Решения для создания искусственного интеллекта для разработчиков
Создание искусственного интеллекта с поддержкой больших языковых моделей (LLM) открывает захватывающие новые возможности для разработчиков программного обеспечения и организаций. Такие службы, как Служба Azure OpenAI, делают разработку ИИ доступными с помощью API-интерфейсов, которые легко использовать. Разработчики на всех уровнях навыков могут интегрировать расширенные функциональные возможности ИИ в свои приложения без специализированных знаний или инвестиций в оборудование.
Как разработчику приложений, вам может быть интересно понять, какую роль вы можете играть и как вы вписываетесь. Например, вы, возможно, задаётесь вопросом, на каком уровне "стека ИИ" стоит сосредоточить своё обучение. Или вы можете задуматься о том, что вы можете построить с учетом существующих технологий.
Чтобы ответить на эти вопросы, важно сначала разработать умственную модель, которая сопоставляет, как новая терминология и технологии вписываются в то, что вы уже понимаете. Разработка психической модели помогает разрабатывать и создавать созданные функции искусственного интеллекта в приложениях.
В серии статей мы покажем, как применяется текущий опыт разработки программного обеспечения к генерируемом ИИ. В статьях также приведена основа ключевых слов и концепций для разработки первых решений искусственного интеллекта.
Как бизнесы извлекают выгоду от использования генеративного искусственного интеллекта
Чтобы понять, как ваш текущий опыт разработки программного обеспечения применяется к генерируемом ИИ, важно понять, как предприятия намерены использовать генерированный ИИ.
Предприятия рассматривают генерированный ИИ в качестве средства для улучшения взаимодействия с клиентами, повышения эффективности работы и повышения эффективности решения проблем и творчества. Интеграция генерируемого искусственного интеллекта в существующие системы открывает возможности для предприятий для улучшения их экосистем программного обеспечения. Он может дополнить традиционные функциональные возможности программного обеспечения расширенными возможностями искусственного интеллекта, например персонализированных рекомендаций для пользователей или интеллектуального агента, которые могут отвечать на конкретные вопросы о организации или ее продуктах или службах.
Ниже приведены некоторые распространенные сценарии, в которых генерированный ИИ может помочь компаниям:
создание содержимого:
- Создание текста, кода, изображений и звука. Этот сценарий может быть полезен для маркетинга, продаж, ИТ-отдела, внутренних коммуникаций и т. д.
Обработка естественного языка
- Создание или улучшение бизнес-коммуникаций с помощью предложений или полного создания сообщений.
- Используйте "чат с данными". Таким образом, пользователь может задавать вопросы в чате с помощью данных, хранящихся в базах данных или документах организации в качестве основы для ответов.
- Резюмирование, организация и упрощение больших объемов информации, чтобы сделать информацию более доступной.
- Используйте семантический поиск. Таким образом, пользователи могут искать документы и данные без точного совпадения ключевых слов.
- Для перевода контента с целью увеличения охвата и доступности.
Анализ данных:
- Анализ рынков и определение тенденций в данных.
- Моделировать сценарии "если", чтобы помочь компаниям планировать возможные изменения или проблемы в каждой области бизнеса.
- Анализ кода для предложения улучшений, исправления ошибок и создания документации.
Разработчик программного обеспечения имеет возможность значительно повысить их влияние, интегрируя созданные приложения ИИ и функциональные возможности в программное обеспечение, на которое они полагаются.
Как создавать генеративные приложения на базе ИИ
Хотя LLM выполняет основную работу, вы создаете системы, которые интегрируют, организуют и отслеживают результаты. Есть много, чтобы узнать, но вы можете применить навыки, которые у вас уже есть, в том числе как:
- Выполняйте вызовы API с помощью REST, JSON или пакетов средств разработки программного обеспечения для конкретного языка (SDK)
- Оркестрация вызовов API и выполнение бизнес-логики
- Хранение и извлечение из хранилищ данных
- Интеграция входных данных и результатов в взаимодействие с пользователем
- Создавайте API, которые можно вызывать из LLM.
Разработка решений для создания искусственного интеллекта на основе существующих навыков.
Средства и службы разработчика
Корпорация Майкрософт инвестирует в разработку средств, служб, API, примеров и ресурсов обучения, которые помогут вам приступить к разработке искусственного интеллекта. Каждый выделяет серьезную проблему или ответственность, необходимую для создания решения в области генеративного ИИ. Чтобы эффективно использовать определенную службу, API или ресурс, необходимо убедиться, что вы:
- Общие сведения о типичных функциях, ролях и обязанностях в заданном типе функции создания искусственного интеллекта. Например, как мы подробно обсудим в концептуальных статьях, описывающих системы чата на основе RAG, существует множество архитектурных обязанностей в системе. Важно понимать предметную область и ограничения в мельчайших подробностях, прежде чем разрабатывать систему, которая решает проблему.
