Отправка заданий и управление ими в кластере Apache Spark™ в HDInsight в AKS
Примечание.
Мы отставим Azure HDInsight в AKS 31 января 2025 г. До 31 января 2025 г. необходимо перенести рабочие нагрузки в Microsoft Fabric или эквивалентный продукт Azure, чтобы избежать резкого прекращения рабочих нагрузок. Оставшиеся кластеры в подписке будут остановлены и удалены из узла.
До даты выхода на пенсию будет доступна только базовая поддержка.
Внимание
Эта функция в настоящее время доступна для предварительного ознакомления. Дополнительные условия использования для предварительных версий Microsoft Azure включают более юридические термины, применимые к функциям Azure, которые находятся в бета-версии, в предварительной версии или в противном случае еще не выпущены в общую доступность. Сведения об этой конкретной предварительной версии см. в статье Azure HDInsight в предварительной версии AKS. Для вопросов или предложений функций отправьте запрос на AskHDInsight с подробными сведениями и следуйте за нами для получения дополнительных обновлений в сообществе Azure HDInsight.
После создания кластера пользователь может использовать различные интерфейсы для отправки заданий и управления ими.
- использование Jupyter
- использование Zeppelin
- using ssh (spark-submit)
Использование Jupyter
Необходимые компоненты
Кластер Apache Spark™ в HDInsight в AKS. Дополнительные сведения см. в статье "Создание кластера Apache Spark".
Jupyter Notebook — это интерактивная среда записных книжек, которая поддерживает различные языки программирования.
Создание записной книжки Jupyter
Перейдите на страницу кластера Apache Spark™ и откройте вкладку "Обзор ". Щелкните Jupyter, попросите пройти проверку подлинности и открыть веб-страницу Jupyter.

На веб-странице Jupyter выберите New > PySpark, чтобы создать записную книжку.
Новая записная книжка, созданная и открытая с именем
Untitled(Untitled.ipynb).Примечание.
С помощью ядра PySpark или Python 3 для создания записной книжки сеанс Spark автоматически создается при запуске первой ячейки кода. Вам не нужно явно создавать этот сеанс.
Вставьте следующий код в пустую ячейку записной книжки Jupyter Notebook и нажмите SHIFT+ВВОД для выполнения кода. Дополнительные элементы управления в Jupyter см . здесь .
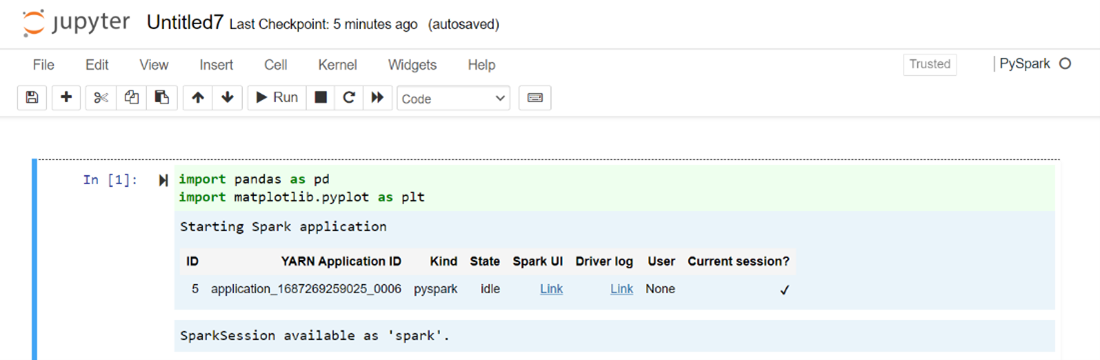
%matplotlib inline import pandas as pd import matplotlib.pyplot as plt data1 = [22,40,10,50,70] s1 = pd.Series(data1) #One-dimensional ndarray with axis labels (including time series). data2 = data1 index = ['John','sam','anna','smith','ben'] s2 = pd.Series(data2,index=index) data3 = {'John':22, 'sam':40, 'anna':10,'smith':50,'ben':70} s3 = pd.Series(data3) s3['jp'] = 32 #insert a new row s3['John'] = 88 names = ['John','sam','anna','smith','ben'] ages = [10,40,50,48,70] name_series = pd.Series(names) age_series = pd.Series(ages) data_dict = {'name':name_series, 'age':age_series} dframe = pd.DataFrame(data_dict) #create a pandas DataFrame from dictionary dframe['age_plus_five'] = dframe['age'] + 5 #create a new column dframe.pop('age_plus_five') #dframe.pop('age') salary = [1000,6000,4000,8000,10000] salary_series = pd.Series(salary) new_data_dict = {'name':name_series, 'age':age_series,'salary':salary_series} new_dframe = pd.DataFrame(new_data_dict) new_dframe['average_salary'] = new_dframe['age']*90 new_dframe.index = new_dframe['name'] print(new_dframe.loc['sam'])График с зарплатой и возрастом в виде осей X и Y
В той же записной книжке вставьте следующий код в пустую ячейку Jupyter Notebook, а затем нажмите клавиши SHIFT+ ВВОД , чтобы запустить код.
