Создание продвинутых систем генерации с дополнением через извлечение
В этой статье подробно рассматривается генерация с дополненным извлечением (RAG). Мы описываем работу и рекомендации, необходимые разработчикам для создания решения RAG, готового к работе.
Чтобы узнать о двух вариантах создания приложения "чат на основе ваших данных", одного из основных вариантов использования генеративного ИИ в бизнесе, см. Дополнение LLM с помощью RAG или точной настройки.
На следующей схеме показаны шаги или этапы RAG:
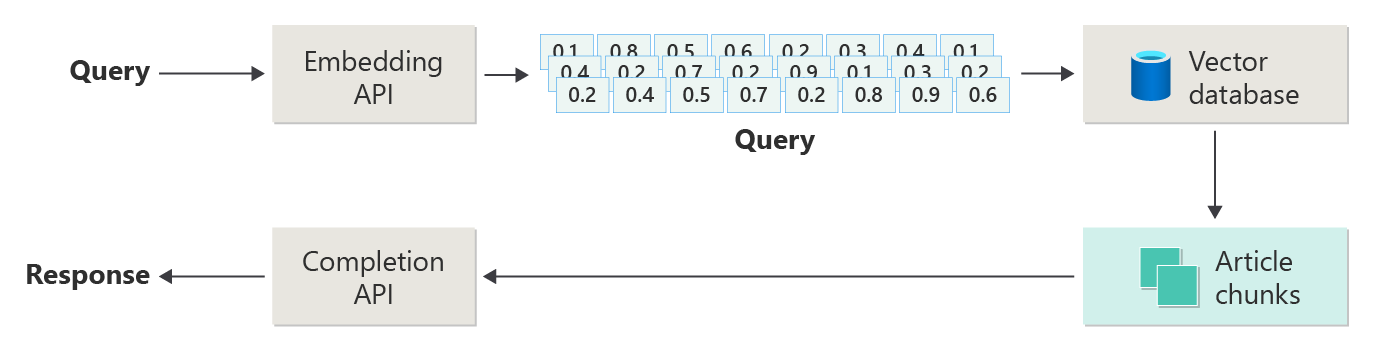
Это изображение называется наивное RAG. Это полезный способ первоначально понять механизмы, роли и обязанности, необходимые для реализации системы чата на основе RAG.
Но реализация в реальном мире имеет гораздо больше шагов предварительной обработки и последующей обработки для подготовки статей, запросов и ответов для использования. На следующей схеме представлено более реалистичное изображение RAG, иногда называемого расширенным RAG .

В этой статье представлена концептуальная платформа для понимания этапов предварительной обработки и последующей обработки в реальной системе чата на основе RAG:
- Этап приема
- Этап конвейера вывода
- Этап оценки
Прием (Ingestion)
Добавление в первую очередь заключается в хранении документов вашей организации для того, чтобы их можно было легко получить и ответить на вопрос пользователя. Задача заключается в том, чтобы части документов, которые лучше всего соответствовали запросу пользователя, находятся и используются во время вывода. Сопоставление выполняется главным образом путем векторизованных внедрения и совместного поиска сходства. Однако сопоставление упрощается путем понимания характера содержимого (например, шаблонов и форм) и стратегии организации данных (структура данных при его хранении в векторной базе данных).
Для обработки данных разработчикам следует рассмотреть следующие шаги:
- Предварительная обработка и извлечение содержимого
- Стратегия фрагментирования
- Организация блокирования
- Стратегия обновления
Предварительная обработка и извлечение содержимого
Чистое и точное содержимое является одним из лучших способов улучшить общее качество системы чата на основе RAG. Чтобы получить чистое, точное содержимое, начните с анализа фигуры и формы документов, которые необходимо индексировать. Соответствуют ли документы указанным шаблонам содержимого, таким как документация? Если нет, какие типы вопросов могут ответить на документы?
