Двоичный файл
Databricks Runtime поддерживает источник данных двоичного файла, который считывает двоичные файлы и преобразует каждый файл в отдельную запись с необработанным содержимым и метаданными файла. Источник данных двоичного файла создает кадр данных со следующими столбцами и, возможно, столбцами секций:
-
path (StringType): путь к файлу. -
modificationTime (TimestampType): время изменения файла. В некоторых реализациях Файловой системы Hadoop этот параметр может быть недоступен, и значение будет задано значением по умолчанию. -
length (LongType): длина файла в байтах. -
content (BinaryType): содержимое файла.
Для чтения двоичных файлов укажите источник данных format как binaryFile.
Изображения
Databricks рекомендует использовать источник данных двоичного файла для отправки данных изображений
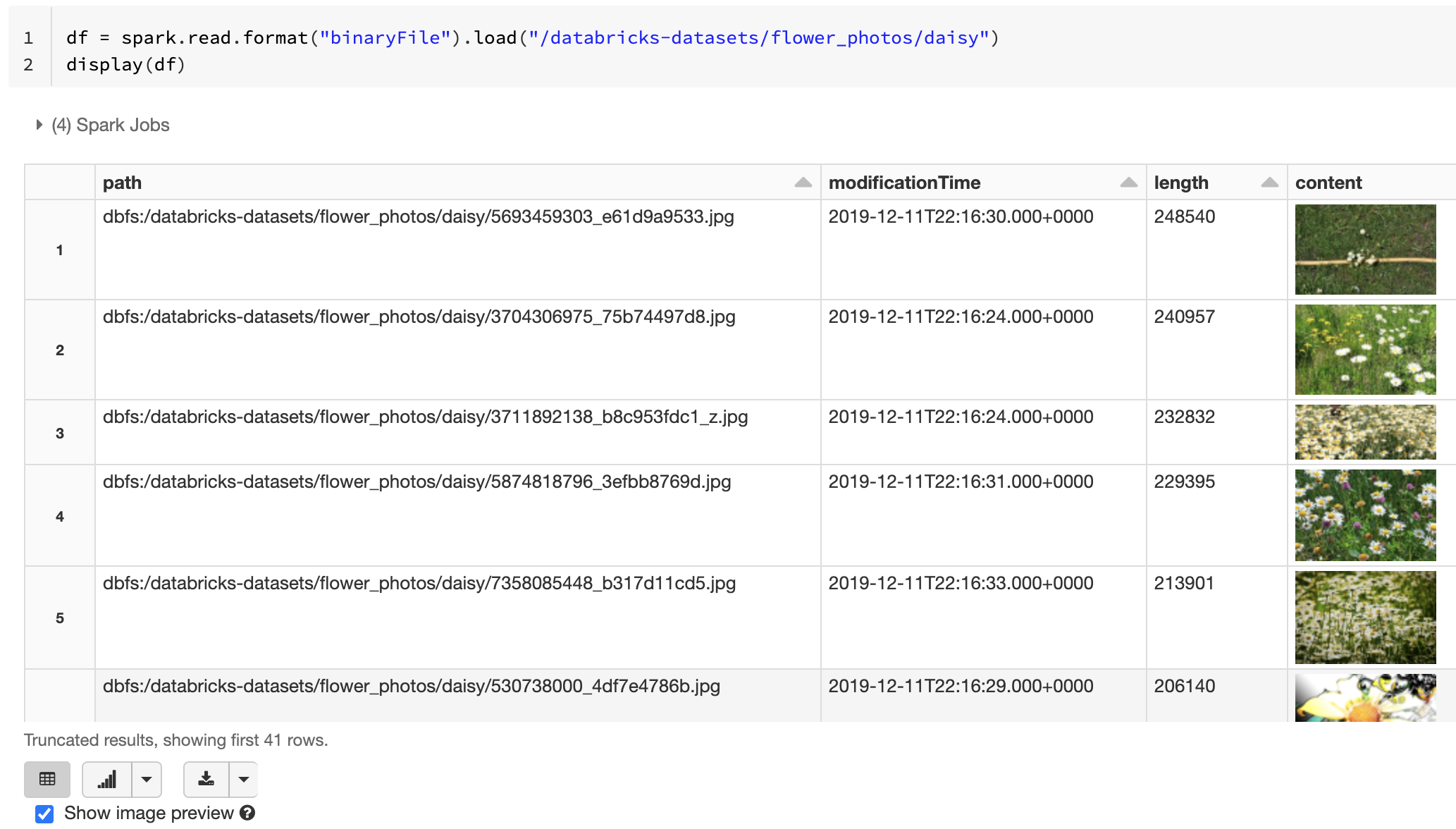
Функция Databricks display поддерживает отображение данных изображения, загруженных с помощью двоичного источника данных.
