Устранение неполадок Центры событий Azure обработчика событий
В этой статье приводятся решения распространенных проблем, которые могут возникнуть при использовании EventProcessorClient типа. Если вы ищете решения других распространенных проблем, которые могут возникнуть при использовании Центры событий Azure, см. статью "Устранение неполадок Центры событий Azure".
Сбои предварительных условий 412 при использовании обработчика событий
412 предварительных ошибок возникают, когда клиент пытается взять или продлить владение секцией, но локальная версия записи владения устарела. Эта проблема возникает, когда другой экземпляр процессора украдет владение секциями. Для получения дополнительных сведений см. следующий раздел.
Часто изменяются права владения секциями
При изменении количества EventProcessorClient экземпляров (то есть добавляются или удаляются), выполняемые экземпляры пытаются сбалансировать секции нагрузки между собой. В течение нескольких минут после изменения количества процессоров, как ожидается, будут изменены владельцы секций. После балансирования права владения секциями должна быть стабильной и редко меняться. Если владение секциями часто меняется, когда число процессоров констант, скорее всего, указывает на проблему. Рекомендуется подать ошибку GitHub с журналами и повтором.
Владение секцией определяется с помощью записей владения в элементе CheckpointStore. В каждом интервале EventProcessorClient балансировки нагрузки выполняются следующие задачи:
- Получение последних записей владения.
- Проверьте записи, чтобы узнать, какие записи не обновили метку времени в течение интервала действия владения секцией. Рассматриваются только записи, соответствующие этим критериям.
- Если существуют несовершенные секции, а нагрузка не балансируется между экземплярами
EventProcessorClient, клиент обработчика событий попытается запросить секцию. - Обновите запись владения для секций, принадлежащих ей, у которых есть активная ссылка на этот раздел.
Вы можете настроить интервалы истечения срока действия балансировки нагрузки и владения при создании EventProcessorClient с помощью EventProcessorClientBuilderследующего списка:
- Метод loadBalancingUpdateInterval(Duration) указывает, как часто выполняется цикл балансировки нагрузки.
- Метод partitionOwnershipExpirationInterval(Duration) указывает минимальное количество времени после обновления записи владения, прежде чем процессор считает секцию неуправляемой.
Например, если запись владения была обновлена в 9:30 утра и partitionOwnershipExpirationInterval составляет 2 минуты. Когда происходит цикл балансировки нагрузки, и он замечает, что запись владения не была обновлена за последние 2 минуты или к 9:32 утра, она будет рассматривать секцию неуправляемой.
Если ошибка возникает в одном из потребителей секции, она закроет соответствующего потребителя, но не попытается восстановить ее до следующего цикла балансировки нагрузки.
"... текущий приемник "RECEIVER_NAME>" с эпохой "<0" становится отключенным"
Все сообщение об ошибке выглядит примерно так:
New receiver 'nil' with higher epoch of '0' is created hence current receiver 'nil' with epoch '0'
is getting disconnected. If you are recreating the receiver, make sure a higher epoch is used.
TrackingId:<GUID>, SystemTracker:<NAMESPACE>:eventhub:<EVENT_HUB_NAME>|<CONSUMER_GROUP>,
Timestamp:2022-01-01T12:00:00}"}
Эта ошибка ожидается при балансировке нагрузки после EventProcessorClient добавления или удаления экземпляров. Балансировка нагрузки — это текущий процесс. При использовании BlobCheckpointStore с потребителем каждые 30 секунд (по умолчанию) потребитель проверка, чтобы увидеть, какие потребители имеют утверждение для каждой секции, затем выполняет некоторую логику, чтобы определить, нужно ли украсть секцию от другого потребителя. Механизм обслуживания, используемый для утверждения монопольного владения над секцией, называется эпохой.
Однако если экземпляры не добавляются или удаляются, возникает основная проблема, которая должна быть устранена. Дополнительные сведения см. в разделе о частом изменении владельца секции и проблемах с отправкой GitHub.
Высокая загрузка ЦП
Высокая загрузка ЦП обычно происходит из-за того, что экземпляр владеет слишком большим количеством секций. Рекомендуется не более трех разделов для каждого ядра ЦП. Лучше начать с 1,5 секций для каждого ядра ЦП, а затем протестировать, увеличив число секций, принадлежащих.
Из памяти и выбор размера кучи
Проблема с нехваткой памяти (OOM) может произойти, если текущая максимальная куча для JVM недостаточно для запуска приложения. Может потребоваться измерить требование кучи приложения. Затем на основе результата размер кучи, задав соответствующую максимальную память кучи с помощью -Xmx параметра JVM.
Не следует указывать -Xmx значение, превышающее доступное или ограничение памяти для узла (виртуальной машины или контейнера), например память, запрошенная в конфигурации контейнера. Для поддержки кучи Java необходимо выделить достаточно памяти для узла.
Ниже описан типичный способ измерения значения максимального числа кучи Java:
Запустите приложение в среде, близкой к рабочей среде, где приложение отправляет, получает и обрабатывает события под пиковой нагрузкой в рабочей среде.
Подождите, пока приложение достигнет устойчивого состояния. На этом этапе приложение и JVM загружали все доменные объекты, типы классов, статические экземпляры, пулы объектов (TCP, пулы подключений базы данных) и т. д.
Под устойчивым состоянием отображается стабильный шаблон пилото-фигуры для коллекции кучи, как показано на следующем снимке экрана:
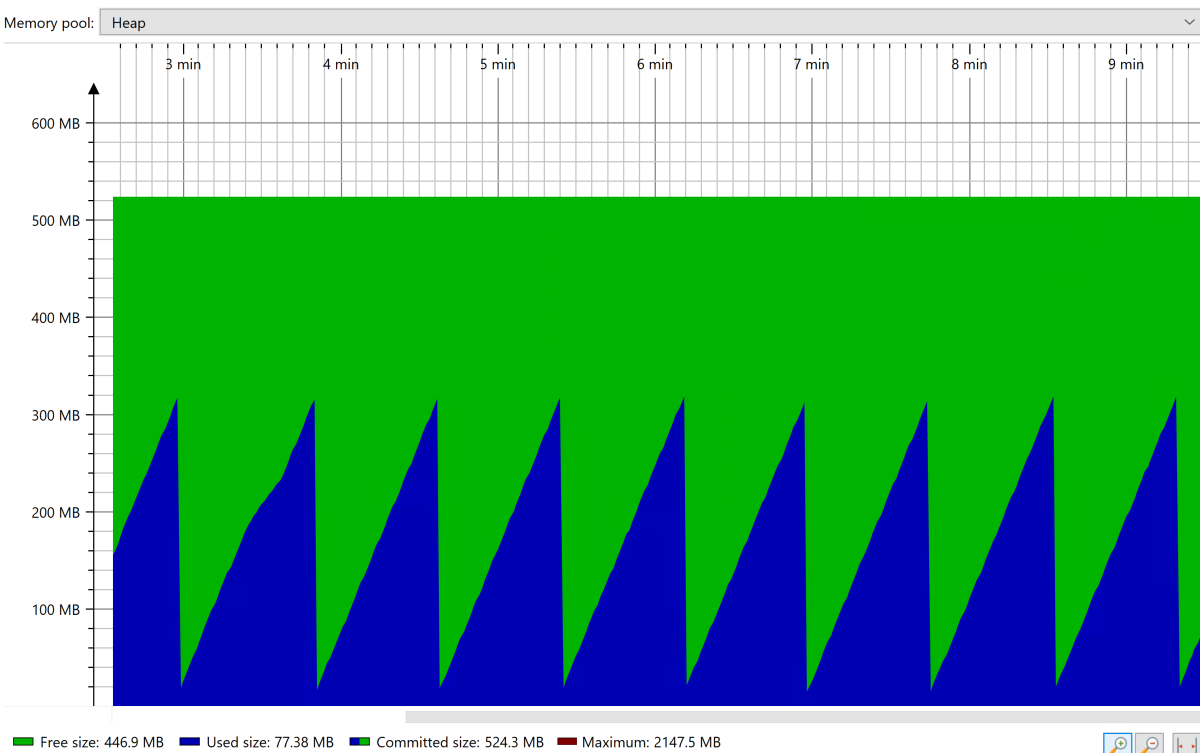
Когда приложение достигнет устойчивого состояния, принудительно выполните полную сборку мусора (GC) с помощью таких средств, как JConsole. Просмотрите память, занятую после полной сборки мусора. Вы хотите размер кучи, чтобы только 30% занимали после полной сборки мусора. Это значение можно использовать для задания максимального размера кучи (с помощью
-Xmx).

Если вы находитесь в контейнере, то размер контейнера должен иметь дополнительную память около 1 ГБ памяти для не кучи, необходимой для экземпляра JVM.
Клиент обработчика перестает получать
Клиент обработчика часто постоянно работает в хост-приложении в течение нескольких дней. Иногда он замечает, что EventProcessorClient не обрабатывает одну или несколько секций. Как правило, недостаточно информации, чтобы определить, почему произошло исключение. Остановка EventProcessorClient является симптомом основной причины (т. е. состояния гонки), которая произошла при попытке восстановиться после временной ошибки. Сведения, необходимые для отправки, см. в разделе "Проблемы с отправкой GitHub".
Повторяющееся событие, полученное при перезапуске процессора
EventProcessorClient Служба Центров событий гарантирует по крайней мере один раз доставку. Можно добавить метаданные для распознавания повторяющихся событий. Дополнительные сведения см. в разделе Центры событий Azure гарантировать по крайней мере один раз доставки в Stack Overflow. Если требуется только один раз доставки, следует рассмотреть служебная шина, которая ожидает подтверждения от клиента. Сравнение служб обмена сообщениями см. в статье "Выбор между службами обмена сообщениями Azure".
Миграция из прежних версий в новую клиентную библиотеку
Руководство по миграции включает шаги по миграции с устаревшего клиента и миграции устаревших проверка точек.
Следующие шаги
Если рекомендации по устранению неполадок, описанные в этой статье, не помогают устранить проблемы при использовании клиентских библиотек пакета SDK Azure для Java, рекомендуется отправить проблему в репозитории Azure SDK для Java GitHub.