Как минимум, создайте шаги в конвейере приема:
- Стандартизация текстовых форматов
- Обработка специальных символов
- Удаление несвязанного, устаревшего содержимого
- Учетная запись для содержимого с версиями
- Учетная запись взаимодействия с контентом (вкладки, изображения, таблицы)
- Извлечение метаданных
Некоторые из этих сведений (например, метаданные) могут оказаться полезными, если они хранятся в векторной базе данных совместно с документом для использования во время процесса извлечения и оценки в конвейере вывода. Его также можно объединить с текстовым фрагментом, чтобы повлиять на векториальное представление блока.
Стратегия фрагментирования
Разработчик должен решить, как разбить более крупный документ на небольшие блоки. Фрагментирование может повысить релевантность дополнительного содержимого, отправленного в LLM, чтобы точно отвечать на запросы пользователей. Также рассмотрите, как использовать блоки после их получения. Системные дизайнеры должны исследовать распространенные отраслевые методы и выполнять некоторые эксперименты. Вы можете даже протестировать стратегию в ограниченном объеме в вашей организации.
Разработчики должны учитывать следующее:
- оптимизации размера блока: определите идеальный размер блока и как назначить блок. По разделу? По абзацу? По предложению?
- перекрывающиеся и сектора скользящего окна: определите, следует ли разделить содержимое на дискретные блоки или сделать их пересекающимися? Вы даже можете сделать и то и другое в конструкции скользящего окна.
- Small2Big: когда фрагментирование выполняется на гранулярном уровне, как одно предложение, упорядочено ли оно так, чтобы было легко найти соседние предложения или абзац, в который оно входит? Получение этих сведений и предоставление их LLM может обеспечить ему дополнительный контекст для ответа на запросы пользователей. Дополнительные сведения см. в следующем разделе.
Организация блокирования
В системе RAG стратегическое упорядочение данных в векторной базе данных является ключом к эффективному получению соответствующей информации для расширения процесса создания. Ниже приведены типы стратегий индексирования и извлечения, которые можно рассмотреть:
- иерархические индексы. Этот подход включает создание нескольких слоев индексов. Индекс верхнего уровня (сводный индекс) быстро сокращает пространство поиска до подмножества потенциально соответствующих блоков. Индекс второго уровня (индекс блоков) предоставляет более подробные указатели на фактические данные. Этот метод может значительно ускорить процесс извлечения, так как он сначала осуществляет фильтрацию по сводному индексу, что уменьшает количество записей для сканирования в подробном индексе.
-
специализированные индексы. В зависимости от характера данных и связей между блоками можно использовать специализированные индексы, такие как графовые или реляционные базы данных:
- Индексы на основе графов полезны, если блоки имеют взаимосвязанные сведения или связи, которые могут улучшить получение, такие как сети ссылок или графы знаний.
- реляционные базы данных могут быть эффективными, если блоки структурированы в табличном формате. Используйте запросы SQL для фильтрации и извлечения данных на основе определенных атрибутов или связей.
- гибридные индексы: гибридный подход объединяет несколько методов индексирования, чтобы применить их сильные стороны к вашей общей стратегии. Например, можно использовать иерархический индекс для начальной фильтрации и графового индекса для динамического изучения связей между блоками во время извлечения.
Оптимизация выравнивания
Чтобы повысить релевантность и точность полученных блоков, выровняйте их в соответствии с типами вопросов или запросов, которые они отвечают. Одна из стратегий заключается в создании и вставке гипотетического вопроса для каждого блока, представляющего вопрос, который лучше всего подходит для ответа. Это помогает несколькими способами:
- Улучшенное сопоставление: во время извлечения система может сравнить входящие запросы с этими гипотетическими вопросами, чтобы найти лучшее соответствие для повышения релевантности фрагментов, которые извлекаются.
- обучающие данные для моделей машинного обучения: эти пары вопросов и блоков могут быть обучающими данными для улучшения моделей машинного обучения, которые являются базовыми компонентами системы RAG. Система RAG узнает, какие типы вопросов лучше всего решаются отдельными блоками.