Если все загруженные файлы имеют имя файла с расширением image, то предварительный просмотр изображения включается автоматически.
df = spark.read.format("binaryFile").load("<path-to-image-dir>")
display(df) # image thumbnails are rendered in the "content" column
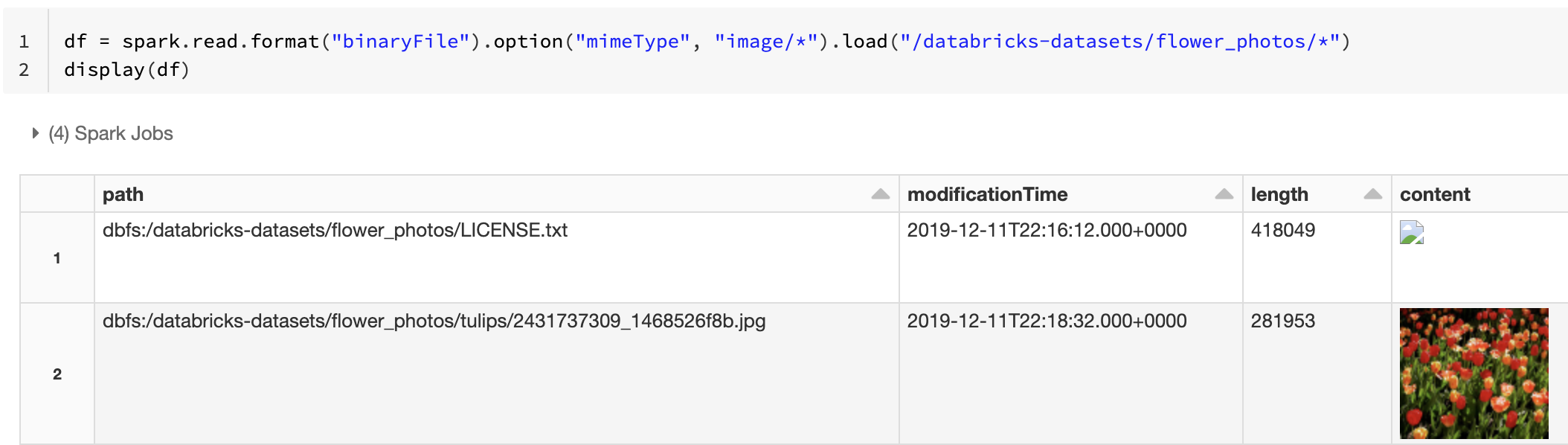
Кроме того, можно принудительно применить функцию предварительного просмотра изображений, используя параметр mimeType со строковым значением "image/*" для аннотации двоичного столбца. Изображения декодируются с учетом сведений о формате в двоичном содержимом. Поддерживаются следующие типы изображений: bmp, gif, jpeg и png. Неподдерживаемые файлы отображаются в виде значка поврежденного изображения.
df = spark.read.format("binaryFile").option("mimeType", "image/*").load("<path-to-dir>")
display(df) # unsupported files are displayed as a broken image icon
Рекомендуемый рабочий процесс для обработки данных изображения см. в разделе Эталонное решение для приложений, работающих с изображениями.
Параметры
Чтобы загрузить файлы с путями, соответствующими заданному шаблону глобов, при сохранении поведения обнаружения секций можно использовать параметр pathGlobFilter. Следующий код считывает все ФАЙЛЫ JPG из входного каталога с обнаружением секций:
df = spark.read.format("binaryFile").option("pathGlobFilter", "*.jpg").load("<path-to-dir>")
Если вы хотите игнорировать обнаружение секций и рекурсивно искать файлы в входном каталоге, используйте параметр recursiveFileLookup. Этот параметр выполняет поиск по вложенным каталогам, даже если их имена не следуют схеме именования разделов, например date=2019-07-01.
Следующий код считывает все ФАЙЛЫ JPG рекурсивно из входного каталога и игнорирует обнаружение секций:
df = spark.read.format("binaryFile") \
.option("pathGlobFilter", "*.jpg") \
.option("recursiveFileLookup", "true") \
.load("<path-to-dir>")
Аналогичные API существуют для Scala, Java и R.
Примечание.
Чтобы повысить производительность чтения при загрузке данных обратно, Azure Databricks рекомендует сохранять данные, загруженные из двоичных файлов с помощью таблиц Delta:
df.write.save("<path-to-table>")