%matplotlib inline import pandas as pd import matplotlib.pyplot as plt plt.plot(age_series,salary_series) plt.show()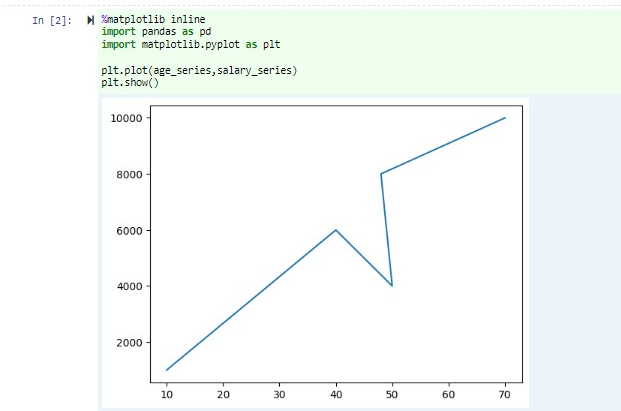




Сохранение записной книжки
В строке меню записной книжки перейдите к разделу "Сохранить файл > " и "Контрольная точка".
Закройте записную книжку, чтобы освободить ресурсы кластера: в строке меню записной книжки перейдите к разделу "Закрыть файл > " и "Остановить". Вы также можете запустить любую из записных книжек в папке examples.


Использование записных книжек Apache Zeppelin
Кластеры Apache Spark в HDInsight в AKS включают записные книжки Apache Zeppelin. Используйте записные книжки для запуска заданий Apache Spark. В этой статье вы узнаете, как использовать записную книжку Zeppelin в HDInsight в кластере AKS.
Необходимые компоненты
Кластер Apache Spark в HDInsight в AKS. Инструкции см. в разделе "Создание кластера Apache Spark".
Запуск записной книжки Apache Zeppelin
Перейдите на страницу обзора кластера Apache Spark и выберите записную книжку Zeppelin на панели мониторинга кластера. Он запрашивает проверку подлинности и открытие страницы Zeppelin.
Создайте новую записную книжку. В области заголовков перейдите в раздел "Создание записной книжки > ". Убедитесь, что в заголовке записной книжки отображается состояние "Подключено". Он обозначает зеленую точку в правом верхнем углу.