- обработке прямых запросов. Если реальный запрос пользователя тесно соответствует гипотетическому вопросу, то система может быстро получить и использовать соответствующий блок и тем самым ускорить время отклика.
Гипотетический вопрос каждого блока действует как метка, которая управляет алгоритмом извлечения, поэтому он более сосредоточен и внимателен к контексту. Такой способ оптимизации полезен, если блоки охватывают широкий спектр информационных разделов или типов.
Стратегии обновления
Если ваша организация индексирует документы, которые часто обновляются, необходимо поддерживать обновленный корпус, чтобы гарантировать, что компонент извлекателя может получить доступ к самой актуальной информации. Компонент
инкрементальные обновления:
- регулярные интервалы: Запланируйте обновления через регулярные интервалы (например, ежедневно или еженедельно) в зависимости от частоты изменений в документе. Этот метод гарантирует, что база данных периодически обновляется по известному расписанию.
- обновления на основе триггеров: реализуйте систему, в которой обновление активирует переиндексирование. Например, любое изменение или добавление документа автоматически инициирует переиндексирование в затронутых разделах.
Частичные обновления:
- выборочное повторное индексирование: вместо повторной индексации всей базы данных обновите только измененные части корпусов. Этот подход может быть более эффективным, чем полная переиндексация, особенно для больших наборов данных.
- Разностная кодировка: храните только различия между существующими документами и их обновленными версиями. Такой подход снижает нагрузку на обработку данных, избегая необходимости обработки без изменений данных.
Версионирование:
- Моментальный снимок: обслуживание версий корпусов документов в разные моменты времени. Этот метод предоставляет механизм резервного копирования и позволяет системе вернуться к предыдущим версиям или ссылаться на нее.
- Управление версиями документа: используйте систему управления версиями для систематического отслеживания изменений документа для поддержания журнала изменений и упрощения процесса обновления.
обновления в режиме реального времени:
- Потоковая обработка: Когда важна актуальность информации, используйте технологии потоковой обработки для обновления векторной базы данных в реальном времени по мере внесения изменений в документ.
- динамические запросы. Вместо того, чтобы полагаться исключительно на прединдексированные векторы, используйте динамический подход к запросу данных для ответов up-to-date, возможно, объединение динамических данных с кэшируемыми результатами для повышения эффективности.
Техники оптимизации:
пакетной обработки: Пакетная обработка накапливает изменения, которые применяются реже для оптимизации ресурсов и снижения накладных расходов.
гибридные подходы: объединение различных стратегий:
- Используйте добавочные обновления для незначительных изменений.
- Используйте полное переиндексирование при основных обновлениях.
- Документируйте структурные изменения, внесенные в корпус.
Выбор правильной стратегии обновления или правильного сочетания зависит от конкретных требований, включая:
- Размер корпуса документа
- Частота обновления
- Потребности в данных в режиме реального времени
- Доступность ресурсов
Оцените эти факторы на основе потребностей конкретного приложения. Каждый подход имеет компромиссы по сложности, затратам и задержке обновления.
Конвейер вывода
Ваши статьи разделены на части, векторизованы и хранятся в векторной базе данных. Теперь сосредоточьтесь на решении сложностей завершения.
Чтобы получить наиболее точные и эффективные завершения, необходимо учитывать множество факторов:
- Записывается ли запрос пользователя таким образом, чтобы получить результаты, которые ищет пользователь?
- Нарушает ли запрос пользователя какие-либо политики организации?
- Как переписать запрос пользователя, чтобы повысить вероятность поиска ближайших совпадений в векторной базе данных?
- Как оценить результаты запроса, чтобы убедиться, что блоки статьи соответствуют запросу?
- Как оценить и изменить результаты запроса перед передачей в LLM, чтобы убедиться, что наиболее важные сведения включены в итоговый результат?
- Как оценить ответ LLM, чтобы убедиться, что завершение LLM отвечает на исходный запрос пользователя?
- Как убедиться, что ответ LLM соответствует политикам организации?
Весь конвейер вывода выполняется в режиме реального времени. Существует не один правильный способ разработки предварительных и постпроцессных шагов. Скорее всего, вы выберете сочетание логики программирования и других вызовов LLM. Одним из наиболее важных аспектов является компромисс между созданием наиболее точного и соответствующего конвейера, а также затратами и задержкой, необходимыми для его выполнения.
Давайте определим конкретные стратегии на каждом этапе конвейера вывода.
Шаги предварительной обработки запросов
Предварительная обработка запроса возникает сразу после отправки пользователем запроса:

Цель этих действий заключается в том, чтобы убедиться, что пользователь задает вопросы, находящиеся в пределах вашей системы, и подготовить запрос пользователя, чтобы повысить вероятность того, что она находит наиболее возможные фрагменты статей с помощью косинусного поиска или "ближайшего соседа".
проверка политик: Этот шаг включает логику, которая определяет, удаляет, помечает или отклоняет определенное содержимое. Некоторые примеры включают удаление персональных данных, удаление бранных слов и выявление попыток взлома системы. Джейлбрейк относится к попыткам пользователя обойти или изменить встроенные правила безопасности, этики или эксплуатации модели.
перезаписи запросов.Этот шаг может включать всё: от расширения аббревиатур и удаления сленга до перефразирования вопроса для более абстрактной формулировки, с целью выявления высокоуровневых понятий и принципов (шаг назад, чтобы задать вопрос).
Вариация подсказывания с шагом назад — Гипотетические встраивания документов (HyDE). HyDE использует LLM для ответа на вопрос пользователя, создает внедрение для этого ответа (гипотетическое внедрение документа), а затем использует внедрение для выполнения поиска в векторной базы данных.
Подзапросы
Этап обработки вложенных запросов основан на исходном запросе. Если исходный запрос является длинным и сложным, его можно программно разбить на несколько небольших запросов, а затем объединить все ответы.
Например, вопрос о научных открытиях в физике может быть: "Кто сделал более значительный вклад в современную физику, Альберт Эйнштейн или Нилс Бор?"
Разбиение сложных запросов в вложенные запросы делает их более управляемыми:
- Subquery 1: "Каковы ключевые вклады Альберта Эйнштейна в современную физику?"
- Subquery 2: "Каковы ключевые вклады Нилса Бора в современную физику?"
Результаты этих вложенных запросов подробно описывают основные теории и открытия каждого физика. Например:
- Для Эйнштейна взносы могут включать теорию относительности, фотоэлектрический эффект и E=mc^2.
- Для Бора, вклады могут включать в себя модель Бора атома водорода, работу Бора по квантовой механике, и принцип взаимодополняемости Бора.
Когда эти вклады очерчены, их можно оценить, чтобы определить больше подзапросов. Например:
- Subquery 3: "Как теории Эйнштейна повлияли на развитие современной физики?"
- Subquery 4: "Как теории Бора повлияли на развитие современной физики?"
Эти вложенные запросы изучают влияние каждого ученого на физику, например:
- Как теории Эйнштейна привели к прогрессу в космологии и квантовой теории
- Как работа Бора способствовала пониманию атомарной структуры и квантовой механики
Объединение результатов этих вложенных запросов может помочь языковой модели сформировать более полный ответ о том, кто сделал более значительный вклад в современную физику на основе их теоретических достижений. Этот метод упрощает исходный сложный запрос путем доступа к более конкретным, ответным компонентам, а затем синтезирует эти выводы в согласованный ответ.
Маршрутизатор запросов
Ваша организация может разделить свой корпус содержимого на несколько векторных хранилищ или на все системы извлечения. В этом сценарии можно использовать маршрутизатор запросов. Маршрутизатор запросов выбирает наиболее подходящую базу данных или индекс, чтобы предоставить лучшие ответы на конкретный запрос.
