Устаревшие визуализации
В этой статье описываются устаревшие визуализации Azure Databricks. Сведения о текущей поддержке визуализаций см . в записных книжках Databricks.
Azure Databricks также нативно поддерживает библиотеки визуализации для Python и R, позволяя устанавливать и использовать сторонние библиотеки.
Создание устаревшей визуализации
Чтобы создать устаревшую визуализацию из ячейки результатов, щелкните + и selectУстаревшая Визуализация.
Устаревшие визуализации поддерживают широкий set типов графиков:
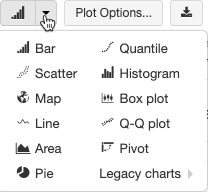
Выбор и настройка типа устаревшей диаграммы
Чтобы выбрать линейчатую диаграмму, щелкните значок  линейчатой диаграммы:
линейчатой диаграммы:
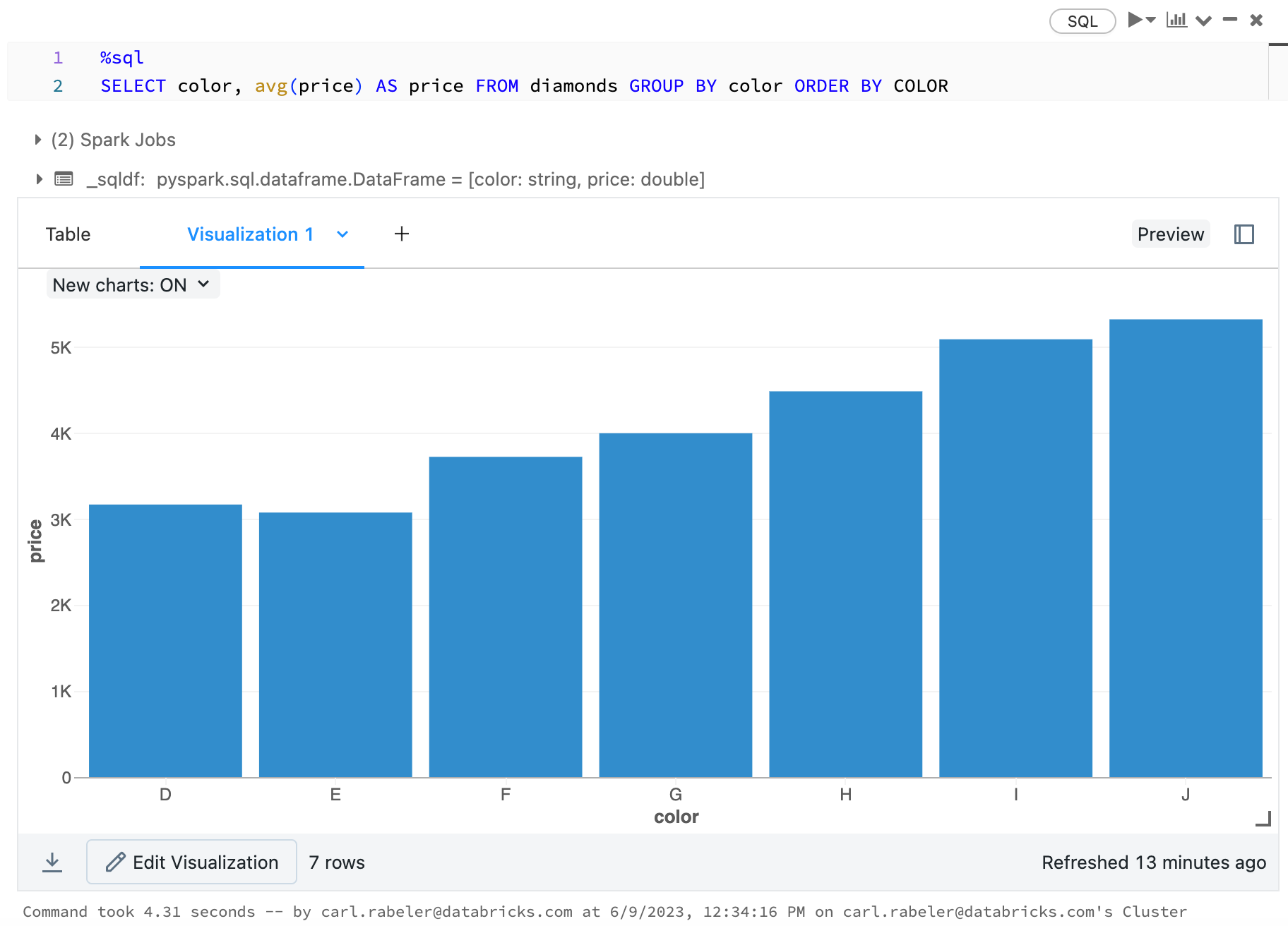
Чтобы выбрать другой тип диаграммы, щелкните ![]() справа от линейчатой диаграммы и выберите тип диаграммы .
справа от линейчатой диаграммы и выберите тип диаграммы .
Панель инструментов устаревшей диаграммы
Как линии, так и линейчатые диаграммы имеют встроенную панель инструментов, которая поддерживает широкий set взаимодействия на стороне клиента.
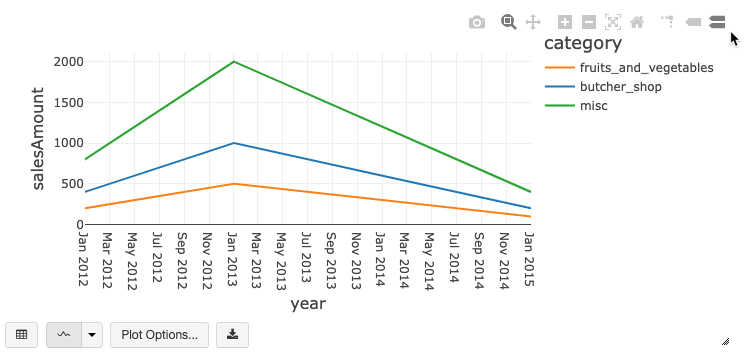
Чтобы настроить диаграмму, щелкните элемент Параметры построения...
