Руководящие принципы для лейкхауса
Руководящие принципы — это правила нулевого уровня, определяющие и влияющие на архитектуру. Для создания озера данных, который помогает вашему бизнесу добиться успеха в будущем, консенсус между заинтересованными лицами в вашей организации является критически важным.
Курировать данные и предлагать доверенные данные как продукты
Для создания озера данных с высоким уровнем ценности для бизнес-аналитики и машинного обучения и машинного обучения и искусственного интеллекта необходимо создать высокоценное озеро данных. Обработка данных как продукта с четким определением, схемой и жизненным циклом. Обеспечение семантической согласованности и улучшение качества данных от уровня до уровня, чтобы бизнес-пользователи могли полностью доверять данным.
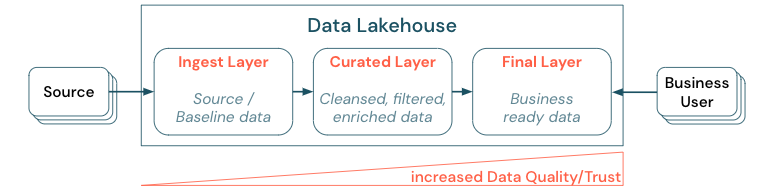
Обработка данных путем установления многоуровневой архитектуры (или многопрыжок) является критически важной практикой для лейкхауса, так как она позволяет командам данных структурировать данные в соответствии с уровнями качества и определять роли и обязанности на уровне. Распространенный подход к наслоениям:
- Уровень приема: исходные данные получают прием в лейкхаус в первом слое и должны быть сохранены там. Когда все подчиненные данные создаются из слоя приема, при необходимости можно перестроить последующие слои из этого слоя.
- Курированный слой: цель второго слоя — хранить очищенные, уточненные, отфильтрованные и агрегированные данные. Цель этого слоя — обеспечить надежную основу для анализа и отчетов во всех ролях и функциях.
- Окончательный уровень: третий уровень создается вокруг потребностей бизнеса или проекта; он предоставляет другое представление как продукты данных для других бизнес-единиц или проектов, подготовка данных вокруг потребностей безопасности (например, анонимные данные) или оптимизация для производительности (с предварительно агрегированными представлениями). Продукты данных в этом слое рассматриваются как истина для бизнеса.
Конвейеры на всех уровнях должны обеспечить соблюдение ограничений качества данных, что означает, что данные являются точными, полными, доступными и согласованными во время одновременного чтения и записи. Проверка новых данных происходит во время ввода данных в курируемый слой, а следующие шаги ETL выполняются для улучшения качества этих данных. Качество данных должно улучшиться по мере прогресса данных на уровнях и, таким образом, доверие к данным впоследствии увеличивается с точки зрения бизнеса.
Устранение силосов данных и минимизация перемещения данных
Не создавайте копии набора данных с бизнес-процессами, основанными на этих разных копиях. Копии могут стать силосами данных, которые выходят из синхронизации, что приводит к снижению качества озера данных и, наконец, к устаревшим или неправильным аналитическим сведениям. Кроме того, для совместного использования данных с внешними партнерами используйте механизм общего доступа предприятия, который обеспечивает безопасный доступ к данным.
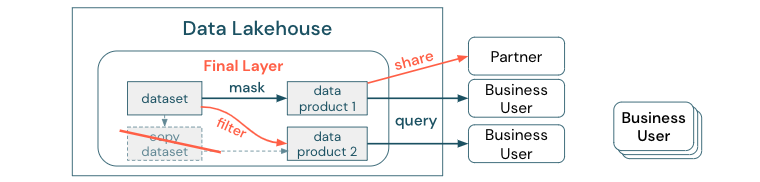
Чтобы сделать различие между копией данных и хранилищем данных: автономная или бросаемая копия данных не вредна самостоятельно. Иногда это необходимо для повышения гибкости, экспериментирования и инноваций. Однако если эти копии становятся операционными с подчиненными продуктами бизнес-данных, зависящими от них, они становятся силосами данных.
Чтобы предотвратить использование силосов данных, команды данных обычно пытаются создать механизм или конвейер данных, чтобы сохранить все копии в синхронизации с исходным. Так как это вряд ли произойдет последовательно, качество данных в конечном итоге снижается. Это также может привести к более высоким затратам и значительной потере доверия пользователей. С другой стороны, для использования нескольких бизнес-вариантов требуется совместное использование данных с партнерами или поставщиками.