- Ознакомьтесь с API, службами и инструментами, которые существуют для данной функции, роли или ответственности. Теперь, когда вы понимаете область проблем и ограничения, вы можете самостоятельно создать этот аспект системы с помощью пользовательского кода или существующих средств с низким кодом или без кода, или вызвать API для существующих служб.
- Ознакомьтесь с опциями, включая решения, ориентированные на код, а также решения без кода и минимального кода. Вы можете построить все самостоятельно, но это эффективное использование вашего времени и навыков? В зависимости от ваших требований обычно можно объединить сочетание технологий и подходов (код, без кода, низкий код, инструменты).
Нет единого правильного способа создания функций искусственного интеллекта в приложениях. Вы можете выбрать множество инструментов и подходов. Важно оценить компромиссы каждого из них.
Начало работы с уровнем приложения
Вам не нужно понимать все, как работает генерированный ИИ, чтобы приступить к работе и быть продуктивным. Как уже говорилось ранее, скорее всего, вы уже знаете достаточно. Вы можете использовать API и применить существующие навыки для начала работы.
Например, вам не нужно обучать собственный LLM с нуля. Обучение LLM требует времени и ресурсов, которые большинство компаний не хотят инвестировать. Вместо этого используйте существующие предварительно обученные базовые модели, такие как GPT-4, выполняя вызовы к API в существующих облачных службах, таких как Azure OpenAI API. Добавление созданных функций ИИ в существующее приложение не отличается от добавления других функций на основе вызова API.
Исследование того, как LLM обучены или как они работают, могут удовлетворить ваше интеллектуальное любопытство, но полное понимание того, как работает LLM, требует глубокого понимания обработки и анализа данных и математического фона, который поддерживает его. Это понимание может включать курсы на уровне послевузовского образования по статистике, вероятностям и теории информации.
Если у вас есть компьютерная наука, вы можете оценить, что большинство разработки приложений происходит на более высоком уровне в "стеке" исследований и технологий. У вас может быть некоторое представление о каждом уровне, но вы, скорее всего, специализируетесь на уровне разработки приложений, с акцентом на определенном языке программирования и платформе, таких как доступные API, инструменты и шаблоны.
То же самое верно для поля ИИ. Вы можете понять и оценить теорию, лежащую в основе разработки на базе крупных языковых моделей (LLM), но вы, вероятно, сосредоточите внимание на уровне прикладных программ или поможете в реализации шаблонов и процессов, чтобы поддержать инициативу по внедрению генеративного ИИ в вашей компании.
Ниже приведено упрощенное представление слоев знаний, необходимых для реализации функций генеративного ИИ в новом или существующем приложении.
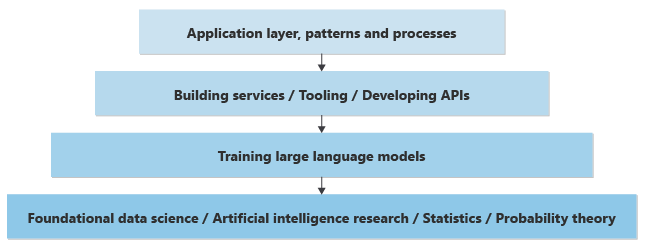
На самом низком уровне специалисты по обработке и анализу данных выполняют исследования по обработке и анализу данных для решения или улучшения ИИ на основе глубокого математического понимания статистики, теории вероятности и т. д.
Один слой вверх, на основе самого низкого базового слоя, специалисты по обработке и анализу данных реализуют теоретические концепции в LLMs, создавая нейронные сети и обучая весы и смещения, чтобы обеспечить практический фрагмент программного обеспечения, который может принимать входные данные (запрашивает) и генерирует результаты (завершения). Вычислительный процесс создания завершений на основе подсказок называется инференцией. Специалисты по обработке и анализу данных определяют , как нейроны нейронной сети предсказывают создание следующего слова или пикселя.
Учитывая объем вычислительной мощности, необходимой для обучения моделей и создания результатов на основе входных данных, модели часто обучены и размещаются в крупных центрах обработки данных. Можно обучать или размещать модель на локальном компьютере, но результаты часто медленные. Скорость и эффективность поставляются с выделенными видеоадаптерами GPU, которые помогают обрабатывать вычислительные ресурсы, необходимые для создания результатов.