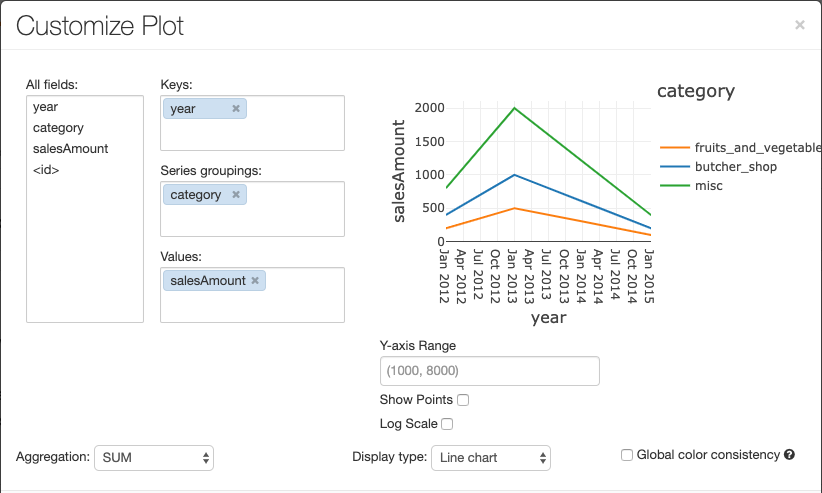
У линейчатой диаграммы есть несколько настраиваемых вариантов графика: настройка диапазона оси Y, отображение и скрытие точек, а также отображение оси Y с логарифмической шкалой.
Сведения об устаревших типах диаграмм см. здесь:
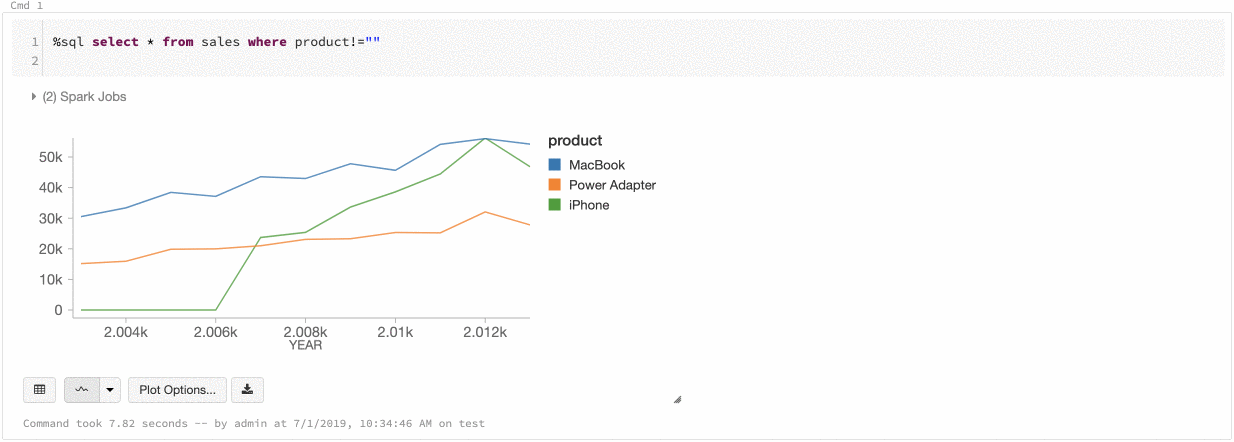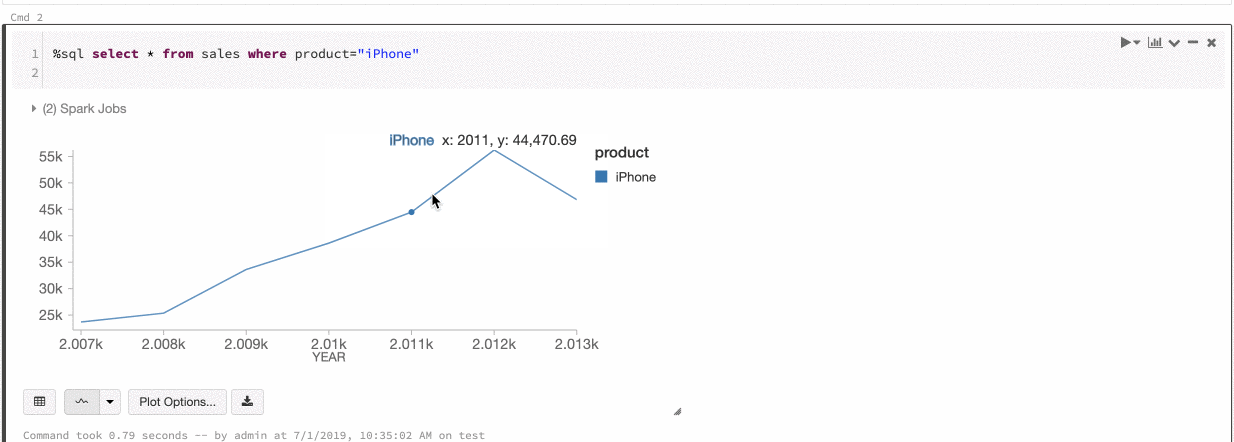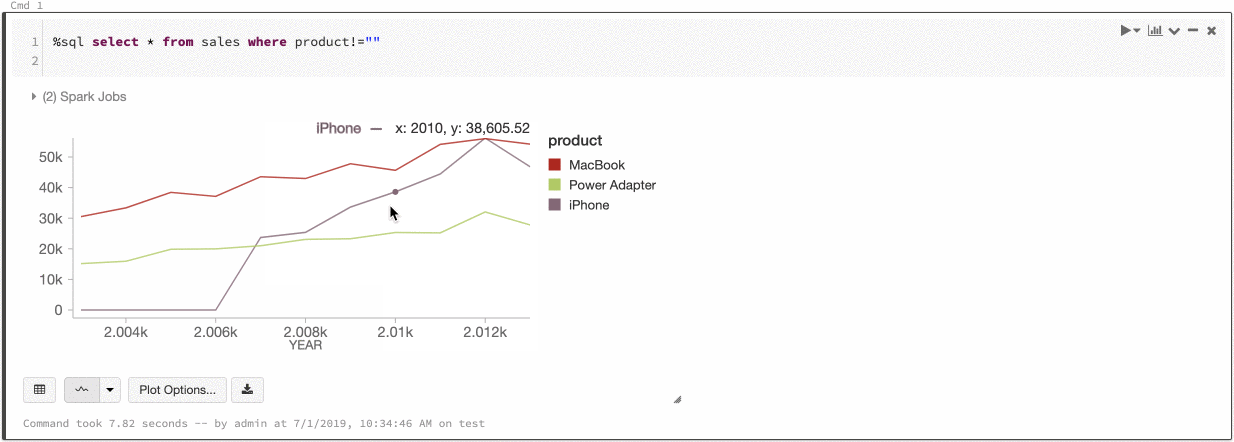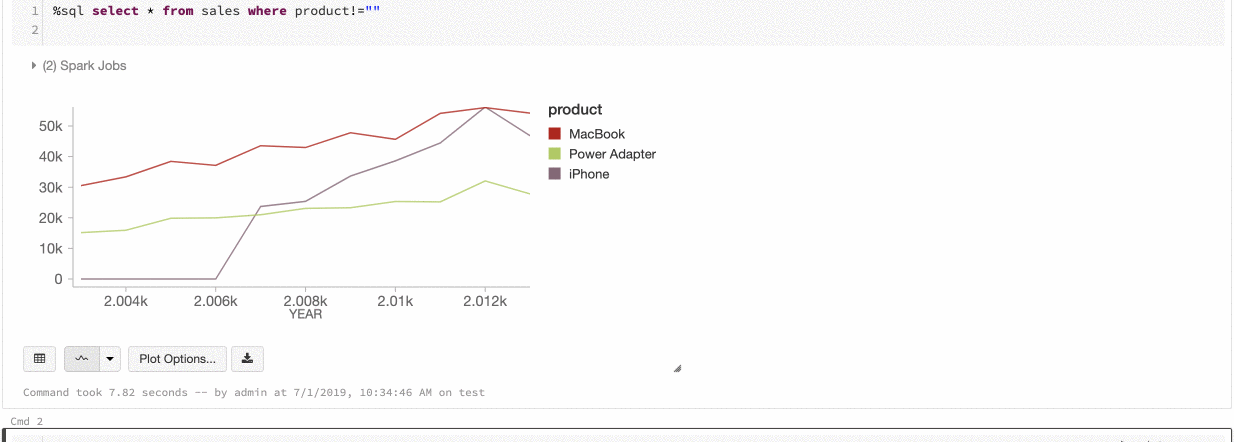
Согласованность цветов в диаграммах
Azure Databricks поддерживает два типа согласованности цветов в устаревших диаграммах: серии set и глобальных.
серии set согласованность цветов присваивает один и тот же цвет одному значению, если у вас есть ряды с одинаковыми values, но в различном порядке (например, A = ["Apple", "Orange", "Banana"] и B = ["Orange", "Banana", "Apple"]).
values отсортированы перед построением графика, поэтому обе легенды сортируются одинаково (["Apple", "Banana", "Orange"]), и тем же values присваиваются одинаковые цвета. Тем не менее, если у вас есть серия C = ["Orange", "Banana"], она не будет согласована по цвету с set А, так как set не совпадает. Алгоритм сортировки назначит первый цвет "Банан" в set C, но второй цвет "Банан" в set A. Если эти ряды должны быть цветообразующими, можно указать, что диаграммы должны иметь глобальную согласованность цветов.
