Использование преобразований dbt в задании Azure Databricks
Проекты dbt Core можно запускать как задачу в задании Azure Databricks. Запустив проект dbt Core как задачу задания, вы можете воспользоваться следующими функциями заданий Azure Databricks:
- автоматизация задач dbt и планирование рабочих процессов, включающих задачи dbt;
- мониторинг преобразования dbt и отправка уведомлений о состоянии преобразований;
- включение проекта dbt в рабочий процесс с другими задачами. Например, рабочий процесс может получать данные с помощью автозагрузчика, преобразовывать данные с помощью dbt и анализировать данные с помощью задачи записной книжки.
- Автоматическая архивация артефактов из выполнений заданий, включая журналы, результаты, манифесты и конфигурацию.
Дополнительные сведения о dbt Core см. в документации по dbt.
Рабочий процесс для среды разработки и рабочей среды
Databricks рекомендует разрабатывать проекты dbt в хранилище Databricks SQL. С помощью хранилища Databricks SQL можно протестировать SQL, созданный dbt, и использовать журнал запросов хранилища SQL для отладки запросов, созданных dbt.
Для преобразования dbt в рабочей среде, Databricks рекомендует использовать задачу dbt в задании Databricks. По умолчанию задача dbt будет выполнять процесс dbt Python с помощью вычислений Azure Databricks и созданного базы данных SQL в выбранном хранилище SQL.
Вы можете выполнять преобразования dbt в бессерверном хранилище SQL или хранилище pro SQL, вычислении Azure Databricks или любом другом хранилище, поддерживаемом базой данных. В этой статье рассматриваются первые два варианта с примерами.
Если рабочая область поддерживает Unity Catalog и включены бессерверные задания, по умолчанию задание выполняется на бессерверных вычислительных мощностях.
Примечание.
Разработка моделей субд для хранилища SQL и их запуск в рабочей среде в вычислительных ресурсах Azure Databricks может привести к незначительным различиям в производительности и поддержке языка SQL. Databricks рекомендует использовать ту же версию Databricks Runtime для вычислений и хранилища SQL.
Требования
Сведения об использовании dbt Core и пакета
dbt-databricksдля создания и запуска проектов dbt в среде разработки см. в статье Подключение к dbt Core.Databricks рекомендует использовать пакет dbt-databricks, а не пакет dbt-spark. Пакет dbt-databricks — это вилка dbt-spark, оптимизированная для Databricks.
Чтобы использовать проекты dbt в задании Azure Databricks, необходимо настроить интеграцию Git для папок Databricks Git. Невозможно запустить проект dbt из DBFS.
Необходимо включить бессерверные или профессиональные хранилища SQL.
У вас должно быть право на использование Databricks SQL.
Создание и запуск первого задания dbt
В следующем примере используется проект jaffle_shop, пример проекта, демонстрирующий основные понятия dbt. Чтобы создать задание, которое запускает проект магазина jaffle, выполните следующие шаги.
Перейдите на целевую страницу Azure Databricks и выполните одно из следующих действий:
- Щелкните
 рабочие процессы на боковой панели и щелкните .
рабочие процессы на боковой панели и щелкните .
- На боковой панели щелкните
 Создать и выберите задание.
Создать и выберите задание.
- Щелкните
В текстовом поле задачи на вкладке "Задачи " замените имя задания... именем задания.
В поле Имя задачи введите имя задачи.
В типевыберите тип задачи dbt.
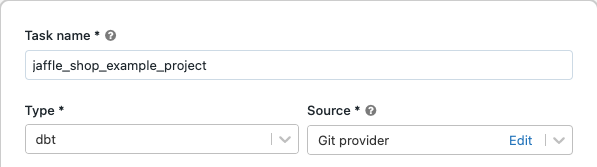
В раскрывающемся меню Источник можно выбрать Рабочее пространство, чтобы использовать проект dbt, расположенный в папке рабочей области Azure Databricks, или провайдера Git для проекта, находящегося в удаленном репозитории Git. Так как в этом примере используется проект "jaffle shop", расположенный в репозитории Git, выберите поставщика Git, нажмите Editи введите данные для репозитория GitHub "jaffle shop."
