Запись сообщений о событиях в Azure Data Lake Storage 2-го поколения с помощью API Apache Flink® DataStream
Примечание.
Мы отставим Azure HDInsight в AKS 31 января 2025 г. До 31 января 2025 г. необходимо перенести рабочие нагрузки в Microsoft Fabric или эквивалентный продукт Azure, чтобы избежать резкого прекращения рабочих нагрузок. Оставшиеся кластеры в подписке будут остановлены и удалены из узла.
До даты выхода на пенсию будет доступна только базовая поддержка.
Внимание
Эта функция в настоящее время доступна для предварительного ознакомления. Дополнительные условия использования для предварительных версий Microsoft Azure включают более юридические термины, применимые к функциям Azure, которые находятся в бета-версии, в предварительной версии или в противном случае еще не выпущены в общую доступность. Сведения об этой конкретной предварительной версии см. в статье Azure HDInsight в предварительной версии AKS. Для вопросов или предложений функций отправьте запрос на AskHDInsight с подробными сведениями и следуйте за нами для получения дополнительных обновлений в сообществе Azure HDInsight.
Apache Flink использует файловые системы для использования и постоянного хранения данных как для результатов приложений, так и для отказоустойчивости и восстановления. Из этой статьи вы узнаете, как записывать сообщения о событиях в Azure Data Lake Storage 2-го поколения с помощью API DataStream.
Необходимые компоненты
- Кластер Apache Flink в HDInsight в AKS
- Кластер Apache Kafka в HDInsight
- Необходимо убедиться, что параметры сети должны быть выполнены, как описано в разделе "Использование Apache Kafka в HDInsight". Убедитесь, что HDInsight в кластерах AKS и HDInsight находятся в одном виртуальная сеть.
- Использование MSI для доступа к ADLS 2-го поколения
- IntelliJ для разработки на виртуальной машине Azure в HDInsight на виртуальная сеть AKS
Соединитель Файловой системы Apache Flink
Этот соединитель файловой системы предоставляет одинаковые гарантии для пакетной службы и потоковой передачи и предназначен для обеспечения точной семантики для выполнения потоковой передачи. Дополнительные сведения см. в разделе Flink DataStream Filesystem.
Соединитель Apache Kafka
Flink предоставляет соединитель Apache Kafka для чтения данных из и записи данных в разделы Kafka с точной гарантией. Дополнительные сведения см. в разделе Apache Kafka Connector.
Создание проекта для Apache Flink
pom.xml в IntelliJ IDEA
<properties>
<maven.compiler.source>1.8</maven.compiler.source>
<maven.compiler.target>1.8</maven.compiler.target>
<flink.version>1.17.0</flink.version>
<java.version>1.8</java.version>
<scala.binary.version>2.12</scala.binary.version>
<kafka.version>3.2.0</kafka.version>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>${flink.version}</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.flink/flink-streaming-java -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java</artifactId>
<version>${flink.version}</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.flink/flink-clients -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients</artifactId>
<version>${flink.version}</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.flink/flink-connector-files -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-files</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka</artifactId>
<version>${flink.version}</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-assembly-plugin</artifactId>
<version>3.0.0</version>
<configuration>
<appendAssemblyId>false</appendAssemblyId>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
</project>
Программа для приемника ADLS 2-го поколения
abfsGen2.java
Примечание.
