Создание обучающего запуска с помощью API тонкой настройки модели Foundation
В этой статье описывается, как создать и настроить обучающий запуск с использованием API для тонкой настройки модели Foundation (теперь это часть обучения модели Mosaic AI), а также приводится описание всех parameters, используемых в вызове API. Вы также можете создать запуск с помощью пользовательского интерфейса. Инструкции см. в статье "Создание обучающего запуска с помощью пользовательского интерфейса тонкой настройки модели Foundation".
Требования
См. раздел Требования.
Создание учебного запуска
Чтобы создать обучающие запуски программным способом, используйте функцию create() . Эта функция обучает модель в предоставленном наборе данных и преобразует окончательную контрольную точку Composer в отформатированную контрольную точку распознавания лиц для вывода.
Необходимые входные данные — это модель, которую вы хотите обучить, расположение набора данных обучения и where для регистрации модели. Существуют также необязательные parameters, которые позволяют вам выполнять оценку и изменять гиперпараметры вашего запуска.
После завершения выполнения завершенный запуск и окончательный контрольный чекпоинт сохраняются, модель клонируется, и этот клон регистрируется в Unity Catalog как версия модели для вывода данных.
Модель из завершенного запуска не клонированную версию модели в Unity Catalog, а ее Composer и Hugging Face контрольные точки сохраняются в MLflow. Контрольные точки Composer можно использовать для дальнейших задач тонкой настройки.
Дополнительные сведения о аргументах для функции см. в разделе "Настройка обучения".create()
from databricks.model_training import foundation_model as fm
run = fm.create(
model='meta-llama/Llama-3.2-3B-Instruct',
train_data_path='dbfs:/Volumes/main/mydirectory/ift/train.jsonl', # UC Volume with JSONL formatted data
# Public HF dataset is also supported
# train_data_path='mosaicml/dolly_hhrlhf/train'
register_to='main.mydirectory', # UC catalog and schema to register the model to
)
Настройка учебного запуска
Следующий table суммирует parameters для функции foundation_model.create().
| Параметр | Обязательное поле | Type | Description |
|---|---|---|---|
model |
x | str | Имя используемой модели. См. раздел "Поддерживаемые модели". |
train_data_path |
x | str | Расположение обучающих данных. Это может быть местоположение в Unity Catalog (<catalog>.<schema>.<table> или dbfs:/Volumes/<catalog>/<schema>/<volume>/<dataset>.jsonl) или набор данных HuggingFace.Для INSTRUCTION_FINETUNEэтого данные должны быть отформатированы с каждой prompt строкой, содержащей и response поле.Для CONTINUED_PRETRAINэтого используется папка .txt файлов. Ознакомьтесь с разделом "Подготовка данных для точной настройки модели Foundation" для принятых форматов данных и рекомендуемого размера данных для обучения модели для рекомендаций по размеру данных. |
register_to |
x | str |
Catalog
catalog Unity и schema (<catalog>.<schema> или <catalog>.<schema>.<custom-name>) where модель регистрируется после обучения для простого развертывания. Если custom-name этот параметр не указан, по умолчанию используется имя выполнения. |
data_prep_cluster_id |
str | Идентификатор кластера для обработки данных Spark. Это необходимо для задач обучения по инструкциям where, данные обучения находятся в Delta table. Сведения о том, как найти идентификатор кластера, см. в Get идентификаторе кластера. | |
experiment_path |
str | Путь к эксперименту MLflow where выходные данные выполнения обучения (метрики и контрольные точки) сохраняются. По умолчанию используется имя запуска в личной рабочей области пользователя (т. е. /Users/<username>/<run_name>). |
|
task_type |
str | Тип выполняемой задачи. Может быть CHAT_COMPLETION (по умолчанию), CONTINUED_PRETRAINили INSTRUCTION_FINETUNE. |
|
eval_data_path |
str | Удаленное расположение данных оценки (если таковые есть). Должен соответствовать тому же формату, что train_data_pathи . |
|
eval_prompts |
List[str] | В ходе оценки оценивается list строк запроса на generate ответов. По умолчанию используется None (не выполнять generate). Результаты регистрируются в эксперимент каждый раз при контрольной точке модели. Поколения происходят на каждой контрольной точке модели со следующим поколением parameters: max_new_tokens: 100, temperature: 1, top_k: 50, top_p: 0.95, do_sample: true. |
|
custom_weights_path |
str | Удаленное расположение пользовательской контрольной точки модели для обучения. Значение по умолчанию — это Noneозначает, что запуск начинается с исходных предварительно обученных весов выбранной модели. Если предоставляются пользовательские весы, эти весы используются вместо исходных предварительно обученных весов модели. Эти весы должны быть контрольной точкой Composer и должны соответствовать архитектуре указанного model . См. статью "Сборка на основе весов пользовательских моделей" |
|
training_duration |
str | Общая длительность выполнения. По умолчанию используется одна эпоха или 1ep. Можно указать в эпохах (10ep) или маркерах (1000000tok). |
|
learning_rate |
str | Частота обучения для обучения модели. Для всех моделей, отличных от Ллама 3.1 405B Instruct, по умолчанию используется 5e-7частота обучения. Для Ламы 3.1 405B инструктажа по умолчанию используется 1.0e-5частота обучения. Оптимизатор — DecoupledLionW с бета-версиями 0,99 и 0,95 и без распада веса. Планировщик скорости обучения — LinearWithWarmupSchedule с 2% от общей продолжительности обучения и окончательного умножения скорости обучения 0. |
|
context_length |
str | Максимальная длина последовательности примера данных. Это используется для усечения всех данных, слишком длинных и для упаковки более коротких последовательностей для повышения эффективности. Значение по умолчанию — 8192 маркеров или максимальная длина контекста для предоставленной модели, в зависимости от того, что ниже. Этот параметр можно использовать для настройки длины контекста, но настройка за пределами максимальной длины контекста модели не поддерживается. См. раздел "Поддерживаемые модели " для максимальной поддерживаемой длины контекста каждой модели. |
|
validate_inputs |
Логический | Следует ли проверять доступ к входным путям перед отправкой задания обучения. По умолчанию — True. |
Сборка на основе весов пользовательских моделей
Базовая настройка модели поддерживает добавление настраиваемых весов с помощью необязательного параметра custom_weights_path для обучения и настройки модели.
