Региональное аварийное восстановление кластеров Azure Databricks
В этой статье описывается архитектура аварийного восстановления, которую удобно использовать для кластеров Azure Databricks, а также действия, необходимые для реализации этой архитектуры.
Архитектура Azure Databricks
При создании рабочей области Azure Databricks из портал Azure управляемое приложение развертывается как ресурс Azure в подписке в выбранном регионе Azure (например, западная часть США). Это устройство развертывается в виртуальной сети Azure с группой безопасности сети и учетной записью службы хранилища Azure, доступной в вашей подписке. Виртуальная сеть обеспечивает безопасность на уровне периметра для рабочей области Databricks и защищается с помощью группы безопасности сети. В рабочей области вы создаете кластеры Databricks, предоставляя тип виртуальной машины рабочего и драйвера и версию среды выполнения Databricks. Сохраненные данные доступны в учетной записи хранения. После создания кластера можно выполнять задания с помощью записных книжек, REST API или конечных точек ODBC/JDBC, подключив их к конкретному кластеру.
Плоскость управления Databricks контролирует и отслеживает среду рабочей области Databricks. Любая операция управления, например создание кластера, будет инициирована с плоскости управления. Все метаданные, такие как запланированные задания, хранятся в базе данных Azure, а резервные копии базы данных автоматически геореплицируются в парные регионы, где она реализована.
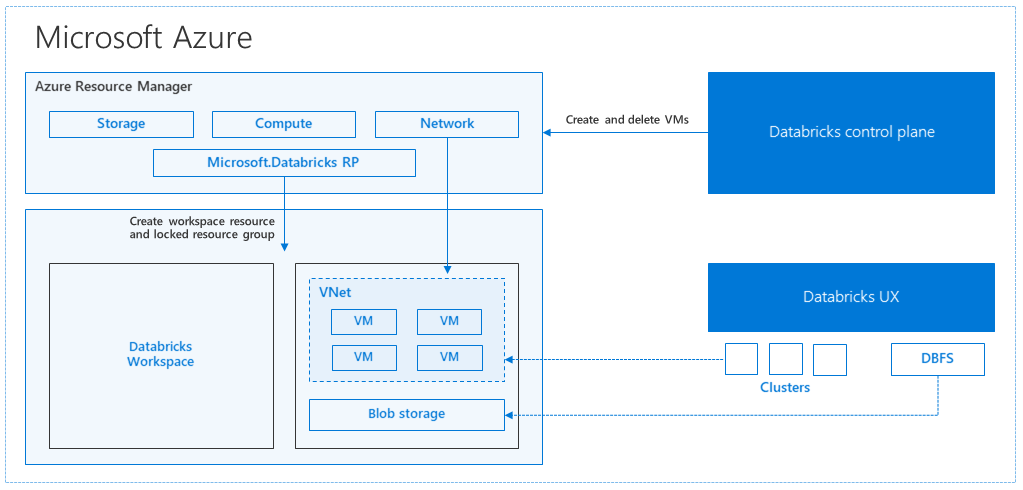
Одно из преимуществ этой архитектуры заключается в том, что пользователи могут подключить Azure Databricks к любому ресурсу хранилища в своей учетной записи. Главное преимущество состоит в том, что вычислительную среду (Azure Databricks) и хранилище можно масштабировать независимо друг от друга.
Как создать топологию регионального аварийного восстановления
В описании предыдущей архитектуры существует ряд компонентов, используемых для конвейера больших данных с помощью Azure Databricks: служба хранилища Azure, Базы данных Azure и других источников данных. Azure Databricks — это вычислительная среда для конвейера больших данных. Это эфемерный характер, т. е. в то время как данные по-прежнему доступны в служба хранилища Azure, вычислительные ресурсы (кластер Azure Databricks) можно завершить, чтобы избежать оплаты за вычислительные ресурсы, если это не требуется. Вычислительная среда (Azure Databricks) и источники хранения должны находиться в одном регионе во избежание высокой задержки при выполнении заданий.
Создавая собственную топологию регионального аварийного восстановления, соблюдайте следующие требования:
Подготавливайте несколько рабочих областей Azure Databricks в отдельных регионах Azure. Например, создайте основную рабочую область Azure Databricks на востоке США. Создайте дополнительную рабочую область Azure Databricks для аварийного восстановления в отдельном регионе, например "Западная часть США". Список парных регионов Azure см. в разделе репликации между регионами. Дополнительные сведения о регионах Azure Databricks см. в разделе "Поддерживаемые регионы".
