Как использовать репликацию Apache Hive в кластерах Azure HDInsight
В контексте баз данных и хранилищ репликация — это процесс копирования сущностей из одного хранилища в другое. Дублирование может применяться ко всей базе данных или к меньшему уровню, например к таблице или секции. Целью является наличие реплики, которая изменяется при изменении базовой сущности. Репликация в Apache Hive фокусируется на аварийном восстановлении и предлагает однонаправленную репликацию первичного копирования. В кластерах HDInsight репликация Hive может использоваться для однонаправленной репликации хранилища метаданных Hive и связанных с ним базовых данных озера данных на Azure Data Lake Storage 2-го поколения.
Репликация Hive развивалась в течение многих лет, а ее новые версии обеспечивают лучшую функциональность, скорость работы меньшую ресурсоемкость. В этой статье рассматривается репликация (Replv2) Hive, которая поддерживается как в типах кластеров HDInsight 3.6, так и HDInsight 4.0.
Преимущества replv2
Hive ReplicationV2 (также называемый Replv2) имеет следующие преимущества по сравнению с первой версией репликации Hive, которая использовала Hive IMPORT-EXPORT:
- Добавочная репликация на основе событий
- Репликация на момент времени
- Сниженные требования к пропускной способности
- Сокращение количества промежуточных копий
- Состояние репликации сохраняется
- Ограниченная репликация
- Поддержка звездообразной модели
- Поддержка таблиц ACID (в HDInsight 4.0)
Этапы репликации
Репликация Hive на основе событий настраивается между основным и дополнительным кластерами. Этот процесс репликации состоит из двух отдельных фаз — начальная загрузка и добавочные запуски.
Начальная загрузка
Начальная загрузка предназначена для однократного выполнения репликации базового состояния баз данных с первичной на вторичную. При необходимости можно настроить начальную загрузку, чтобы включить подмножество таблиц целевой базы данных, в которых необходимо включить репликацию.
Добавочные запуски
Добавочные запуски выполняются автоматически в основном кластере после начальной загрузки, а события, сгенерированные при добавочных запусках, воспроизводятся в дополнительном кластере. Когда дополнительный кластер начинает подключаться к основному кластеру, он будет согласовываться с событиями основного.
Команды репликации
Hive предоставляет набор команд REPL (DUMP, LOAD и STATUS) для оркестрирования потока событий. Команда DUMP создает локальный журнал всех событий DDL / DML в основном кластере. Команда LOAD является подходом к отложенному копированию метаданных и данных, регистрируемых в извлеченных резервных копиях данных репликации, и выполняется в целевом кластере. Команда STATUS выполняется из целевого кластера, чтобы предоставить актуальный идентификатор события, который был успешно реплицирован последней нагрузкой репликации.
Настройка источника репликации
Перед началом работы с репликацией убедитесь, что база данных, которая должна быть реплицирована, задана в качестве источника репликации. Можно использовать команду DESC DATABASE EXTENDED <db_name>, чтобы определить, задан ли параметр repl.source.for с именем политики.
Если политика запланирована и параметр repl.source.for не задан, необходимо сначала задать этот параметр с помощью ALTER DATABASE <db_name> SET DBPROPERTIES ('repl.source.for'='<policy_name>').
ALTER DATABASE tpcds_orc SET DBPROPERTIES ('repl.source.for'='replpolicy1')
Дамп метаданных в озере данных
Команда REPL DUMP [database name]. => location / event_id используется на этапе начальной загрузки для дампа соответствующих метаданных в Azure Data Lake Storage 2-го поколения. event_id указывает минимальное событие, в которое помещаются соответствующие метаданные в Azure Data Lake Storage 2-го поколения.
repl dump tpcds_orc;
Пример результата:
| dump_dir | last_repl_id |
|---|---|
| /tmp/hive/repl/38896729-67d5-41b2-90dc-46eeed4c5dd0 | 2925 |
Загрузка данных в целевой кластер
Команда REPL LOAD [database name] FROM [ location ] { WITH ( ‘key1’=‘value1’{, ‘key2’=‘value2’} ) } используется для загрузки данных в целевой кластер как для начальной загрузки, так и для добавочных фаз репликации. [database name] может совпадать с источником или другим именем в целевом кластере. Объект [location] представляет расположение из выходных данных предыдущей команды REPL DUMP. Это означает, что целевой кластер должен иметь возможность взаимодействовать с исходным кластером. Предложение WITH было в основном добавлено для предотвращения перезапуска целевого кластера, что позволяет выполнять репликацию.
repl load tpcds_orc from '/tmp/hive/repl/38896729-67d5-41b2-90dc-46eeed4c5dd0';
Вывод идентификатора последнего реплицированного события
Команда REPL STATUS [database name] выполняется в целевых кластерах и выводит последний реплицированный объект event_id. Эта команда также позволяет пользователям знать, в каком состоянии реплицируется целевой кластер. Выходные данные этой команды можно использовать для создания следующей команды REPL DUMP для добавочной репликации.
repl status tpcds_orc;
Пример результата:
| last_repl_id |
|---|
| 2925 |
Дамп релевантных данных и метаданных в озеро данных
Команда REPL DUMP [database name] FROM [event-id] { TO [event-id] } { LIMIT [number of events] } используется для дампа соответствующих метаданных и данных в Azure Data Lake Storage. Эта команда используется на добавочной фазе и выполняется в исходном хранилище. Для добавочной фазы необходим параметр FROM [event-id], а значение event-id может быть получено путем выполнения команды REPL STATUS [database name] в целевом хранилище.
repl dump tpcds_orc from 2925;
Пример результата:
| dump_dir | last_repl_id |
|---|---|
| /tmp/hive/repl/38896729-67d5-41b2-90dc-466466agadd0 | 2960 |
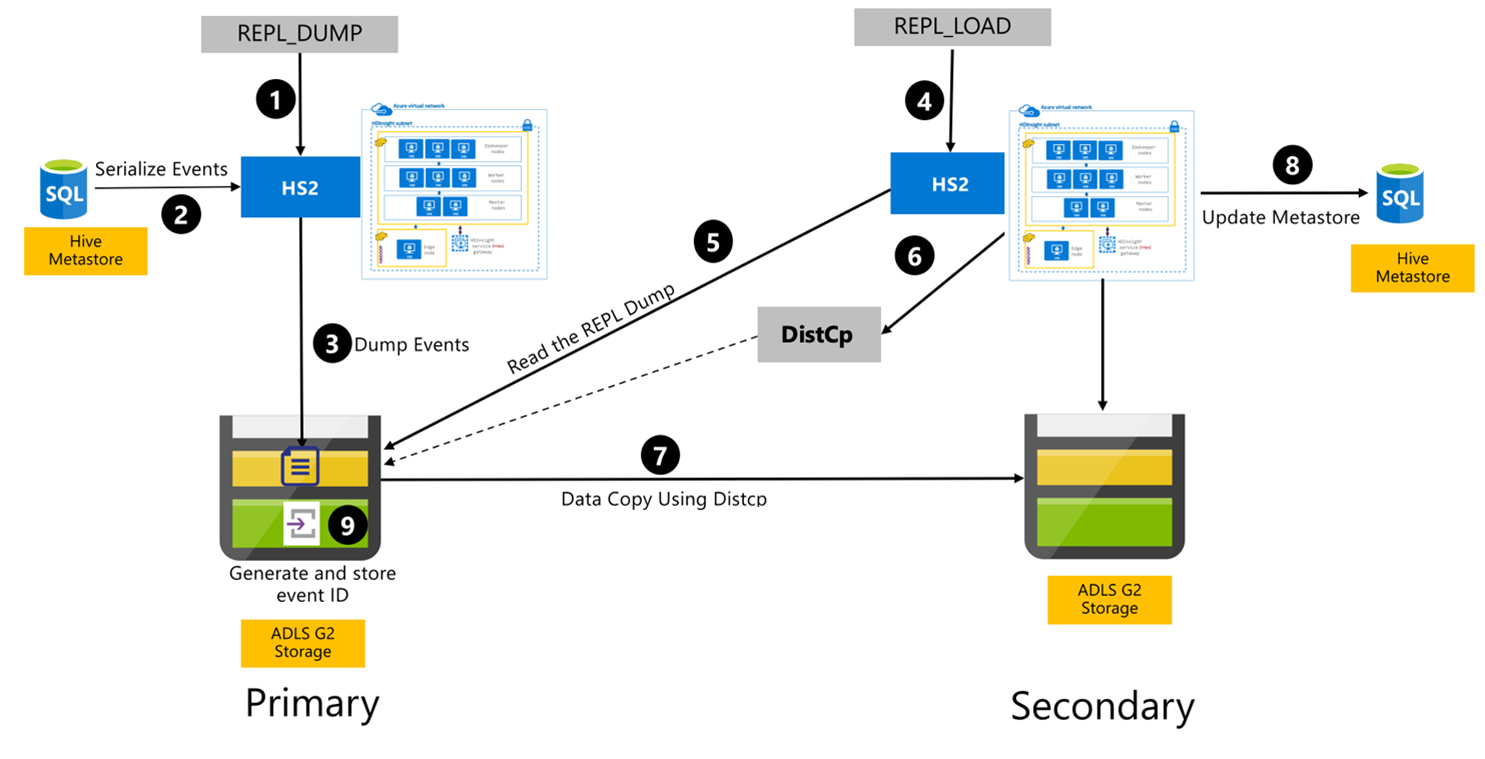
Процесс репликации Hive
Следующие шаги являются последовательными событиями, происходящими во время процесса репликации Hive.
Убедитесь, что таблицы для репликации заданы в качестве источника репликации для определенной политики.
