Чтение данных, предоставленных с помощью открытой передачи данных через Delta Sharing (для получателей)
В этой статье описывается, как считывать данные, к которым вам предоставлен общий доступ с помощью протокола открытого обмена данными Delta Sharing. В ней содержатся инструкции по чтению общих данных с помощью Databricks, Apache Spark, pandas, Power BI и Tableau.
При открытом совместном доступе вы используете файл учетных данных, который был предоставлен участнику команды поставщиком данных, чтобы получить безопасный доступ на чтение к общим данным. Доступ сохраняется до тех пор, пока учетные данные действительны, и поставщик продолжает предоставлять общий доступ к данным. Поставщики управляют истечением срока действия учетных данных и процессом их обновления. Обновления данных появляются почти в режиме реального времени. Вы можете считывать общие данные и создавать их копии, но не можете вносить в них изменения.
Примечание.
Если данные были переданы вам с помощью Databricks-to-Databricks Delta Sharing, вам не нужен файл учетных данных для доступа к данным, и эта статья не применяется к вам. Инструкции см. в разделе «Чтение данных с помощью Databricks-to-Databricks Delta Sharing (для получателей)».
В следующих разделах описано, как использовать Azure Databricks, Apache Spark, pandas и Power BI для доступа к общим данным и считывания общих данных с помощью файла учетных данных. Полный список соединителей Delta Sharing и сведения об их использовании см. в документации открытого исходного кода Delta Sharing. При возникновении проблем с доступом к общим данным обратитесь к поставщику данных.
Примечание.
Интеграцию с партнерскими продуктами, если не указано иное, предоставляют третьи лица. Для работы с продуктами и службами определенного поставщика требуется соответствующая учетная запись. Прилагаются все усилия, чтобы поддерживать содержимое Databricks в актуальном состоянии. Но мы не делаем никаких заявлений в отношении интеграции или точности содержимого на партнерских страницах со сведениями об интеграции. По вопросам интеграции обращайтесь к соответствующим поставщикам.
Прежде чем начать
Член вашей команды должен скачать файл учетных данных, к которым предоставлен доступ поставщику данных. См. Получите доступ в модели открытого обмена.
Они должны использовать безопасный канал, чтобы поделиться с вами этим файлом или его местоположением.
Azure Databricks: чтение общих данных с помощью открытых соединителей общего доступа
В этом разделе описывается, как импортировать провайдера и как запрашивать общие данные в обозревателе каталогов или в записной книжке Python.
- Если рабочая область Azure Databricks включена для каталога Unity, используйте пользовательский интерфейс поставщика импорта в обозревателе каталогов. Это позволяет создавать каталоги из общих папок с помощью кнопки, использовать элементы управления доступом каталога Unity для предоставления доступа к общим таблицам и использовать стандартный синтаксис каталога Unity для запроса этих общих папок без необходимости хранить файл учетных данных или указывать его при запросе общих данных.
- Если рабочая область Azure Databricks не активирована для Unity Catalog, используйте инструкции в блокноте Python как образец. Инструкции записной книжки также описывают, как использовать записную книжку для перечисления и чтения общих таблиц.
Примечание.
Если поставщик данных использует совместное использование Databricks-to-Databricks, им не нужно делиться с вами файлом учетных данных, и инструкции в этой статье не применяются к вам. Вместо этого см. раздел Чтение данных, которыми делятся с помощью Databricks-to-Databricks Delta Sharing (для получателей).
Обозреватель каталогов
разрешения, необходимые: администратор хранилища метаданных или пользователь, имеющий права CREATE PROVIDER и USE PROVIDER для хранилища метаданных каталога Unity.
В рабочей области Azure Databricks щелкните значок каталога
 каталога, чтобы открыть обозреватель каталогов.
каталога, чтобы открыть обозреватель каталогов.В верхней части области каталога щелкните по значку
 и выберите Delta Sharing.
и выберите Delta Sharing.Кроме того, на странице Быстрый доступ нажмите кнопку Delta Sharing>.
На вкладке "Поделились со мной" нажмите "Импортировать поставщика непосредственно".
В диалоговом окне поставщика импорта введите имя поставщика.
Имя не может содержать пробелы.
Загрузите файл учетных данных, который поставщик поделился с вами.
Многие поставщики имеют собственные сети Delta Sharing, от которых можно получать доли. Дополнительные сведения см. в разделе конфигурации для конкретного поставщика.