Маршрутизатор запросов обычно работает в точке после того, как пользователь сформулирует запрос, но перед отправкой запроса в системы извлечения.
Ниже приведен упрощенный рабочий процесс для маршрутизатора запросов:
- анализ запросов: LLM или другой компонент анализирует входящие запросы, чтобы понять его содержимое, контекст и тип информации, которая, вероятно, нужна.
- выбор индекса. На основе анализа маршрутизатор запросов выбирает один или несколько индексов из потенциально нескольких доступных индексов. Каждый индекс может быть оптимизирован для различных типов данных или запросов. Например, некоторые индексы могут быть более подходящими для фактических запросов. Другие индексы могут преуспеть в предоставлении мнений или субъективного содержимого.
- Диспетчеризация запросов: запрос отправляется в выбранный индекс.
- агрегирование результатов. Ответы из выбранных индексов извлекаются и, возможно, агрегируются или обрабатываются для формирования комплексного ответа.
- поколение ответов. Последний шаг включает создание последовательного ответа на основе полученной информации, возможно, интеграции или синтезирования содержимого из нескольких источников.
Ваша организация может использовать несколько обработчиков извлечения или индексов для следующих вариантов использования:
- специализация типа данных: некоторые индексы могут специализируется на новостных статьях, других в академических статьях, а также другие в общих веб-материалах или конкретных базах данных, таких как медицинская или юридическая информация.
- оптимизации типов запросов: некоторые индексы могут быть оптимизированы для быстрого поиска фактических данных (например, дат или событий). Другие могут быть лучше использованы для сложных задач, требующих логического мышления, или для запросов, требующих глубоких знаний в области.
- различия алгоритмов. Различные алгоритмы извлечения могут использоваться в разных механизмах, таких как поиск сходства на основе векторов, традиционные поиски на основе ключевых слов или более сложные модели семантического понимания.
Представьте себе систему на основе RAG, которая используется в контексте медицинских консультаций. Система имеет доступ к нескольким индексам:
- Индекс статей медицинских исследований, оптимизированный для подробных и технических объяснений
- Клинический индекс исследования, который предоставляет реальные примеры симптомов и лечения
- Общий индекс информации о здоровье для основных запросов и общественного здравоохранения
Если пользователь задает технический вопрос о последствиях нового препарата, маршрутизатор запросов может определить приоритет индекса бумаги для медицинских исследований из-за его глубины и технического фокуса. Для вопроса о типичных симптомах распространенной болезни, однако, общий индекс здоровья может быть выбран для его широкого и легко понятного содержания.
Этапы обработки после извлечения
Обработка после получения происходит после того, как компонент извлекателя извлекает соответствующие фрагменты содержимого из векторной базы данных:

При извлечении фрагментов содержимого кандидатов следующий шаг — проверить полезность фрагмента статьи при расширении запроса LLM перед подготовкой запроса для его представления в LLM.
Ниже приведены некоторые аспекты запроса для рассмотрения:
- Включение слишком большого количества дополнительных сведений может привести к игнорирую наиболее важных сведений.
- Включение неуместных сведений может отрицательно повлиять на ответ.
Другим соображением является проблема поиска иголки в стоге сена, термин, который относится к известной особенности некоторых LLM, при которой содержимое в начале и конце запроса имеет больший вес для LLM, чем содержимое в середине.
Наконец, рассмотрим максимальную длину окна контекста LLM и количество токенов, необходимых для выполнения чрезвычайно длинных подсказок (особенно для выполнения запросов в масштабе).
Для решения этих проблем конвейер обработки после извлечения может включать следующие действия:
- результаты фильтрации. На этом шаге убедитесь, что фрагменты статьи, возвращаемые векторной базой данных, относятся к запросу. Если их нет, результат игнорируется при создании запроса LLM.
- повторное ранжирование: ранжирует фрагменты статьи, полученные из векторного хранилища, чтобы убедиться, что соответствующие сведения находятся рядом с краями (начало и конец) запроса.
- сжатие запроса: используйте небольшую, недорогую модель для сжатия и суммирования нескольких фрагментов статей в единый сжатый запрос перед отправкой запроса в LLM.
Этапы обработки после завершения
Обработка после завершения происходит после запроса пользователя и отправки всех блоков содержимого в LLM:

Проверка точности происходит после завершения запроса LLM. Конвейер обработки после завершения может включать следующие действия:
- проверка фактов: намерение заключается в определении конкретных утверждений, сделанных в статье, которые представлены как факты, а затем проверять эти факты на точность. Если шаг проверки фактов завершается сбоем, может потребоваться повторно выполнить запрос LLM в надежде получить лучший ответ или вернуть пользователю сообщение об ошибке.
- проверка соответствия политике: Последняя линия защиты, гарантирующая, что ответы не содержат вредного содержимого ни для пользователя, ни для организации.
Оценка
Оценка результатов недетерминированной системы не так проста, как выполнение модульных или интеграционных тестов, с которыми знакомо большинство разработчиков. Необходимо учитывать несколько факторов:
- Удовлетворены ли пользователи результатами, которые они получают?
- Получают ли пользователи точные ответы на их вопросы?
- Как записать отзывы пользователей? У вас есть какие-либо политики, ограничивающие, какие данные можно собирать о пользовательских данных?
- Для диагностики неудовлетворительных ответов у вас есть доступ ко всей работе, проведенной для ответа на вопрос? Храните ли журнал каждого этапа в конвейере вывода входных и выходных данных, чтобы можно было выполнить анализ первопричин?
- Как вносить изменения в систему без регрессии или ухудшения результатов?
Запись и выполнение отзывов от пользователей
Как описано ранее, вам может потребоваться работать с командой по конфиденциальности вашей организации для разработки механизмов отслеживания отзывов, телеметрии и ведения журнала для судебной экспертизы и анализа первопричин сеанса запроса.
Следующим шагом является разработка конвейера оценки. Конвейер оценки помогает со сложностью и трудоемким характером анализа дословных отзывов и первопричин ответов, предоставляемых системой ИИ. Этот анализ имеет решающее значение, поскольку он включает в себя изучение каждого ответа, чтобы понять, как запрос искусственного интеллекта создал результаты, проверяя правильность фрагментов содержимого, которые используются из документации, и стратегии, используемые в делении этих документов.
Он также включает в себя рассмотрение любых дополнительных шагов предварительной обработки или последующей обработки, которые могут улучшить результаты. Этот подробный анализ часто обнаруживает пробелы в содержимом, особенно если соответствующая документация не существует для ответа на запрос пользователя.
Создание конвейера оценки становится важным для эффективного управления масштабом этих задач. Эффективный конвейер использует кастомные инструменты для оценки усредненных метрик, приближающих качество ответов, предоставляемых ИИ. Эта система упрощает процесс определения того, почему конкретный ответ был предоставлен пользователю, какие документы использовались для создания этого ответа, а также эффективность конвейера вывода, обрабатывающего запросы.
Золотой набор данных
Одной из стратегий оценки результатов недетерминированной системы, такой как система чата RAG, является использование золотого набора данных. золотой набор данных — это подобранный набор вопросов с утвержденными ответами, метаданные (например, тема и тип вопроса), ссылки на исходные документы, которые могут служить эталоном для ответов, и даже вариации (различные формулировки, чтобы отразить разнообразие того, как пользователи могут задавать одни и те же вопросы).
Золотой набор данных представляет "лучший сценарий". Разработчики могут оценить систему, чтобы узнать, насколько хорошо она работает, а затем выполнять регрессионные тесты при реализации новых функций или обновлений.