Чтобы get начал, setcustom_weights_path по пути Composer контрольной точки из предыдущего учебного запуска. Пути контрольной точки можно найти на вкладке Артефактов предыдущего запуска MLflow. Имя папки контрольной точки соответствует пакету и эпохе определенного моментального снимка, например ep29-ba30/.

- Чтобы предоставить последнюю контрольную точку из предыдущего запуска в контрольную точку Composer, используйте set
custom_weights_path. Например,custom_weights_path=dbfs:/databricks/mlflow-tracking/<experiment_id>/<run_id>/artifacts/<run_name>/checkpoints/latest-sharded-rank0.symlink. - Чтобы обеспечить доступ к более ранней контрольной точке, укажите путь set
custom_weights_pathк папке, содержащей файлы.distcp, которые соответствуют требуемой контрольной точке, например,custom_weights_path=dbfs:/databricks/mlflow-tracking/<experiment_id>/<run_id>/artifacts/<run_name>/checkpoints/ep#-ba#.
Затем update параметр model для сопоставления базовой модели контрольной точки, переданной custom_weights_path.
В следующем примере ift-meta-llama-3-1-70b-instruct-ohugkq показан предыдущий запуск, который настраивается meta-llama/Meta-Llama-3.1-70B. Чтобы точно настроить последнюю контрольную точку из ift-meta-llama-3-1-70b-instruct-ohugkq, set переменные model и custom_weights_path следующим образом:
from databricks.model_training import foundation_model as fm
run = fm.create(
model = 'meta-llama/Meta-Llama-3.1-70B'
custom_weights_path = 'dbfs:/databricks/mlflow-tracking/2948323364469837/d4cd1fcac71b4fb4ae42878cb81d8def/artifacts/ift-meta-llama-3-1-70b-instruct-ohugkq/checkpoints/latest-sharded-rank0.symlink'
... ## other parameters for your fine-tuning run
)
См. Настройка запуска обучения для настройки прочих parameters в вашем запуске тонкой настройки.
идентификатор кластера Get
Чтобы получить идентификатор кластера, выполните следующие действия.
В левой панели навигации рабочей области Databricks щелкните "Вычисления".
В tableвыберите имя вашего кластера.
Нажмите кнопку
 в правом верхнем углу и select"Просмотреть JSON" из раскрывающегося меню.
в правом верхнем углу и select"Просмотреть JSON" из раскрывающегося меню.Появится JSON-файл кластера. Скопируйте идентификатор кластера, который является первой строкой в файле.
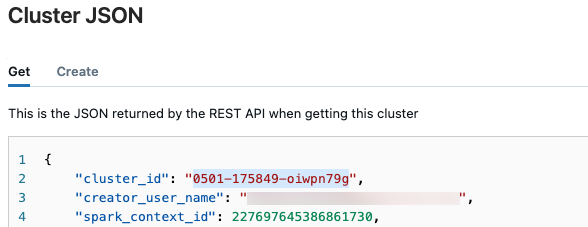
Get состояние запуска
Ход выполнения можно отслеживать с помощью страницы "Эксперимент" в пользовательском интерфейсе Databricks или с помощью команды get_events()API. Дополнительные сведения см. в статье Просмотр, управление и анализ запусков тонкой настройки модели Foundation.
Пример выходных данных из get_events():
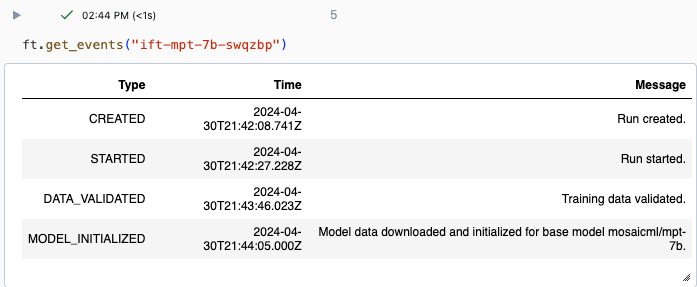
Пример сведений о выполнении на странице "Эксперимент"
Следующие шаги
После завершения обучения можно просмотреть метрики в MLflow и развернуть модель для вывода. См. шаги 5–7 руководства. Создание и развертывание запуска тонкой настройки модели Foundation.
Дополнительные сведения о настройке инструкции: демонстрационная записная книжка распознавания именованных сущностей см. в примере точной настройки инструкции, которая описывает подготовку данных, настройку конфигурации и развертывания для обучения.
Пример записной книжки
В следующей записной книжке показан пример того, как generate синтетические данные с использованием модели Meta Llama 3.1 405B Instruct и использовать эти данные для точной настройки модели.
Generate данные синтетические с помощью блокнота Instruct Llama 3.1 405B
Дополнительные ресурсы
- Тонкое настройка модели Foundation
- Руководство по созданию и развертыванию запуска тонкой настройки модели Foundation
- Создание обучающего запуска с помощью пользовательского интерфейса тонкой настройки модели Foundation
- Просмотр, управление и анализ запусков тонкой настройки модели Foundation
- Подготовка данных для точной настройки модели Foundation