Замена Apache Kafka в кластере HDInsight bootStrapServers собственными брокерами для Kafka 3.2
package contoso.example;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.api.common.serialization.SimpleStringEncoder;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.configuration.MemorySize;
import org.apache.flink.connector.file.sink.FileSink;
import org.apache.flink.connector.kafka.source.KafkaSource;
import org.apache.flink.connector.kafka.source.enumerator.initializer.OffsetsInitializer;
import org.apache.flink.core.fs.Path;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.sink.filesystem.rollingpolicies.DefaultRollingPolicy;
import java.time.Duration;
public class KafkaSinkToGen2 {
public static void main(String[] args) throws Exception {
// 1. get stream execution env
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
Configuration flinkConfig = new Configuration();
flinkConfig.setString("classloader.resolve-order", "parent-first");
env.getConfig().setGlobalJobParameters(flinkConfig);
// 2. read kafka message as stream input, update your broker ip's
String brokers = "<update-broker-ip>:9092,<update-broker-ip>:9092,<update-broker-ip>:9092";
KafkaSource<String> source = KafkaSource.<String>builder()
.setBootstrapServers(brokers)
.setTopics("click_events")
.setGroupId("my-group")
.setStartingOffsets(OffsetsInitializer.earliest())
.setValueOnlyDeserializer(new SimpleStringSchema())
.build();
DataStream<String> stream = env.fromSource(source, WatermarkStrategy.noWatermarks(), "Kafka Source");
stream.print();
// 3. sink to gen2, update container name and storage path
String outputPath = "abfs://<container-name>@<storage-path>.dfs.core.windows.net/flink/data/click_events";
final FileSink<String> sink = FileSink
.forRowFormat(new Path(outputPath), new SimpleStringEncoder<String>("UTF-8"))
.withRollingPolicy(
