Непрерывная интеграция и доставка в Azure Databricks с помощью Azure DevOps
Примечание.
В этой статье рассматриваются Azure DevOps, разработанные сторонними разработчиками. Чтобы связаться с поставщиком, обратитесь в службу поддержки Azure DevOps Services.
В этой статье описано, как настроить автоматизацию Azure DevOps для кода и артефактов, которые работают с Azure Databricks. В частности, вы настроите рабочий процесс непрерывной интеграции и доставки (CI/CD) для подключения к репозиторию Git, запускайте задания с помощью Azure Pipelines для сборки и модульного тестирования колесика Python (*.whl) и развернете его для использования в записных книжках Databricks.
Рабочий процесс разработки CI/CD
Databricks предлагает следующий рабочий процесс для разработки CI/CD с помощью Azure DevOps:
- Создайте репозиторий или используйте существующий репозиторий с сторонним поставщиком Git.
- Подключите локальный компьютер разработки к одному и тому же стороннему репозиторию. Инструкции см. в документации сторонних поставщиков Git.
- Извлеките все существующие обновленные артефакты (например, записные книжки, файлы кода и скрипты сборки) на локальный компьютер разработки из стороннего репозитория.
- При необходимости создайте, обновите и протестируйте артефакты на локальном компьютере разработки. Затем отправьте все новые и измененные артефакты с локального компьютера разработки в сторонний репозиторий. Инструкции см. в документации сторонних поставщиков Git.
- Повторите шаги 3 и 4 по мере необходимости.
- Используйте Azure DevOps периодически в качестве интегрированного подхода к автоматическому извлечению артефактов из стороннего репозитория, сборки, тестирования и выполнения кода в рабочей области Azure Databricks, а также создания отчетов о результатах тестирования и выполнения. Хотя вы можете запускать Azure DevOps вручную в реальных реализациях, вы будете поручать стороннему поставщику Git запускать Azure DevOps каждый раз, когда происходит определенное событие, например запрос на вытягивание репозитория.
Существует множество инструментов CI/CD, которые можно использовать для управления и выполнения конвейера. В этой статье показано, как использовать Azure DevOps. CI/CD — это шаблон проектирования, поэтому шаги и этапы, описанные в примере этой статьи, должны передаваться с несколькими изменениями языка определения конвейера в каждом средстве. Кроме того, большая часть кода в этом примере конвейера является стандартным кодом Python, который можно вызвать в других средствах.
Совет
Сведения об использовании Jenkins с Azure Databricks вместо Azure DevOps см. в статье CI/CD с Jenkins в Azure Databricks.
В остальной части этой статьи описывается пара примеров конвейеров в Azure DevOps, которые можно адаптировать к собственным потребностям Azure Databricks.
Пример
В этом примере используется два конвейера для сбора, развертывания и запуска примера кода Python и записных книжек Python, хранящихся в удаленном репозитории Git.
Первый конвейер, известный как конвейер сборки, подготавливает артефакты сборки для второго конвейера, известного как конвейер выпуска. Разделение конвейера сборки из конвейера выпуска позволяет создавать артефакт сборки без развертывания или одновременного развертывания артефактов из нескольких сборок. Чтобы создать конвейеры сборки и выпуска, выполните следующие действия.
- Создайте виртуальную машину Azure для конвейера сборки.
- Скопируйте файлы из репозитория Git на виртуальную машину.
- Создайте файл tar gzip'ed, содержащий код Python, записные книжки Python и связанные сборки, развертывания и запуска файлов параметров.
- Скопируйте файл tar-файла gzip в виде ZIP-файла в расположение для доступа к конвейеру выпуска.
- Создайте другую виртуальную машину Azure для конвейера выпуска.
- Получите ZIP-файл из расположения конвейера сборки, а затем распакуйте его, чтобы получить код Python, записные книжки Python и связанные файлы настроек сборки, развертывания и выполнения.
- Разверните код Python, записные книжки Python и связанные сборки, развертывания и запуска файлов параметров в удаленной рабочей области Azure Databricks.
- Создайте файлы кода компонентов библиотеки колес Python в файл колесика Python.
- Запустите модульные тесты в коде компонента, чтобы проверить логику в файле колесика Python.
- Запустите записные книжки Python, один из которых вызывает функциональные возможности файла колеса Python.
Сведения о интерфейсе командной строки Databricks
В этом примере показано, как использовать интерфейс командной строки Databricks в неинтерактивном режиме в конвейере. Пример конвейера в этой статье развертывает код, создает библиотеку и запускает записные книжки в рабочей области Azure Databricks.
Если вы используете интерфейс командной строки Databricks в конвейере без реализации примера кода, библиотеки и записных книжек из этой статьи, выполните следующие действия.
Подготовьте рабочую область Azure Databricks для проверки подлинности субъекта-службы с помощью проверки подлинности субъекта-службы на компьютере (M2M). Прежде чем начать, убедитесь, что у вас есть субъект-служба идентификатора Microsoft Entra с секретом OAuth Azure Databricks. См. автоматическую авторизацию для несанкционированного доступа к ресурсам Azure Databricks через сервисный уполномоченный, используя OAuth.
Установите интерфейс командной строки Databricks в конвейере. Для этого добавьте задачу скрипта Bash в конвейер, который запускает следующий скрипт:
curl -fsSL https://raw.githubusercontent.com/databricks/setup-cli/main/install.sh | shЧтобы добавить задачу скрипта Bash в конвейер, см. шаг 3.6. Установите интерфейс командной строки Databricks и средства сборки колес Python.
Настройте конвейер, чтобы включить установленный интерфейс командной строки Databricks для проверки подлинности субъекта-службы в рабочей области. Для этого см . шаг 3.1. Определение переменных среды для конвейера выпуска.
Добавьте дополнительные задачи скрипта Bash в конвейер по мере необходимости для выполнения команд CLI Databricks. См . команды CLI Databricks.
Подготовка к работе
Чтобы использовать пример этой статьи, необходимо:
- Существующий проект Azure DevOps . Если у вас еще нет проекта, создайте проект в Azure DevOps.
- Существующий репозиторий с поставщиком Git, поддерживаемым Azure DevOps. Вы добавите пример кода Python, пример записной книжки Python и связанные файлы параметров выпуска в этот репозиторий. Если у вас еще нет репозитория, создайте его, следуя инструкциям поставщика Git. Затем подключите проект Azure DevOps к этому репозиторию, если это еще не сделано. Инструкции см. по ссылкам в поддерживаемых исходных репозиториях.
- В этом примере используется проверка подлинности OAuth на компьютере (M2M) для проверки подлинности субъекта-службы идентификатора Microsoft Entra в рабочей области Azure Databricks. У вас должен быть субъект-служба идентификатора Microsoft Entra с секретом OAuth Azure Databricks для этого субъекта-службы. См. автоматическая авторизация необслуживаемого доступа к ресурсам Azure Databricks с использованием субъекта-службы в OAuth.
Шаг 1. Добавление файлов примера в репозиторий
На этом шаге в репозитории с сторонним поставщиком Git вы добавите все примеры файлов этой статьи, которые конвейеры Azure DevOps создают, развертывают и запускаются в удаленной рабочей области Azure Databricks.
Шаг 1.1. Добавление файлов компонентов колес Python
В примере этой статьи конвейеры Azure DevOps сборки и модульного тестирования файла колеса Python. Затем записная книжка Azure Databricks вызывает встроенные функции колесика Python.
Чтобы определить логику и модульные тесты для файла колеса Python, с которыми выполняются записные книжки, в корневом каталоге репозитория создайте два файла с именем и addcol.pyдобавьте их в структуру папок с именем test_addcol.pypython/dabdemo/dabdemo в папкеLibraries, визуализированную следующим образом:
└── Libraries
└── python
└── dabdemo
└── dabdemo
├── addcol.py
└── test_addcol.py
Файл addcol.py содержит функцию библиотеки, которая встроена позже в файл колесика Python, а затем установлена в кластерах Azure Databricks. Это простая функция, которая добавляет новый столбец, заполненный литералом, в DataFrame Apache Spark.
# Filename: addcol.py
import pyspark.sql.functions as F
def with_status(df):
return df.withColumn("status", F.lit("checked"))
Файл test_addcol.py содержит тесты для передачи объекта mock DataFrame в функцию, определенную with_status в addcol.py. Затем результат сравнивается с объектом DataFrame, содержащим ожидаемые значения. Если значения совпадают, тест проходит:
# Filename: test_addcol.py
import pytest
from pyspark.sql import SparkSession
from dabdemo.addcol import *
class TestAppendCol(object):
def test_with_status(self):
spark = SparkSession.builder.getOrCreate()
source_data = [
("paula", "white", "paula.white@example.com"),
("john", "baer", "john.baer@example.com")
]
source_df = spark.createDataFrame(
source_data,
["first_name", "last_name", "email"]
)
actual_df = with_status(source_df)
expected_data = [
("paula", "white", "paula.white@example.com", "checked"),
("john", "baer", "john.baer@example.com", "checked")
]
expected_df = spark.createDataFrame(
expected_data,
["first_name", "last_name", "email", "status"]
)
assert(expected_df.collect() == actual_df.collect())
Чтобы разрешить Databricks CLI правильно упаковать этот код библиотеки в файл колесика Python, создайте два файла с именем __init__.py и в той же папке, что и __main__.py предыдущие два файла. Кроме того, создайте файл с именем setup.py в папке python/dabdemo , визуализируемый следующим образом:
└── Libraries
└── python
└── dabdemo
├── dabdemo
│ ├── __init__.py
│ ├── __main__.py
│ ├── addcol.py
│ └── test_addcol.py
└── setup.py
Файл __init__.py содержит номер версии библиотеки и его автор. Замените <my-author-name> своим именем:
# Filename: __init__.py
__version__ = '0.0.1'
__author__ = '<my-author-name>'
import sys, os
sys.path.append(os.path.join(os.path.dirname(__file__), "..", ".."))
Файл __main__.py содержит точку входа библиотеки:
# Filename: __main__.py
import sys, os
sys.path.append(os.path.join(os.path.dirname(__file__), "..", ".."))
from addcol import *
def main():
pass
if __name__ == "__main__":
main()
Файл setup.py содержит дополнительные параметры для создания библиотеки в файл колесика Python. Замените <my-url>, <my-author-name>@<my-organization>и <my-package-description> допустимыми значениями:
# Filename: setup.py
from setuptools import setup, find_packages
import dabdemo
setup(
name = "dabdemo",
version = dabdemo.__version__,
author = dabdemo.__author__,
url = "https://<my-url>",
author_email = "<my-author-name>@<my-organization>",
description = "<my-package-description>",
packages = find_packages(include = ["dabdemo"]),
entry_points={"group_1": "run=dabdemo.__main__:main"},
install_requires = ["setuptools"]
)
Шаг 1.2. Добавление записной книжки модульного тестирования для файла колеса Python
Позже интерфейс командной строки Databricks запускает задание записной книжки. Это задание запускает записную книжку Python с именем run_unit_tests.pyфайла. Эта записная книжка выполняется pytest в логике библиотеки колес Python.
Чтобы выполнить модульные тесты для примера этой статьи, добавьте в корневой каталог репозитория файл записной книжки с именем run_unit_tests.py следующего содержимого:
# Databricks notebook source
# COMMAND ----------
# MAGIC %sh
# MAGIC
# MAGIC mkdir -p "/Workspace${WORKSPACEBUNDLEPATH}/Validation/reports/junit/test-reports"
# COMMAND ----------
# Prepare to run pytest.
import sys, pytest, os
# Skip writing pyc files on a readonly filesystem.
sys.dont_write_bytecode = True
# Run pytest.
retcode = pytest.main(["--junit-xml", f"/Workspace{os.getenv('WORKSPACEBUNDLEPATH')}/Validation/reports/junit/test-reports/TEST-libout.xml",
f"/Workspace{os.getenv('WORKSPACEBUNDLEPATH')}/files/Libraries/python/dabdemo/dabdemo/"])
# Fail the cell execution if there are any test failures.
assert retcode == 0, "The pytest invocation failed. See the log for details."
Шаг 1.3. Добавление записной книжки, которая вызывает файл колесика Python
Позже интерфейс командной строки Databricks запускает другое задание записной книжки. Эта записная книжка создает объект DataFrame, передает его в функцию библиотеки with_status колес Python, выводит результат и сообщает результаты выполнения задания. Создайте корневой каталог репозитория в файле dabdemo_notebook.py записной книжки с указанным ниже содержимым:
# Databricks notebook source
# COMMAND ----------
# Restart Python after installing the Python wheel.
dbutils.library.restartPython()
# COMMAND ----------
from dabdemo.addcol import with_status
df = (spark.createDataFrame(
schema = ["first_name", "last_name", "email"],
data = [
("paula", "white", "paula.white@example.com"),
("john", "baer", "john.baer@example.com")
]
))
new_df = with_status(df)
display(new_df)
# Expected output:
#
# +------------+-----------+-------------------------+---------+
# │ first_name │ last_name │ email │ status │
# +============+===========+=========================+=========+
# │ paula │ white │ paula.white@example.com │ checked │
# +------------+-----------+-------------------------+---------+
# │ john │ baer │ john.baer@example.com │ checked │
# +------------+-----------+-------------------------+---------+
Шаг 1.4. Создание конфигурации пакета
В примере этой статьи используются пакеты ресурсов Databricks для определения параметров и поведения для создания, развертывания и запуска файла колеса Python, двух записных книжек и файла кода Python. Наборы ресурсов Databricks, известные как пакеты, позволяют выразить полные данные, аналитику и проекты машинного обучения в виде коллекции исходных файлов. См. раздел "Что такое пакеты ресурсов Databricks?".
Чтобы настроить пакет для примера этой статьи, создайте в корне репозитория файл с именем databricks.yml. В этом примере databricks.yml файла замените следующие заполнители:
- Замените
<bundle-name>уникальным программным именем пакета. Например,azure-devops-demo. - Замените
<job-prefix-name>на некоторую строку, чтобы однозначно определить задания, созданные в рабочей области Azure Databricks в этом примере. Например,azure-devops-demo. - Замените
<spark-version-id>идентификатором версии databricks Runtime для кластеров заданий, например13.3.x-scala2.12. - Замените
<cluster-node-type-id>идентификатором типа узла кластера для кластеров заданий, напримерStandard_DS3_v2. - Обратите внимание, что
devвtargetsсопоставлении указывается узел и связанное поведение развертывания. В реальных реализациях вы можете дать этому целевому объекту другое имя в собственных пакетах.
Ниже приведено содержимое файла этого примера databricks.yml :
# Filename: databricks.yml
bundle:
name: <bundle-name>
variables:
job_prefix:
description: A unifying prefix for this bundle's job and task names.
default: <job-prefix-name>
spark_version:
description: The cluster's Spark version ID.
default: <spark-version-id>
node_type_id:
description: The cluster's node type ID.
default: <cluster-node-type-id>
artifacts:
dabdemo-wheel:
type: whl
path: ./Libraries/python/dabdemo
resources:
jobs:
run-unit-tests:
name: ${var.job_prefix}-run-unit-tests
tasks:
- task_key: ${var.job_prefix}-run-unit-tests-task
new_cluster:
spark_version: ${var.spark_version}
node_type_id: ${var.node_type_id}
num_workers: 1
spark_env_vars:
WORKSPACEBUNDLEPATH: ${workspace.root_path}
notebook_task:
notebook_path: ./run_unit_tests.py
source: WORKSPACE
libraries:
- pypi:
package: pytest
run-dabdemo-notebook:
name: ${var.job_prefix}-run-dabdemo-notebook
tasks:
- task_key: ${var.job_prefix}-run-dabdemo-notebook-task
new_cluster:
spark_version: ${var.spark_version}
node_type_id: ${var.node_type_id}
num_workers: 1
spark_env_vars:
WORKSPACEBUNDLEPATH: ${workspace.root_path}
notebook_task:
notebook_path: ./dabdemo_notebook.py
source: WORKSPACE
libraries:
- whl: "/Workspace${workspace.root_path}/files/Libraries/python/dabdemo/dist/dabdemo-0.0.1-py3-none-any.whl"
targets:
dev:
mode: development
Дополнительные сведения о синтаксисе databricks.yml файла см. в разделе "Конфигурация пакета ресурсов Databricks".
Шаг 2. Определение конвейера сборки
Azure DevOps предоставляет пользовательский интерфейс, размещенный в облаке, для определения этапов конвейера CI/CD с помощью YAML. Дополнительные сведения о Azure DevOps и конвейерах см. в документации по Azure DevOps.
На этом шаге для определения конвейера сборки используется разметка YAML, которая создает артефакт развертывания. Чтобы развернуть код в рабочей области Azure Databricks, необходимо указать артефакт сборки этого конвейера в качестве входных данных в конвейер выпуска. Вы определите этот конвейер выпуска позже.
Для запуска конвейеров сборки Azure DevOps предоставляет облачные агенты выполнения по запросу, поддерживающие развертывания в Kubernetes, виртуальных машинах, Функции Azure, Azure веб-приложения и многих других целевых объектах. В этом примере для автоматизации создания артефакта развертывания используется агент по запросу.
Определите пример конвейера сборки этой статьи следующим образом:
Войдите в Azure DevOps и щелкните ссылку входа , чтобы открыть проект Azure DevOps.
Примечание.
Если портал Azure отображается вместо проекта Azure DevOps, щелкните "Другие службы > Azure DevOps" организации > My Azure DevOps, а затем откройте проект Azure DevOps.
Щелкните "Конвейеры" на боковой панели и выберите "Конвейеры" в меню "Конвейеры".