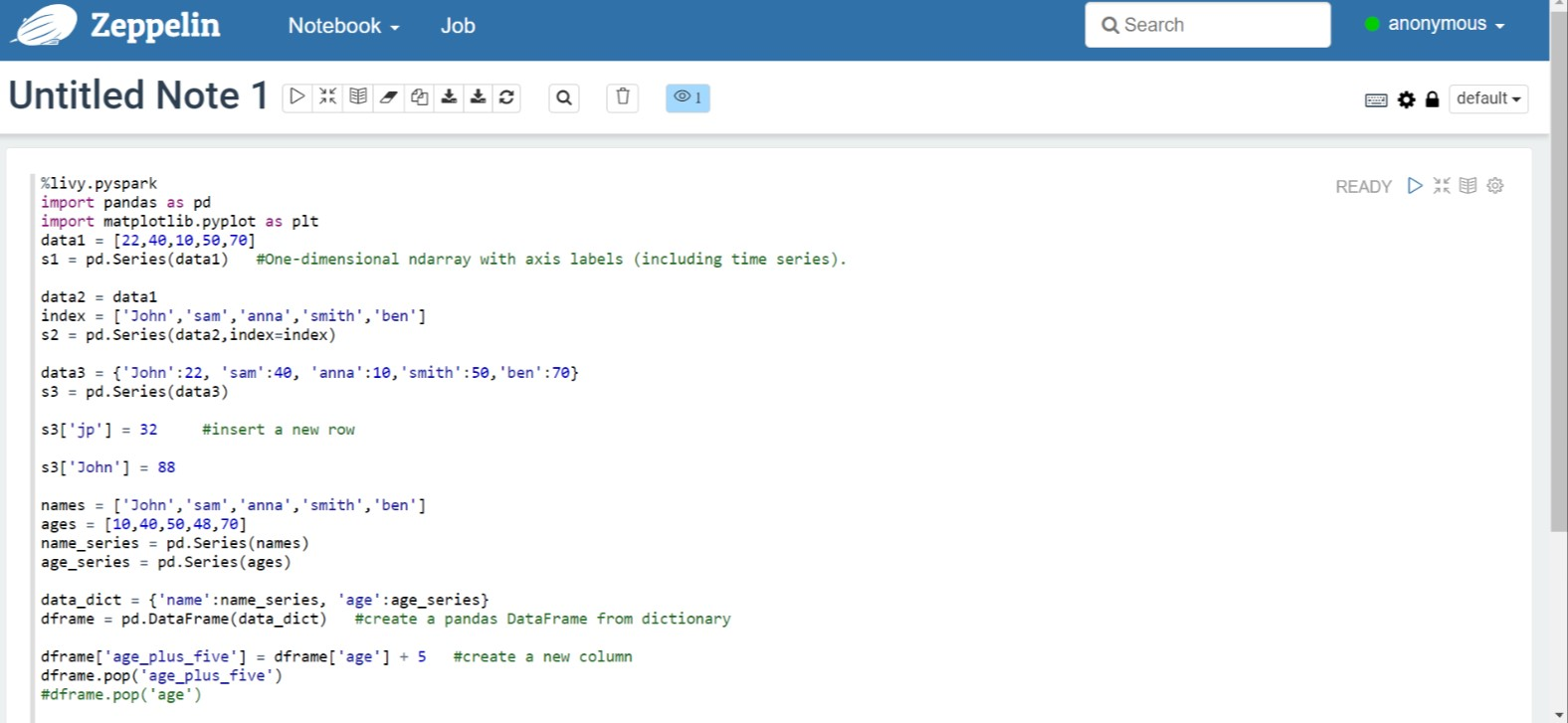
Выполните следующий код в Записной книжке Zeppelin:
%livy.pyspark import pandas as pd import matplotlib.pyplot as plt data1 = [22,40,10,50,70] s1 = pd.Series(data1) #One-dimensional ndarray with axis labels (including time series). data2 = data1 index = ['John','sam','anna','smith','ben'] s2 = pd.Series(data2,index=index) data3 = {'John':22, 'sam':40, 'anna':10,'smith':50,'ben':70} s3 = pd.Series(data3) s3['jp'] = 32 #insert a new row s3['John'] = 88 names = ['John','sam','anna','smith','ben'] ages = [10,40,50,48,70] name_series = pd.Series(names) age_series = pd.Series(ages) data_dict = {'name':name_series, 'age':age_series} dframe = pd.DataFrame(data_dict) #create a pandas DataFrame from dictionary dframe['age_plus_five'] = dframe['age'] + 5 #create a new column dframe.pop('age_plus_five') #dframe.pop('age') salary = [1000,6000,4000,8000,10000] salary_series = pd.Series(salary) new_data_dict = {'name':name_series, 'age':age_series,'salary':salary_series} new_dframe = pd.DataFrame(new_data_dict) new_dframe['average_salary'] = new_dframe['age']*90 new_dframe.index = new_dframe['name'] print(new_dframe.loc['sam'])Нажмите кнопку воспроизведения абзаца, чтобы запустить фрагмент кода. Состояние, которое отображается в правом верхнем углу абзаца, должно изменяться в следующей последовательности: READY (ГОТОВО), PENDING (ОЖИДАЕТ), RUNNING (ВЫПОЛНЯЕТСЯ) и FINISHED (ЗАВЕРШЕНО). Выходные данные отображаются в нижней части того же абзаца. Снимок экрана выглядит следующим образом.
