Настройка Delta Lake для управления размером файла данных
Примечание.
Рекомендации, приведенные в этой статье, не применяются к управляемым таблицам каталога Unity. Databricks рекомендует использовать управляемые таблицы каталога Unity с параметрами по умолчанию для всех новых таблиц Delta.
В Databricks Runtime 13.3 и более поздних версиях Databricks рекомендует использовать кластеризацию для макета таблицы Delta. См. Использование кластеризации жидкости для таблиц Delta.
Databricks рекомендует использовать прогнозную оптимизацию для автоматического запуска OPTIMIZE и VACUUM для таблиц Delta. См. прогнозную оптимизацию для управляемых каталогом Unity таблиц.
В Databricks Runtime 10.4 LTS и более поздних версиях автоматическое сжатие и оптимизированная запись всегда включены для операций MERGE, UPDATE, и DELETE. Вы не можете отключить эту функцию.
Delta Lake предоставляет параметры для ручной или автоматической настройки целевого размера файла для записи и операций OPTIMIZE. Azure Databricks автоматически настраивает многие из этих параметров и включает функции, которые автоматически повышают производительность таблицы, стремясь к правильным файлам размера.
Для управляемых таблиц каталога Unity Databricks настраивает большинство этих конфигураций автоматически, если вы используете хранилище SQL или Databricks Runtime 11.3 LTS или более поздней версии.
Если вы обновляете рабочую нагрузку с версии Databricks Runtime 10.4 LTS или ниже, см. раздел "Обновление до фонового автоматического сжатия".
Когда следует запустить OPTIMIZE
Автоматическое сжатие и оптимизированные записи уменьшают проблемы, связанные с небольшими файлами, но не являются полной заменой для OPTIMIZE. Особенно для таблиц размером более 1 ТБ, Databricks рекомендует запускать OPTIMIZE в расписании для дальнейшего консолидации файлов. Azure Databricks не запускает автоматически ZORDER на таблицах, поэтому необходимо выполнить OPTIMIZE с помощью ZORDER, чтобы включить улучшенное пропускание данных. Смотрите сведения о пропусках данных для Delta Lake.
Что такое автоматическая оптимизация в Azure Databricks?
Термин автоматическая оптимизация иногда используется для описания функциональности, контролируемой параметрами delta.autoOptimize.autoCompact и delta.autoOptimize.optimizeWrite. Этот термин был заменён в пользу отдельного описания настроек. См. "Автоматическое сжатие для Delta Lake в Azure Databricks" и "Оптимизированные записи для Delta Lake в Azure Databricks".
Автоматическое сжатие для Delta Lake в Azure Databricks
Автоматическое сжатие объединяет небольшие файлы в секциях таблиц Delta, чтобы автоматически уменьшить проблемы с небольшими файлами. Автоматическое сжатие происходит после успешной записи в таблицу и выполняется синхронно в кластере, который выполнил запись. Автоматическое сжатие только сжимает файлы, которые ранее не были сжаты.
Размер выходного файла можно контролировать, задав конфигурациюspark.databricks.delta.autoCompact.maxFileSizeSpark. Databricks рекомендует использовать автоматическую настройку на основе рабочей нагрузки или размера таблицы. См. размер файла Autotune на основе рабочей нагрузки и размера файла Autotune на основе размера таблицы.
Автоматическое сжатие активируется только для секций или таблиц, имеющих по крайней мере определенное количество небольших файлов. При необходимости можно изменить минимальное количество файлов, необходимых для активации автоматического сжатия, задав параметр spark.databricks.delta.autoCompact.minNumFiles.