При размещении в крупных центрах обработки данных программный доступ к этим моделям предоставляется через REST API. API иногда "упаковываются" пакетами SDK и доступны разработчикам приложений для простоты использования. Другие средства могут помочь улучшить интерфейс разработчика, обеспечивая наблюдаемость или другие служебные программы.
Разработчики приложений могут вызывать эти API для реализации бизнес-функций.
Помимо программного запроса моделей, появляются шаблоны и процессы, которые помогают организациям создавать надежные бизнес-функции на основе генеративного искусственного интеллекта. Например, возникают закономерности, которые помогают предприятиям гарантировать, что созданный текст, код, изображения и звук соответствуют этическим стандартам и безопасности и обязательствам по конфиденциальности данных клиентов.
В этом стеке проблем или уровней, если вы являетесь разработчиком приложений, ответственным за создание бизнес-функций, вы можете перейти за рамки уровня приложений в разработку и обучение собственного LLM. Но на этом уровне понимания требуется новый набор навыков, которые часто разрабатываются только с помощью расширенного образования.
Если вы не можете посвятить себя академическому развитию компетенции в области науки о данных, чтобы внести свой вклад в разработку следующего нижнего слоя стека, вы можете сосредоточиться на развитии знаний по темам уровня приложений.
- API и SDK: что доступно и что создают различные конечные точки.
- Связанные средства и службы помогут вам создать все функции, необходимые для готового к производству решения искусственного интеллекта.
- Разработка подсказок: как добиться наилучших результатов, задавая или перефразируя вопросы.
- Где возникают узкие места и как масштабировать решение. Эта область включает в себя понимание того, что связано с ведением журнала или получением данных телеметрии без нарушения конфиденциальности клиентов.
- Характеристики различных LLM: их сильные стороны, варианты использования, тесты и то, что они измеряют, и ключевые различия между поставщиками и моделями, созданными каждым поставщиком. Эта информация помогает выбрать подходящую модель для потребностей вашей организации.
- Последние шаблоны, рабочие процессы и процессы, которые можно использовать для создания эффективных и устойчивых функций создания ИИ в приложениях.
Средства и службы от Майкрософт
Вы можете использовать инструменты и услуги генеративного ИИ от Microsoft с низким кодом и без кода, чтобы помочь вам создать часть или все ваше решение. Различные службы Azure могут играть основные роли. Каждый из них способствует эффективности, масштабируемости и надежности решения.
API и пакеты SDK для подхода, ориентированного на код
В основе каждого создаваемого решения искусственного интеллекта лежит модель LLM. Azure OpenAI предоставляет доступ ко всем функциям, доступным в моделях, таких как GPT-4.
| Продукт | Description |
|---|---|
| Azure OpenAI | Размещенная служба, которая предоставляет доступ к мощным языковым моделям, таким как GPT-4. Вы можете использовать несколько API для выполнения всех типичных функций LLM, включая создание внедрения и создание интерфейса чата. У вас есть полный доступ к параметрам и настройкам, чтобы получить нужные результаты. |
Среды выполнения
Так как вы создаете бизнес-логику, логику презентации или API для интеграции генерируемого ИИ в приложения вашей организации, вам потребуется служба для размещения и выполнения этой логики.
| Продукт | Description |
|---|---|
| служба приложение Azure (или одна из нескольких облачных служб на основе контейнеров) | Эта платформа может размещать веб-интерфейсы или API-интерфейсы, с помощью которых пользователи взаимодействуют с системой чата RAG. Она поддерживает быструю разработку, развертывание и масштабирование веб-приложений, поэтому проще управлять интерфейсными компонентами системы. |
| Функции Azure | Используйте бессерверные вычисления для обработки задач на основе событий в системе чата RAG. Например, используйте его для активации процессов извлечения данных, обработки запросов пользователей или обработки фоновых задач, таких как синхронизация данных и очистка. Это обеспечивает более модульный и масштабируемый подход к созданию серверной части системы. |
Решения с низким кодом и без кода
Некоторые логики, необходимые для реализации визуального распознавания генерированного искусственного интеллекта, можно быстро создавать и размещать надежно с помощью решения с низким кодом или без кода.
| Продукт | Description |
|---|---|
| Azure AI Foundry | Вы можете использовать Azure AI Foundry для обучения, тестирования и развертывания пользовательских моделей машинного обучения для улучшения системы чата RAG. Например, используйте Azure AI Foundry для настройки создания ответов или повышения релевантности полученных сведений. |
Векторная база данных
Для некоторых генеративных решений ИИ может потребоваться хранение и извлечение данных, используемых для укрепления генерации. Примером является система чата на основе RAG, которая позволяет пользователям общаться с данными вашей организации. В этом случае требуется векторное хранилище данных.
| Продукт | Description |
|---|---|
| Поиск по искусственному интеллекту Azure | Эту службу можно использовать для эффективного поиска по большим наборам данных, чтобы найти соответствующую информацию, которая сообщает ответы, созданные языковой моделью. Это полезно для компонента, отвечающего за извлечение в системе RAG, чтобы создаваемые ответы были максимально информативными и релевантными контексту. |
| Azure Cosmos DB | Эта глобально распределенная служба базы данных с несколькими моделями может хранить огромные объемы структурированных и неструктурированных данных, к которым должна обращаться система чата RAG. Его быстрые возможности чтения и записи делают его идеальным для обслуживания данных в режиме реального времени в языковой модели и для хранения взаимодействия пользователей для дальнейшего анализа. |
| Кэш Azure для Redis | Это полностью управляемое хранилище данных в памяти можно использовать для кэширования часто доступных сведений, снижения задержки и повышения производительности системы чата RAG. Особенно полезно хранить данные сеанса, предпочтения пользователей и распространенные запросы. |
| Azure Database for PostgreSQL — гибкий сервер | Эта служба управляемой базы данных может хранить данные приложения, включая журналы, профили пользователей и исторические данные чата. Ее гибкость и масштабируемость поддерживают динамические потребности системы чата RAG, чтобы данные были постоянно доступны и безопасны. |
Каждая из этих служб Azure способствует созданию комплексной, масштабируемой и эффективной архитектуры для создания решения искусственного интеллекта. Они помогают разработчикам получать доступ и использовать лучшие возможности облака Azure и технологии искусственного интеллекта.
Разработка искусственного интеллекта с учетом кода с помощью API OpenAI Azure
В этом разделе мы сосредоточимся на API OpenAI Azure. Как упоминалось ранее, вы обращаетесь к функциям LLM программным способом через веб-API RESTful. Вы можете использовать буквально любой современный язык программирования для вызова этих API. Во многих случаях пакеты SDK для конкретного языка или платформы работают как оболочки вокруг вызовов REST API, чтобы сделать интерфейс более идиоматичным.
Ниже приведен список оболочки REST API Azure OpenAI:
- Клиентская библиотека Azure OpenAI для .NET
- Клиентская библиотека Azure OpenAI для Java
- Клиентская библиотека Azure OpenAI для JavaScript
- Клиентский модуль Azure OpenAI для Go
- Используйте пакет OpenAI Python и измените несколько опций. Python не предлагает клиентскую библиотеку Azure.
Если язык или пакет SDK платформы недоступен, худший сценарий заключается в том, что необходимо выполнять вызовы REST непосредственно к веб-API:
Большинство разработчиков знакомы с тем, как вызывать веб-API.
Azure OpenAI предлагает широкий спектр API, предназначенных для упрощения различных типов задач с использованием искусственного интеллекта, поэтому разработчики могут интегрировать расширенные функциональные возможности искусственного интеллекта в свои приложения. Ниже приведен обзор ключевых API, доступных в OpenAI:
- API завершения чата. Этот API ориентирован на сценарии создания текста, включая возможности общения для поддержки создания чат-ботов и виртуальных помощников, которые могут участвовать в естественном, человеческом диалоге. Он оптимизирован для интерактивных вариантов использования, включая поддержку клиентов, личные помощники и интерактивные учебные среды. Однако он используется для всех сценариев создания текста, включая суммирование, автозавершение, написание документов, анализ текста и перевод. Это точка входа для возможностей визуального зрения, которые в настоящее время находятся в предварительной версии (т. е. для отправки изображения и задавать вопросы об этом).
- API модерации. Данный API разработан для помощи разработчикам в выявлении и фильтрации потенциально опасного контента в тексте. Это инструмент, который помогает обеспечить безопасное взаимодействие с пользователем, автоматически обнаруживая оскорбительные, небезопасные или иным образом неуместные материалы.
- API внедрения: API внедрения создает векторные представления текстовых входных данных. Он преобразует слова, предложения или абзацы в высокомерные векторы. Эти внедрения можно использовать для семантического поиска, кластеризации, анализа сходства содержимого и многого другого. Он фиксирует базовое значение и семантические связи в тексте.