В глобальной согласованности цветов каждое значение всегда сопоставляется с тем же цветом независимо от того, какие данные содержат values серии. Чтобы включить эту функцию для каждой диаграммы, установите флажок select.
Примечание.
Чтобы обеспечить эту согласованность, Azure Databricks прямо создает хеши от values к цветам. Чтобы избежать коллизий (where два values принимают один и тот же цвет), хэш используется для большого set цветов, что имеет побочный эффект: красивые или легко различимые цвета не могут быть гарантированы; у множества цветов обязательно найдутся некоторые, которые выглядят очень похоже.
Визуализации машинного обучения
Помимо стандартных типов диаграмм, наследуемые визуализации поддерживают следующие обучение машинного обучения parameters и результаты:
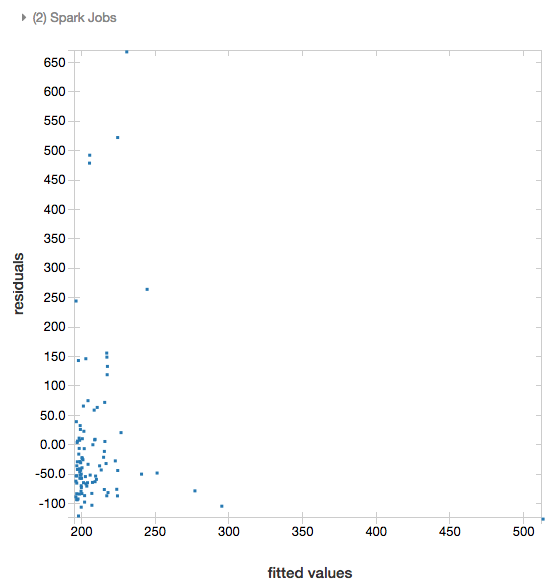
Остатки
Для линейной и логистической регрессии вы можете отрисовать график сопоставления совпадений и остатков. Чтобы получить такой график, предоставьте модель и кадр данных.