(Необязательно) Введите комментарий.
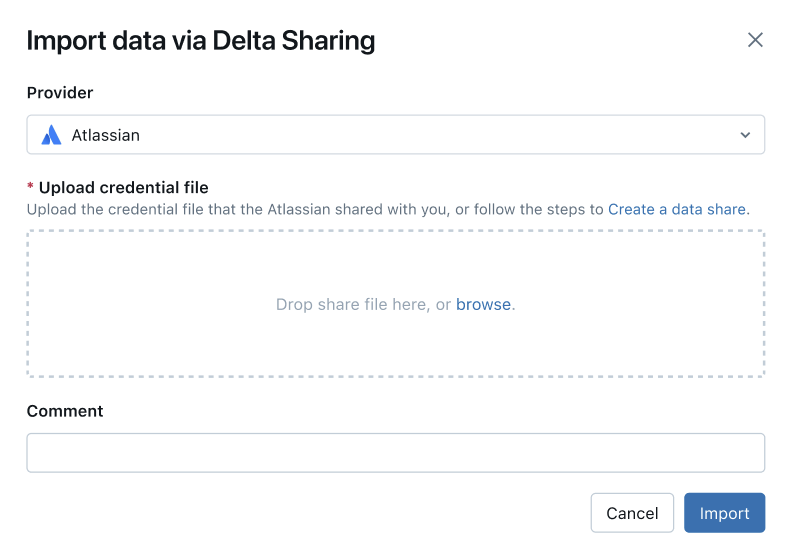 пользовательского интерфейса
пользовательского интерфейсаНажмите кнопку Импорт.
Создайте каталоги из общих данных.
На вкладке Акции щелкните Создать каталог в строке Акции.
Сведения об использовании SQL или интерфейса командной строки Databricks для создания каталога из общего ресурса см. в статье Создание каталога изобщего ресурса.
Предоставьте доступ к каталогам.
См. Как сделать общие данные доступными для моей команды? и Управлять разрешениями для схем, таблиц и томов в каталоге Delta Sharing.
Считывайте данные из совместно используемых объектов точно так же, как и из любых объектов данных, зарегистрированных в каталоге Unity.
Дополнительные сведения и примеры см. в разделе Доступ к данным в общей таблице или томе.
Python
В этом разделе описывается, как использовать открытый соединитель общего доступа для доступа к общим данным с помощью записной книжки в рабочей области Azure Databricks. Вы или другой член вашей команды храните файл учетных данных в Azure Databricks, а затем используете его для проверки подлинности в учетной записи Azure Databricks поставщика данных и считываете данные, к которым предоставлен доступ поставщику данных.
Примечание.
В этих инструкциях предполагается, что рабочая область Azure Databricks не поддерживает Unity Catalog. Если вы используете Unity Catalog, вам не нужно указывать на файл учетных данных при чтении из объекта обмена. Вы можете читать из общих таблиц так же, как и из любой таблицы, зарегистрированной в каталоге Unity. Databricks рекомендует использовать пользовательский интерфейс поставщика импорта в обозревателе каталогов вместо приведенных здесь инструкций.
Сначала используйте записную книжку Python в Azure Databricks для хранения файла учетных данных, чтобы пользователи в вашей команде могли получить доступ к общим данным.
В текстовом редакторе откройте файл учетных данных.
В вашей рабочей области Azure Databricks нажмите кнопку
"Создать новую записную книжку". - Введите имя.
- Задайте язык по умолчанию для записной книжки в Python.
- Выберите кластер для добавления к блокноту.
- Нажмите кнопку Создать.
Записная книжка откроется в редакторе записных книжек.
Чтобы с помощью Python или pandas получить доступ к общим данным, установите Python-коннектор для Delta Sharing. В редакторе записной книжки вставьте следующую команду:
%sh pip install delta-sharingЗапустите ячейку.
Библиотека
delta-sharingPython устанавливается в кластере, если она еще не установлена.В новой ячейке вставьте следующую команду, которая передает содержимое файла учетных данных в папку в DBFS.
Замените переменные следующим образом:
<dbfs-path>: указывает путь к папке, в которую следует сохранить файл учетных данных.<credential-file-contents>: содержимое файла учетных данных. Это не путь к файлу, а скопированное содержимое файла.Файл учетных данных содержит JSON, определяющий три поля:
shareCredentialsVersion,endpointиbearerToken.%scala dbutils.fs.put("<dbfs-path>/config.share",""" <credential-file-contents> """)
Запустите ячейку.