Используйте геоизбыточное хранилище. По умолчанию данные, связанные Azure Databricks, размещаются в службе хранилища Azure, а результаты выполнения заданий Databricks размещаются в Хранилище BLOB-объектов Azure, чтобы обеспечить их устойчивость и высокую доступность после завершения работы кластера. Хранилище кластера и хранилище заданий размещены в одной зоне доступности. Чтобы обеспечить защиту в случае недоступности региона, для рабочих областей Azure Databricks по умолчанию используется геоизбыточное хранилище. При использовании геоизбыточного хранилища данные реплицируются в связанный регион Azure. Databricks рекомендует оставить по умолчанию геоизбыточное хранилище, но если необходимо использовать локально избыточное хранилище, можно задать
storageAccountSkuNameиStandard_LRSв ARM-шаблоне для рабочей области.После создания дополнительного региона необходимо перенести пользователей, их папки, записные книжки, конфигурацию кластеров и заданий, библиотеки, хранилище и скрипты инициализации, а также заново настроить управление доступом. Дополнительные сведения представлены в следующем разделе.
Региональное бедствие
Чтобы подготовиться к региональным авариям, необходимо явно поддерживать другой набор рабочих областей Azure Databricks во вторичном регионе. См. статью "Аварийное восстановление".
Мы рекомендуемые средства для аварийного восстановления в основном Terraform (для репликации в инфраструктуре) и Delta Deep Clone (для репликации данных).
Подробное описание этапов миграции
Установка интерфейса командной строки Databricks
В примерах в этой статье используется интерфейс командной строки Databricks (CLI), который является простой оболочкой через REST API Azure Databricks.
Перед выполнением любых действий по миграции установите интерфейс командной строки Databricks на локальном компьютере или виртуальной машине. Дополнительные сведения см. в разделе "Установка интерфейса командной строки Databricks".
Примечание.
Скрипты Python, приведенные в этой статье, работают с Python 2.7 и выше.
Настройка двух профилей
Следуя инструкциям в _, настройте два профиля: один для основной рабочей области, а другой — для вторичной рабочей области.
databricks configure --profile primary databricks configure --profile secondaryПредставленные в этой статье блоки кода переключаются между профилями на каждом последующем этапе с помощью соответствующей команды рабочей области. Обязательно замените имена в каждом блоке кода на названия созданных вами профилей.
EXPORT_PROFILE = "primary" IMPORT_PROFILE = "secondary"При необходимости вы можете вручную переключать профили в командной строке:
databricks workspace list --profile primary databricks workspace list --profile secondaryМиграция пользователей Microsoft Entra ID (прежнее название — Azure Active Directory)
Вручную добавьте те же пользователи Идентификатора Microsoft Entra (ранее Azure Active Directory) в вторичную рабочую область, которая существует в основной рабочей области.
Перенос записных книжек и папок пользователей
Используйте приведенный ниже код python, чтобы перенести изолированные пользовательские среды, включающие вложенную структуру папок и записные книжки каждого пользователя.
Примечание.
На этом этапе не копируются библиотеки, так как базовый API не поддерживает их.
Скопируйте и сохраните следующий скрипт Python в файл и запустите его в командной строке. Например,
python scriptname.py.import sys import os import subprocess from subprocess import call, check_output EXPORT_PROFILE = "primary" IMPORT_PROFILE = "secondary" # Get a list of all users user_list_out = check_output(["databricks", "workspace", "list", "/Users", "--profile", EXPORT_PROFILE]) user_list = (user_list_out.decode(encoding="utf-8")).splitlines() print (user_list) # Export sandboxed environment(folders, notebooks) for each user and import into new workspace. #Libraries are not included with these APIs / commands. for user in user_list: #print("Trying to migrate workspace for user ".decode() + user) print (("Trying to migrate workspace for user ") + user) subprocess.call(str("mkdir -p ") + str(user), shell = True) export_exit_status = call("databricks workspace export_dir /Users/" + str(user) + " ./" + str(user) + " --profile " + EXPORT_PROFILE, shell = True) if export_exit_status==0: print ("Export Success") import_exit_status = call("databricks workspace import_dir ./" + str(user) + " /Users/" + str(user) + " --profile " + IMPORT_PROFILE, shell=True) if import_exit_status==0: print ("Import Success") else: print ("Import Failure") else: print ("Export Failure") print ("All done")Перенос конфигураций кластеров
После переноса записных книжек при желании вы можете перенести конфигурации кластеров в новую рабочую область. Это почти полностью автоматизированный шаг с помощью интерфейса командной строки Databricks, если вы не хотите выполнить выборочную миграцию конфигурации кластера.
Примечание.
Конечная точка конфигурации кластера отсутствует, и этот скрипт пытается сразу создать каждый кластер. Если в вашей подписке недостаточно ядер, создание кластера может завершиться неудачей. Сбой можно игнорировать, если конфигурация перенесена успешно.