В следующем примере линейная регрессия выполняется для сопоставления населения городов и цен продажи недвижимости, а затем отображаются данные о сравнении остатков и совпадений.
# Load data
pop_df = spark.read.csv("/databricks-datasets/samples/population-vs-price/data_geo.csv", header="true", inferSchema="true")
# Drop rows with missing values and rename the feature and label columns, replacing spaces with _
from pyspark.sql.functions import col
pop_df = pop_df.dropna() # drop rows with missing values
exprs = [col(column).alias(column.replace(' ', '_')) for column in pop_df.columns]
# Register a UDF to convert the feature (2014_Population_estimate) column vector to a VectorUDT type and apply it to the column.
from pyspark.ml.linalg import Vectors, VectorUDT
spark.udf.register("oneElementVec", lambda d: Vectors.dense([d]), returnType=VectorUDT())
tdata = pop_df.select(*exprs).selectExpr("oneElementVec(2014_Population_estimate) as features", "2015_median_sales_price as label")
# Run a linear regression
from pyspark.ml.regression import LinearRegression
lr = LinearRegression()
modelA = lr.fit(tdata, {lr.regParam:0.0})
# Plot residuals versus fitted data
display(modelA, tdata)
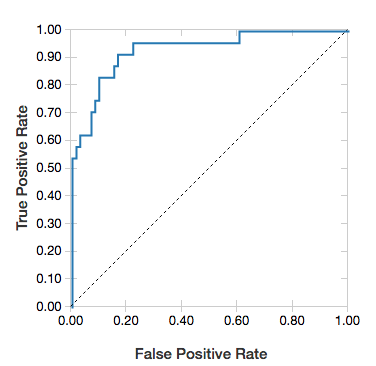
Кривые ROC
Для логистической регрессии можно выполнить отрисовку кривой ROC. Чтобы получить такой график, предоставьте модель, подготовленные входные данные для метода fit и параметр "ROC".
В следующем примере разрабатывается классификатор, который прогнозирует уровень дохода человека (не меньше или больше 50 000 в год) на основе различных атрибутов этого человека. Набор данных Adult получен из данных переписи населения и содержит информацию о 48 842 человеках и их годовом доходе.
В примере кода из этого раздела используется прямое кодирование.
# This code uses one-hot encoding to convert all categorical variables into binary vectors.
schema = """`age` DOUBLE,
`workclass` STRING,
`fnlwgt` DOUBLE,
`education` STRING,
`education_num` DOUBLE,
`marital_status` STRING,
`occupation` STRING,
`relationship` STRING,
`race` STRING,
`sex` STRING,
`capital_gain` DOUBLE,
`capital_loss` DOUBLE,
`hours_per_week` DOUBLE,
`native_country` STRING,
`income` STRING"""
dataset = spark.read.csv("/databricks-datasets/adult/adult.data", schema=schema)
from pyspark.ml import Pipeline
from pyspark.ml.feature import OneHotEncoder, StringIndexer, VectorAssembler
categoricalColumns = ["workclass", "education", "marital_status", "occupation", "relationship", "race", "sex", "native_country"]
stages = [] # stages in the Pipeline
for categoricalCol in categoricalColumns:
# Category indexing with StringIndexer
stringIndexer = StringIndexer(inputCol=categoricalCol, outputCol=categoricalCol + "Index")
# Use OneHotEncoder to convert categorical variables into binary SparseVectors
encoder = OneHotEncoder(inputCols=[stringIndexer.getOutputCol()], outputCols=[categoricalCol + "classVec"])
# Add stages. These are not run here, but will run all at once later on.
stages += [stringIndexer, encoder]
# Convert label into label indices using the StringIndexer
label_stringIdx = StringIndexer(inputCol="income", outputCol="label")
stages += [label_stringIdx]
# Transform all features into a vector using VectorAssembler
numericCols = ["age", "fnlwgt", "education_num", "capital_gain", "capital_loss", "hours_per_week"]
assemblerInputs = [c + "classVec" for c in categoricalColumns] + numericCols
assembler = VectorAssembler(inputCols=assemblerInputs, outputCol="features")
stages += [assembler]