Автоматическое сжатие можно включить на уровне таблицы или сеанса с помощью следующих параметров:
- Свойство таблицы:
delta.autoOptimize.autoCompact - Параметр SparkSession:
spark.databricks.delta.autoCompact.enabled
Эти параметры принимают следующие опции:
| Параметры | Поведение |
|---|---|
auto (рекомендуется) |
Настраивает целевой размер файла при соблюдении других функций автоматической настройки. Требуется Databricks Runtime 10.4 LTS или более поздней версии. |
legacy |
Псевдоним для true. Требуется Databricks Runtime 10.4 LTS или более поздней версии. |
true |
Используйте 128 МБ в качестве целевого размера файла. Отсутствует динамическое изменение размера. |
false |
Отключает автоматическое сжатие. Можно задать на уровне сеанса для отключения автоматического сжатия для всех таблиц Delta, которые были изменены в рабочей нагрузке. |
Внимание
В Databricks Runtime 9.1 LTS, когда другие записи выполняют такие операции, как DELETE, MERGE, UPDATE или OPTIMIZE параллельно, автоматическое сжатие может привести к сбою других заданий с конфликтом транзакций. Это не проблема в Databricks Runtime 10.4 LTS и выше.
Оптимизированные записи для Delta Lake на платформе Azure Databricks
Оптимизированные операции записи уменьшают размер файла, поскольку данные записываются и улучшают последующие операции чтения в таблице.
Оптимизированные записи наиболее эффективны для секционированных таблиц, так как они снижают количество небольших файлов, записанных в каждую секцию. Запись меньше больших файлов эффективнее, чем запись нескольких небольших файлов, но вы по-прежнему можете увидеть увеличение задержки записи, так как данные перемешиваются перед записью.
На следующем рисунке показано, как работает оптимизированная запись:
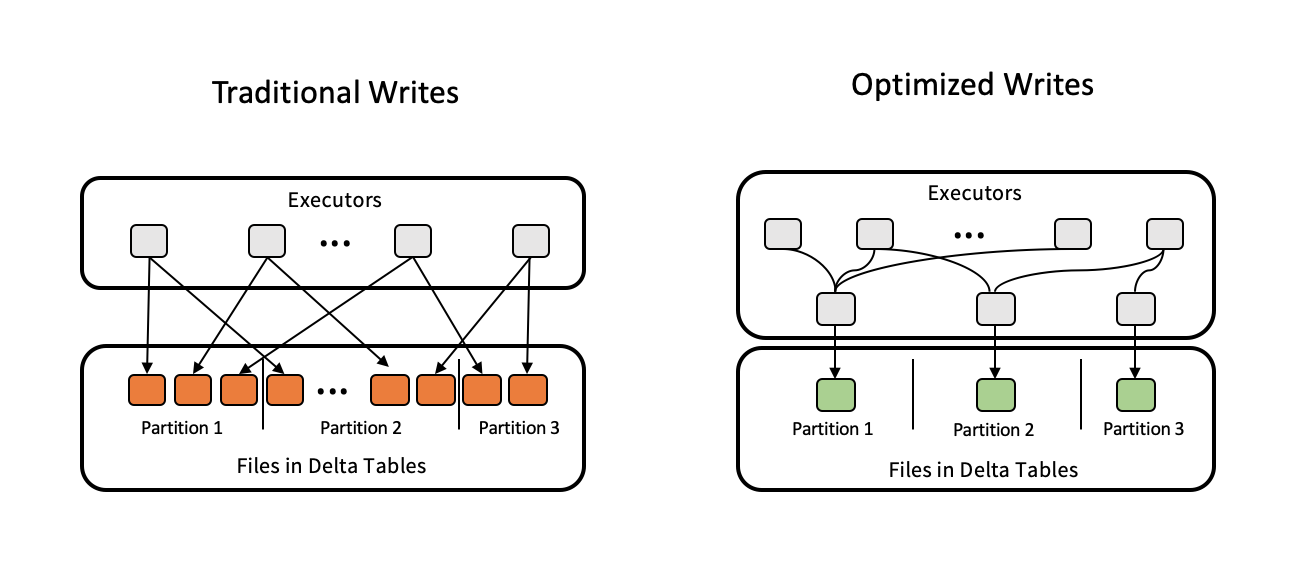
Примечание.
Возможно, у вас есть код, который запускается coalesce(n) или repartition(n) незадолго до записи данных для управления количеством записанных файлов. Оптимизированные операции записи устраняют необходимость использования этого шаблона.
Оптимизированные записи включены по умолчанию для следующих операций в Databricks Runtime 9.1 LTS и выше:
MERGE-
UPDATEс вложенными запросами -
DELETEс вложенными запросами
Оптимизированные операции записи также включены для CTAS инструкций и INSERT операций при использовании хранилищ SQL. В Databricks Runtime 13.3 LTS и более поздних версиях для всех таблиц Delta, зарегистрированных в Unity Catalog, активированы оптимизированные записи для инструкций CTAS и операций INSERT с разделёнными таблицами.
Оптимизированные записи можно включить на уровне таблицы или сеанса с помощью следующих параметров:
- Параметр таблицы:
delta.autoOptimize.optimizeWrite - Параметр SparkSession:
spark.databricks.delta.optimizeWrite.enabled
Эти параметры принимают следующие опции:
| Параметры | Поведение |
|---|---|
true |
Используйте 128 МБ в качестве целевого размера файла. |
false |
Отключает оптимизированные записи. Задается на уровне сеанса для переопределения автоматического сжатия всех таблиц Delta, измененных в рабочей нагрузке. |
Установка целевого размера файла
Если вы хотите настроить размер файлов в таблице Delta, задайте для свойства таблицы значениеdelta.targetFileSize требуемого размера. Если это свойство задано, все операции оптимизации макета данных помогут создать файлы указанного размера. Примеры включают оптимизацию или Z-порядка, автоматическое сжатиеи оптимизацию записей.
Примечание.
При использовании управляемых таблиц Unity Catalog и хранилищ SQL или Databricks Runtime 11.3 LTS и более поздних версий только команды OPTIMIZE учитывают параметр targetFileSize.
| Свойство таблицы |
|---|
|
delta.targetFileSize Тип: размер в байтах или более высоких единицах. Размер целевого файла. Например: 104857600(bytes) или 100mb.Значение по умолчанию: нет |
Для существующих таблиц можно задать и отменить свойства с помощью команды SQL ALTER TABLESET свойства TBL. Эти свойства также можно настроить автоматически при создании таблиц с помощью конфигураций сеанса Spark. Дополнительные сведения см. в справочнике по свойствам таблицы Delta.
Размер файла Autotune на основе рабочей нагрузки
Databricks рекомендует установить свойство таблицы delta.tuneFileSizesForRewrites на true для всех таблиц, к которым выполняется много операций MERGE или DML, независимо от среды выполнения Databricks, каталога Unity или других оптимизаций. Если задано значение true, целевой размер файла для таблицы устанавливается на гораздо меньшее пороговое значение, что ускоряет операции с интенсивным записью.
Если не задано явно, Azure Databricks автоматически обнаруживает, что 9 из последних 10 операций с таблицей Delta были операциями MERGE, и устанавливает для этой таблицы свойство true. Чтобы избежать этого поведения, необходимо явно задать для этого свойства значение false.
| Свойство таблицы |
|---|
|
delta.tuneFileSizesForRewrites Тип: BooleanСледует ли настраивать размеры файлов для оптимизации макета данных. Значение по умолчанию: нет |
Для существующих таблиц можно задать и отменить свойства с помощью команды SQL ALTER TABLESET свойства TBL. Эти свойства также можно настроить автоматически при создании таблиц с помощью конфигураций сеанса Spark. Дополнительные сведения см. в справочнике по свойствам таблицы Delta.
Автоматически наладить размер файла на основе размера таблицы
Чтобы свести к минимуму необходимость ручной настройки, Azure Databricks автоматически настраивает размер файла таблиц Delta на основе размера таблицы. Azure Databricks будет использовать меньшие размеры файлов для небольших таблиц и больших размеров файлов для больших таблиц, чтобы количество файлов в таблице не росло слишком большим. Azure Databricks не выполняет автоматическую настройку таблиц, настроенных с использованием определенного целевого размера или на основе рабочей нагрузки с частыми перезаписями.
Размер целевого файла основан на текущем размере таблицы Delta. Для таблиц меньше 2,56 ТБ размер автоматически настраиваемого целевого файла составляет 256 МБ. Для таблиц с размером от 2,56 ТБ до 10 ТБ целевой размер будет линейно увеличиваться с 256 МБ до 1 ГБ. Для таблиц размером более 10 ТБ целевой размер файла составляет 1 ГБ.
Примечание.
При росте размера целевого файла для таблицы существующие файлы не оптимизированы повторно в более крупные файлы с помощью команды OPTIMIZE. Поэтому большая таблица может иметь некоторые файлы, которые меньше целевого размера. Если требуется оптимизировать небольшие файлы в более крупные, можно настроить фиксированный целевой размер файла для таблицы с помощью свойства delta.targetFileSize таблицы.
При добавочном написании таблицы целевые размеры и количество файлов будут близки к следующим числам на основе размера таблицы. Количество файлов в этой таблице — только пример. Фактические результаты будут отличаться в зависимости от множества факторов.
| Размер таблицы | Размер целевого файла | Приблизительное количество файлов в таблице |
|---|---|---|
| 10 ГБ | 256 МБ | 40 |
| 1 TБ | 256 МБ | 4096 |
| 2,56 ТБ | 256 МБ | 10240 |
| 3 ТБ | 307 МБ | 12108 |
| 5 ТБ | 512 МБ | 17339 |
| 7 ТБ | 716 МБ | 20784 |
| 10 ТБ | 1 ГБ | 24437 |
| 20 TБ | 1 ГБ | 34437 |
| 50 ТБ | 1 ГБ | 64437 |
| 100 ТБ | 1 ГБ | 114437 |
Ограничение строк, записанных в файле данных
Иногда таблицы с узкими данными могут столкнуться с ошибкой, когда количество строк в заданном файле данных превышает ограничения поддержки формата Parquet. Чтобы избежать этой ошибки, можно использовать конфигурацию сеанса SQL spark.sql.files.maxRecordsPerFile, чтобы указать максимальное количество записей для записи в один файл для таблицы Delta Lake. Указание значения нуля или отрицательного значения не представляет предела.
В версиях Databricks Runtime 11.3 LTS и выше можно также использовать параметр DataFrameWriter maxRecordsPerFile при использовании API DataFrame для записи в таблицу Delta Lake. Если указан параметр maxRecordsPerFile, значение конфигурации spark.sql.files.maxRecordsPerFile для сеанса SQL игнорируется.
Примечание.
Databricks не рекомендует использовать этот параметр, если не требуется избежать указанной выше ошибки. Этот параметр может по-прежнему потребоваться для некоторых управляемых таблиц каталога Unity с очень узкими данными.
Обновление до автоматического сжатия фона
Фоновое автоматическое сжатие доступно для управляемых таблиц Unity Catalog в Databricks Runtime 11.3 LTS и более поздних версиях. При миграции устаревшей рабочей нагрузки или таблицы сделайте следующее:
- Удалите конфигурацию Spark
spark.databricks.delta.autoCompact.enabledиз параметров конфигурации кластера или настройки записной книжки. - Для каждой таблицы выполните
ALTER TABLE <table_name> UNSET TBLPROPERTIES (delta.autoOptimize.autoCompact), чтобы удалить устаревшие параметры автоматического сжатия.
После удаления этих устаревших конфигураций вы увидите, что автоматическое фоновое сжатие будет включаться автоматически для всех таблиц, управляемых каталогом Unity.