Выходные данные:





Использование заданий отправки Spark
Создайте файл с помощью следующей команды "#vim samplefile.py"
Эта команда открывает файл vim
Вставьте следующий код в файл vim
import pandas as pd import matplotlib.pyplot as plt From pyspark.sql import SparkSession Spark = SparkSession.builder.master('yarn').appName('SparkSampleCode').getOrCreate() # Initialize spark context data1 = [22,40,10,50,70] s1 = pd.Series(data1) #One-dimensional ndarray with axis labels (including time series). data2 = data1 index = ['John','sam','anna','smith','ben'] s2 = pd.Series(data2,index=index) data3 = {'John':22, 'sam':40, 'anna':10,'smith':50,'ben':70} s3 = pd.Series(data3) s3['jp'] = 32 #insert a new row s3['John'] = 88 names = ['John','sam','anna','smith','ben'] ages = [10,40,50,48,70] name_series = pd.Series(names) age_series = pd.Series(ages) data_dict = {'name':name_series, 'age':age_series} dframe = pd.DataFrame(data_dict) #create a pandas DataFrame from dictionary dframe['age_plus_five'] = dframe['age'] + 5 #create a new column dframe.pop('age_plus_five') #dframe.pop('age') salary = [1000,6000,4000,8000,10000] salary_series = pd.Series(salary) new_data_dict = {'name':name_series, 'age':age_series,'salary':salary_series} new_dframe = pd.DataFrame(new_data_dict) new_dframe['average_salary'] = new_dframe['age']*90 new_dframe.index = new_dframe['name'] print(new_dframe.loc['sam'])Сохраните файл с помощью следующего метода.
- Нажмите кнопку Escape
- Введите команду
:wq
Выполните следующую команду, чтобы запустить задание.
/spark-submit --master yarn --deploy-mode cluster <filepath>/samplefile.py

Мониторинг запросов к кластеру Apache Spark в HDInsight в AKS
Пользовательский интерфейс журнала Spark
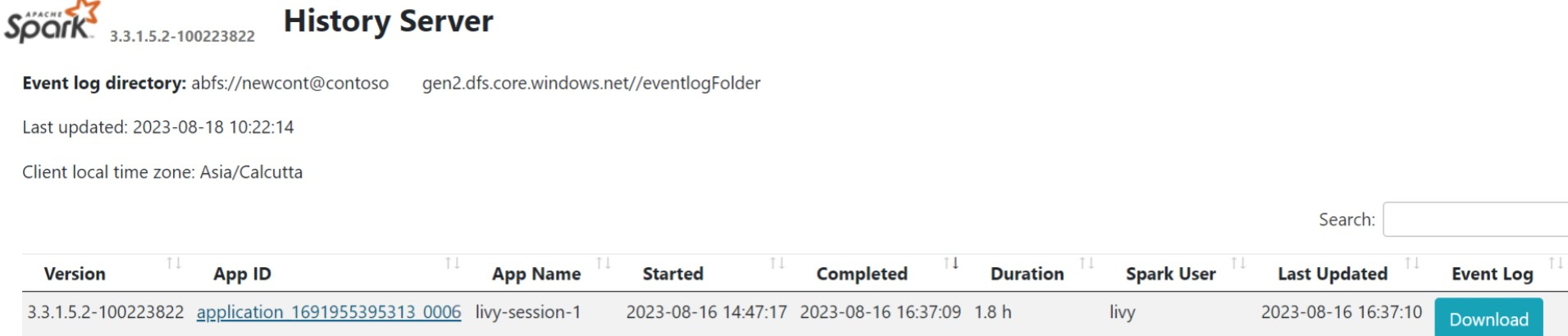
Щелкните пользовательский интерфейс сервера журнала Spark на вкладке обзора.

