Правила для типов данных SQL
Область применения:![]() Databricks SQL
Databricks SQL ![]() Databricks Runtime
Databricks Runtime
Azure Databricks использует несколько правил для устранения конфликтов между типами данных:
- Повышение уровня позволяет безопасно перейти к боле широкому типу.
- Неявное нисходящее приведение позволяет перейти к более узкому типу. Противоположность продвижению.
- Неявное перекрестное приведение преобразует тип в тип другого семейства.
Также можно выполнить явное приведение между различными типами:
- Функция cast выполняет приведение между большинством типов и возвращает ошибки, если это невозможно.
- Функция try_cast работает аналогично функции cast, но возвращает значение NULL при передаче недопустимых значений.
- Другие встроенные функции выполняют приведение между типами с помощью указанных директив форматирования.
Преобразование типа
Повышение типа — это процесс приведения типа к другому типу того же семейства, который содержит все возможные значения исходного типа.
Таким образом, повышение типа является безопасной операцией. Например, TINYINT использует диапазон -128–127. Все возможные значения можно безопасно повысить до уровня INTEGER.
Список приоритета типов
Список приоритета типов определяет, можно ли неявно повысить уровень значений конкретного типа данных до другого типа данных.
| Тип данных | Список предшествования (от узкого к широкому) |
|---|---|
| TINYINT | TINYINT -> SMALLINT -> INT -> BIGINT -> DECIMAL -> FLOAT (1) -> DOUBLE |
| SMALLINT | SMALLINT -> INT -> BIGINT -> DECIMAL -> FLOAT (1) -> DOUBLE |
| INT | INT -> BIGINT -> DECIMAL -> FLOAT (1) -> DOUBLE |
| BIGINT | BIGINT -> DECIMAL -> FLOAT (1) -> DOUBLE |
| DECIMAL | ДЕСЯТИЧНОЕ -> ПЛАВАЮЩАЯ ТОЧКА (1) -> ДВОЙНОЕ |
| FLOAT | FLOAT (1) -> DOUBLE |
| DOUBLE | ДВОЙНОЙ |
| DATE | ДАТА -> МЕТКА ВРЕМЕНИ |
| TIMESTAMP | TIMESTAMP |
| ARRAY | ARRAY (2) |
| BINARY | ДВОИЧНЫЙ |
| BOOLEAN | BOOLEAN |
| INTERVAL | ИНТЕРВАЛ |
| MAP | КАРТА (2) |
| STRING | STRING |
| СТРУКТУРА | СТРУКТУРА (2) |
| ВАРИАНТ | ВАРИАНТ |
| ОБЪЕКТ | OBJECT (3) |
(1) Для разрешения наименее распространенных типовFLOAT пропускается, чтобы избежать потери точности.
(2) Для сложного типа правило приоритета применяется рекурсивно к элементам его компонентов.
(3)OBJECT существует только в пределах VARIANT.
Строки и NULL
Специальные правила применяются к STRING и нетипизированным значениям NULL:
-
NULLможно преобразовать в любой другой тип. -
STRINGможно повысить до уровнейBIGINT,BINARY,BOOLEAN,DATE,DOUBLE,INTERVALиTIMESTAMP. Если фактическое строковое значение не может быть приведено к наименее распространённому типу, Azure Databricks вызовет ошибку во время выполнения. При повышении до уровняINTERVALстроковое значение должно совпадать с единицами интервалов.
Граф приоритета типов
Это графическое изображение иерархии приоритетов, объединяющее список приоритета типов и правила для строк и значений NULL.