Приведенный ниже скрипт выводит таблицу соответствия старых идентификаторов кластеров новым. Ее можно использовать позже для переноса заданий (настроенных на использование имеющихся кластеров).
Скопируйте и сохраните следующий скрипт Python в файл и запустите его в командной строке. Например,
python scriptname.py.import sys import os import subprocess import json from subprocess import call, check_output EXPORT_PROFILE = "primary" IMPORT_PROFILE = "secondary" # Get all clusters info from old workspace clusters_out = check_output(["databricks", "clusters", "list", "--profile", EXPORT_PROFILE]) clusters_info_list = str(clusters_out.decode(encoding="utf-8")).splitlines() print("Printing Cluster info List") print(clusters_info_list) # Create a list of all cluster ids clusters_list = [] ##for cluster_info in clusters_info_list: clusters_list.append(cluster_info.split(None, 1)[0]) for cluster_info in clusters_info_list: if cluster_info != '': clusters_list.append(cluster_info.split(None, 1)[0]) # Optionally filter cluster ids out manually, so as to create only required ones in new workspace # Create a list of mandatory / optional create request elements cluster_req_elems = ["num_workers","autoscale","cluster_name","spark_version","spark_conf","node_type_id","driver_node_type_id","custom_tags","cluster_log_conf","spark_env_vars","autotermination_minutes","enable_elastic_disk"] print("Printing Cluster element List") print (cluster_req_elems) print(str(len(clusters_list)) + " clusters found in the primary site" ) print ("---------------------------------------------------------") # Try creating all / selected clusters in new workspace with same config as in old one. cluster_old_new_mappings = {} i = 0 for cluster in clusters_list: i += 1 print("Checking cluster " + str(i) + "/" + str(len(clusters_list)) + " : " +str(cluster)) cluster_get_out_f = check_output(["databricks", "clusters", "get", "--cluster-id", str(cluster), "--profile", EXPORT_PROFILE]) cluster_get_out=str(cluster_get_out_f.decode(encoding="utf-8")) print ("Got cluster config from old workspace") print (cluster_get_out) # Remove extra content from the config, as we need to build create request with allowed elements only cluster_req_json = json.loads(cluster_get_out) cluster_json_keys = cluster_req_json.keys() #Don't migrate Job clusters if cluster_req_json['cluster_source'] == u'JOB' : print ("Skipping this cluster as it is a Job cluster : " + cluster_req_json['cluster_id'] ) print ("---------------------------------------------------------") continue #cluster_req_json.pop(key, None) for key in cluster_json_keys: if key not in cluster_req_elems: print (cluster_req_json) #cluster_del_item=cluster_json_keys .keys() cluster_req_json.popitem(key, None) # Create the cluster, and store the mapping from old to new cluster ids #Create a temp file to store the current cluster info as JSON strCurrentClusterFile = "tmp_cluster_info.json" #delete the temp file if exists if os.path.exists(strCurrentClusterFile) : os.remove(strCurrentClusterFile) fClusterJSONtmp = open(strCurrentClusterFile,"w+") fClusterJSONtmp.write(json.dumps(cluster_req_json)) fClusterJSONtmp.close() #cluster_create_out = check_output(["databricks", "clusters", "create", "--json", json.dumps(cluster_req_json), "--profile", IMPORT_PROFILE]) cluster_create_out = check_output(["databricks", "clusters", "create", "--json-file", strCurrentClusterFile , "--profile", IMPORT_PROFILE]) cluster_create_out_json = json.loads(cluster_create_out) cluster_old_new_mappings[cluster] = cluster_create_out_json['cluster_id'] print ("Cluster create request sent to secondary site workspace successfully") print ("---------------------------------------------------------") #delete the temp file if exists if os.path.exists(strCurrentClusterFile) : os.remove(strCurrentClusterFile) print ("Cluster mappings: " + json.dumps(cluster_old_new_mappings)) print ("All done") print ("P.S. : Please note that all the new clusters in your secondary site are being started now!") print (" If you won't use those new clusters at the moment, please don't forget terminating your new clusters to avoid charges")Перенос конфигурации заданий
Если вы перенесли конфигурации кластеров на предыдущем этапе, вы можете перенести конфигурации заданий. Это полностью автоматизированный шаг с помощью интерфейса командной строки Databricks, если вы не хотите выполнять выборочную миграцию конфигурации задания, а не делать это для всех заданий.
Примечание.
Конфигурация запланированного задания также содержит сведения о расписании, поэтому по умолчанию эта конфигурация начнет работу в назначенное время после миграции. С помощью приведенного ниже блока кода можно удалить все сведения о расписании во время миграции (во избежание повторного выполнения в старых и новых рабочих областях). Настраивайте расписание для таких заданий, когда вы будете готовы к прямой миграции.