Важным аспектом является безопасное и надежное совместное использование последней версии набора данных. Копии набора данных часто недостаточно, так как они могут быстро выйти из синхронизации. Вместо этого данные следует совместно использовать с помощью корпоративных средств общего доступа к данным.
Демократизация создания значений с помощью самообслуживания
Лучшее озеро данных не может обеспечить достаточное значение, если пользователи не могут получить доступ к платформе или данным для своих задач бизнес-аналитики и машинного обучения и искусственного интеллекта. Снижение барьеров доступа к данным и платформам для всех бизнес-подразделений. Рассмотрим процессы управления данными с поддержкой бережливого управления и обеспечивают самостоятельный доступ для платформы и базовых данных.
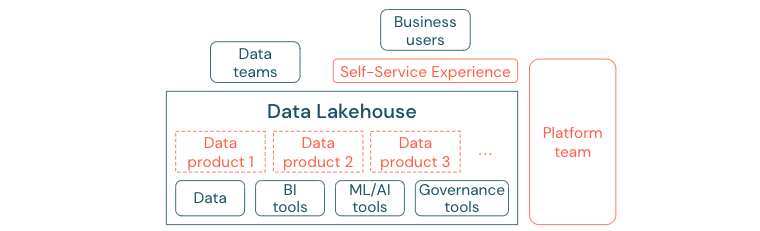
Предприятия, которые успешно переехали в культуру на основе данных, будут процветать. Это означает, что каждая бизнес-единица получает свои решения от аналитических моделей или от анализа собственных или централизованно предоставленных данных. Для потребителей данные должны быть легко обнаруживаемыми и безопасными.
Хорошая концепция для производителей данных — это "данные как продукт": данные предлагаются и поддерживаются одним бизнес-подразделением или бизнес-партнером, например продуктом и потребляемыми другими сторонами с соответствующим контролем разрешений. Вместо того, чтобы полагаться на центральную команду и потенциально медленные процессы запроса, эти продукты данных должны быть созданы, предложены, обнаружены и использованы в самообслуживании.
Однако это не только данные, которые имеют значение. Для демократизации данных требуются правильные средства, позволяющие всем создавать или использовать и понимать данные. Для этого необходимо, чтобы data lakehouse был современной платформой данных и ИИ, которая предоставляет инфраструктуру и инструменты для создания продуктов данных без дублирования усилий по настройке другого стека инструментов.
Внедрение стратегии управления данными на уровне организации
Данные являются критически важным ресурсом любой организации, но вы не можете предоставить всем доступ ко всем данным. Доступ к данным должен быть активно управляемым. Контроль доступа, аудит и отслеживание происхождения являются ключевыми для правильного и безопасного использования данных.
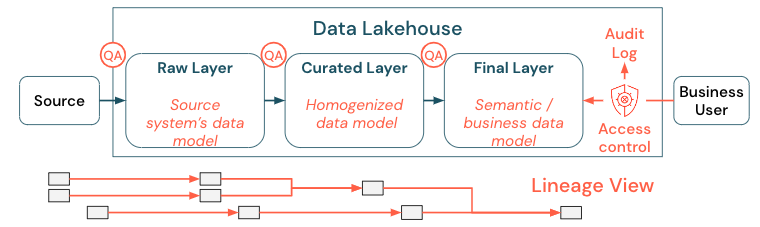
Управление данными — это широкий раздел. Lakehouse охватывает следующие измерения:
Качество данных
Наиболее важным условием для правильных и значимых отчетов, результатов анализа и моделей является высококачественные данные. Обеспечение качества (QA) должно существовать во всех шагах конвейера. Примеры реализации этого способа: наличие контрактов данных, соглашения об уровне обслуживания для собраний, сохранение стабильной схемы и их развитие в управляемом режиме.
Каталог данных
Еще одним важным аспектом является обнаружение данных: пользователи всех бизнес-областей, особенно в модели самообслуживания, должны легко обнаруживать соответствующие данные. Таким образом, в лейкхаусе требуется каталог данных, охватывающий все бизнес-релевантные данные. Основными целями каталога данных являются следующие:
- Убедитесь, что одна и та же бизнес-концепция называется единообразно и объявлена по всему бизнесу. Вы можете подумать о нем как семантической модели в курированном и окончательном слое.
- Отслеживайте происхождение данных точно, чтобы пользователи могли объяснить, как эти данные прибыли в текущую фигуру и форму.
- Поддерживайте высококачественные метаданные, которые так же важны, как сами данные для правильного использования данных.