DefaultRollingPolicy.builder()
.withRolloverInterval(Duration.ofMinutes(2))
.withInactivityInterval(Duration.ofMinutes(3))
.withMaxPartSize(MemorySize.ofMebiBytes(5))
.build())
.build();
stream.sinkTo(sink);
// 4. run stream
env.execute("Kafka Sink To Gen2");
}
}
Jar-файл пакета и отправка в Apache Flink.
Отправьте jar-файл в ABFS.
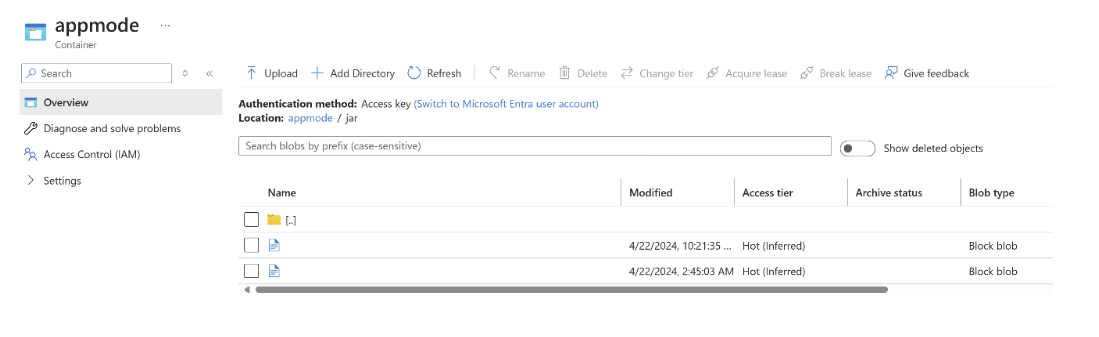
Передайте jar-сведения о задании в
AppModeсоздании кластера.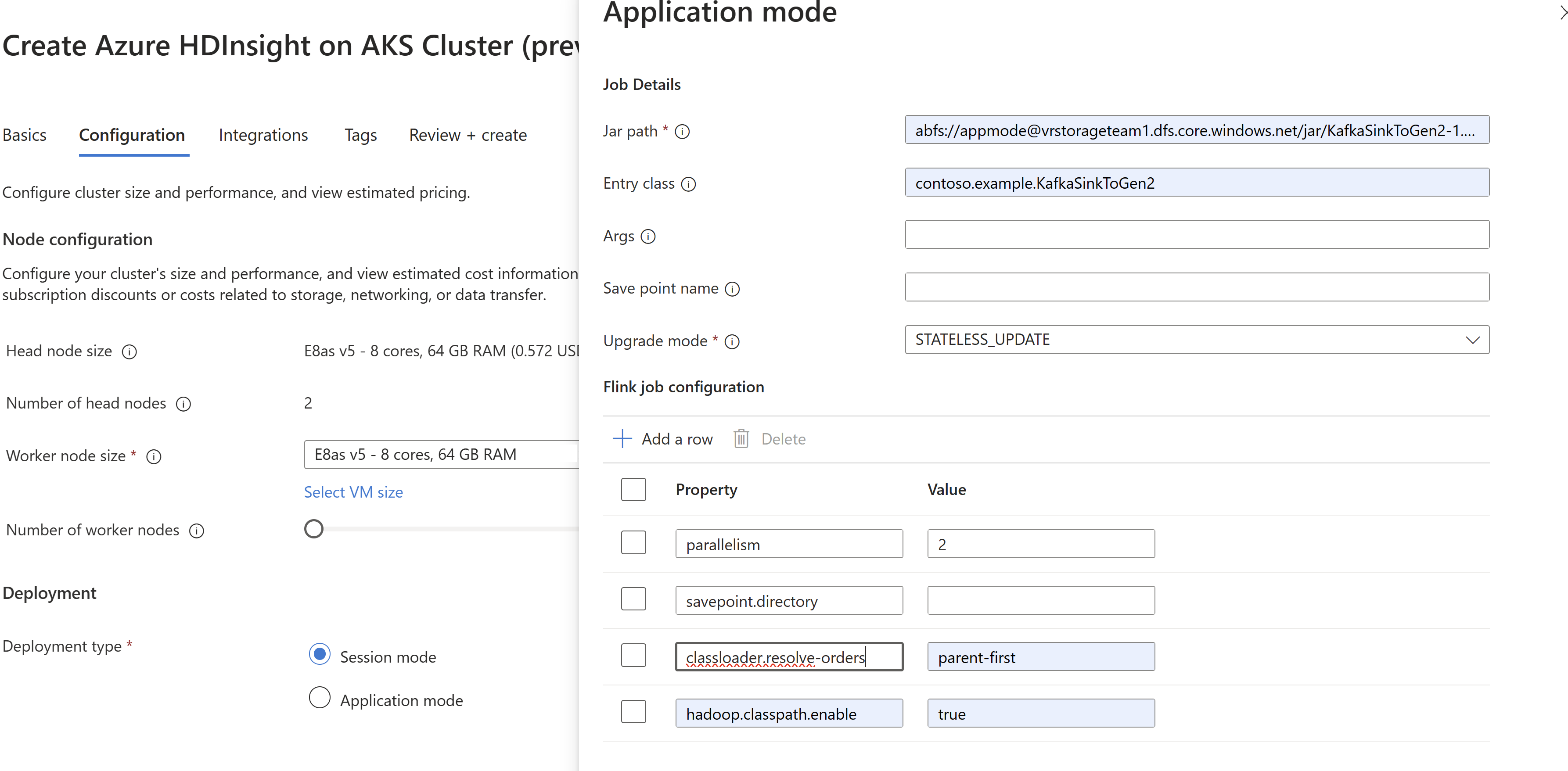
Примечание.
Обязательно добавьте classloader.resolve-order как parent-first и hadoop.classpath.enable как
trueВыберите агрегирование журнала заданий для отправки журналов заданий в учетную запись хранения.
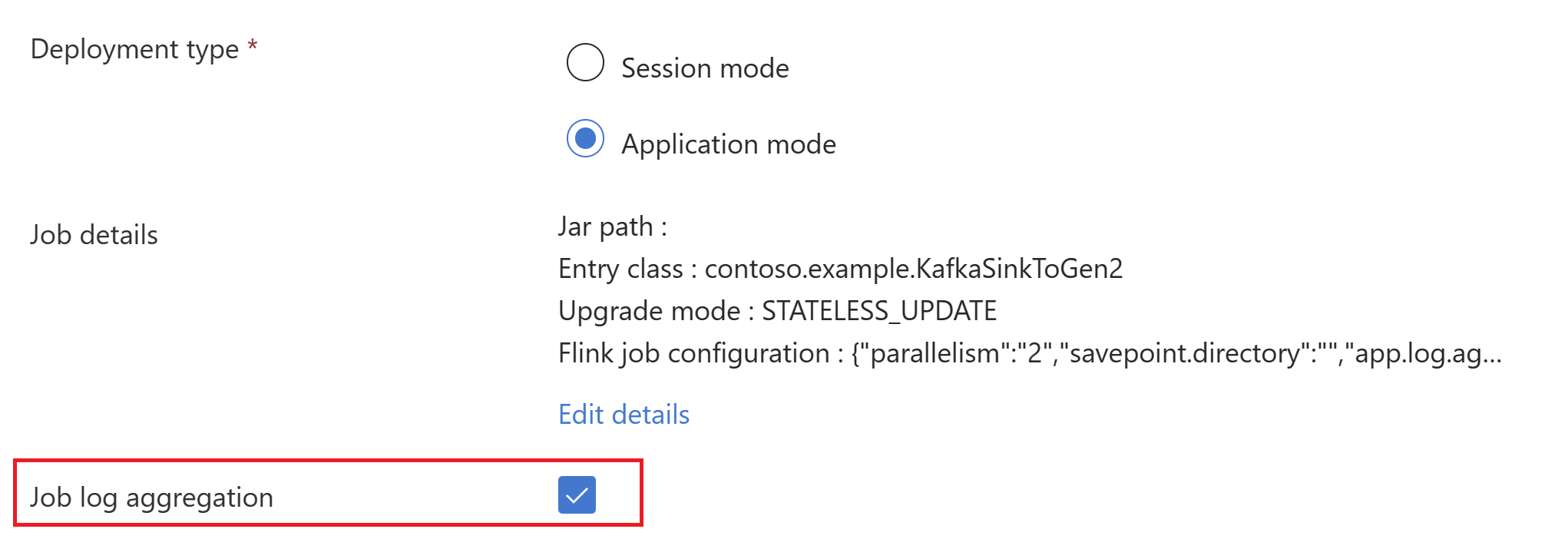
Вы можете увидеть выполнение задания.
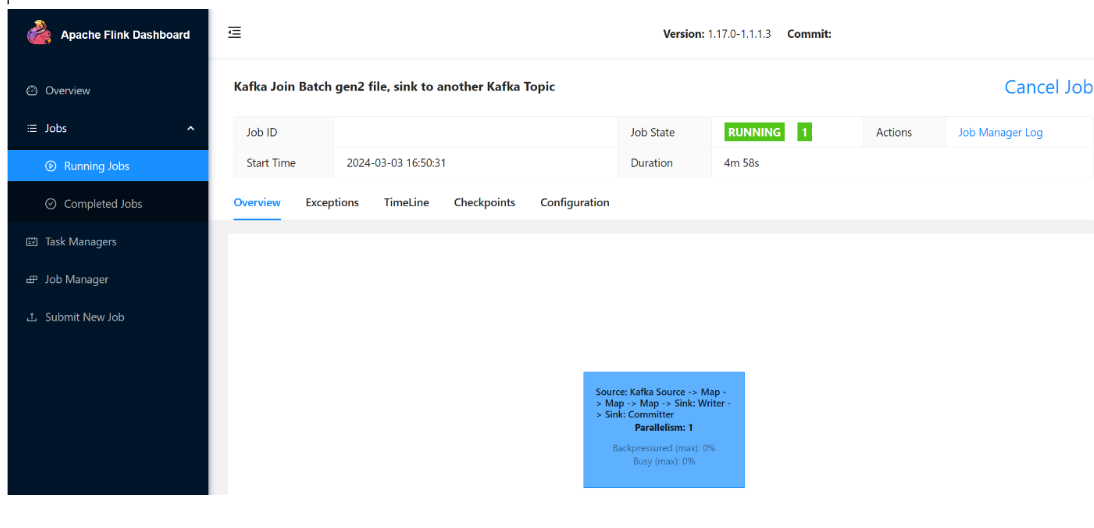




Проверка потоковых данных в ADLS 2-го поколения
Мы видим потоковую передачу в ADLS 2-го click_events поколения.