# Run the stages as a Pipeline. This puts the data through all of the feature transformations in a single call.
partialPipeline = Pipeline().setStages(stages)
pipelineModel = partialPipeline.fit(dataset)
preppedDataDF = pipelineModel.transform(dataset)
# Fit logistic regression model
from pyspark.ml.classification import LogisticRegression
lrModel = LogisticRegression().fit(preppedDataDF)
# ROC for data
display(lrModel, preppedDataDF, "ROC")
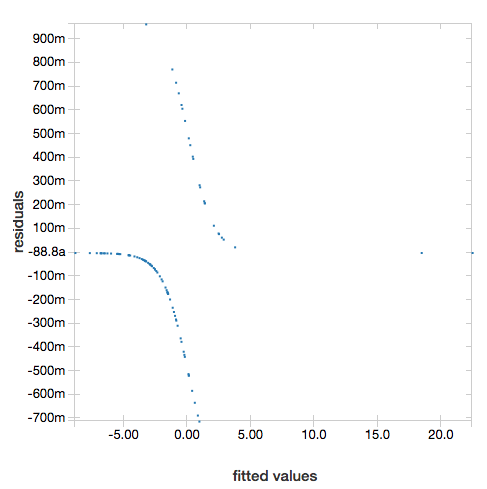
Чтобы отобразить остатки, опустите параметр "ROC":
display(lrModel, preppedDataDF)
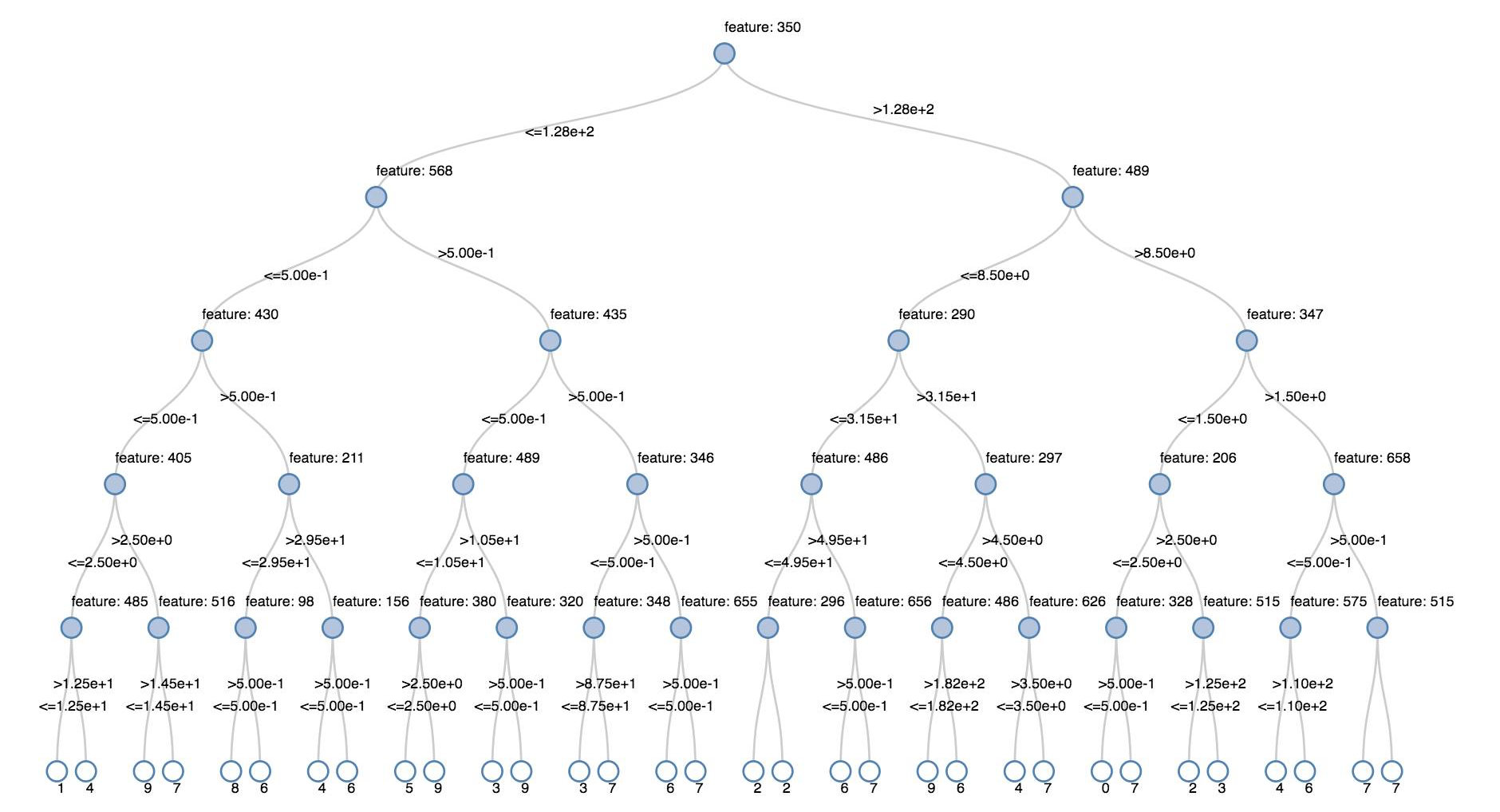
деревья принятия решений
Устаревшие визуализации поддерживают отрисовку дерева принятия решений.
Чтобы получить такую визуализацию, предоставьте модель дерева принятия решений.
В следующих примерах показано обучение дерева распознаванию цифр (0–9) по набору данных MNIST с изображениями рукописных цифр, а затем отображается полученное дерево.
Python
trainingDF = spark.read.format("libsvm").load("/databricks-datasets/mnist-digits/data-001/mnist-digits-train.txt").cache()
testDF = spark.read.format("libsvm").load("/databricks-datasets/mnist-digits/data-001/mnist-digits-test.txt").cache()
from pyspark.ml.classification import DecisionTreeClassifier
from pyspark.ml.feature import StringIndexer
from pyspark.ml import Pipeline
indexer = StringIndexer().setInputCol("label").setOutputCol("indexedLabel")
dtc = DecisionTreeClassifier().setLabelCol("indexedLabel")
# Chain indexer + dtc together into a single ML Pipeline.
pipeline = Pipeline().setStages([indexer, dtc])
model = pipeline.fit(trainingDF)
display(model.stages[-1])
Scala
val trainingDF = spark.read.format("libsvm").load("/databricks-datasets/mnist-digits/data-001/mnist-digits-train.txt").cache
val testDF = spark.read.format("libsvm").load("/databricks-datasets/mnist-digits/data-001/mnist-digits-test.txt").cache
import org.apache.spark.ml.classification.{DecisionTreeClassifier, DecisionTreeClassificationModel}
import org.apache.spark.ml.feature.StringIndexer
import org.apache.spark.ml.Pipeline
val indexer = new StringIndexer().setInputCol("label").setOutputCol("indexedLabel")
val dtc = new DecisionTreeClassifier().setLabelCol("indexedLabel")
val pipeline = new Pipeline().setStages(Array(indexer, dtc))
val model = pipeline.fit(trainingDF)
val tree = model.stages.last.asInstanceOf[DecisionTreeClassificationModel]
display(tree)
Структурированные кадры данных потоковой передачи
Чтобы визуализировать результат потокового запроса в режиме реального времени, можно выполнить display для структурированной потоковой таблицы данных в Scala и Python.