- API создания изображений. Используйте этот API для создания исходных, высококачественных изображений и искусства из текстовых описаний. Он основан на DALL OpenAI· Модель E, которая может создавать изображения, соответствующие широкому спектру стилей и тем на основе получаемых запросов.
- API аудио: этот API предоставляет доступ к звуковой модели OpenAI и предназначен для автоматического распознавания речи. Он может транскрибировать речевой язык в текст или текст в речь, поддерживая различные языки и диалекты. Это полезно для приложений, требующих голосовых команд, транскрибирования аудиоконтентности и многое другое.
Хотя вы можете использовать генерирующий ИИ для работы с различными модалями мультимедиа, в остальной части этой статьи мы сосредоточимся на текстовых решениях для создания ИИ. К этим решениям относятся такие сценарии, как чат и сводка.
Начните разрабатывать с генеративным искусственным интеллектом
Разработчики программного обеспечения, которые являются новыми для незнакомого языка, API или технологии, обычно начинают изучать его, следуя руководствам или учебным модулям, которые демонстрируют, как создавать небольшие приложения. Некоторые разработчики программного обеспечения предпочитают использовать самонаправляемый подход и создавать небольшие экспериментальные приложения. Оба подхода являются допустимыми и полезными.
Когда вы начинаете работу, лучше всего начать с малого, давать меньше обещаний, итеративно улучшать и постепенно строить свои навыки и понимание. Разработка приложений с помощью генерного ИИ имеет уникальные проблемы. Например, в традиционной разработке программного обеспечения можно полагаться на детерминированные выходные данные. То есть для любого набора входных данных можно ожидать одинаковые выходные данные каждый раз. Но генерированный ИИ недетерминирован. Вы никогда не получаете один и тот же ответ дважды для заданного запроса, который находится в корне многих новых проблем.
По мере начала рассмотрим эти советы.
Совет 1. Будьте ясны о том, что вы хотите достичь
- Обратите внимание на проблему, которую вы пытаетесь решить: генерированный ИИ может решить широкий спектр проблем, но успех происходит от четкого определения конкретной задачи, которую вы стремитесь решить. Вы пытаетесь создать текст, изображения, код или что-то другое? Чем более конкретный, тем лучше вы можете адаптировать ИИ в соответствии с вашими потребностями.
- Понимание аудитории: знание аудитории помогает адаптировать выходные данные ИИ в соответствии с их ожиданиями, будь то случайные пользователи или эксперты в определенном поле.
Совет 2. Использование сильных сторон LLM
- Понимание ограничений и предвзятостей LLM-ов: хотя LLM-ы мощны, они имеют ограничения и предубеждения. Знание ограничений и предвзятости может помочь вам разработать их или включить способы устранения рисков.
- Узнайте, в чем LLMs преуспевают: LLMs преуспевают в таких задачах, как создание контента, резюмирование и перевод языка. Хотя их возможности принятия решений и дискриминирующие возможности становятся сильнее с каждой новой версией, могут быть другие типы ИИ, которые более подходящи для вашего сценария или варианта использования. Выберите подходящее средство для задания.
Совет 3. Для получения хороших результатов используйте хорошие запросы
- Ознакомьтесь с рекомендациями по проектированию запросов: создание эффективных подсказок — это искусство. Поэкспериментируйте с различными запросами, чтобы узнать, как они влияют на выходные данные. Будьте краткими, но описательными.
- Фиксация итеративного уточнения. Часто первый запрос может не дать желаемого результата. Это процесс проб и ошибок. Используйте выходные данные для дальнейшего уточнения запросов.
Создание первого решения для создания искусственного интеллекта
Если вы хотите сразу же начать экспериментировать с созданием генеративного решения искусственного интеллекта, рекомендуется ознакомиться с и начать работу с чатом, используя собственный образец данных для Python. Это руководство также доступно для .NET, Javaи JavaScript.
Окончательные рекомендации по проектированию приложений
Ниже приведен краткий список вещей, которые следует рассмотреть и другие варианты из этой статьи, которые могут повлиять на ваши решения по проектированию приложений:
- Четко определите пространство проблем и аудиторию для выравнивания возможностей ИИ с ожиданиями пользователей. Оптимизируйте эффективность решения для предполагаемого варианта использования.
- Используйте платформы с низким кодом или без кода для быстрого создания прототипов и разработки, если они соответствуют требованиям проекта. Оцените компромисс между скоростью разработки и настройкой. Узнайте о возможностях решений с низким кодом и без кода для частей приложения, чтобы ускорить разработку и разрешить участникам нетехнических команд внести свой вклад в проект.