Что такое Delta Live Tables?
Примечание.
Для Delta Live Tables требуется Premium план . Чтобы получить дополнительные сведения, обратитесь к группе учетной записи Databricks.
Delta Live Tables — это декларативная платформа, предназначенная для упрощения создания надежных и поддерживаемых конвейеров извлечения, преобразования и загрузки (ETL). Вы указываете, какие данные следует принять и как его преобразовать, и Delta Live Tables автоматизирует ключевые аспекты управления конвейером данных, включая оркестрацию, управление вычислениями, мониторинг, применение качества данных и обработку ошибок.
Delta Live Tables построены на базе Apache Spark, но вместо определения конвейеров данных с помощью ряда отдельных задач Apache Spark, вы определяете потоковые таблицы и материализованные представления, которые система должна создавать, а также запросы, необходимые для заполнения и обновления этих потоковых таблиц и материализованных представлений.
Дополнительные сведения о преимуществах создания и запуска конвейеров ETL с помощью Delta Live Tables см. на странице продуктов Delta Live Tables.
Преимущества Delta Live Tables по сравнению с Apache Spark
Apache Spark — это универсальный единый модуль аналитики с открытым кодом, включая ETL. Delta Live Tables — это надстройка над Spark для решения конкретных и распространенных задач обработки ETL. Delta Live Tables могут значительно ускорить ваш путь к производственной среде, если ваши требования включают следующие задачи обработки, в том числе:
- Прием данных из типичных источников.
- Постепенное преобразование данных.
- Выполнение записи измененных данных (CDC).
Однако Delta Live Tables не подходит для реализации некоторых типов процедурной логики. Например, требования к обработке, такие как запись во внешнюю таблицу или включение условий, которые работают с внешним хранилищем файлов или таблицами баз данных, не могут выполняться внутри кода, определяющего набор данных Delta Live Table. Чтобы реализовать обработку, не поддерживаемую Delta Live Tables, Databricks рекомендует использовать Apache Spark или включить конвейер в задание Databricks, которое выполняет обработку в отдельной задаче задания. См. задачу конвейера Delta Live Tables для заданий.
В следующей таблице сравниваются Delta Live Tables и Apache Spark.
| Способность | Delta Live таблицы | Apache Spark |
|---|---|---|
| Преобразования данных | Вы можете преобразовать данные с помощью SQL или Python. | Вы можете преобразовать данные с помощью SQL, Python, Scala или R. |
| Добавочная обработка данных | Многие преобразования данных автоматически обрабатываются постепенно. | Необходимо определить новые данные, чтобы можно было постепенно обработать их. |
| Оркестрация | Преобразования автоматически оркеструются в правильном порядке. | Необходимо убедиться, что различные преобразования выполняются в правильном порядке. |
| Параллелизм | Все преобразования выполняются с правильным уровнем параллелизма. | Для параллельного выполнения несвязанных преобразований необходимо использовать потоки или внешний оркестратор. |
| Обработка ошибок | Ошибки автоматически повторяются. | Необходимо решить, как обрабатывать ошибки и повторные попытки. |
| Контроль | Метрики и события регистрируются автоматически. | Необходимо написать код для сбора метрик о выполнении или качестве данных. |
Основные понятия Delta Live Tables
На следующем рисунке показаны важные компоненты конвейера Delta Live Tables, за которыми следует объяснение каждого компонента.
ключевые концепции Delta Live Tables. 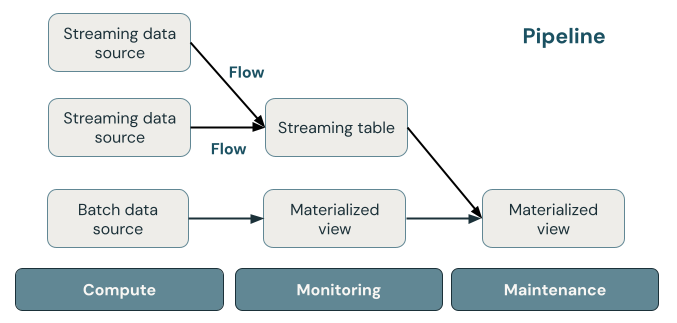
таблица потоковой передачи
Потоковая таблица — это Delta table, в которую записывают один или несколько потоков. Потоковые таблицы обычно используются для приема данных, так как они обрабатывают входные данные ровно один раз и могут обрабатывать большие объемы данных только для добавления. Таблицы потоковой передачи также полезны для низкозадержечного преобразования данных в потоке больших объемов.