Управление доступом
Поскольку создание ценности из данных в лейкхаусе происходит во всех бизнес-областях, озеро должно быть построено с безопасностью в качестве первого класса гражданина. Компании могут иметь более открытую политику доступа к данным или строго следовать принципу наименьших привилегий. Независимо от этого, элементы управления доступом к данным должны находиться на каждом уровне. Важно реализовать схемы разрешений точного уровня с самого начала (управление доступом на уровне столбцов и строк, управление доступом на основе ролей или атрибутов). Компании могут начинаться с менее строгих правил. Но по мере роста платформы Lakehouse все механизмы и процессы для более сложного режима безопасности уже должны быть на месте. Кроме того, все доступ к данным в lakehouse должен регулироваться журналами аудита из get-go.
Поощрять открытые интерфейсы и открытые форматы
Открытые интерфейсы и форматы данных важны для взаимодействия между lakehouse и другими инструментами. Она упрощает интеграцию с существующими системами, а также открывает экосистему партнеров, которые интегрировали свои инструменты с платформой.
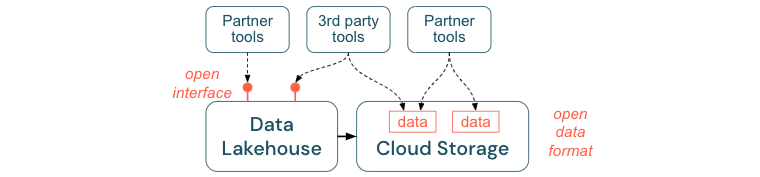
Открытые интерфейсы критически важны для обеспечения взаимодействия и предотвращения зависимостей от одного поставщика. Традиционно поставщики создали собственные технологии и закрытые интерфейсы, которые ограничивают предприятия тем, как они могут хранить, обрабатывать и делиться данными.
Опираясь на открытые интерфейсы, вы сможете построить в будущем:
- Это повышает долголетие и переносимость данных, чтобы их можно было использовать с большим количеством приложений и для других вариантов использования.
- Она открывает экосистему партнеров, которые могут быстро использовать открытые интерфейсы для интеграции своих инструментов в платформу Lakehouse.
Наконец, стандартизируя открытые форматы данных, общая стоимость будет значительно ниже; доступ к данным можно получить непосредственно в облачном хранилище без необходимости передавать их через собственную платформу, которая может нести высокие затраты на исходящий и вычислительный трафик.
Сборка для масштабирования и оптимизации производительности и затрат
Данные неизбежно продолжают расти и становятся более сложными. Чтобы обеспечить организацию для будущих потребностей, вы сможете масштабировать lakehouse. Например, вы можете легко добавлять новые ресурсы по запросу. Затраты должны быть ограничены фактическим потреблением.
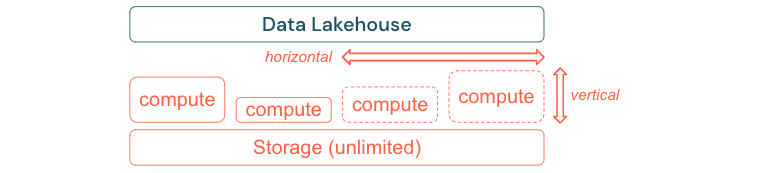
Стандартные процессы ETL, бизнес-отчеты и панели мониторинга часто имеют прогнозируемый ресурс с точки зрения памяти и вычислений. Однако новые проекты, сезонные задачи или современные подходы, такие как обучение модели (отток, прогноз, обслуживание), создают пики потребности в ресурсах. Чтобы обеспечить бизнесу выполнение всех этих рабочих нагрузок, необходимо масштабируемую платформу для памяти и вычислений. Новые ресурсы должны быть легко добавлены по запросу, и только фактическое потребление должно генерировать затраты. Как только пик закончится, ресурсы можно освободить снова и сократить расходы соответствующим образом. Часто это называется горизонтальным масштабированием (меньше или больше узлов) и вертикальным масштабированием (большими или меньшими узлами).
Масштабирование также позволяет предприятиям повысить производительность запросов, выбрав узлы с большим количеством ресурсов или кластеров с большим количеством узлов. Но вместо постоянного предоставления больших компьютеров и кластеров они могут быть подготовлены только по требованию только для времени, необходимого для оптимизации общего соотношения производительности к затратам. Другим аспектом оптимизации является хранилище и вычислительные ресурсы. Поскольку нет четкой связи между объемом данных и рабочими нагрузками, использующими эти данные (например, только с помощью частей данных или интенсивных вычислений на небольших данных), рекомендуется урегулировать на инфраструктурной платформе, которая отделяет хранилище и вычислительные ресурсы.