Выберите последний запуск из пользовательского интерфейса с помощью того же идентификатора приложения.
Просмотрите циклы ациклических графов и этапы задания в пользовательском интерфейсе сервера журнала Spark.
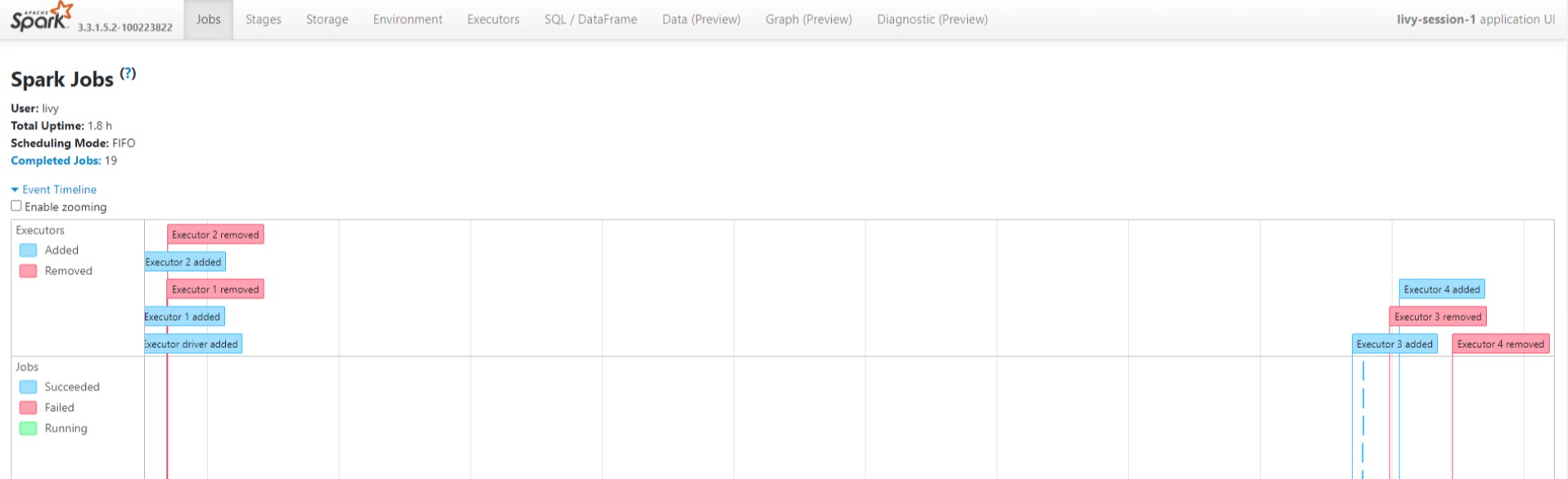



Livy session UI
Чтобы открыть пользовательский интерфейс сеанса Livy, введите следующую команду в браузере.
https://<CLUSTERNAME>.<CLUSTERPOOLNAME>.<REGION>.projecthilo.net/p/livy/ui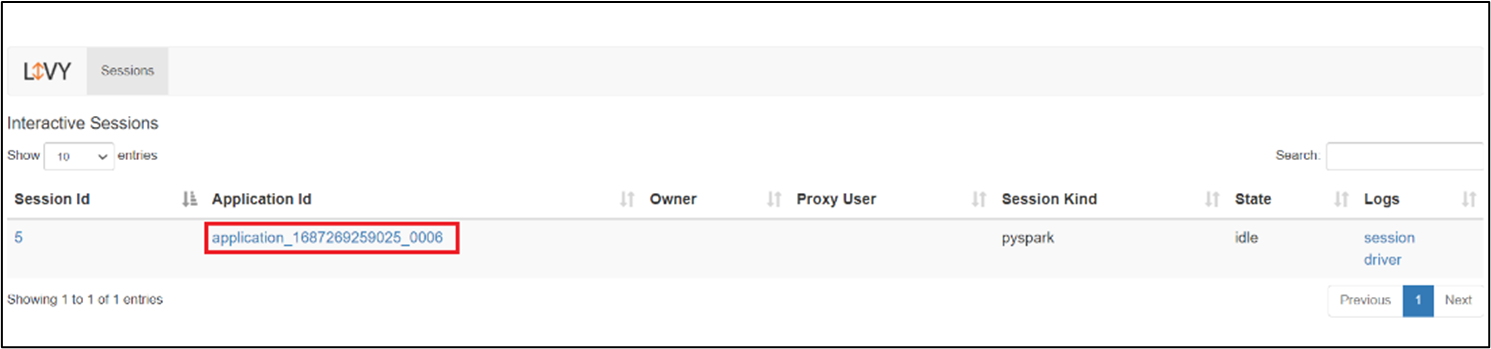
Просмотрите журналы драйверов, щелкнув параметр драйвера в журналах.

Пользовательский интерфейс Yarn
На вкладке "Обзор" щелкните Yarn и откройте пользовательский интерфейс Yarn.
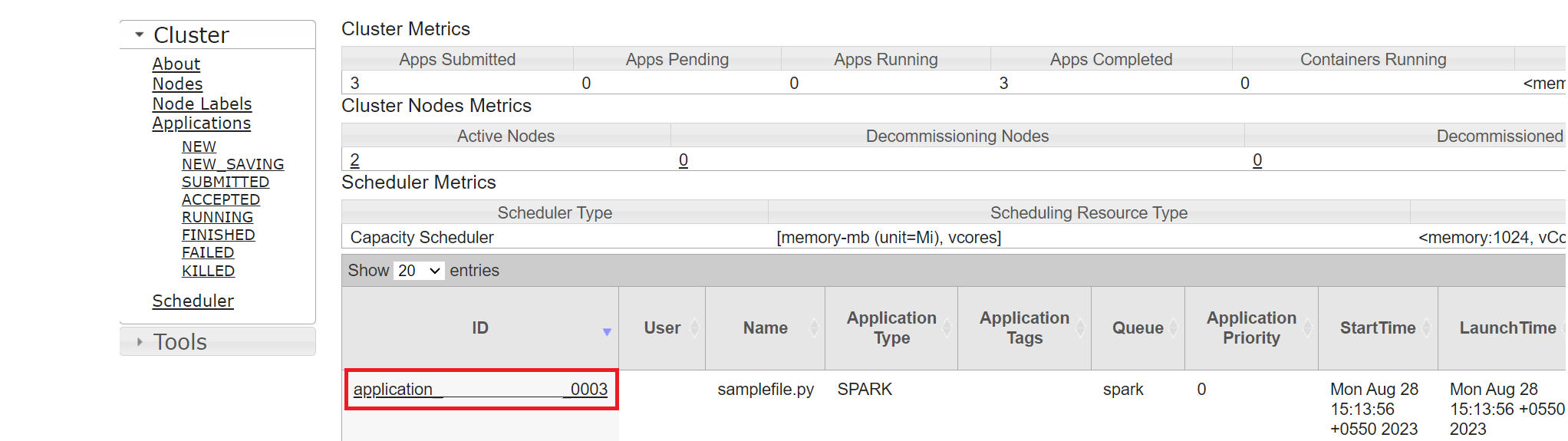
Вы можете отслеживать задание, которое вы недавно выполнили с помощью того же идентификатора приложения.
Щелкните идентификатор приложения в Yarn, чтобы просмотреть подробные журналы задания.


Справочные материалы
- Apache, Apache Spark, Spark и связанные открытый код имена проектов являются товарными знаками Apache Software Foundation (ASF).