Python
streaming_df = spark.readStream.format("rate").load()
display(streaming_df.groupBy().count())
Scala
val streaming_df = spark.readStream.format("rate").load()
display(streaming_df.groupBy().count())
display поддерживает следующие необязательные parameters:
-
streamName: имя запроса потоковой передачи. -
trigger(Scala) иprocessingTime(Python): определяет частоту выполнения запроса потоковой передачи. Если значение не указано, система проверяет доступность новых данных сразу после предыдущей обработки. Чтобы сократить затраты в рабочей среде, Databricks рекомендует всегдаset интервал триггера. Интервал триггера по умолчанию — 500 мс. -
checkpointLocation: расположение, where система записывает все сведения о контрольной точке. Если значение не указано, система автоматически создает временное расположение контрольной точки в DBFS. Чтобы поток продолжал обрабатывать данные из where с того места, на котором остановился, необходимо указать расположение контрольной точки. Для Databricks в рабочей среде рекомендуется всегда указывать параметрcheckpointLocation.
Python
streaming_df = spark.readStream.format("rate").load()
display(streaming_df.groupBy().count(), processingTime = "5 seconds", checkpointLocation = "dbfs:/<checkpoint-path>")
Scala
import org.apache.spark.sql.streaming.Trigger
val streaming_df = spark.readStream.format("rate").load()
display(streaming_df.groupBy().count(), trigger = Trigger.ProcessingTime("5 seconds"), checkpointLocation = "dbfs:/<checkpoint-path>")
Дополнительные сведения об этих parametersсм. в разделе Начало потоковых запросов.
Функция displayHTML
Записные книжки Azure Databricks для языков программирования Python, R и Scala поддерживают графику HTML с использованием функции displayHTML, которая принимает любой код HTML, CSS или JavaScript. Эта функция поддерживает интерактивную графику через библиотеки JavaScript, например D3.
Примеры использования displayHTML см. здесь:
Примечание.
Контейнер iFrame displayHTML обслуживается из домена databricksusercontent.com, а песочница iFrame включает атрибут allow-same-origin. Адрес databricksusercontent.com должен быть доступным из браузера. Если оно в настоящее время заблокировано вашей корпоративной сетью, оно должно быть добавлено в список разрешенных list.
Изображения
Columns, содержащий данные изображения, отображается как интерактивный HTML. Azure Databricks пытается отобразить эскизы изображений для DataFramecolumns, которые соответствуют Spark ImageSchema.
Визуализация эскизов работает для всех изображений, которые успешно считываются с помощью spark.read.format('image') функции. Для изображений values, созданных с помощью других средств, Azure Databricks поддерживает отрисовку 1, 3 или 4 каналов (where каждый канал состоит из одного байта), с следующими ограничениями:
-
Одноканальные изображения: поле
modeдолжно иметь значение 0. Поляheight,widthиnChannelsдолжны точно описывать двоичные данные изображения в полеdata. -
Трехканальные изображения: поле
modeдолжно иметь значение 16. Поляheight,widthиnChannelsдолжны точно описывать двоичные данные изображения в полеdata. Полеdataдолжно содержать пиксельные данные в трехбайтовых блоках, с последовательностью каналов(blue, green, red)для каждого пикселя. -
Четырехканальные изображения: поле
modeдолжно иметь значение 24. Поляheight,widthиnChannelsдолжны точно описывать двоичные данные изображения в полеdata. Полеdataдолжно содержать пиксельные данные в четырехбайтовых блоках, с последовательностью каналов(blue, green, red, alpha)для каждого пикселя.
Пример
Предположим, у вас есть папка с несколькими изображениями:

Если вы считываете изображения в кадр данных, а затем отображаете кадр данных, Azure Databricks отрисовывает эскизы изображений:
image_df = spark.read.format("image").load(sample_img_dir)
display(image_df)

Визуализации в Python
В этом разделе рассматриваются следующие вопросы.
Seaborn
Вы также можете использовать другие библиотеки Python для generate графиков. Databricks Runtime включает библиотеку визуализаций seaborn. Чтобы создать график seaborn, импортируйте эту библиотеку, создайте график и передайте его в функцию display.