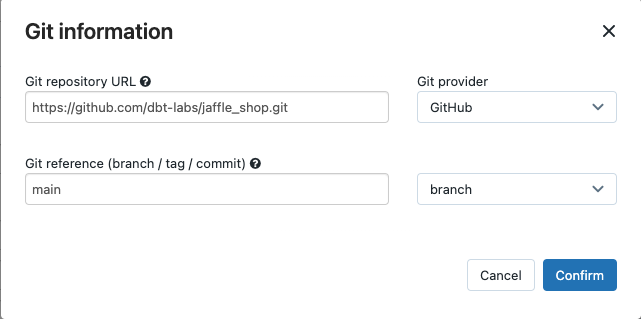
- В поле URL-репозитория Git введите URL-адрес для проекта магазина jaffle.
- В поле Git reference (branch / tag / commit) (Ссылка Git (ветвь/тег/фиксация)) введите
main. Вы также можете использовать тег или SHA.
Нажмите кнопку Подтвердить.
В текстовых полях команд dbt укажите команды dbt для выполнения (deps, seed и run). Перед каждой командой необходимо указывать префикс
dbt. Команды выполняются в указанном порядке.
В SQL-хранилищевыберите SQL-хранилище для выполнения SQL-кода, созданного с помощью dbt. Раскрывающееся меню хранилища SQL отображает только бессерверные и профессиональные хранилища SQL.
(Необязательно) Можно указать схему для выходных данных задачи. По умолчанию используется схема
default.(Необязательно) Если вы хотите изменить конфигурацию вычислений, на которой выполняется dbt Core, щелкните вычисление dbt CLI.
(Необязательно) Для задачи можно указать версию dbt-databricks. Например, чтобы закрепить задачу dbt в определенной версии для среды разработки и рабочей среды:
- В разделе Зависимые библиотеки щелкните
 рядом с текущей версией dbt-databricks.
рядом с текущей версией dbt-databricks. - Нажмите кнопку Добавить.
- В диалоговом окне
Добавление зависимой библиотеки выберитеPyPI и введите версию пакета dbt в текстовом поле пакета(например, ). - Нажмите кнопку Добавить.

Примечание.
Databricks рекомендует закрепить задачи dbt в определенной версии пакета dbt-databricks, чтобы для разработки и рабочих запусков использовалась одна и та же версия. Databricks рекомендует версию 1.6.0 или больше пакета dbt-databricks.
- В разделе Зависимые библиотеки щелкните
Нажмите кнопку Создать.
Чтобы запустить задание, нажмите кнопку
 .
.
Просмотр результатов задачи задания dbt
После завершения задания можно протестировать результаты, запустив SQL-запросы из записной книжки или выполнив запросы в хранилище Databricks. Например, ознакомьтесь со следующими примерами запросов:
SHOW tables IN <schema>;
SELECT * from <schema>.customers LIMIT 10;
Замените <schema> именем схемы, настроенным в конфигурации задачи.
Пример API
Api заданий можно также использовать для создания заданий и управления ими, включающих задачи dbt. В следующем примере создается задание с одной задачей dbt:
{
"name": "jaffle_shop dbt job",
"max_concurrent_runs": 1,
"git_source": {
"git_url": "https://github.com/dbt-labs/jaffle_shop",
"git_provider": "gitHub",
"git_branch": "main"
},
"job_clusters": [
{
"job_cluster_key": "dbt_CLI",
"new_cluster": {
"spark_version": "10.4.x-photon-scala2.12",
"node_type_id": "Standard_DS3_v2",
"num_workers": 0,
"spark_conf": {
"spark.master": "local[*, 4]",
"spark.databricks.cluster.profile": "singleNode"
},
"custom_tags": {
"ResourceClass": "SingleNode"
}
}
}
],
"tasks": [
{
"task_key": "transform",
"job_cluster_key": "dbt_CLI",
"dbt_task": {
"commands": [
"dbt deps",
"dbt seed",
"dbt run"
],
"warehouse_id": "1a234b567c8de912"
},
"libraries": [
{
"pypi": {
"package": "dbt-databricks>=1.0.0,<2.0.0"
}
}
]
}
]
}
(Дополнительно) Запуск базы данных с пользовательским профилем
Чтобы выполнить задачу dbt с хранилищем SQL (рекомендуется) или всеми целевыми вычислениями, используйте настраиваемое profiles.yml определение хранилища или вычислений Azure Databricks для подключения. Чтобы создать задание, которое запускает проект магазина jaffle с хранилищем или вычислением всех целей, выполните следующие действия.
Примечание.
В качестве целевого объекта для задачи dbt можно использовать только хранилище SQL или вычислительные ресурсы всех целей. Вы не можете использовать вычисления заданий в качестве целевого объекта для dbt.
Создайте вилку хранилища jaffle_shop.
Клонируйте репозиторий с вилкой на рабочий стол. Например, можно выполнить следующую команду:
git clone https://github.com/<username>/jaffle_shop.gitВместо
<username>укажите дескриптор GitHub.Создайте новый файл, который называется
profiles.ymlв каталогеjaffle_shopсо следующим содержимым:jaffle_shop: target: databricks_job outputs: databricks_job: type: databricks method: http schema: "<schema>" host: "<http-host>" http_path: "<http-path>" token: "{{ env_var('DBT_ACCESS_TOKEN') }}"- Замените
<schema>именем схемы для таблиц проекта. - Чтобы запустить задачу dbt с хранилищем SQL, замените
<http-host>значением имени узла сервера на вкладке сведений о подключении для хранилища SQL. Чтобы выполнить задачу dbt со всеми целевыми вычислениями, замените<http-host>значением имени узла сервера на вкладке "Дополнительные параметры" (JDBC/ODBC ) для вычислений Azure Databricks. - Чтобы запустить задачу dbt с хранилищем SQL, замените
<http-path>значение HTTP-пути на вкладке сведений о подключении для хранилища SQL. Чтобы запустить задачу dbt со всеми целевыми вычислительными ресурсами, замените<http-path>значение HTTP-пути на вкладке "Дополнительные параметры" (JDBC/ODBC) для вычислений Azure Databricks.
Секреты, такие как маркеры доступа, не указываются в файле, так как этот файл будет проверяться в системе управления версиями. Вместо этого этот файл использует функцию шаблонов dbt для динамического вставки учетных данных во время выполнения.
Примечание.
Созданные учетные данные действительны на время выполнения, до 30 дней, и автоматически аннулируются после завершения.
- Замените
Загрузите этот файл в Git и отправьте его в репозиторий с вилкой. Например, можно выполнить следующую команду:
git add profiles.yml git commit -m "adding profiles.yml for my Databricks job" git pushЩелкните
рабочие процессы на боковой панели пользовательского интерфейса Databricks.Выберите задание dbt и нажмите на вкладку "Задачи".
В поле Источник нажмите кнопку Изменить и введите сведения о репозитории с вилкой GitHub магазина jaffle.
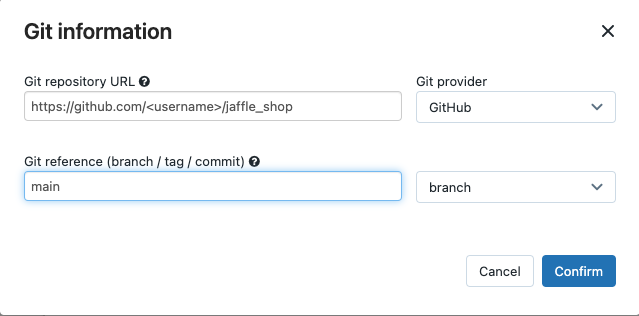
В хранилище SQLвыберите Нет (вручную).
В Каталоге профилей введите относительный путь к каталогу, содержащему файл
profiles.yml. Оставьте значение пути пустым, чтобы использовать корневой каталог репозитория по умолчанию.
(Дополнительно) Использование моделей dbt Python в рабочем процессе
Примечание.
Поддержка dbt для моделей Python находится на этапе бета-тестирования и требует использования dbt 1.3 или более поздней версии.
dbt теперь поддерживает модели Python в определенных хранилищах данных, включая Databricks. С помощью моделей dbt Python можно использовать средства из экосистемы Python для реализации преобразований, которые сложно реализовать с помощью SQL. Вы можете создать задание Azure Databricks для выполнения одной задачи с моделью dbt Python или включить задачу dbt в состав рабочего процесса, включающего несколько задач.
Модели Python нельзя запускать в задаче dbt с помощью хранилища SQL. Для получения более подробной информации об использовании моделей dbt Python с Azure Databricks см. Специальные хранилища данных в документации по dbt.
Ошибки и устранение неполадок
Ошибка Файл профиля не существует
Сообщение об ошибке
dbt looked for a profiles.yml file in /tmp/.../profiles.yml but did not find one.
Возможные причины:
Файл profiles.yml не найден в указанном пути $PATH. Убедитесь, что корневой каталог проекта dbt содержит файл profiles.yml.