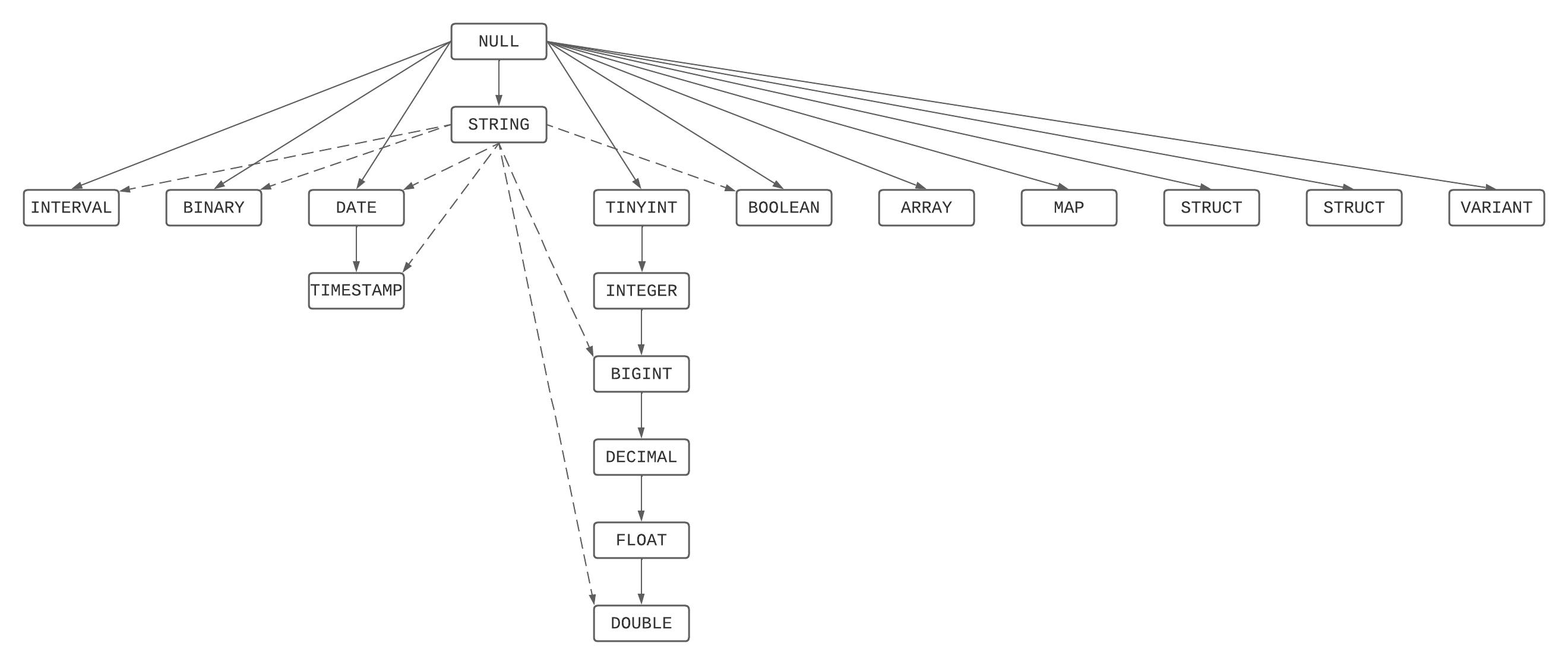
Разрешение наименьшего общего типа
Наименьший общий тип из набора типов является самым узким типом, который доступен всем элементам набора типов из графа приоритета типов.
Разрешение наименее общего типа используется для:
- Чтобы решить, можно ли вызвать функцию, ожидающую параметр данного типа, с помощью аргумента более узкого типа.
- Чтобы определить тип аргумента для функции, ожидающей общий тип аргумента для нескольких параметров, таких как coalesce, in, least или greatest.
- Определите типы операндов для таких операторов, как арифметические операции или сравнения.
- Определите производный тип результата для таких выражений, как выражение CASE.
- Выведите типы элементов, ключей или значений для конструкторов массива и отображения.
- Определите тип результата операторов объединения множеств UNION, INTERSECT или EXCEPT.
Если наименьший общий тип разрешается в FLOAT, то применяются специальные правила. Если любой из участвующих типов представляет собой точный числовой тип (TINYINT, SMALLINT, INTEGER, BIGINT или DECIMAL), для предотвращения возможной потери цифр за наименьший общий тип берется DOUBLE.
Если наименее распространенный тип является STRING, сопоставление вычисляется по правилам приоритета сортировки .
Неявное нисходящее приведение типа и кросскастинг
Azure Databricks использует эти формы неявного приведения только при вызове функций и операторов, и только в тех случаях, когда можно однозначно определить намерение.
Неявное нисходящее преобразование
Неявное нисходящее приведение автоматически является приведением более широкого типа к более узкому, не требуя от вас указания приведения явно. Нисходящее приведение типа удобно, но оно связано с риском непредвиденных ошибок выполнения, если реальное значение не может быть представлено в более узком типе.
Нисходящее приведение применяет список приоритетов типов в обратном порядке.
Неявный кросскастинг
Неявный кросскастинг приводит значение из одного семейства типов к типу из другого семейства, не требуя явно указывать приведение.
Azure Databricks поддерживает неявную перекрестную рассылку из:
- Любого простого типа, кроме
BINARY, кSTRING. -
STRINGк любому простому типу.
- Любого простого типа, кроме
Приведение при вызове функции
При наличии разрешенной функции или оператора применяются следующие правила (в порядке их перечисления) для каждой пары "параметр-аргумент":
Если поддерживаемый тип параметра является частью графа превосходства типа аргумента, Azure Databricks переводит аргумент на этот тип параметра.
В большинстве случаев в описании функции явно указываются поддерживаемые типы или цепочка, например "любой числовой тип".
Например, sin(expr) работает с
DOUBLE, но принимает любое числовое значение.Если ожидаемый тип параметра – это
STRING, и аргумент является простым типом, то Azure Databricks преобразует аргумент в строковый тип параметра.Например, substr(str, start, len) ожидает, что типом
strбудетSTRING. Вместо этого можно передать числовой тип или тип даты-времени.Если тип аргумента является
STRING, а ожидаемый тип параметра является простым типом, Azure Databricks преобразует строковый аргумент в самый широкий поддерживаемый тип параметра.Например, date_add(date, days) ожидает
DATEиINTEGER.При вызове
date_add()с двумяSTRINGAzure Databricks переконвертирует первыйSTRINGвDATE, а второйSTRINGвINTEGER.Если функция ожидает числовый тип, например, как
INTEGERилиDATE, но аргумент является более общим типом, например, таким какDOUBLEилиTIMESTAMP, Azure Databricks неявно понижает тип аргумента до данного типа параметра.Например, date_add(date, days) ожидает
DATEиINTEGER.При вызове
date_add()сTIMESTAMPиBIGINT, Azure Databricks понижает типTIMESTAMPдоDATE, удаляя компонент времени, аBIGINTдоINTEGER.В противном случае Azure Databricks вызывает ошибку.
Примеры
Функция coalesce принимает любой набор типов аргументов, если они имеют наименьший общий тип.
Тип результата определяется наименьшим общим типом всех аргументов.
-- The least common type of TINYINT and BIGINT is BIGINT
> SELECT typeof(coalesce(1Y, 1L, NULL));
BIGINT
-- INTEGER and DATE do not share a precedence chain or support crosscasting in either direction.
> SELECT typeof(coalesce(1, DATE'2020-01-01'));
Error: DATATYPE_MISMATCH.DATA_DIFF_TYPES
-- Both are ARRAYs and the elements have a least common type
> SELECT typeof(coalesce(ARRAY(1Y), ARRAY(1L)))
ARRAY<BIGINT>
-- The least common type of INT and FLOAT is DOUBLE
> SELECT typeof(coalesce(1, 1F))
DOUBLE
> SELECT typeof(coalesce(1L, 1F))
DOUBLE
> SELECT typeof(coalesce(1BD, 1F))
DOUBLE
-- The least common type between an INT and STRING is BIGINT
> SELECT typeof(coalesce(5, '6'));
BIGINT
-- The least common type is a BIGINT, but the value is not BIGINT.
> SELECT coalesce('6.1', 5);
Error: CAST_INVALID_INPUT
-- The least common type between a DECIMAL and a STRING is a DOUBLE
> SELECT typeof(coalesce(1BD, '6'));
DOUBLE
-- Two distinct explicit collations result in an error
> SELECT collation(coalesce('hello' COLLATE UTF8_BINARY,
'world' COLLATE UNICODE));
Error: COLLATION_MISMATCH.EXPLICIT
-- The resulting collation between two distinct implicit collations is indeterminate
> SELECT collation(coalesce(c1, c2))
FROM VALUES('hello' COLLATE UTF8_BINARY,
'world' COLLATE UNICODE) AS T(c1, c2);
NULL
-- The resulting collation between a explicit and an implicit collations is the explicit collation.
> SELECT collation(coalesce(c1 COLLATE UTF8_BINARY, c2))
FROM VALUES('hello',
'world' COLLATE UNICODE) AS T(c1, c2);
UTF8_BINARY
-- The resulting collation between an implicit and the default collation is the implicit collation.
> SELECT collation(coalesce(c1, ‘world’))
FROM VALUES('hello' COLLATE UNICODE) AS T(c1, c2);
UNICODE
-- The resulting collation between the default collation and the indeterminate collation is the default collation.
> SELECT collation(coalesce(coalesce(‘hello’ COLLATE UTF8_BINARY, ‘world’ COLLATE UNICODE), ‘world’));
UTF8_BINARY
Функция substring ожидает аргументы типа STRING для строки и типа INTEGER — для параметров начала и длины.
-- Promotion of TINYINT to INTEGER
> SELECT substring('hello', 1Y, 2);
he
-- No casting
> SELECT substring('hello', 1, 2);
he
-- Casting of a literal string
> SELECT substring('hello', '1', 2);
he
-- Downcasting of a BIGINT to an INT
> SELECT substring('hello', 1L, 2);
he
-- Crosscasting from STRING to INTEGER
> SELECT substring('hello', str, 2)
FROM VALUES(CAST('1' AS STRING)) AS T(str);
he
-- Crosscasting from INTEGER to STRING
> SELECT substring(12345, 2, 2);
23
|| (CONCAT) допускает неявный кросскастинг в строковый тип.
-- A numeric is cast to STRING
> SELECT 'This is a numeric: ' || 5.4E10;
This is a numeric: 5.4E10
-- A date is cast to STRING
> SELECT 'This is a date: ' || DATE'2021-11-30';
This is a date: 2021-11-30
date_add можно вызвать с помощью TIMESTAMP или BIGINT из-за неявного нисходящего приведения типа.
> SELECT date_add(TIMESTAMP'2011-11-30 08:30:00', 5L);
2011-12-05
date_add можно вызвать с помощью STRING из-за неявного кросскастинга.
> SELECT date_add('2011-11-30 08:30:00', '5');
2011-12-05