import seaborn as sns
sns.set(style="white")
df = sns.load_dataset("iris")
g = sns.PairGrid(df, diag_sharey=False)
g.map_lower(sns.kdeplot)
g.map_diag(sns.kdeplot, lw=3)
g.map_upper(sns.regplot)
display(g.fig)
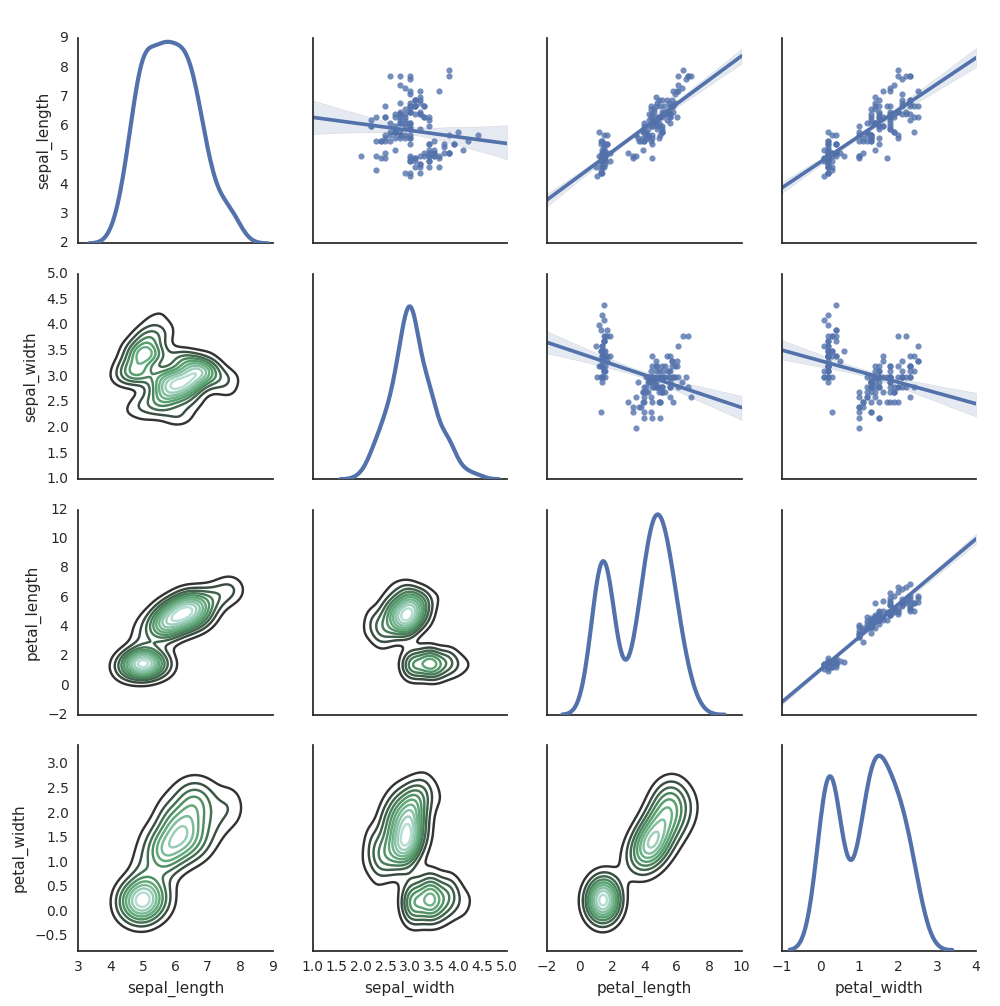
Другие библиотеки Python
Визуализации в R
Чтобы отобразить данные в виде графика в R, используйте функцию display следующим образом:
library(SparkR)
diamonds_df <- read.df("/databricks-datasets/Rdatasets/data-001/csv/ggplot2/diamonds.csv", source = "csv", header="true", inferSchema = "true")
display(arrange(agg(groupBy(diamonds_df, "color"), "price" = "avg"), "color"))
Можно применить стандартную функцию plot языка R.
fit <- lm(Petal.Length ~., data = iris)
layout(matrix(c(1,2,3,4),2,2)) # optional 4 graphs/page
plot(fit)
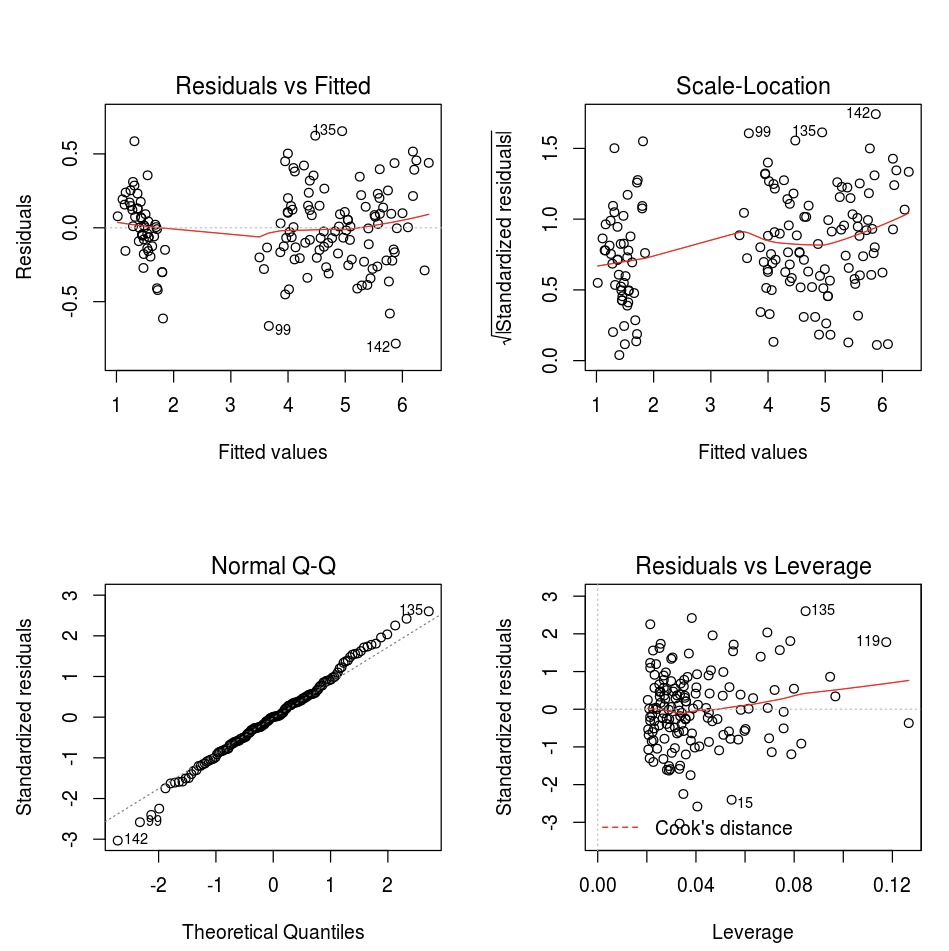
Можно также использовать любой пакет визуализации для R. Записная книжка R сохранит полученный график в виде .png и отобразит его как встроенный график.
В этом разделе рассматриваются следующие вопросы.