Нажмите кнопку "Создать конвейер" и следуйте инструкциям на экране. (Если у вас уже есть конвейеры, щелкните Создайте конвейер вместо этого.) В конце этих инструкций откроется редактор конвейера. Здесь вы определяете скрипт конвейера сборки в
azure-pipelines.ymlпоявившемся файле. Если редактор конвейера не отображается в конце инструкций, выберите имя конвейера сборки и щелкните Изменить.Вы можете использовать селектор
 ветви Git для настройки процесса сборки для каждой ветви в репозитории Git. Рекомендуется не выполнять рабочую работу непосредственно в ветви репозитория
ветви Git для настройки процесса сборки для каждой ветви в репозитории Git. Рекомендуется не выполнять рабочую работу непосредственно в ветви репозитория main. В этом примере предполагается, что в репозитории существует ветвьrelease, которая будет использоваться вместоmain.
azure-pipelines.ymlСкрипт конвейера сборки хранится по умолчанию в корневом каталоге удаленного репозитория Git, сопоставленном с конвейером.Перезапись начального содержимого файла конвейера
azure-pipelines.ymlс помощью следующего определения и нажмите кнопку "Сохранить".# Specify the trigger event to start the build pipeline. # In this case, new code merged into the release branch initiates a new build. trigger: - release # Specify the operating system for the agent that runs on the Azure virtual # machine for the build pipeline (known as the build agent). The virtual # machine image in this example uses the Ubuntu 22.04 virtual machine # image in the Azure Pipeline agent pool. See # https://learn.microsoft.com/azure/devops/pipelines/agents/hosted#software pool: vmImage: ubuntu-22.04 # Download the files from the designated branch in the remote Git repository # onto the build agent. steps: - checkout: self persistCredentials: true clean: true # Generate the deployment artifact. To do this, the build agent gathers # all the new or updated code to be given to the release pipeline, # including the sample Python code, the Python notebooks, # the Python wheel library component files, and the related Databricks asset # bundle settings. # Use git diff to flag files that were added in the most recent Git merge. # Then add the files to be used by the release pipeline. # The implementation in your pipeline will likely be different. # The objective here is to add all files intended for the current release. - script: | git diff --name-only --diff-filter=AMR HEAD^1 HEAD | xargs -I '{}' cp --parents -r '{}' $(Build.BinariesDirectory) mkdir -p $(Build.BinariesDirectory)/Libraries/python/dabdemo/dabdemo cp $(Build.Repository.LocalPath)/Libraries/python/dabdemo/dabdemo/*.* $(Build.BinariesDirectory)/Libraries/python/dabdemo/dabdemo cp $(Build.Repository.LocalPath)/Libraries/python/dabdemo/setup.py $(Build.BinariesDirectory)/Libraries/python/dabdemo cp $(Build.Repository.LocalPath)/*.* $(Build.BinariesDirectory) displayName: 'Get Changes' # Create the deployment artifact and then publish it to the # artifact repository. - task: ArchiveFiles@2 inputs: rootFolderOrFile: '$(Build.BinariesDirectory)' includeRootFolder: false archiveType: 'zip' archiveFile: '$(Build.ArtifactStagingDirectory)/$(Build.BuildId).zip' replaceExistingArchive: true - task: PublishBuildArtifacts@1 inputs: ArtifactName: 'DatabricksBuild'
Шаг 3. Определение конвейера выпуска
Конвейер выпуска развертывает артефакты сборки из конвейера сборки в среду Azure Databricks. Разделение конвейера выпуска на этом шаге от конвейера сборки на предыдущих шагах позволяет создавать сборку, не развертывая ее или развертывая артефакты из нескольких сборок одновременно.
В проекте Azure DevOps в меню "Конвейеры " на боковой панели щелкните " Выпуски".
Нажмите кнопку "Создать > конвейер выпуска". (Если у вас уже есть конвейеры, щелкните Вместо этого новый конвейер .)
На стороне экрана отображается список шаблонов, используемых для распространенных шаблонов развертывания. В этом примере конвейер выпуска щелкните
 .
.
В поле "Артефакты" на боковой части экрана нажмите кнопку
 . В области Добавление артефакта для Источник (конвейер сборки)выберите созданный ранее конвейер сборки. Нажмите кнопку Добавить.
. В области Добавление артефакта для Источник (конвейер сборки)выберите созданный ранее конвейер сборки. Нажмите кнопку Добавить.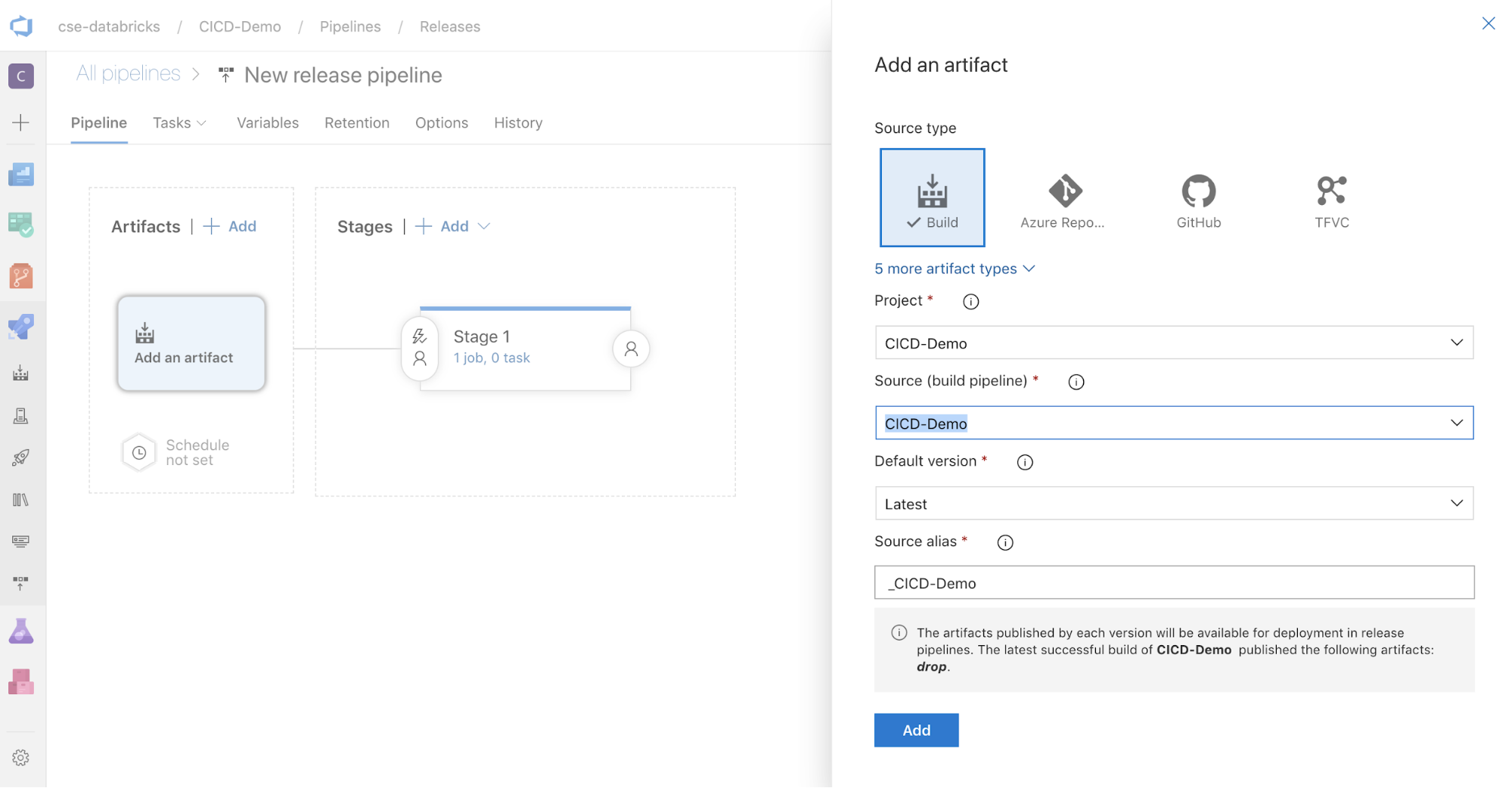
Вы можете настроить активацию конвейера, щелкнув
 , чтобы отобразить параметры активации на стороне экрана. Если требуется автоматически запускать выпуск на основе доступности артефактов сборки или после рабочего процесса запроса на вытягивание, включите соответствующий триггер. В этом примере на последнем шаге этой статьи вы вручную активируете конвейер сборки, а затем конвейер выпуска.
, чтобы отобразить параметры активации на стороне экрана. Если требуется автоматически запускать выпуск на основе доступности артефактов сборки или после рабочего процесса запроса на вытягивание, включите соответствующий триггер. В этом примере на последнем шаге этой статьи вы вручную активируете конвейер сборки, а затем конвейер выпуска.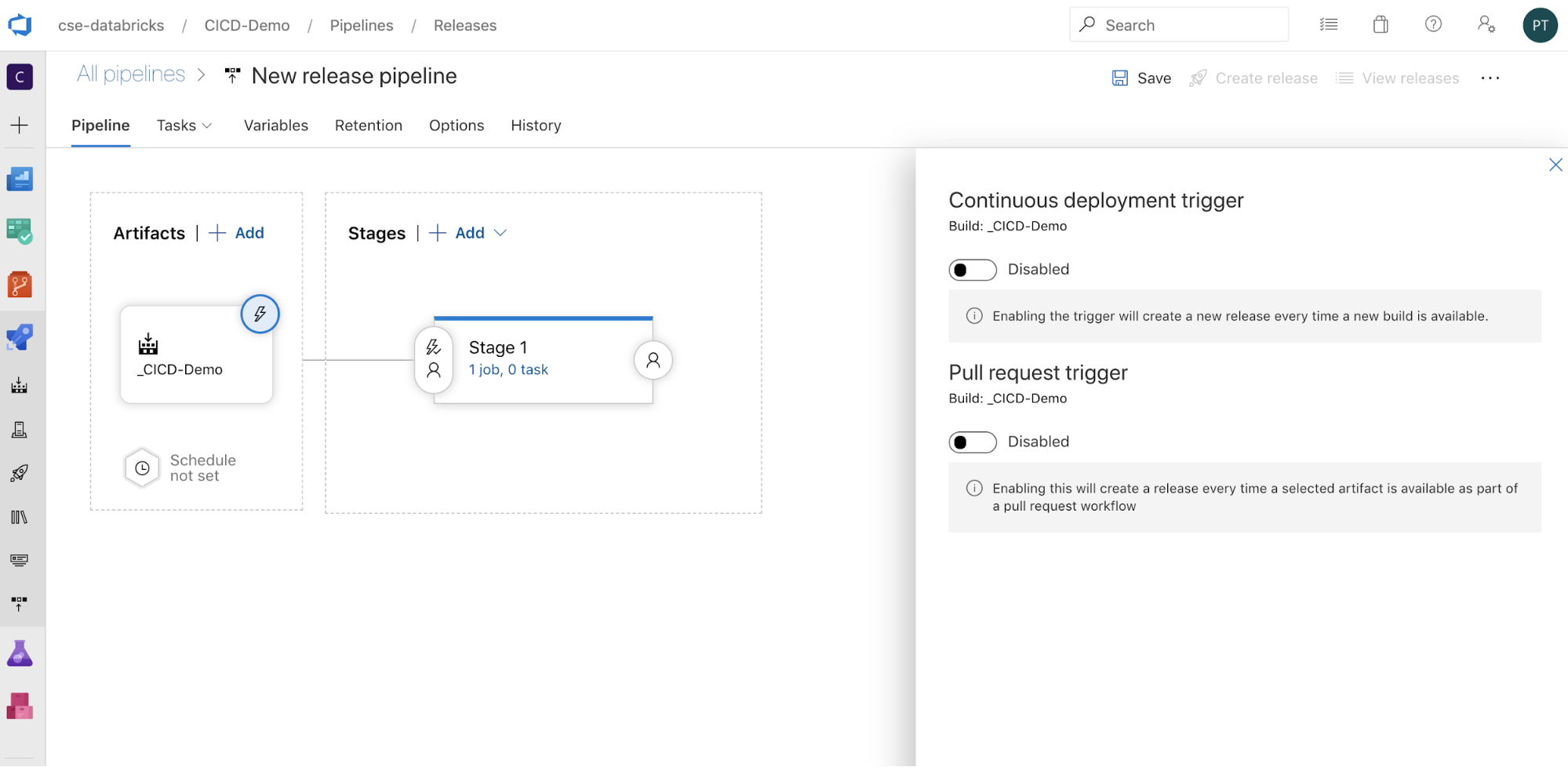
Нажмите кнопку "Сохранить > ОК".
Шаг 3.1. Определение переменных среды для конвейера выпуска
Конвейер выпуска этого примера зависит от следующих переменных среды, которые можно добавить, щелкнув "Добавить" в разделе "Переменные конвейера" на вкладке "Переменные" с областьюэтапа 1:
-
BUNDLE_TARGET, который должен соответствоватьtargetимени вdatabricks.ymlфайле. В примере этой статьи это .dev -
DATABRICKS_HOST— это URL-адрес рабочей области для рабочей области Azure Databricks, начиная сhttps://примераhttps://adb-<workspace-id>.<random-number>.azuredatabricks.net. Не включайте конечный после/.net. -
DATABRICKS_CLIENT_ID— это идентификатор приложения для субъекта-службы Microsoft Entra ID. -
DATABRICKS_CLIENT_SECRET, представляющий секрет OAuth Azure Databricks для субъекта-службы идентификатора Microsoft Entra.
Шаг 3.2. Настройка агента выпуска для конвейера выпуска
Щелкните ссылку на задание 1, 0 в объекте Stage 1 .
На вкладке "Задачи" щелкните задание агента.
В разделе выбора агента
дляпула агентов выберите Azure Pipelines. Для спецификации агентавыберите тот же агент, что и для агента сборки ранее, в этом примере ubuntu-22.04.
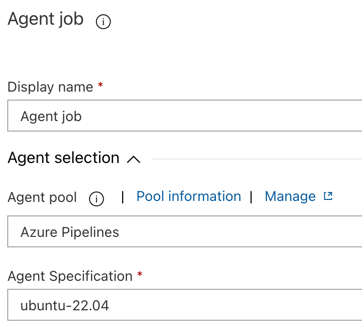
Нажмите кнопку "Сохранить > ОК".
Шаг 3.3. Установка версии Python для агента выпуска
Щелкните значок "плюс" в разделе задания агента, указанный красной стрелкой на следующем рисунке. Появится список доступных задач, доступных для поиска. Существует также вкладка Marketplace для сторонних подключаемых модулей, которые можно использовать для дополнения стандартных задач Azure DevOps. Во время следующих действий вы добавите несколько задач в агент выпуска.
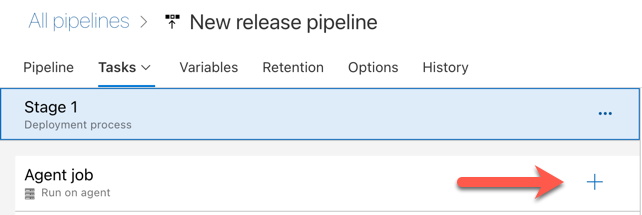
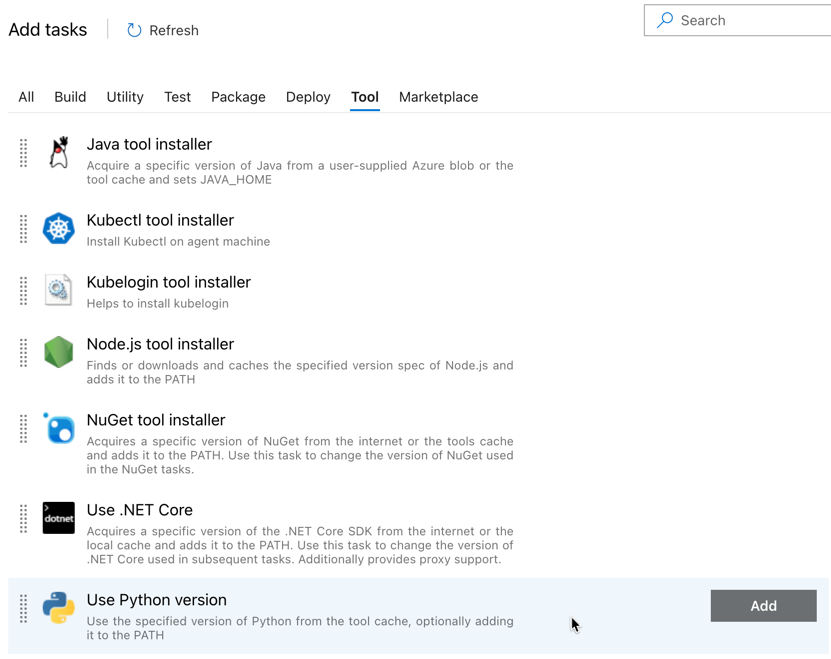
Первая задача, добавляемая, — использовать версию Python, расположенную на вкладке "Инструмент ". Если вы не можете найти эту задачу, используйте поле поиска для поиска. Найдите его, выберите его и нажмите кнопку Добавить рядом с задачей Использовать версию Python.
Как и в случае с конвейером сборки, необходимо убедиться, что версия Python совместима со скриптами, которые вызываются в последующих задачах. В этом случае щелкните задачу
Использовать Python 3.x рядом с заданием агента, а затем установите для спецификации версии значение . Также установите отображаемое имя Use Python 3.10. В этом конвейере предполагается, что вы используете Databricks Runtime 13.3 LTS в кластерах, на которых установлен Python 3.10.12.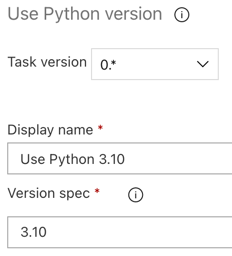
Нажмите кнопку "Сохранить > ОК".
Шаг 3.4. Распаковка артефакта сборки из конвейера сборки
Затем агент выпуска извлекает файл колесика Python, связанные файлы параметров выпуска, записные книжки и файл кода Python из ZIP-файла с помощью задачи Извлечения файлов: щелкните значок плюса в разделе задания агента , выберите задачу извлечь файлы на вкладке служебной программы, и нажмите кнопку Добавить.
Щелкните задачу Извлечь файлы рядом с заданием агента, установите шаблоны архивных файлов на
**/*.zipи установите папку назначения на системную переменную$(Release.PrimaryArtifactSourceAlias)/Databricks. Также установите отображаемое имяExtract build pipeline artifact.Примечание.
$(Release.PrimaryArtifactSourceAlias)представляет псевдоним, созданный Azure DevOps, для идентификации основного исходного расположения артефакта в агенте выпуска, например_<your-github-alias>.<your-github-repo-name>. Конвейер выпуска задает это значение в качестве переменнойRELEASE_PRIMARYARTIFACTSOURCEALIASсреды на этапе задания инициализации агента выпуска. См . классические переменные выпуска и артефактов.Задайте отображаемого имени
значение . 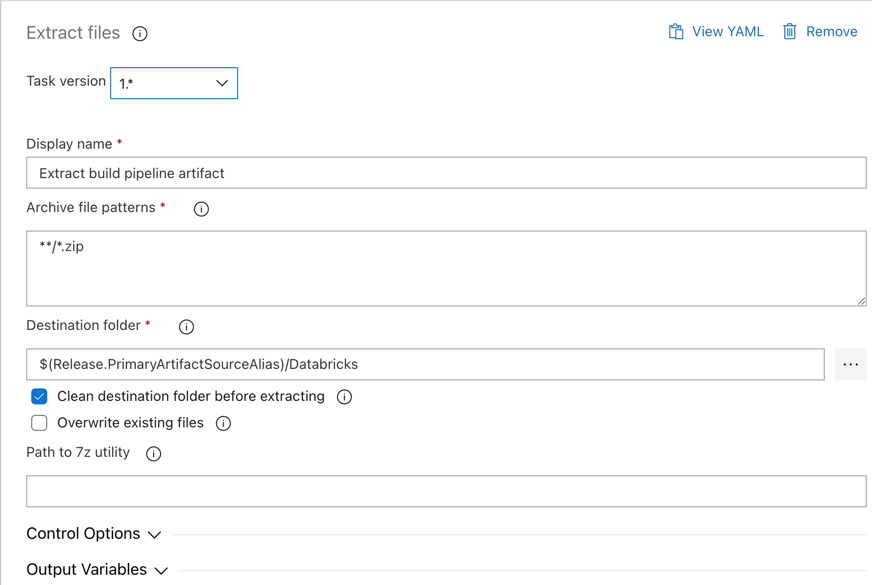
Нажмите кнопку "Сохранить > ОК".
Шаг 3.5. Установка переменной среды BUNDLE_ROOT
Чтобы пример этой статьи работал должным образом, необходимо задать переменную среды с именем BUNDLE_ROOT в конвейере выпуска. Наборы ресурсов Databricks используют эту переменную среды для определения расположения databricks.yml файла. Чтобы задать эту переменную среды, выполните указанные ниже действия.
Используйте задачу переменных среды
: в разделе задания агента переменных средывыберите задачу и нажмите кнопку Добавить .Примечание.
Если задача переменных среды не отображается на вкладке служебная программа, введите
Environment Variablesв поле поиска и следуйте инструкциям на экране, чтобы добавить задачу на вкладку служебной программы. Это может потребовать выйти из Azure DevOps, а затем вернуться в это место, где вы остановились.Для переменных среды (разделенные запятыми)введите следующее определение:
BUNDLE_ROOT=$(Agent.ReleaseDirectory)/$(Release.PrimaryArtifactSourceAlias)/DatabricksПримечание.
$(Agent.ReleaseDirectory)представляет псевдоним, созданный Azure DevOps, чтобы определить расположение каталога выпуска агента выпуска, например/home/vsts/work/r1/a. Конвейер выпуска задает это значение в качестве переменнойAGENT_RELEASEDIRECTORYсреды на этапе задания инициализации агента выпуска. См . классические переменные выпуска и артефактов. Дополнительные сведения см$(Release.PrimaryArtifactSourceAlias). в заметке на предыдущем шаге.Задайте отображаемого имени
значение . 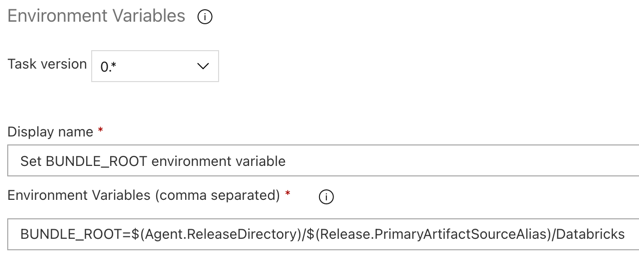
Нажмите кнопку "Сохранить > ОК".
Шаг 3.6. Установка средств сборки колес Databricks и Python
Затем установите интерфейс командной строки Databricks и средства сборки колес Python в агенте выпуска. Агент выпуска вызовет средства сборки колес Databricks и Python в следующих нескольких задачах. Для этого используйте задачу Bash: снова нажмите 'плюс' в разделе задания агента, выберите задачу Bash на вкладке Утилиты, а затем нажмите Добавить.
Щелкните задачу скрипта Bash рядом с заданием агента.
Для типа выберите встроенный .
Замените содержимое скрипта следующей командой, которая устанавливает интерфейс командной строки Databricks и средства сборки колес Python:
curl -fsSL https://raw.githubusercontent.com/databricks/setup-cli/main/install.sh | sh pip install wheelЗадайте отображаемого имени
значение . 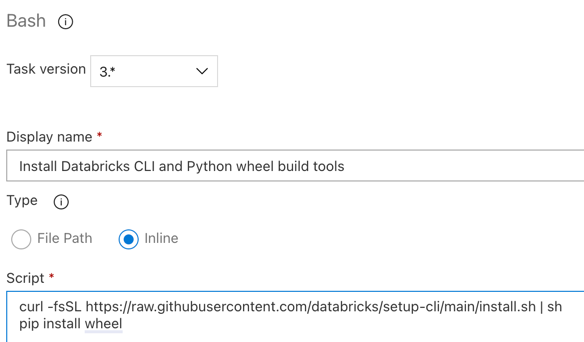
Нажмите кнопку "Сохранить > ОК".
Шаг 3.7. Проверка пакета активов Databricks
На этом шаге необходимо убедиться, что databricks.yml файл синтаксически правильно.
Используйте задачу Bash: нажмите кнопку «Плюс» еще раз в разделе задания агента , выберите задачу Bash на вкладке служебные программы и нажмите кнопку Добавить.
Щелкните задачу скрипта Bash рядом с заданием агента.
Для типа выберите встроенный .
Замените содержимое скрипта следующей командой, которая использует интерфейс командной строки Databricks для проверки правильности
databricks.ymlфайла:databricks bundle validate -t $(BUNDLE_TARGET)Задайте отображаемого имени
значение . Нажмите кнопку "Сохранить > ОК".
Шаг 3.8. Развертывание пакета
На этом шаге вы создадите файл колесика Python и развернете созданный файл колесика Python, две записные книжки Python и файл Python из конвейера выпуска в рабочую область Azure Databricks.
Используйте задачу Bash: нажмите кнопку «Плюс» еще раз в разделе задания агента , выберите задачу Bash на вкладке служебные программы и нажмите кнопку Добавить.
Щелкните задачу скрипта Bash рядом с заданием агента.
Для типа выберите встроенный .
Замените содержимое скрипта следующей командой, которая использует интерфейс командной строки Databricks для сборки файла колес Python и развертывания примеров файлов этой статьи из конвейера выпуска в рабочей области Azure Databricks:
databricks bundle deploy -t $(BUNDLE_TARGET)Задайте отображаемого имени
значение . Нажмите кнопку "Сохранить > ОК".
Шаг 3.9. Запуск записной книжки модульного теста для колеса Python
На этом шаге вы запустите задание, которое запускает записную книжку модульного теста в рабочей области Azure Databricks. Эта записная книжка выполняет модульные тесты в логике библиотеки колес Python.
Используйте задачу Bash: нажмите кнопку «Плюс» еще раз в разделе задания агента , выберите задачу Bash на вкладке служебные программы и нажмите кнопку Добавить.
Щелкните задачу скрипта Bash рядом с заданием агента.
Для типа выберите встроенный .
Замените содержимое скрипта следующей командой, которая использует интерфейс командной строки Databricks для запуска задания в рабочей области Azure Databricks:
databricks bundle run -t $(BUNDLE_TARGET) run-unit-testsЗадайте отображаемого имени
значение . Нажмите кнопку "Сохранить > ОК".
Шаг 3.10. Запустите записную книжку, которая вызывает колесо Python
На этом шаге вы запустите задание, которое запускает другую записную книжку в рабочей области Azure Databricks. Эта записная книжка вызывает библиотеку колес Python.
Используйте задачу Bash: нажмите кнопку «Плюс» еще раз в разделе задания агента , выберите задачу Bash на вкладке служебные программы и нажмите кнопку Добавить.
Щелкните задачу скрипта Bash рядом с заданием агента.
Для типа выберите встроенный .
Замените содержимое скрипта следующей командой, которая использует интерфейс командной строки Databricks для запуска задания в рабочей области Azure Databricks:
databricks bundle run -t $(BUNDLE_TARGET) run-dabdemo-notebookЗадайте отображаемого имени
значение . Нажмите кнопку "Сохранить > ОК".
Теперь вы завершили настройку конвейера выпуска. Он должен выглядеть следующим образом:
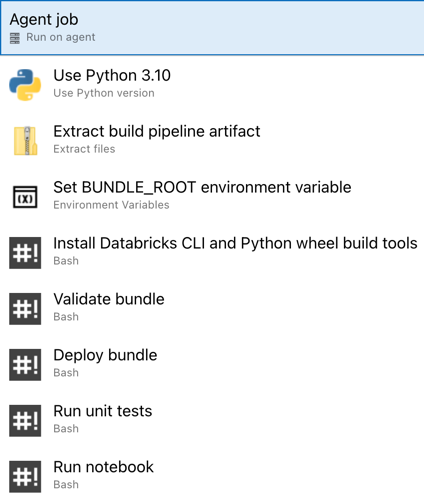
Шаг 4. Запуск конвейеров сборки и выпуска
На этом шаге конвейеры выполняются вручную. Сведения о том, как автоматически запускать конвейеры, см. в разделе "Указание событий, которые активируют конвейеры и триггеры выпуска".
Чтобы запустить конвейер сборки вручную, выполните следующие действия.
- В меню "Конвейеры" на боковой панели щелкните "Конвейеры".
- Щелкните имя конвейера сборки и нажмите кнопку "Выполнить конвейер".
- Для Ветви или тегавыберите имя ветви в репозитории Git, содержащей весь добавленный исходный код. В этом примере предполагается, что это ветвь
release. - Щелкните Выполнить. Откроется страница запуска конвейера сборки.
- Чтобы просмотреть ход выполнения конвейера сборки и просмотреть связанные журналы, щелкните значок спиннинга рядом с заданием.
- После того как значок задания перейдет на зеленый флажок, перейдите к запуску конвейера выпуска.
Чтобы запустить конвейер выпуска вручную, выполните следующие действия.
- После успешного выполнения конвейера сборки в меню "Конвейеры " на боковой панели нажмите кнопку " Выпуски".
- Щелкните имя конвейера выпуска и нажмите кнопку "Создать выпуск".
- Нажмите кнопку Создать.
- Чтобы просмотреть ход выполнения конвейера выпуска, в списке выпусков щелкните имя последнего выпуска.
- В поле "Этапы" нажмите кнопку "Этап 1" и щелкните "Журналы".