Материализованное представление
Материализованное представление — это представление, содержащее предварительно вычисляемые записи на основе запроса, определяющего материализованное представление. Записи в материализованном представлении автоматически обновляются инструментом Delta Live Tables на основе расписания обновления или триггеров конвейера. Каждый раз, когда материализованное представление обновляется, гарантируется, что оно дает те же результаты, что и выполнение определяющего запроса по последним доступным данным. Однако это часто делается без повторной компиляции полного результата с нуля, используя добавочное обновление. Материализованные представления обычно используются для преобразований.
Представления
Все представления в Azure Databricks вычисляют результаты из исходных наборов данных по мере их запроса, используя оптимизации кэширования при наличии. Delta Live Tables не публикует представления в каталоге, следовательно, на них можно ссылаться только в конвейере, в котором они определены. Представления полезны как промежуточные запросы, которые не должны предоставляться конечным пользователям или системам. Databricks рекомендует использовать представления для применения ограничений качества данных или преобразования и обогащения наборов данных, которые управляют несколькими подчиненными запросами.
Трубопровод
Поток данных — это набор потоковых таблиц и материализованных представлений, которые обновляются вместе. Эти таблицы потоковой передачи и материализованные представления объявляются в исходных файлах Python или SQL. Конвейер также включает конфигурацию, которая определяет вычислительные ресурсы, используемые для обновления потоковых таблиц и материализованных представлений при запуске конвейера. Как и шаблон Terraform определяет инфраструктуру в облачной учетной записи, конвейер Delta Live Tables определяет наборы данных и преобразования для обработки данных.
Как наборы данных Delta Live Tables обрабатывают данные?
В следующей таблице описывается, как материализованные представления, потоковые таблицы и представления обрабатывают данные:
| Тип набора данных | Как записи обрабатываются с помощью определенных запросов? |
|---|---|
| Таблица потоковых данных | Каждая запись обрабатывается ровно один раз. Предполагается, что источник только для добавления. |
| Материализованное представление | Записи обрабатываются по мере необходимости, чтобы получить точные результаты для текущего состояния данных. Материализованные представления должны использоваться для задач обработки данных, таких как преобразования, агрегаты или предварительные вычисления медленных запросов и часто используемые вычисления. |
| Представления | Записи обрабатываются при каждом запросе представления. Используйте представления для промежуточных преобразований и проверок качества данных, которые не должны публиковаться в общедоступных наборах данных. |
Объявление первых наборов данных в Delta Live Tables
Delta Live Tables вводит новый синтаксис для Python и SQL. Сведения об основах синтаксиса конвейера см. в статье "Разработка кода конвейера с помощью Python и разработка кода конвейера с помощью SQL".
Примечание.
Delta Live Tables отделяют определения наборов данных от процессов обновления, а ноутбуки Delta Live Tables не предназначены для интерактивного выполнения.
Как настроить конвейеры Delta Live Tables?
Параметры конвейеров Delta Live Tables делятся на две широкие категории:
- Конфигурации, определяющие коллекцию записных книжек или файлов (известных как исходный код), которые используют синтаксис Delta Live Table для объявления наборов данных.
- Конфигурации, управляющие инфраструктурой конвейера, управлением зависимостями, обработкой обновлений и сохранением таблиц в рабочей области.
Большинство конфигураций являются необязательными, но некоторые требуют внимательного внимания, особенно при настройке рабочих конвейеров. следующие основные параметры.
- Чтобы сделать данные доступными за пределами конвейера, необходимо объявить целевую схему для публикации в хранилище метаданных Hive или целевой каталог и целевую схему для публикации в каталоге Unity.
- Разрешения доступа к данным настраиваются через кластер, используемый для выполнения. Убедитесь, что кластер имеет соответствующие разрешения, настроенные для источников данных и для целевого местоположения хранилища , если это указано.
Дополнительные сведения об использовании Python и SQL для написания исходного кода для конвейеров см. в
Более подробную информацию о параметрах и конфигурациях конвейера см. в разделе Настройка конвейера Delta Live Tables.
Развертывание первого конвейера и активация обновлений
Перед обработкой данных с использованием Delta Live Tables необходимо настроить конвейер. После настройки конвейера можно активировать обновление, чтобы вычислить результаты для каждого набора данных в конвейере. Чтобы приступить к работе с потоками Delta Live Tables, см. учебник: как запустить ваш первый поток Delta Live Tables.
Что такое обновление конвейера?
Пайпланы разворачивают инфраструктуру и пересчитывают состояние данных при запуске обновления . Обновление выполняет следующее:
- Запускает кластер с правильной конфигурацией.
- Обнаруживает все таблицы и представления, определенные и проверяет наличие ошибок анализа, таких как недопустимые имена столбцов, отсутствующие зависимости и синтаксические ошибки.
- Создает или обновляет таблицы и представления с самыми последними доступными данными.
Конвейеры могут выполняться непрерывно или по расписанию в зависимости от затрат и задержки вашего варианта использования. См. выполнение обновления в конвейере Delta Live Tables.
Загрузка данных с помощью Delta Live Tables
Delta Live Tables поддерживает все источники данных, доступные в Azure Databricks.
Databricks рекомендует использовать стриминговые таблицы для большинства случаев загрузки данных. Для файлов, поступающих в облачное хранилище объектов, Databricks рекомендует автозагрузчик. Вы можете напрямую получать данные с Delta Live Tables из большинства шин сообщений.
Дополнительные сведения о настройке доступа к облачному хранилищу см. в разделе "Конфигурация облачного хранилища".
Для форматов, не поддерживаемых автозагрузчиком, можно использовать Python или SQL для запроса любого формата, поддерживаемого Apache Spark. Смотреть загрузку данных с помощью Delta Live Tables.
Мониторинг и применение качества данных
Вы можете использовать ожидания для указания элементов управления качеством данных для содержимого набора данных. В отличие от ограничения CHECK в традиционной базе данных, которая предотвращает добавление записей, которые не выполняют ограничение, ожидания обеспечивают гибкость при обработке данных, которые не отвечают требованиям к качеству данных. Такая гибкость позволяет обрабатывать и хранить данные, которые, по вашему мнению, будут неструктурированными, а также данные, которые должны соответствовать строгим требованиям к качеству. См. Управление качеством данных с ожиданиями для конвейера.
Как связаны Delta Live Tables и Delta Lake?
Delta Live Tables расширяет функциональные возможности Delta Lake. Поскольку таблицы, созданные и управляемые с помощью Delta Live Tables, являются Delta-таблицами, они имеют такие же гарантии и функции, как и предоставленные Delta Lake. См. статью Сведения о Delta Lake.
Delta Live Tables добавляет несколько свойств таблицы в дополнение к множеству свойств, которые можно задать в Delta Lake. См. ссылки на свойства Delta Live Table и, а также на свойства таблицы Delta и.
Создание и управление таблицами Delta Live Tables
Azure Databricks автоматически управляет таблицами, созданными с помощью Delta Live Tables, определяя, как необходимо обрабатывать обновления для корректного вычисления текущего состояния таблицы, и выполняет ряд задач по её обслуживанию и оптимизации.
Для большинства операций следует разрешить Delta Live Table обрабатывать все обновления, вставки и удаления в целевую таблицу. Дополнительные сведения и ограничения см. в разделе "Сохранение удаления или обновления вручную".
Задачи по обслуживанию, выполняемые Delta Live Tables
Delta Live Tables проводят обслуживание в течение 24 часов после обновления таблицы. Обслуживание может повысить производительность запросов и сократить затраты, удалив старые версии таблиц. По умолчанию система выполняет полную операцию OPTIMIZE, за которой следует VACUUM. Вы можете отключить OPTIMIZE таблицы, задав pipelines.autoOptimize.managed = false в свойствах таблицы для таблицы. Задачи обслуживания выполняются только в том случае, если обновление конвейера выполняется в 24 часа до планирования задач обслуживания.
Ограничения
Список ограничений см. в разделе Ограничения разностных динамических таблиц.
Список требований и ограничений, специфичных для использования Delta Live Tables с Unity Catalog, см. в разделе Использование Unity Catalog с конвейерами Delta Live Tables
Дополнительные ресурсы
- Delta Live Tables имеет полную поддержку в REST API Databricks. См . API DLT.
- Сведения о параметрах конвейера и таблицы см. в справочнике по свойствам Delta Live Table.
- справочник по языку SQL Delta Live Tables.
- справочник по языку Python для Delta Live Tables.