Решетка
Пакет Lattice поддерживает графы trellis, которые отображают переменные или связи между переменными с условной зависимостью от одной или нескольких переменных.
library(lattice)
xyplot(price ~ carat | cut, diamonds, scales = list(log = TRUE), type = c("p", "g", "smooth"), ylab = "Log price")
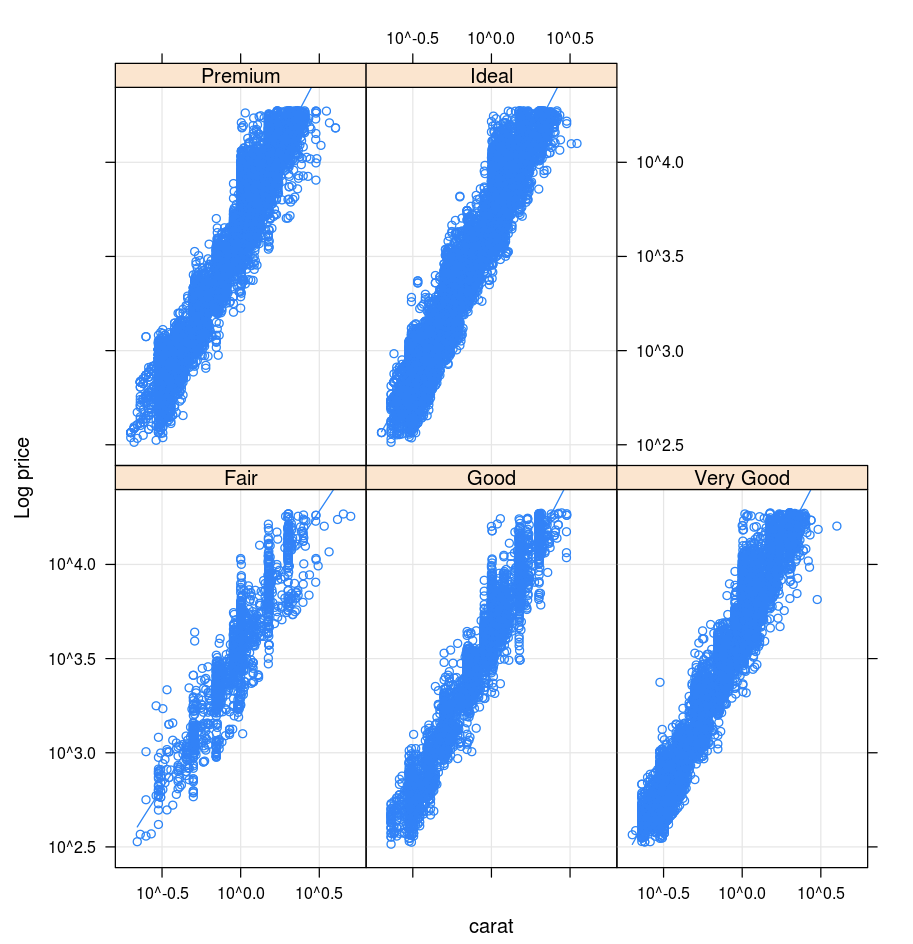
DandEFA
Пакет DandEFA поддерживает графики dandelion.
install.packages("DandEFA", repos = "https://cran.us.r-project.org")
library(DandEFA)
data(timss2011)
timss2011 <- na.omit(timss2011)
dandpal <- rev(rainbow(100, start = 0, end = 0.2))
facl <- factload(timss2011,nfac=5,method="prax",cormeth="spearman")
dandelion(facl,bound=0,mcex=c(1,1.2),palet=dandpal)
facl <- factload(timss2011,nfac=8,method="mle",cormeth="pearson")
dandelion(facl,bound=0,mcex=c(1,1.2),palet=dandpal)
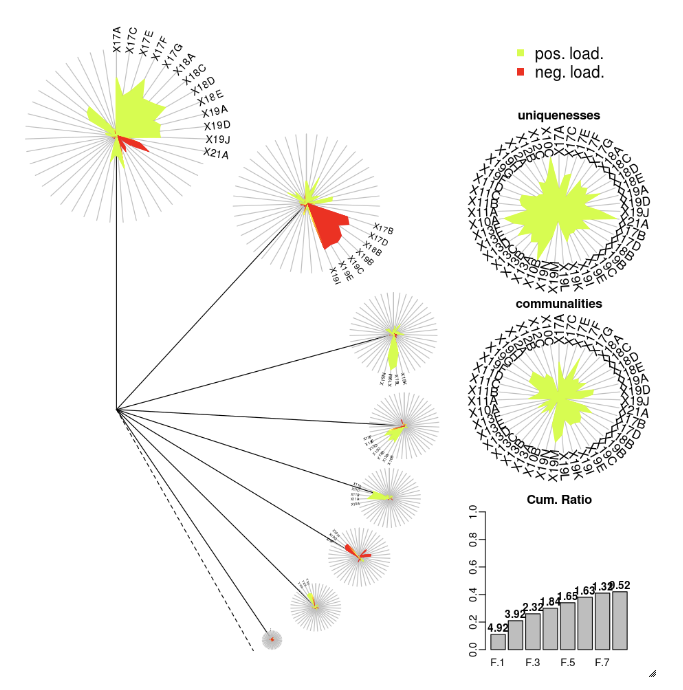
Plotly
Пакет Plotly R использует htmlwidgets для R. Инструкции по установке и записная книжка см. в htmlwidgets.
Другие библиотеки R
Визуализации в Scala
Чтобы отобразить данные в виде графика в Scala, используйте функцию display следующим образом:
val diamonds_df = spark.read.format("csv").option("header","true").option("inferSchema","true").load("/databricks-datasets/Rdatasets/data-001/csv/ggplot2/diamonds.csv")
display(diamonds_df.groupBy("color").avg("price").orderBy("color"))
Записные книжки с подробным обзором для Python и Scala
Подробный обзор визуализаций на Python можно найти в этой записной книжке:
Подробный обзор визуализаций на Scala можно найти в этой записной книжке: