Google BigQuery
В этой статье описывается чтение и запись в таблицы Google BigQuery в Azure Databricks.
Внимание
Конфигурации, описанные в этой статье, являются экспериментальными. Экспериментальные функции предоставляются в имеющемся виде и не поддерживаются Databricks в рамках технической поддержки клиентов. Чтобы получить полную поддержку федерации запросов, вместо этого следует использовать Lakehouse Federation, что позволяет пользователям Azure Databricks использовать синтаксис Unity Catalog и средства управления данными.
Необходимо подключиться к BigQuery с помощью проверки подлинности на основе ключей.
Разрешения
Проекты должны иметь определенные разрешения Google для чтения и записи с помощью BigQuery.
Примечание.
В этой статье рассматриваются материализованные представления BigQuery. Дополнительные сведения см. в статье Google Введение в материализованные представления. Сведения о других терминологиях BigQuery и модели безопасности BigQuery см. в документации по Google BigQuery.
Чтение и запись данных с помощью BigQuery зависит от двух проектов Google Cloud:
- Проект (
project): Идентификатор проекта Google Cloud, из которого Azure Databricks считывает или записывает таблицу BigQuery. - Родительский проект (
parentProject): идентификатор родительского проекта, который является идентификатором проекта Google Cloud для выставления счетов за чтение и запись. Установите проект Google Cloud, связанный с учетной записью службы Google, для которой нужно создать ключи.
Необходимо явно указать project и parentProject значения в коде, который обращается к BigQuery. Используйте код, аналогичный следующему:
spark.read.format("bigquery") \
.option("table", table) \
.option("project", <project-id>) \
.option("parentProject", <parent-project-id>) \
.load()
Необходимые разрешения для проектов Google Cloud зависят от того, совпадают ли project и parentProject. В следующих разделах перечислены необходимые разрешения для каждого сценария.
Необходимые разрешения, если project и parentProject совпадают
Если идентификаторы для ваших project и parentProject одинаковы, используйте следующую таблицу, чтобы определить минимальные разрешения:
| Задача Azure Databricks | Разрешения Google, необходимые в проекте |
|---|---|
| Чтение таблицы BigQuery без материализованного представления |
project В проекте:
|
| Чтение таблицы в BigQuery с материализованным представлением |
project В проекте:
В проекте материализации:
|
| Записать таблицу в BigQuery |
project В проекте:
|
Необходимые разрешения, если project и parentProject отличаются
Если идентификаторы для ваших project и parentProject отличаются, используйте следующую таблицу, чтобы определить минимальные разрешения:
| Задача Azure Databricks | Необходимые разрешения Google |
|---|---|
| Чтение таблицы BigQuery без материализованного представления | В проекте parentProject:
project В проекте:
|
| Чтение таблицы BigQuery используя материализованное представление |
parentProject В проекте:
В проекте project:
В проекте материализации:
|
| Записать данные в таблицу BigQuery |
parentProject В проекте:
В проекте project:
|
Шаг 1. Настройка Google Cloud
Включение API хранилища BigQuery
API хранилища BigQuery включается по умолчанию в новых проектах Google Cloud, где также включен BigQuery. Однако если у вас есть существующий проект и API хранилища BigQuery не включен, выполните действия, описанные в этом разделе, чтобы включить его.
Вы можете включить API хранилища BigQuery с помощью Google Cloud CLI или Google Cloud Console.
Включение API хранилища BigQuery с помощью Google Cloud CLI
gcloud services enable bigquerystorage.googleapis.com
Включение API хранилища BigQuery с помощью Google Cloud Console
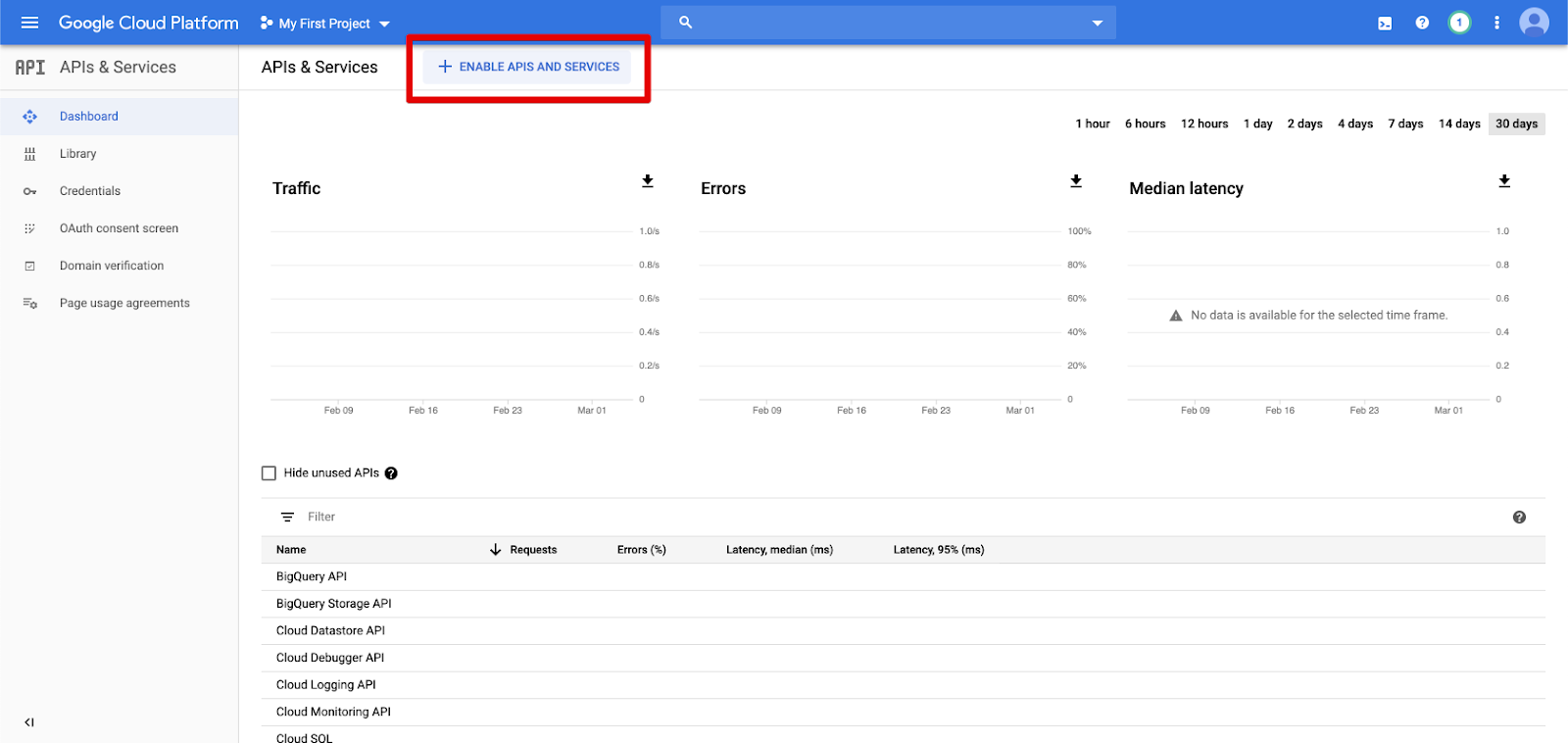
Щелкните API и службы в области навигации слева.
Нажмите кнопку ENABLE APIS AND SERVICES .
Введите
bigquery storage apiв строке поиска и выберите первый результат.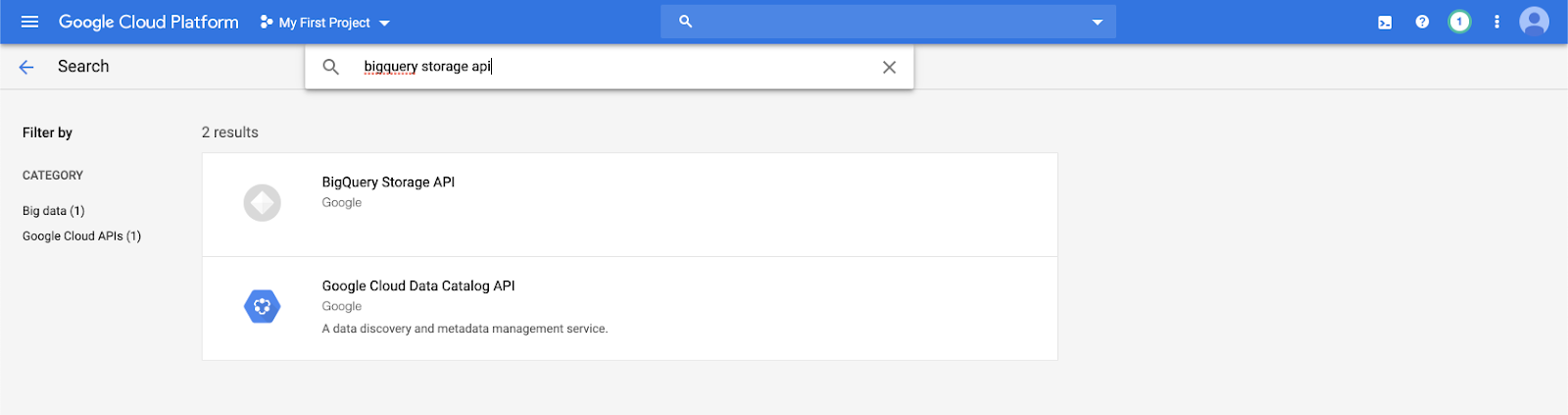
Убедитесь, что API хранилища BigQuery включен.
Создание учетной записи службы Google для Azure Databricks
Создайте учетную запись службы для кластера Azure Databricks. Databricks рекомендует предоставить этой учетной записи службы наименьшие привилегии, необходимые для выполнения задач. См. статью "Роли и разрешения BigQuery".
Вы можете создать учетную запись службы с помощью Google Cloud CLI или Google Cloud Console.
Создание учетной записи службы Google с помощью Google Cloud CLI
gcloud iam service-accounts create <service-account-name>
gcloud projects add-iam-policy-binding <project-name> \
--role roles/bigquery.user \
--member="serviceAccount:<service-account-name>@<project-name>.iam.gserviceaccount.com"
gcloud projects add-iam-policy-binding <project-name> \
--role roles/bigquery.dataEditor \
--member="serviceAccount:<service-account-name>@<project-name>.iam.gserviceaccount.com"
Создайте ключи для учетной записи службы:
gcloud iam service-accounts keys create --iam-account \
"<service-account-name>@<project-name>.iam.gserviceaccount.com" \
<project-name>-xxxxxxxxxxx.json
Создание учетной записи службы Google с помощью Google Cloud Console
Чтобы создать учетную запись, выполните следующие действия.
Щелкните IAM и Admin в области навигации слева.
Щелкните "Учетные записи службы".
Нажмите + СОЗДАТЬ СЛУЖЕБНУЮ УЧЕТНУЮ ЗАПИСЬ.
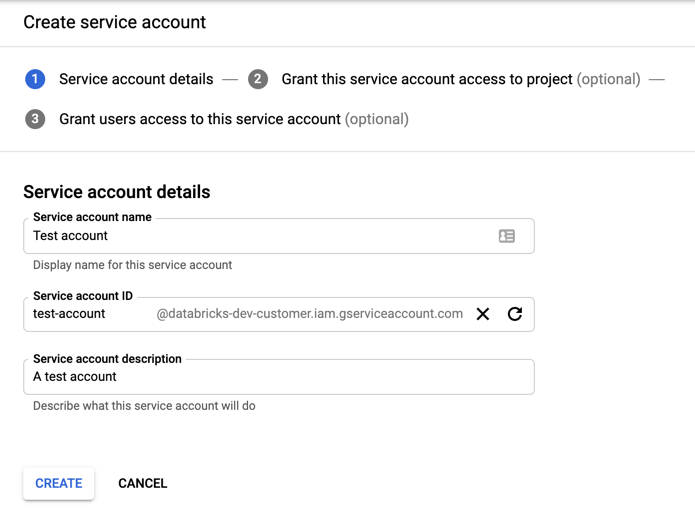
Введите имя и описание учетной записи службы.
Нажмите Создать.
Укажите роли для учетной записи службы. В раскрывающемся списке "Выбор роли " введите
BigQueryи добавьте следующие роли: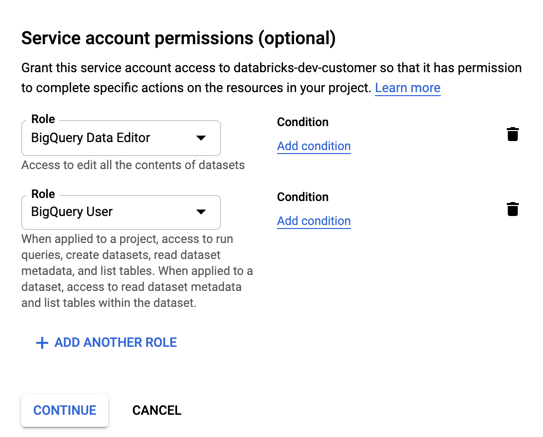
Щелкните CONTINUE (Продолжить).
Нажмите кнопку "ГОТОВО".
Чтобы создать ключи для учетной записи службы, выполните приведенные действия.
В списке учетных записей служб щелкните только что созданную учетную запись.
В разделе "Ключи" нажмите кнопку >Добавить ключ).
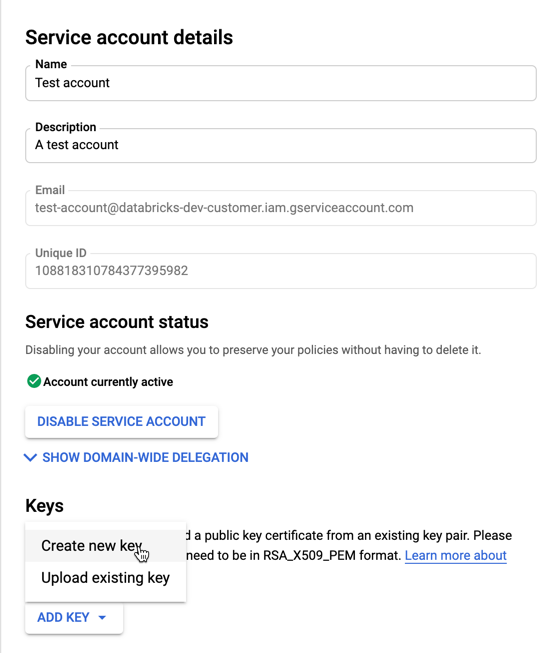
Примите тип ключа JSON .
Нажмите Создать. Файл ключа JSON скачан на компьютер.
Внимание
Файл ключа JSON, создаваемый для учетной записи службы, является закрытым ключом, который должен быть предоставлен только авторизованным пользователям, так как он управляет доступом к наборам данных и ресурсам в учетной записи Google Cloud.
Создание контейнера Google Cloud Storage (GCS) для временного хранилища
Чтобы записать данные в BigQuery, источник данных должен получить доступ к контейнеру GCS.
Щелкните хранилище в левой области навигации.
Нажмите кнопку CREATE BUCKET.
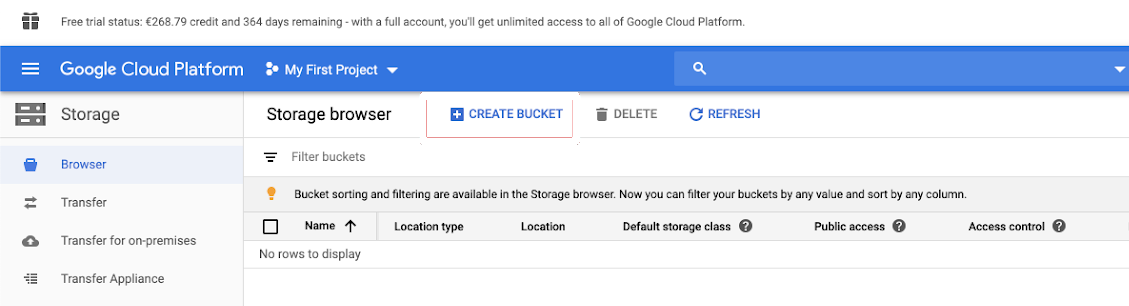
Настройте сведения о контейнере.
Нажмите Создать.
Перейдите на вкладку "Разрешения" и "Добавить участников".
Укажите следующие разрешения для учетной записи сервиса в хранилище.
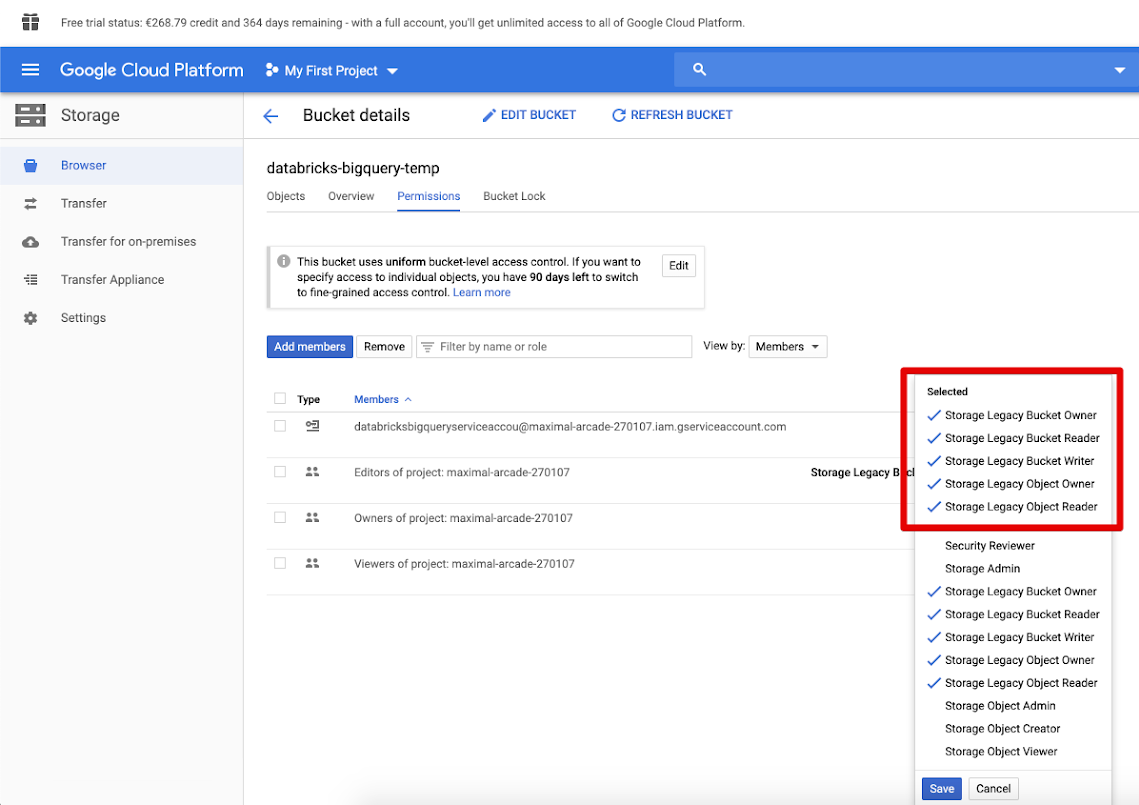
Щелкните СОХРАНИТЬ.
Шаг 2. Настройка Azure Databricks
Чтобы настроить кластер для доступа к таблицам BigQuery, необходимо предоставить файл ключа JSON в качестве конфигурации Spark. Используйте локальное средство для кодирования файла ключа JSON в Base64. В целях безопасности не используйте веб-или удаленное средство, которое может получить доступ к вашим ключам.
На вкладке "Конфигурация Spark" добавьте следующую конфигурацию Spark. Замените <base64-keys> строку файла ключа JSON в кодировке Base64. Замените другие элементы в квадратных скобках (например <client-email>) значениями этих полей из файла ключа JSON.
credentials <base64-keys>
spark.hadoop.google.cloud.auth.service.account.enable true
spark.hadoop.fs.gs.auth.service.account.email <client-email>
spark.hadoop.fs.gs.project.id <project-id>
spark.hadoop.fs.gs.auth.service.account.private.key <private-key>
spark.hadoop.fs.gs.auth.service.account.private.key.id <private-key-id>
Чтение и запись в таблицу BigQuery
Чтобы прочитать таблицу BigQuery, укажите
df = spark.read.format("bigquery") \
.option("table",<table-name>) \
.option("project", <project-id>) \
.option("parentProject", <parent-project-id>) \
.load()
Чтобы записать в таблицу BigQuery, укажите
df.write.format("bigquery") \
.mode("<mode>") \
.option("temporaryGcsBucket", "<bucket-name>") \
.option("table", <table-name>) \
.option("project", <project-id>) \
.option("parentProject", <parent-project-id>) \
.save()
где <bucket-name> имя корзины, которую вы создали в Google Cloud Storage (GCS) для временного хранения. См. раздел Разрешения, чтобы узнать о требованиях к значениям <project-id> и <parent-id>.
Создание внешней таблицы из BigQuery
Внимание
Эта функция не поддерживается каталогом Unity.
Вы можете объявить неуправляемую таблицу в Databricks, которая будет считывать данные непосредственно из BigQuery:
CREATE TABLE chosen_dataset.test_table
USING bigquery
OPTIONS (
parentProject 'gcp-parent-project-id',
project 'gcp-project-id',
temporaryGcsBucket 'some-gcp-bucket',
materializationDataset 'some-bigquery-dataset',
table 'some-bigquery-dataset.table-to-copy'
)
Пример нотбука Python: загрузка таблицы Google BigQuery в DataFrame
Следующая записная книжка Python загружает таблицу Google BigQuery в фрейм данных Azure Databricks.
Пример записной книжки Google BigQuery Python
Пример ноутбука Scala: загрузка таблицы из Google BigQuery в DataFrame
Следующий ноутбук на Scala загружает таблицу из Google BigQuery в DataFrame платформы Azure Databricks.