После отправки файла учетных данных эту ячейку можно удалить. Все пользователи рабочей области могут считывать файл учетных данных из DBFS, а файл учетных данных доступен в DBFS во всех кластерах и хранилищах SQL в рабочей области. Чтобы удалить ячейку, щелкните x в меню
 , расположенном справа.
, расположенном справа.
Теперь, когда файл учетных данных хранится, можно использовать записную книжку для перечисления и чтения общих таблиц.
С помощью Python получите список таблиц в общей папке.
В новой ячейке вставьте следующую команду. Замените
<dbfs-path>на созданный выше путь.При выполнении кода Python считывает файл учетных данных из DBFS в кластере. Доступ к данным, хранящимся в DBFS в пути
/dbfs/.import delta_sharing client = delta_sharing.SharingClient(f"/dbfs/<dbfs-path>/config.share") client.list_all_tables()Запустите ячейку.
Результатом является массив таблиц, а также метаданные для каждой таблицы. В следующих выходных данных показаны две таблицы:
Out[10]: [Table(name='example_table', share='example_share_0', schema='default'), Table(name='other_example_table', share='example_share_0', schema='default')]Если выходные данные пусты или не содержат нужных таблиц, обратитесь к поставщику данных.
Сделать запрос к общей таблице.
Использование Scala:
В новой ячейке вставьте следующую команду. При выполнении кода файл учетных данных считывается из DBFS через виртуальную машину Java.
Замените переменные следующим образом:
-
<profile-path>: путь к файлу учетных данных в DBFS. Например,/<dbfs-path>/config.share. -
<share-name>: значениеshare=для таблицы. -
<schema-name>: значениеschema=для таблицы. -
<table-name>: значениеname=для таблицы.
%scala spark.read.format("deltaSharing") .load("<profile-path>#<share-name>.<schema-name>.<table-name>").limit(10);Запустите ячейку. Каждый раз при загрузке общей таблицы отображаются новые данные из источника.
-
Использование SQL:
Чтобы запросить данные с помощью SQL, создайте локальную таблицу в рабочей области из общей таблицы, а затем запросите локальную таблицу. Общие данные не хранятся и не кэшируются в локальной таблице. Каждый раз при запросе локальной таблицы отображается текущее состояние общих данных.
В новой ячейке вставьте следующую команду.
Замените переменные следующим образом:
-
<local-table-name>: имя локальной таблицы. -
<profile-path>: расположение файла учетных данных. -
<share-name>: значениеshare=для таблицы. -
<schema-name>: значениеschema=для таблицы. -
<table-name>: значениеname=для таблицы.
%sql DROP TABLE IF EXISTS table_name; CREATE TABLE <local-table-name> USING deltaSharing LOCATION "<profile-path>#<share-name>.<schema-name>.<table-name>"; SELECT * FROM <local-table-name> LIMIT 10;При выполнении команды запрос к общим данным осуществляется напрямую. В качестве теста выполняется запрос к таблице и возвращаются первые 10 результатов.
-
Если выходные данные пусты или не содержат нужных данных, обратитесь к поставщику.
Apache Spark: чтение общих данных
Выполните следующие действия, чтобы получить доступ к общим данным с помощью Spark 3.x или более поздней версии.
В этих инструкциях предполагается, что у вас есть доступ к файлу учетных данных, который был предоставлен поставщиком данных. См. Получить доступ в модели открытого доступа.
Примечание.
Если вы используете Spark в рабочей области Azure Databricks, где активирован Unity Catalog, и использовали пользовательский интерфейс импорта для импорта поставщика и передачи, инструкции в этом разделе не применяются к вам. Доступ к общим таблицам можно получить так же, как и к любой другой таблице, зарегистрированной в каталоге Unity. Не нужно устанавливать соединитель Python delta-sharing или указать путь к файлу учетных данных. См. Azure Databricks: чтение общих данных с использованием открытых коннекторов для совместного доступа.
Установите коннекторы Delta Sharing для Python и Spark.
Чтобы получить доступ к метаданным, связанным с общими данными, например списком таблиц, которыми вы поделились, выполните указанные ниже действия. В этом примере используется Python.
Установите коннектор Python для delta-sharing:
pip install delta-sharingУстановите соединитель Apache Spark.
Вывод списка общих таблиц с помощью Spark
Получите список таблиц в общей папке. В следующем примере замените <profile-path> на расположение файла учетных данных.
import delta_sharing
client = delta_sharing.SharingClient(f"<profile-path>/config.share")
client.list_all_tables()
Результатом является массив таблиц, а также метаданные для каждой таблицы. В следующих выходных данных показаны две таблицы:
Out[10]: [Table(name='example_table', share='example_share_0', schema='default'), Table(name='other_example_table', share='example_share_0', schema='default')]
Если выходные данные пусты или не содержат нужных таблиц, обратитесь к поставщику данных.
Доступ к общим данным с помощью Spark
Выполните следующие действия, заменив эти переменные:
-
<profile-path>: расположение файла учетных данных. -
<share-name>: значениеshare=для таблицы. -
<schema-name>: значениеschema=для таблицы. -
<table-name>: значениеname=для таблицы. -
<version-as-of>: необязательно. Версия таблицы для загрузки данных. Работает только в том случае, если поставщик данных предоставляет общий доступ к журналу таблицы. Требуетсяdelta-sharing-spark0.5.0 или более поздней версии. -
<timestamp-as-of>: необязательно. Загрузите данные из версии, существующей до заданной отметки времени или на момент этой отметки. Работает только в том случае, если поставщик данных предоставляет общий доступ к журналу таблицы. Требуетсяdelta-sharing-spark0.6.0 или более поздней версии.
Python
delta_sharing.load_as_spark(f"<profile-path>#<share-name>.<schema-name>.<table-name>", version=<version-as-of>)
spark.read.format("deltaSharing")\
.option("versionAsOf", <version-as-of>)\
.load("<profile-path>#<share-name>.<schema-name>.<table-name>")\
.limit(10))
delta_sharing.load_as_spark(f"<profile-path>#<share-name>.<schema-name>.<table-name>", timestamp=<timestamp-as-of>)
spark.read.format("deltaSharing")\
.option("timestampAsOf", <timestamp-as-of>)\
.load("<profile-path>#<share-name>.<schema-name>.<table-name>")\
.limit(10))
Scala
Выполните следующие действия, заменив эти переменные:
-
<profile-path>: расположение файла учетных данных. -
<share-name>: значениеshare=для таблицы. -
<schema-name>: значениеschema=для таблицы. -
<table-name>: значениеname=для таблицы. -
<version-as-of>: необязательно. Версия таблицы для загрузки данных. Работает только в том случае, если поставщик данных предоставляет общий доступ к журналу таблицы. Требуетсяdelta-sharing-spark0.5.0 или более поздней версии. -
<timestamp-as-of>: необязательно. Загрузите данные в версии, соответствующей или предшествующей данной временной метке. Работает только в том случае, если поставщик данных предоставляет общий доступ к журналу таблицы. Требуетсяdelta-sharing-spark0.6.0 или более поздней версии.
spark.read.format("deltaSharing")
.option("versionAsOf", <version-as-of>)
.load("<profile-path>#<share-name>.<schema-name>.<table-name>")
.limit(10)
spark.read.format("deltaSharing")
.option("timestampAsOf", <version-as-of>)
.load("<profile-path>#<share-name>.<schema-name>.<table-name>")
.limit(10)
Доступ к общему потоку данных об изменениях с помощью Spark
Если история таблицы предоставлена вам, и канал изменения данных (CDF) включен для исходной таблицы, вы можете получить доступ к каналу изменения данных, выполнив следующие действия, заменив эти переменные. Требуется delta-sharing-spark 0.5.0 или более поздней версии.
Необходимо указать только один и только один начальный параметр.
-
<profile-path>: расположение файла учетных данных. -
<share-name>: значениеshare=для таблицы. -
<schema-name>: значениеschema=для таблицы. -
<table-name>: значениеname=для таблицы. -
<starting-version>: необязательно. Начальная версия запроса включительно. Укажите значение long. -
<ending-version>: необязательно. Конечная версия запроса включительно. Если конечная версия не указана, API использует последнюю версию таблицы. -
<starting-timestamp>: необязательно. Начальная метка времени запроса преобразуется в версию, созданную больше или равной этой метке времени. Укажите строку в форматеyyyy-mm-dd hh:mm:ss[.fffffffff]. -
<ending-timestamp>: необязательно. Конечная метка времени запроса преобразуется в версию, созданную ранее или равной этой метке времени. Укажите строку в форматеyyyy-mm-dd hh:mm:ss[.fffffffff]
Python
delta_sharing.load_table_changes_as_spark(f"<profile-path>#<share-name>.<schema-name>.<table-name>",
starting_version=<starting-version>,
ending_version=<ending-version>)
delta_sharing.load_table_changes_as_spark(f"<profile-path>#<share-name>.<schema-name>.<table-name>",
starting_timestamp=<starting-timestamp>,
ending_timestamp=<ending-timestamp>)
spark.read.format("deltaSharing").option("readChangeFeed", "true")\
.option("statingVersion", <starting-version>)\
.option("endingVersion", <ending-version>)\
.load("<profile-path>#<share-name>.<schema-name>.<table-name>")
spark.read.format("deltaSharing").option("readChangeFeed", "true")\
.option("startingTimestamp", <starting-timestamp>)\
.option("endingTimestamp", <ending-timestamp>)\
.load("<profile-path>#<share-name>.<schema-name>.<table-name>")
Scala
spark.read.format("deltaSharing").option("readChangeFeed", "true")
.option("statingVersion", <starting-version>)
.option("endingVersion", <ending-version>)
.load("<profile-path>#<share-name>.<schema-name>.<table-name>")
spark.read.format("deltaSharing").option("readChangeFeed", "true")
.option("startingTimestamp", <starting-timestamp>)
.option("endingTimestamp", <ending-timestamp>)
.load("<profile-path>#<share-name>.<schema-name>.<table-name>")
Если выходные данные пусты или не содержат нужных данных, обратитесь к поставщику.
Доступ к общей таблице с помощью структурированной потоковой передачи Spark
Если вам предоставили доступ к истории таблицы, вы можете напрямую читать общие данные. Требуется delta-sharing-spark 0.6.0 или более поздней версии.
Поддерживаемые параметры:
-
ignoreDeletes: игнорировать транзакции, которые удаляют данные. -
ignoreChanges: повторно обработать обновления, если файлы были перезаписаны в исходной таблице из-за операции изменения данных, напримерUPDATE, (в разделахMERGE INTO,DELETE) илиOVERWRITE. Неизменённые строки по-прежнему можно выдавать. Таким образом, нижестоящие потребители должны иметь возможность обрабатывать дубликаты. Удаления не распространяются вниз по потоку.ignoreChangesвключаетignoreDeletes. Поэтому, если используетсяignoreChanges, поток не будет нарушаться удалением или обновлением исходной таблицы. -
startingVersion: версия разделяемой таблицы для начала. Все изменения таблицы, начиная с этой версии (включительно), будут считываться источником потоковой передачи. -
startingTimestamp: Метка времени, с которой начать. Все изменения в таблице, зафиксированные в момент или после метки времени (включительно), считываются источником потоковой передачи. Пример:"2023-01-01 00:00:00.0". -
maxFilesPerTrigger: количество новых файлов, которые следует учитывать в каждом микропакете. -
maxBytesPerTrigger: объем данных, обрабатываемых в каждом микропакете. Этот параметр задает значение "мягкого максимума", то есть пакет обрабатывает приблизительно такой объем данных и может обработать больше, чтобы потоковый запрос продолжился в случаях, когда наименьший входной блок превышает это ограничение. -
readChangeFeed: поток считывания читает канал обновления данных общей таблицы.
Неподдерживаемые параметры:
Trigger.availableNow
Примеры структурированных запросов потоковой передачи
Scala
spark.readStream.format("deltaSharing")
.option("startingVersion", 0)
.option("ignoreChanges", true)
.option("maxFilesPerTrigger", 10)
.load("<profile-path>#<share-name>.<schema-name>.<table-name>")
Python
spark.readStream.format("deltaSharing")\
.option("startingVersion", 0)\
.option("ignoreDeletes", true)\
.option("maxBytesPerTrigger", 10000)\
.load("<profile-path>#<share-name>.<schema-name>.<table-name>")
См. также стриминг на Azure Databricks.
Чтение таблиц с включенными векторами удаления или сопоставлением столбцов
Внимание
Эта функция предоставляется в режиме общедоступной предварительной версии.
Векторы удаления — это функция оптимизации хранилища, которую поставщик может включить в общих таблицах Delta. См. раздел " Что такое векторы удаления?".
Azure Databricks также поддерживает сопоставление столбцов для таблиц Delta. См. раздел "Переименование и удаление столбцов" с сопоставлением столбцов Delta Lake.
Если ваш поставщик предоставил таблицу, в которой включены векторы удаления или сопоставление столбцов, вы можете прочитать её, используя вычислительные мощности версии delta-sharing-spark 3.1 или выше. Если вы используете кластеры Databricks, вы можете выполнять пакетные операции чтения с помощью кластера под управлением Databricks Runtime 14.1 или более поздней версии. Для запросов CDF и потоковой передачи требуется Среда выполнения Databricks 14.2 или более поздней версии.
Пакетные запросы можно выполнять в исходном виде, так как они могут автоматически разрешаться responseFormat на основе функций общей таблицы.
Чтобы считывать поток данных об изменениях (CDF) или выполнять потоковые запросы к общим таблицам с включенными векторами удаления или сопоставлением столбцов, необходимо задать дополнительный параметр responseFormat=delta.
В следующих примерах показаны пакетные запросы, запросы CDF и потоковые запросы.
import org.apache.spark.sql.SparkSession
val spark = SparkSession
.builder()
.appName("...")
.master("...")
.config("spark.sql.extensions", "io.delta.sql.DeltaSparkSessionExtension")
.config("spark.sql.catalog.spark_catalog", "org.apache.spark.sql.delta.catalog.DeltaCatalog")
.getOrCreate()
val tablePath = "<profile-file-path>#<share-name>.<schema-name>.<table-name>"
// Batch query
spark.read.format("deltaSharing").load(tablePath)
// CDF query
spark.read.format("deltaSharing")
.option("readChangeFeed", "true")
.option("responseFormat", "delta")
.option("startingVersion", 1)
.load(tablePath)
// Streaming query
spark.readStream.format("deltaSharing").option("responseFormat", "delta").load(tablePath)
Pandas: чтение данных из общего доступа
Чтобы получить доступ к общим данным в pandas 0.25.3 или более поздней версии, выполните указанные ниже действия.
В этих инструкциях предполагается, что у вас есть доступ к файлу учетных данных, который был предоставлен поставщиком данных. См. Как получить доступ в рамках открытой модели совместного использования.
Примечание.
Если вы используете pandas в рабочей области Azure Databricks, настроенной для Unity Catalog, и использовали пользовательский интерфейс импорта для добавления поставщика и ресурса, то инструкции в этом разделе к вам не применяются. Доступ к общим таблицам можно получить так же, как и к любой другой таблице, зарегистрированной в каталоге Unity. Не нужно устанавливать соединитель Python delta-sharing или указать путь к файлу учетных данных. См. Azure Databricks: чтение общих данных с использованием открытых коннекторов для совместного доступа.
Установите коннектор Delta Sharing для Python
Чтобы получить доступ к метаданным, связанным с общими данными, например списком таблиц, которые с вами поделились, необходимо установить коннектор delta-sharing для Python.
pip install delta-sharing
Вывод списка общих таблиц с помощью pandas
Чтобы перечислить таблицы в общем ресурсе, выполните следующую команду, заменив <profile-path>/config.share на расположение файла учетных данных.
import delta_sharing
client = delta_sharing.SharingClient(f"<profile-path>/config.share")
client.list_all_tables()
Если выходные данные пусты или не содержат нужных таблиц, обратитесь к поставщику данных.
Доступ к общим данным с помощью pandas
Чтобы получить доступ к общим данным в pandas с помощью Python, выполните следующие действия, заменив переменные следующим образом:
-
<profile-path>: расположение файла учетных данных. -
<share-name>: значениеshare=для таблицы. -
<schema-name>: значениеschema=для таблицы. -
<table-name>: значениеname=для таблицы.
import delta_sharing
delta_sharing.load_as_pandas(f"<profile-path>#<share-name>.<schema-name>.<table-name>")
Доступ к общему потоку данных об изменениях с использованием pandas
Чтобы получить доступ к каналу измененных данных для общей таблицы в pandas с помощью Python, выполните следующие шаги, заменив переменные следующим образом. Поток данных об изменениях может отсутствовать в зависимости от того, предоставил ли поставщик данных доступ к потоку изменений на таблицу.
-
<starting-version>: необязательно. Начальная версия запроса включительно. -
<ending-version>: необязательно. Конечная версия запроса включительно. -
<starting-timestamp>: необязательно. Начальная метка времени запроса. Это преобразуется в версию, созданную в момент времени, который больше или равен этой метке времени. -
<ending-timestamp>: необязательно. Конечная метка времени запроса. Это преобразуется в версию, созданную ранее или равной этой метке времени.
import delta_sharing
delta_sharing.load_table_changes_as_pandas(
f"<profile-path>#<share-name>.<schema-name>.<table-name>",
starting_version=<starting-version>,
ending_version=<starting-version>)
delta_sharing.load_table_changes_as_pandas(
f"<profile-path>#<share-name>.<schema-name>.<table-name>",
starting_timestamp=<starting-timestamp>,
ending_timestamp=<ending-timestamp>)
Если выходные данные пусты или не содержат нужных данных, обратитесь к поставщику.
Power BI: просмотр общих данных
Соединитель Delta Sharing Power BI позволяет обнаруживать, анализировать и визуализировать наборы данных, которыми вы поделились с помощью открытого протокола Delta Sharing.
Требования
- Power BI Desktop 2.99.621.0 или более поздняя версия.
- Доступ к файлу учетных данных, который был предоставлен поставщиком данных. См. "Получить доступ в модели открытого совместного использования".
Подключение к Databricks
Чтобы подключиться к Azure Databricks с помощью соединителя Delta Sharing, сделайте следующее:
- Откройте общий файл учетных данных с текстовым редактором, чтобы получить URL-адрес конечной точки и маркер.
- Запустите Power BI Desktop.
- В меню Получение данных выполните поиск Delta Sharing.
- Выберите соединитель и щелкните Подключиться.
- Введите URL-адрес конечной точки, скопированный из файла учетных данных, в поле Delta Sharing Server URL.
- При необходимости на вкладке Дополнительные параметры задайте максимальное число строк которое можно скачать. По умолчанию задано значение в 1 000 000 строк.
- Щелкните OK.
- В разделе Проверка подлинности скопируйте токен, полученный из файла учетных данных, в поле Маркер носителя.
- Щелкните Подключить.
Ограничения соединителя Delta Sharing в Power BI
Соединитель Power BI Delta Sharing имеет следующие ограничения:
- Данные, которые загружает соединитель, должны соответствовать памяти компьютера. Чтобы управлять этим требованием, соединитель ограничивает количество импортированных строк ограничением строк, заданным на вкладке "Дополнительные параметры" в Power BI Desktop.
Tableau: чтение общих данных
Соединитель Tableau Delta Sharing позволяет обнаруживать, анализировать и визуализировать наборы данных, которые совместно используются через открытый протокол Delta Sharing.
Требования
- Tableau Desktop и Tableau Server 2024.1 или новее
- Доступ к файлу учетных данных, который был предоставлен поставщиком данных. См. Получение доступа в модели открытого совместного использования.
Подключение к Azure Databricks
Чтобы подключиться к Azure Databricks с помощью соединителя Delta Sharing, сделайте следующее:
- Перейдите в Tableau Exchange, следуйте инструкциям, чтобы скачать соединитель Delta Sharing и поместить его в соответствующую папку рабочего стола.
- Откройте Tableau Desktop.
- На странице "Соединители" найдите "Delta Sharing by Databricks".
- Выберите Загрузить файл для общего доступа, и выберите файл учетных данных, который был предоставлен поставщиком.
- Щелкните Получить данные.
- В обозревателе данных выберите таблицу.
- При необходимости добавьте фильтры SQL или ограничения строк.
- Нажмите кнопку "Получить данные таблицы".
Ограничения соединителя Tableau Delta Sharing
Соединитель Delta Sharing Tableau имеет следующие ограничения:
- Данные, которые загружает соединитель, должны соответствовать памяти компьютера. Для управления этим требованием соединитель ограничивает количество импортированных строк ограничением строки, заданным в Tableau.
- Все столбцы возвращаются в виде типа
String. - Фильтр SQL работает только в том случае, если сервер Delta Sharing поддерживает предикатHint.
Запрос новых учетных данных
Если URL-адрес активации учетных данных или скачанные учетные данные потеряны, повреждены или скомпрометированы, или срок действия учетных данных истекает без отправки нового поставщика, обратитесь к поставщику, чтобы запросить новые учетные данные.