Команда
REPL_DUMPдается основному кластеру с соответствующими ограничениями, такими как имя базы данных, диапазон идентификаторов событий и URL-адрес хранилища Azure Data Lake Storage 2-го поколения.Система сериализует дамп всех отслеживаемых событий от хранилища метаданных до последнего действия. Этот дамп хранится в учетной записи хранения Azure Data Lake Storage 2-го поколения в основном кластере по URL-адресу, указанному параметром
REPL_DUMP.Основной кластер сохраняет метаданные репликации в хранилище Azure Data Lake Storage 2-го поколения основного кластера. Путь можно настроить в пользовательском интерфейсе настройки Hive в Ambari. Процесс предоставляет путь, по которому хранятся метаданные, и идентификатор последнего отслеживаемого события DML / DDL.
Команда
REPL_LOADвыдается из дополнительного кластера. Команда указывает путь, настроенный на шаге 3.Дополнительный кластер считывает файл метаданных с отслеживающими событиями, созданными на шаге 3. Убедитесь, что дополнительный кластер имеет сетевое подключение к хранилищу Azure Data Lake Storage 2-го поколения основного кластера, в котором хранятся отслеживаемые события
REPL_DUMP.Вторичный кластер порождает вычисление распределенной копии (
DistCP).Вторичный кластер копирует данные из хранилища основного кластера.
Хранилище метаданных в дополнительном кластере обновляется.
Последний записанный идентификатор события хранится в первичном хранилище метаданных.
Добавочная репликация выполняется таким же образом и требует наличия идентификатора последнего реплицированного события в качестве входных данных. Это приводит к добавочному копированию с момента последнего события репликации. Добавочные репликации обычно автоматизируются с предварительно определенной частотой для достижения требуемой целевой точки восстановления (RPO).
Шаблоны репликации
Репликация обычно настраивается однонаправленным способом между основным и дополнительным элементами, где основной элемент обслуживает запросы на чтение и запись. Дополнительный кластер предназначен только для запросов на чтение. Операции записи на дополнительном кластере разрешены только в случае аварии, но при этом необходимо настроить обратную репликацию в основной кластер.