Оценка вреда
Моделирование вреда — это методология, направленная на предвидение потенциального вреда, выявления недостатков в продукте, которые могут представлять риски для отдельных лиц, и разработки упреждающих стратегий для устранения таких рисков.
Инструмент, предназначенный для оценки влияния технологий, в частности системы искусственного интеллекта, будет включать несколько ключевых компонентов на основе принципов моделирования вреда, как описано в предоставленных ресурсах.
Ключевыми функциями средства оценки вреда могут быть:
идентификации заинтересованных лиц: это средство может помочь пользователям выявлять и классифицировать различные заинтересованные лица, затронутые технологией, включая прямых пользователей, косвенно затронутых сторон и других сущностей, таких как будущие поколения или нечеловеческие факторы, такие как экологические проблемы.
категории вреда и описания: инструмент может включать полный список потенциальных причинений вреда, таких как потеря конфиденциальности, эмоциональный стресс или экономическая эксплуатация. Это средство может помочь пользователю в различных сценариях, иллюстрировать, как технология может причинить эти повреждения, и помочь оценить как предполагаемые, так и непредвиденные последствия.
Оценка серьезности и вероятности: инструмент может помочь пользователям оценить серьезность и вероятность каждого идентифицированного вреда. Пользователь может определить приоритеты проблем, которые необходимо сначала решить. Примеры включают качественные оценки, поддерживаемые данными, где они доступны.
стратегии устранения рисков: инструмент может предложить потенциальные стратегии устранения рисков после определения и оценки вреда. К примерам относятся изменения в проектировании системы, добавлении гарантий и альтернативных технологических решений, которые свести к минимуму выявленные риски.
механизмы обратной связи: инструмент должен включать механизмы сбора отзывов заинтересованных лиц, чтобы процесс оценки вреда был динамическим и адаптивным к новым сведениям и перспективам.
документации и отчетности. Для прозрачности и подотчетности инструмент может способствовать созданию подробных отчетов, документирующих процесс оценки ущерба, выводы и потенциальные действия по снижению рисков.
Эти функции помогают выявлять и устранять риски, но они также помогают создавать более этические и ответственные системы ИИ, рассматривая широкий спектр последствий с самого начала.
Дополнительные сведения см. в следующих статьях:
Тестирование и проверка гарантий
В этой статье описывается несколько процессов, направленных на устранение возможности использования или компрометации системы чата на основе RAG. Red-teaming играет важную роль в обеспечении эффективности мер защиты. Red-teaming включает имитацию действий потенциального злоумышленника для выявления слабых мест или уязвимостей в приложении. Этот подход особенно важен для решения значительного риска взлома тюрьмы.
Разработчики должны тщательно оценивать системы чата на основе RAG в различных сценариях руководства для эффективного тестирования и проверки их. Этот подход не только гарантирует надежность, но и помогает точно настроить ответы системы на строгое соблюдение определенных этических стандартов и операционных процедур.
Окончательные рекомендации по проектированию приложений
Ниже приведен краткий список вещей, которые следует рассмотреть и другие варианты из этой статьи, которые могут повлиять на ваши решения по проектированию приложений:
- Подтвердите недетерминированную природу генерированного искусственного интеллекта в вашем дизайне. Запланируйте вариативность выходных данных и настройте механизмы для обеспечения согласованности и релевантности в ответах.
- Оцените преимущества предварительной обработки запросов пользователей в отношении потенциального увеличения задержки и затрат. Упрощение или изменение запросов перед отправкой может повысить качество отклика, но может добавить сложность и время в цикл отклика.
- Чтобы повысить производительность, изучите стратегии параллелизации запросов LLM. Этот подход может снизить задержку, но требует тщательного управления, чтобы избежать повышения сложности и потенциальных последствий затрат.
Если вы хотите начать экспериментировать с созданием генеративного AI-решения немедленно, рекомендуем изучить Начало работы с чатом с использованием собственного примера данных на Python. Это руководство также доступно для .NET, Javaи JavaScript.