Определение ресурсоемкого чтения в DAG Spark
Получение к DAG
Предположим, что вы рассматриваете дорогостоящую работу, сначала нам нужно получить идентификатор этапа, который выполняет чтение. Здесь мы видим, что идентификатор этапа равен 194:

Теперь нам нужно добраться до DAG SQL. Прокрутите вверх до начала страницы задания и нажмите связанный запрос SQL.

Теперь вы должны увидеть DAG. Если нет, прокрутите немного и увидите следующее:
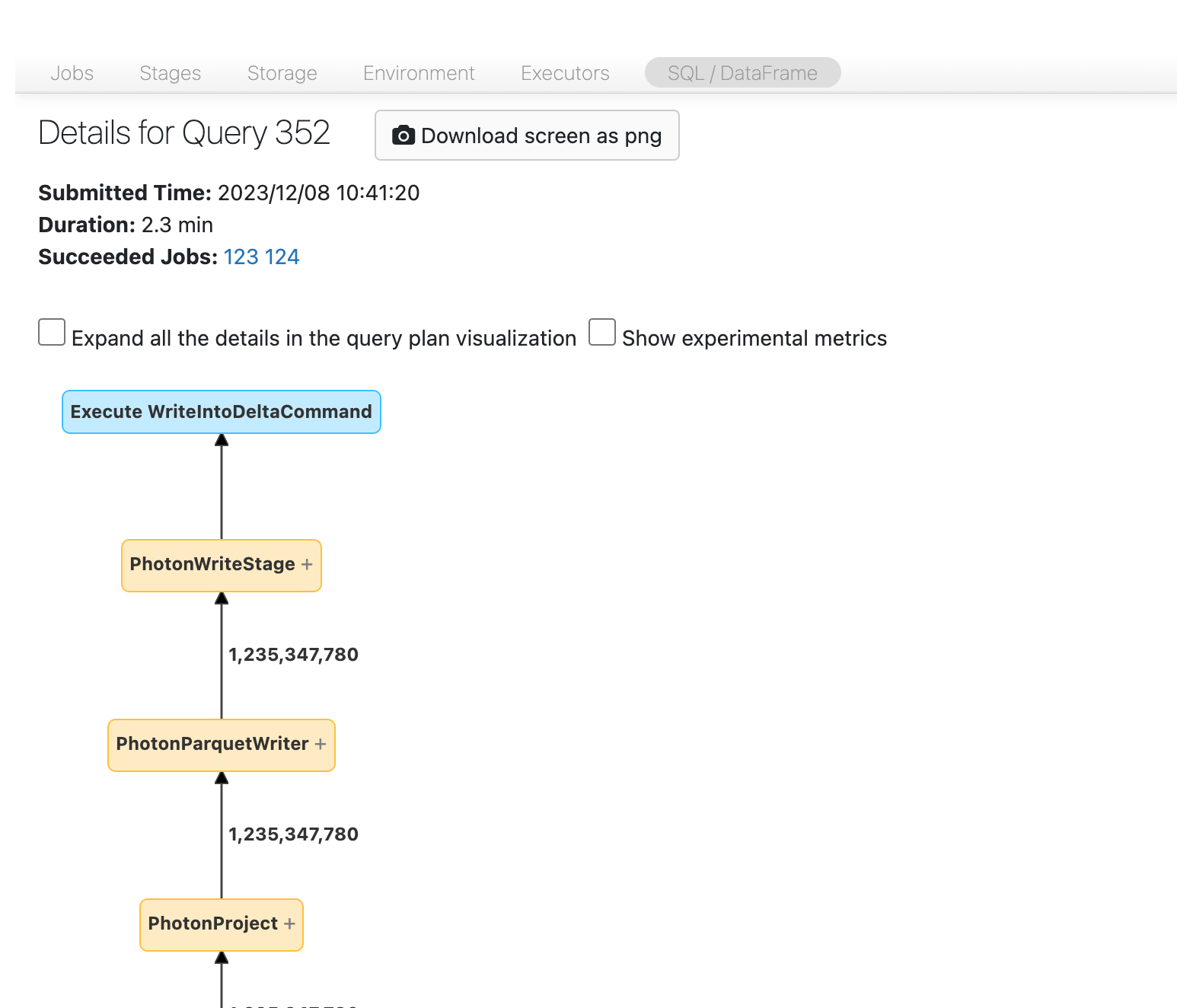
В некоторых случаях можно следить за DAG и видеть, откуда приходят данные. В других случаях найдите идентификатор этапа, который вы указали:
Этап SQL 
Затем необходимо найти узел "Скан". В этом случае довольно просто сказать, что мы читаем таблицу с именем transactions:

В некоторых случаях может потребоваться щелкнуть на узел или навести на него курсор, чтобы определить местоположение данных, которые вы просматриваете.