Azure для улучшения качества взаимодействия с клиентами. Вступайте в сообщество Azure для получения нужных ресурсов: ответов, поддержки и советов экспертов.
Если вам нужна дополнительная помощь, отправьте запрос в службу поддержки на портале Azure. Выберите Поддержка в строке меню или откройте центр Справка и поддержка. Дополнительные сведения см. в статье Создание запроса на поддержку Azure. Доступ к управлению подписками и поддержкой выставления счетов уже включен в вашу подписку Microsoft Azure, а техническая поддержка предоставляется в рамках одного из планов Службы поддержки Azure.