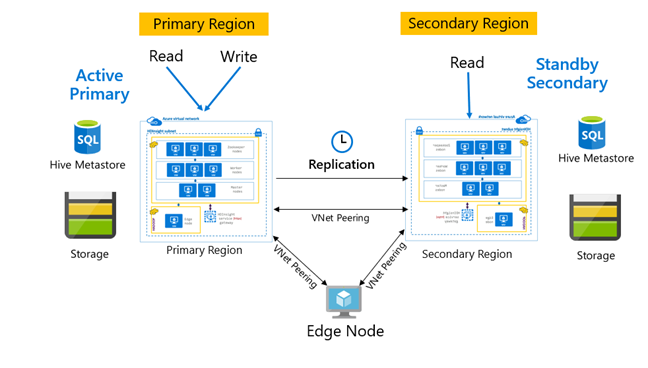
Для репликации Hive доступно множество шаблонов, в том числе первичная — вторичная, звездообразная модель, а также ретрансляция.
В HDInsight "Активный основной — резервный дополнительный" является распространенным шаблоном непрерывности бизнес-процессов и аварийного восстановления (BCDR), и HiveReplicationV2 может использовать этот шаблон с разделенными по регионам кластерами HDInsight Hadoop с пирингом виртуальной сети. Для размещения скриптов автоматизации репликации можно использовать общую виртуальную машину для обоих кластеров. Дополнительные сведения о возможных шаблонах BCDR HDInsight см. в Документации по обеспечению непрерывности бизнес-процессов HDInsight.
Репликация Hive с корпоративным пакетом безопасности
В случаях, когда репликация Hive планируется в кластерах HDInsight Hadoop с корпоративным пакетом безопасности, необходимо учитывать механизмы репликации для хранилища метаданных Ranger и доменных служб Microsoft Entra.
Используйте функцию наборов реплик доменных служб Microsoft Entra, чтобы создать несколько наборов реплик доменных служб Microsoft Entra для каждого клиента Microsoft Entra в нескольких регионах. Каждый отдельный набор реплик должен быть соединен с виртуальными сетями HDInsight в соответствующих регионах. В этой конфигурации изменения в доменных службах Microsoft Entra, включая конфигурацию, удостоверение пользователя и учетные данные, группы, объекты групповой политики, объекты компьютера и другие изменения применяются ко всем наборам реплик в управляемом домене с помощью репликации доменных служб Microsoft Entra.
Политики Ranger можно периодически архивировать и реплицировать из основного в дополнительный элемент с помощью функций Ranger Import-Export. Вы можете выбрать репликацию всех или подмножества политик Ranger в зависимости от уровня авторизации, который вы хотите реализовать в дополнительном кластере.
Пример кода
В следующей последовательности кода приведен пример того, как можно реализовать начальную и добавочную репликацию для образца таблицы с именем tpcds_orc.
Задайте таблицу в качестве источника для политики репликации.
ALTER DATABASE tpcds_orc SET DBPROPERTIES ('repl.source. for'='replpolicy1');Дамп начальной загрузки в основном кластере.
repl dump tpcds_orc with ('hive.repl.rootdir'='/tmpag/hiveag/replag');Пример результата:
dump_dir last_repl_id /tmpag/hiveag/replag/675d1bea-2361-4cad-bcbf-8680d305a27a 2925 Нагрузка начальной загрузки в основном кластере.
repl load tpcds_orc from '/tmpag/hiveag/replag 675d1bea-2361-4cad-bcbf-8680d305a27a';Проверьте состояние
REPLво вторичном кластере.repl status tpcds_orc;last_repl_id 2925 Добавочный дамп в основном кластере.
repl dump tpcds_orc from 2925 with ('hive.repl.rootdir'='/tmpag/hiveag/ replag');Пример результата:
dump_dir last_repl_id /tmpag/hiveag/replag/31177ff7-a40f-4f67-a613-3b64ebe3bb31 2960 Добавочная нагрузка в дополнительном кластере.
repl load tpcds_orc from '/tmpag/hiveag/replag/31177ff7-a40f-4f67-a613-3b64ebe3bb31';Проверьте состояние
REPLв дополнительном кластере.repl status tpcds_orc;last_repl_id 2960
Следующие шаги
Дополнительные сведения по темам, обсуждавшимся в этой статье, см. в следующих разделах: