Потоковые чтение и запись для Delta таблиц
Delta Lake надежно интегрирована со Структурированной потоковой передачей Spark с помощью readStream и writeStream. Delta Lake преодолевает многие ограничения, которые обычно связаны с системами потоковой передачи и файлами, включая:
- Объединение небольших файлов, созданных при низкой задержке приема.
- Обслуживание обработки "ровно один раз" с несколькими потоками (или параллельными пакетными заданиями).
- Эффективное обнаружение новых файлов при использовании файлов в качестве источника для потока.
Примечание.
В этой статье описывается использование таблиц Delta Lake в качестве источников потоковой передачи и приемников. Сведения о загрузке данных с помощью потоковых таблиц в Databricks SQL см. в статье Загрузка данных с помощью таблиц потоковой передачи в Databricks SQL.
Сведения о потоковых статических соединениях с Delta Lake см. в разделе "Поток-статические соединения".
Delta table как источник
Структурированная потоковая передача постепенно считывает таблицы Delta. Хотя потоковый запрос активен для таблицы Delta, новые записи обрабатываются идемпотентно, так как новые версии таблиц фиксируются в исходной таблице.
В следующих примерах кода показано, как настроить потоковое чтение с помощью имени таблицы или пути к файлу.
Python
spark.readStream.table("table_name")
spark.readStream.load("/path/to/table")
Scala
spark.readStream.table("table_name")
spark.readStream.load("/path/to/table")
Внимание
Если схема таблицы Delta изменяется после начала потокового чтения в таблице, запрос завершается сбоем. Для большинства изменений схемы можно перезапустить поток, чтобы устранить несоответствие схемы и продолжить обработку.
В Databricks Runtime 12.2 LTS и более ранних версиях нельзя осуществлять потоковую передачу данных из таблицы Delta с включенным сопоставлением столбцов, которая подверглась неаддитивной эволюции схемы, например, переименованию или удалению столбцов. Дополнительные сведения см. в разделе Потоковая передача с помощью сопоставления столбцов и изменений схемы.
Ограничение скорости ввода
Для управления микропакетами доступны следующие параметры:
-
maxFilesPerTrigger: Сколько новых файлов будет учитываться в каждом микропакете. Значение по умолчанию — 1000. -
maxBytesPerTrigger: Сколько данных обрабатывается в каждом микропакете. Этот параметр задает "мягкое ограничение", то есть пакетная обработка приблизительно такого объема данных и может обрабатывать больше установленного предела, чтобы позволить потоковому запросу продвигаться вперед, если наименьший входной блок превышает это ограничение. Это значение не задано по умолчанию.
Если вы используете maxBytesPerTrigger вместе с maxFilesPerTrigger, микропакетный процесс обрабатывает данные до тех пор, пока не будет достигнут предел maxFilesPerTrigger или maxBytesPerTrigger.
Примечание.
В случаях, когда транзакции исходной таблицы очищаются из-за logRetentionDurationконфигурации, а потоковый запрос пытается обработать эти версии, по умолчанию запрос не может избежать потери данных. Параметр failOnDataLoss можно установить в false так, чтобы игнорировать потерянные данные и продолжать обработку.
Потоковая передача потока отслеживания измененных данных Delta Lake (CDC)
Delta Lake поток изменений данных фиксирует изменения в таблице Delta, включая обновления и удаления. При включении можно выполнять потоковую передачу данных из потока изменений и записывать логику для обработки вставок, обновлений и удаления в последующие таблицы. Хотя данные, выводимые потоками данных об изменениях, немного отличаются от данных описываемой таблицы Delta, это обеспечивает решение для распространения инкрементальных изменений в зависимых таблицах в медальонной архитектуре .
Внимание
В Databricks Runtime 12.2 LTS и ниже вы не можете начинать поток из канала измененных данных для таблицы Delta с включенным сопоставлением столбцов, которая подверглась неаддитивной эволюции схемы, например, переименованию или удалению столбцов. См. потоковая передача с сопоставлением столбцов и изменениями схемы.
Игнорировать обновления и удаления
Структурированная потоковая передача не обрабатывает входные данные, которые не являются добавлением и вызывает исключение, если какие-либо изменения происходят в таблице, используемой в качестве источника. Существуют две основные стратегии для работы с изменениями, которые не могут быть автоматически распространены по нисходящей:
- Вы можете удалить выходные данные и контрольную точку и перезапустить поток с самого начала.
- Можно задать один из следующих двух вариантов:
-
ignoreDeletes: игнорируйте транзакции, которые удаляют данные по границам секций. -
skipChangeCommits: игнорировать транзакции, которые удаляют или изменяют существующие записи.skipChangeCommitsвключаетignoreDeletes.
-
Примечание.
В Databricks Runtime 12.2 LTS и более поздних skipChangeCommits версиях не рекомендуется использовать предыдущий параметр ignoreChanges. В Databricks Runtime 11.3 LTS и более низкий ignoreChanges вариант поддерживается.
Семантика параметраignoreChanges существенно отличается от семантики параметра skipChangeCommits. При активированном ignoreChanges перезаписанные файлы данных в исходной таблице повторно отправляются после операций изменения данных, таких как UPDATE, MERGE INTO, DELETE (внутри разделов) или OVERWRITE. Неизменяемые строки часто создаются вместе с новыми строками, поэтому нижестоящие потребители должны иметь возможность обрабатывать дубликаты. Удаления не распространяются по нисходящей.
ignoreChanges включает ignoreDeletes.
skipChangeCommits полностью игнорирует операции изменения файлов. Файлы данных, которые переписываются в исходной таблице из-за операции изменения данных, например UPDATE, MERGE INTO, DELETEи OVERWRITE, полностью игнорируются. Чтобы отразить изменения в вышестоящих исходных таблицах, необходимо реализовать отдельную логику для распространения этих изменений.
Рабочие нагрузки, настроенные с продолжением работы с ignoreChanges известной семантикой, но Databricks рекомендует использовать skipChangeCommits для всех новых рабочих нагрузок. Перенос рабочих нагрузок, использующихся ignoreChanges для skipChangeCommits выполнения рефакторинга, требует логики рефакторинга.
Пример
Например, предположим, что у вас есть таблица user_events с date, user_emailи столбцами action, секционированных по date. Вы выгружаете данные из таблицы user_events, и данные должны быть удалены из нее в соответствии с GDPR.
При удалении по границам секции (то есть WHERE находится в столбце секционирования), файлы уже сегментируются по значению, поэтому удаление просто удаляет эти файлы из метаданных. При удалении всей секции данных можно использовать следующее:
spark.readStream
.option("ignoreDeletes", "true")
.table("user_events")
При удалении данных в нескольких разделах (в этом примере фильтрация по user_email) используйте следующий синтаксис:
spark.readStream
.option("skipChangeCommits", "true")
.table("user_events")
При обновлении user_email с помощью инструкции UPDATE файл, содержащий user_email в вопросе, перезаписывается. Используйте skipChangeCommits для пропуска измененных файлов данных.
Указать начальное расположение
Для указания начальной точки источника потоковой передачи Delta Lake можно использовать следующие параметры, не обрабатывая всю таблицу.
startingVersion: Версия Delta Lake, с которой начинается запуск. Databricks рекомендует не использовать этот параметр для большинства рабочих нагрузок. Если он не задан, поток начинается с последней доступной версии, включая полный моментальный снимок таблицы на тот момент.Если определено, поток считывает все изменения для таблицы Delta, начиная с указанной версии (включительно). Если указанная версия больше недоступна, поток не запускается. Вы можете получить коммиты из столбца
versionвыходных данных команды DESCRIBE HISTORY.Чтобы вернуть только последние изменения, укажите
latest.startingTimestamp: Метка времени для запуска. Все изменения таблицы, зафиксированные в метке времени или после (включительно), считываются потоковым средством чтения. Если указанная метка времени предшествует всем коммитам таблицы, потоковое чтение начинается с самой ранней доступной метки времени. Одно из двух значений:- Строка метки времени. Например,
"2019-01-01T00:00:00.000Z". - Строка даты. Например,
"2019-01-01".
- Строка метки времени. Например,
Одновременно нельзя задать оба параметра. Они вступают в силу только при запуске нового потокового запроса. Если потоковый запрос запущен и в его контрольной точке записан ход выполнения, эти параметры игнорируются.
Внимание
Хотя вы можете запустить источник потоковой передачи из указанной версии или метки времени, схема источника потоковой передачи всегда является последней схемой таблицы Delta. Необходимо убедиться, что после указанной версии или метки времени в таблице Delta не произошло изменения несовместимой схемы. В противном случае источник потоковой передачи может возвращать неверные результаты при чтении данных с неправильной схемой.
Пример
Например, предположим, что у вас есть таблица user_events. Если вы хотите считать изменения начиная с версии 5, используйте:
spark.readStream
.option("startingVersion", "5")
.table("user_events")
Если вы хотите считать изменения начиная с 18 октября 2018 г., используйте:
spark.readStream
.option("startingTimestamp", "2018-10-18")
.table("user_events")
начальный моментальный снимок процесса без удаления данных
Эта функция доступна в Databricks Runtime 11.3 LTS и выше.
При использовании таблицы Delta в качестве источника потока запрос сначала обрабатывает все данные, присутствующих в таблице. Таблица Delta в этой версии называется начальным снимком. По умолчанию файлы данных таблицы Delta обрабатываются на основе последнего изменения файла. Однако время последнего изменения необязательно соответствует временной последовательности событий.
В состояниесохраняющем потоковом запросе с определенной точкой отсечки обработка файлов на основе времени их изменения может привести к обработке записей в неправильном порядке. Это может привести к тому, что записи будут считаться опоздавшими по водяному знаку.
Чтобы избежать проблемы с удалением данных, включите следующий параметр:
- withEventTimeOrder: следует ли обрабатывать исходный моментальный снимок в порядке времени события.
Если включен временной порядок события, диапазон времени исходного моментального снимка делится на периоды времени. Каждый микропакет обрабатывает период путем фильтрации данных в пределах диапазона времени. Параметры конфигурации maxFilesPerTrigger и maxBytesPerTrigger по-прежнему можно использовать для управления размером микропакета, но только приблизительно, что связано с принципом обработки.
На рисунке ниже показан этот процесс:
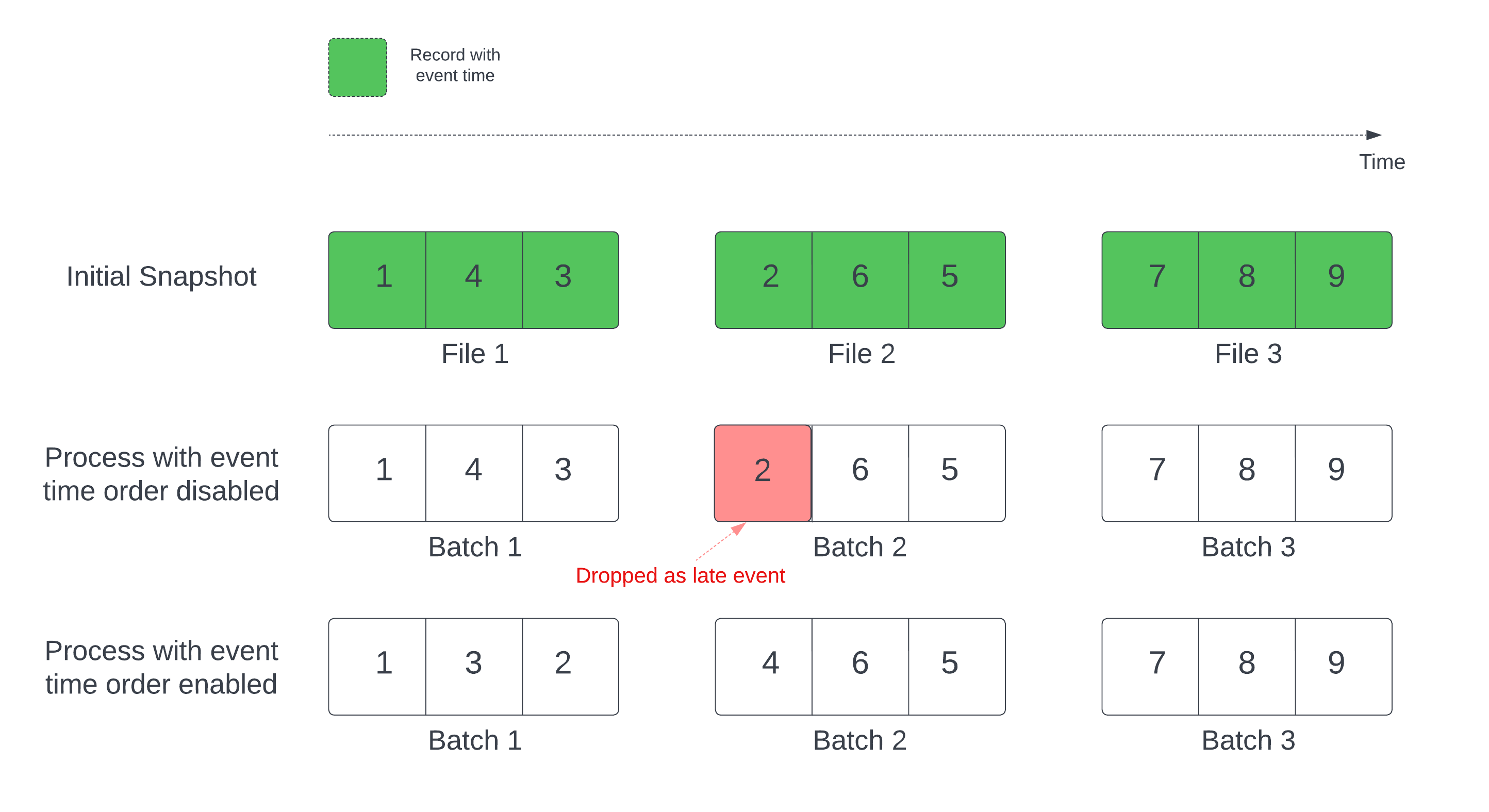
Важная информация об этой функции:
- Проблема с удалением данных возникает только в том случае, если исходный разностный моментальный снимок запроса потоковой передачи с отслеживанием состояния обрабатывается в порядке по умолчанию.
- После запуска запроса потока во время обработки исходного моментального снимка изменить
withEventTimeOrderневозможно. Чтобы запустить повторно с измененнымwithEventTimeOrder, необходимо удалить контрольную точку. - Если выполняется потоковый запрос с включенным параметром EventTimeOrder, вы не сможете перейти на более раннюю версию DBR, которая не поддерживает эту функцию до завершения обработки исходного моментального снимка. Если необходимо перейти на более раннюю версию, можно дождаться завершения обработки исходного моментального снимка или удалить контрольную точку и перезапустить запрос.
- Эта функция не поддерживается в следующих редких сценариях:
- Столбец времени события — это сгенерированный столбец, и между источником Delta и водяным знаком существуют преобразования, не связанные с проекцией.
- В запросе потока имеется подложка с несколькими источниками delta.
- Если включен временной порядок событий, производительность обработки исходных разностных моментальных снимков может быть ниже.
- Каждый микропакет сканирует исходный моментальный снимок, чтобы отфильтровать данные в пределах соответствующего диапазона времени события. Чтобы ускорить выполнение фильтрации, рекомендуется использовать столбец источника Delta в качестве времени события, чтобы можно было применить пропуск данных (см. Пропуск данных для Delta Lake, где это применимо). Кроме того, секционирование таблиц по столбцу времени события может ускорить обработку. С помощью пользовательского интерфейса Spark можно узнать, сколько сканируется разностных файлов для определенного микропакета.
Пример
Предположим, что у вас есть таблица user_events с столбцом event_time. Запрос потоковой передачи — это агрегатный запрос. Если вы хотите убедиться, что данные не будут удаляться во время обработки исходных моментальных снимков, можно использовать следующее:
spark.readStream
.option("withEventTimeOrder", "true")
.table("user_events")
.withWatermark("event_time", "10 seconds")
Примечание.
Вы также можете включить эту конфигурацию Spark в кластере, которая будет применяться ко всем потоковым запросам: spark.databricks.delta.withEventTimeOrder.enabled true
разностная таблица в качестве приемника
Вы также можете записывать данные в Delta table с помощью Structured Streaming. Журнал транзакций позволяет Delta Lake гарантировать точно однократную обработку, даже если в таблице одновременно выполняются другие потоки или пакетные запросы.
Примечание.
Функция Delta Lake VACUUM удаляет все файлы, не управляемые Delta Lake, но пропускает все каталоги, имена которых начинаются с _. Вы можете безопасно хранить контрольные точки вместе с другими данными и метаданными для таблицы Delta, используя структуру каталогов, например <table-name>/_checkpoints.
Метрики
Количество байтов и файлов, которым еще предстоит пройти обработку, можно узнать в процессе потоковой обработки, с помощью метрик numBytesOutstanding и numFilesOutstanding. К дополнительным метрикам относятся:
-
numNewListedFiles: количество файлов Delta Lake, перечисленных для вычисления невыполненной работы для этого пакета.-
backlogEndOffset: версия таблицы, используемая для вычисления невыполненной работы.
-
Если вы выполняете поток в записной книжке, эти метрики можно просмотреть на вкладке "Необработанные данные " на панели мониторинга хода выполнения потокового запроса:
{
"sources": [
{
"description": "DeltaSource[file:/path/to/source]",
"metrics": {
"numBytesOutstanding": "3456",
"numFilesOutstanding": "8"
}
}
]
}
Режим добавления
По умолчанию потоки выполняются в режиме добавления, который добавляет новые записи в таблицу.
При потоковой передаче в таблицы используйте метод toTable, как показано в следующем примере:
Python
(events.writeStream
.outputMode("append")
.option("checkpointLocation", "/tmp/delta/events/_checkpoints/")
.toTable("events")
)
Scala
events.writeStream
.outputMode("append")
.option("checkpointLocation", "/tmp/delta/events/_checkpoints/")
.toTable("events")
Полный режим
Вы также можете использовать структурированную потоковую передачу для замены всей таблицы каждым пакетом. Один из примеров использования — вычисление сводки с помощью статистической обработки:
Python
(spark.readStream
.table("events")
.groupBy("customerId")
.count()
.writeStream
.outputMode("complete")
.option("checkpointLocation", "/tmp/delta/eventsByCustomer/_checkpoints/")
.toTable("events_by_customer")
)
Scala
spark.readStream
.table("events")
.groupBy("customerId")
.count()
.writeStream
.outputMode("complete")
.option("checkpointLocation", "/tmp/delta/eventsByCustomer/_checkpoints/")
.toTable("events_by_customer")
В предыдущем примере постоянно обновляется таблица, содержащая совокупное количество событий по клиентам.
Для приложений с менее строгими дополнительными требованиями к задержке можно сэкономить вычислительные ресурсы с одноразовыми триггерами. Используйте их для обновления таблиц сводки агрегирования по заданному расписанию, обрабатывая только новые данные, поступающие с момента последнего обновления.
Upsert из потоковых запросов с помощью foreachBatch
Вы можете использовать сочетание merge и foreachBatch для записи сложных обновлений и вставок из потокового запроса в Delta таблицу. См. раздел Использование foreachBatch для записи в произвольные приемники данных.
Этот шаблон содержит множество приложений, включая следующее:
- Записывайте потоковые агрегаты в режиме Обновления: Это гораздо эффективнее, чем Полный режим.
-
Запись потока изменений базы данных в таблицу Delta: запрос на слияние для записи данных об изменениях можно использовать в
foreachBatchдля непрерывного применения потока изменений к таблице Delta. -
запись потока данных в разностную таблицу с дедупликацией: запрос слияния только для вставки для дедупликации можно использовать в
foreachBatchдля непрерывной записи данных (с дубликатами) в разностную таблицу с автоматической дедупликацией.
Примечание.
- Убедитесь, что инструкция
mergeвforeachBatchидемпотентная, так как перезагрузка потокового запроса может применить операцию к тому же пакету данных несколько раз. - Если
mergeиспользуется вforeachBatch, скорость входных данных для запроса потоковой передачи (выдаваемых черезStreamingQueryProgressи видимых в диаграмме скорости записной книжки) может быть кратна фактической скорости, с которой данные создаются в источнике. Это связано с тем, чтоmergeсчитывает входные данные несколько раз, что приводит к умножению метрик входных данных. Если это узкое место, можно кэшировать пакетный DataFrame доmergeи кэшировать его послеmerge.
В следующем примере показано, как можно использовать SQL для foreachBatch выполнения этой задачи:
Scala
// Function to upsert microBatchOutputDF into Delta table using merge
def upsertToDelta(microBatchOutputDF: DataFrame, batchId: Long) {
// Set the dataframe to view name
microBatchOutputDF.createOrReplaceTempView("updates")
// Use the view name to apply MERGE
// NOTE: You have to use the SparkSession that has been used to define the `updates` dataframe
microBatchOutputDF.sparkSession.sql(s"""
MERGE INTO aggregates t
USING updates s
ON s.key = t.key
WHEN MATCHED THEN UPDATE SET *
WHEN NOT MATCHED THEN INSERT *
""")
}
// Write the output of a streaming aggregation query into Delta table
streamingAggregatesDF.writeStream
.foreachBatch(upsertToDelta _)
.outputMode("update")
.start()
Python
# Function to upsert microBatchOutputDF into Delta table using merge
def upsertToDelta(microBatchOutputDF, batchId):
# Set the dataframe to view name
microBatchOutputDF.createOrReplaceTempView("updates")
# Use the view name to apply MERGE
# NOTE: You have to use the SparkSession that has been used to define the `updates` dataframe
# In Databricks Runtime 10.5 and below, you must use the following:
# microBatchOutputDF._jdf.sparkSession().sql("""
microBatchOutputDF.sparkSession.sql("""
MERGE INTO aggregates t
USING updates s
ON s.key = t.key
WHEN MATCHED THEN UPDATE SET *
WHEN NOT MATCHED THEN INSERT *
""")
# Write the output of a streaming aggregation query into Delta table
(streamingAggregatesDF.writeStream
.foreachBatch(upsertToDelta)
.outputMode("update")
.start()
)
Вы также можете использовать API Delta Lake для выполнения потоковых upserts, как показано в следующем примере:
Scala
import io.delta.tables.*
val deltaTable = DeltaTable.forName(spark, "table_name")
// Function to upsert microBatchOutputDF into Delta table using merge
def upsertToDelta(microBatchOutputDF: DataFrame, batchId: Long) {
deltaTable.as("t")
.merge(
microBatchOutputDF.as("s"),
"s.key = t.key")
.whenMatched().updateAll()
.whenNotMatched().insertAll()
.execute()
}
// Write the output of a streaming aggregation query into Delta table
streamingAggregatesDF.writeStream
.foreachBatch(upsertToDelta _)
.outputMode("update")
.start()
Python
from delta.tables import *
deltaTable = DeltaTable.forName(spark, "table_name")
# Function to upsert microBatchOutputDF into Delta table using merge
def upsertToDelta(microBatchOutputDF, batchId):
(deltaTable.alias("t").merge(
microBatchOutputDF.alias("s"),
"s.key = t.key")
.whenMatchedUpdateAll()
.whenNotMatchedInsertAll()
.execute()
)
# Write the output of a streaming aggregation query into Delta table
(streamingAggregatesDF.writeStream
.foreachBatch(upsertToDelta)
.outputMode("update")
.start()
)
Идемпотентная таблица записывается в foreachBatch
Примечание.
Databricks рекомендует настроить отдельные потоковые операции записи для каждого приемника, который нужно обновить, вместо использования foreachBatch. Это связано с тем, что операции записи в несколько таблиц сериализуются при использовании foreachBatch, что снижает параллелизацию и увеличивает общую задержку.
Таблицы Delta поддерживают следующие параметры DataFrameWriter, чтобы сделать запись в несколько таблиц в foreachBatch идемпотентной.
-
txnAppId: уникальная строка, которую можно передать для каждой записи dataFrame. Например, идентификатор StreamingQuery можно использовать какtxnAppId. -
txnVersion: Монотонно возрастающее количество, действующее как версия транзакции.
В Delta Lake используется сочетание txnAppId и txnVersion для обнаружения повторяющихся записей и их пропуска.
Если пакетная запись прерывается сбоем, повторное выполнение пакета использует одно и то же приложение и идентификатор пакетной службы, чтобы помочь среде выполнения правильно определить повторяющиеся записи и игнорировать их. Идентификатор приложения (txnAppId) может быть любой уникальной строкой, созданной пользователем, и не обязательно должен быть связан с идентификатором потока. См. раздел Использование foreachBatch для записи в произвольные приемники данных.
Предупреждение
Если удалить контрольную точку потоковой передачи и перезапустить запрос с помощью новой контрольной точки, необходимо указать другой txnAppId. Новые контрольные точки начинаются с пакетного идентификатора 0. Delta Lake использует идентификатор пакета и txnAppId в качестве уникального ключа и пропускает пакеты с уже видимыми значениями.
В следующем примере кода показан этот шаблон:
Python
app_id = ... # A unique string that is used as an application ID.
def writeToDeltaLakeTableIdempotent(batch_df, batch_id):
batch_df.write.format(...).option("txnVersion", batch_id).option("txnAppId", app_id).save(...) # location 1
batch_df.write.format(...).option("txnVersion", batch_id).option("txnAppId", app_id).save(...) # location 2
streamingDF.writeStream.foreachBatch(writeToDeltaLakeTableIdempotent).start()
Scala
val appId = ... // A unique string that is used as an application ID.
streamingDF.writeStream.foreachBatch { (batchDF: DataFrame, batchId: Long) =>
batchDF.write.format(...).option("txnVersion", batchId).option("txnAppId", appId).save(...) // location 1
batchDF.write.format(...).option("txnVersion", batchId).option("txnAppId", appId).save(...) // location 2
}