Конфигурация заданий должна включать параметры для нового или имеющегося кластера. Если используется имеющийся кластер, приведенный ниже скрипт попытается заменить старый идентификатор кластера на новый.
Скопируйте и сохраните приведенный ниже скрипт python в файл. Замените значения параметров
old_cluster_idиnew_cluster_idна выходные данные, полученные в результате переноса кластеров на предыдущем этапе. Запустите его в командной строке, напримерpython scriptname.py.import sys import os import subprocess import json from subprocess import call, check_output EXPORT_PROFILE = "primary" IMPORT_PROFILE = "secondary" # Please replace the old to new cluster id mappings from cluster migration output cluster_old_new_mappings = {"0227-120427-tryst214": "0229-032632-paper88"} # Get all jobs info from old workspace try: jobs_out = check_output(["databricks", "jobs", "list", "--profile", EXPORT_PROFILE]) jobs_info_list = jobs_out.splitlines() except: print("No jobs to migrate") sys.exit(0) # Create a list of all job ids jobs_list = [] for jobs_info in jobs_info_list: jobs_list.append(jobs_info.split(None, 1)[0]) # Optionally filter job ids out manually, so as to create only required ones in new workspace # Create each job in the new workspace based on corresponding settings in the old workspace for job in jobs_list: print("Trying to migrate " + str(job)) job_get_out = check_output(["databricks", "jobs", "get", "--job-id", job, "--profile", EXPORT_PROFILE]) print("Got job config from old workspace") job_req_json = json.loads(job_get_out) job_req_settings_json = job_req_json['settings'] # Remove schedule information so job doesn't start before proper cutover job_req_settings_json.pop('schedule', None) # Replace old cluster id with new cluster id, if job configured to run against an existing cluster if 'existing_cluster_id' in job_req_settings_json: if job_req_settings_json['existing_cluster_id'] in cluster_old_new_mappings: job_req_settings_json['existing_cluster_id'] = cluster_old_new_mappings[job_req_settings_json['existing_cluster_id']] else: print("Mapping not available for old cluster id " + str(job_req_settings_json['existing_cluster_id'])) continue call(["databricks", "jobs", "create", "--json", json.dumps(job_req_settings_json), "--profile", IMPORT_PROFILE]) print("Sent job create request to new workspace successfully") print("All done")Перенос библиотек
В настоящее время не существует простого способа перенести библиотеки из одной рабочей области в другую. Вместо этого библиотеки следует устанавливать в новой рабочей области вручную. Это можно автоматизировать с помощью интерфейса командной строки Databricks для отправки пользовательских библиотек в рабочую область.
Перенос подключений Хранилища BLOB-объектов Azure и Azure Data Lake Storage
Вручную подключите все хранилища BLOB-объектов Azure и точки подключения Azure Data Lake Storage (2-го поколения) с помощью решения на основе записной книжки. Ресурсы хранилища были бы подключены в основной рабочей области, и это следует повторить в дополнительной рабочей области. Внешних API для подключений не существует.
Перенос скриптов инициализации кластеров
Любые скрипты инициализации кластера можно перенести из старой в новую рабочую область с помощью интерфейса командной строки Databricks. Сначала скопируйте необходимые скрипты на локальный рабочий стол или виртуальную машину. Затем скопируйте эти скрипты в новую рабочую область, находящуюся по тому же пути.
Примечание.
Если у вас есть скрипты инициализации, хранящиеся в DBFS, сначала перенесите их в поддерживаемое расположение. См статью: _.
// Primary to local databricks fs cp dbfs:/Volumes/my_catalog/my_schema/my_volume/ ./old-ws-init-scripts --profile primary // Local to Secondary workspace databricks fs cp old-ws-init-scripts dbfs:/Volumes/my_catalog/my_schema/my_volume/ --profile secondaryПовторная настройка и применение управления доступом вручную
Если существующая основная рабочая область настроена на использование уровня Premium или Enterprise (SKU), скорее всего, вы также используете управление доступом.
Если вы используете управление доступом, повторно примените управление доступом к ресурсам (записные книжки, кластеры, задания, таблицы).
Аварийное восстановление для экосистемы Azure
Если вы используете другие службы Azure, обязательно реализуйте рекомендации по аварийному восстановлению и для этих служб. Например, если вы решили использовать внешний экземпляр хранилища метаданных Hive, рекомендуем обеспечить аварийное восстановление для Базы данных SQL Azure, Azure HDInsight и (или) Базы данных Azure для MySQL. Общие сведения об аварийном восстановлении см. в статье Аварийное восстановление для приложений Azure.
Следующие шаги
Дополнительные сведения см. в документации по Azure Databricks.