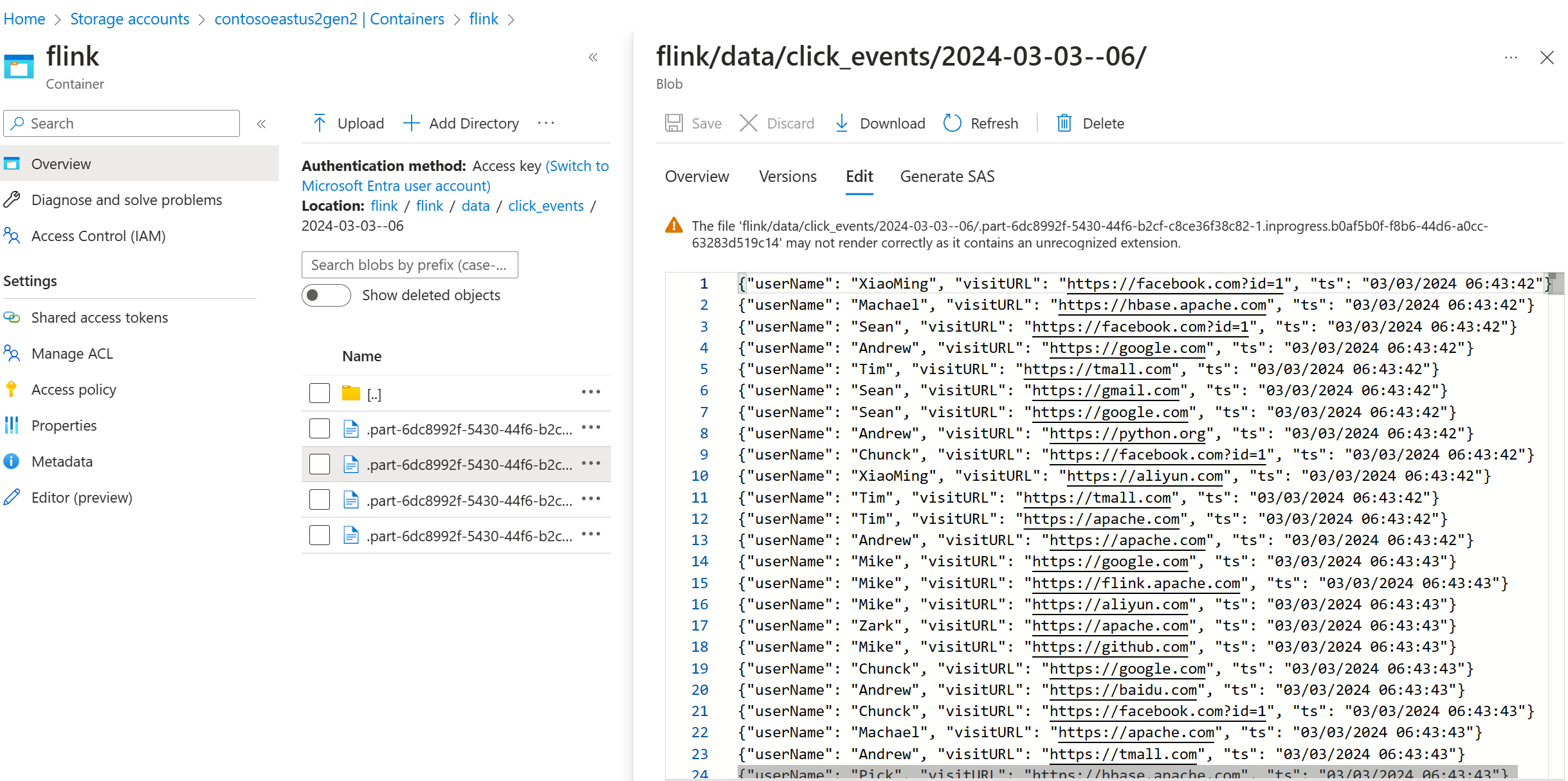
Вы можете указать скользящую политику, которая выполняет развертывание файла части в любом из следующих трех условий:
.withRollingPolicy(
DefaultRollingPolicy.builder()
.withRolloverInterval(Duration.ofMinutes(5))
.withInactivityInterval(Duration.ofMinutes(3))
.withMaxPartSize(MemorySize.ofMebiBytes(5))
.build())
Справочные материалы
- Соединитель Apache Kafka
- Файловая система Flink DataStream
- Веб-сайт Apache Flink
- Apache, Apache Kafka, Kafka, Apache Flink, Flink и связанные открытый код имена проектов являются товарными знаками Apache Software Foundation (ASF).