Устаревшее Обслуживание моделей MLflow в Azure Databricks
Внимание
Эта функция предоставляется в режиме общедоступной предварительной версии.
Внимание
- Поддержка этой документации прекращена, она может больше не обновляться. Продукты, службы или технологии, упомянутые в этом контенте, больше не поддерживаются.
- Руководство в этой статье предназначено для устаревшей модели MLflow. Databricks рекомендует перенести рабочие процессы обслуживания моделей в модель обслуживания для расширенного развертывания конечной точки модели и масштабируемости. Дополнительные сведения см. в статье Развертывание моделей с использованием службы Mosaic AI Model Serving.
Устаревшая служба моделей MLflow позволяет размещать модели машинного обучения из реестра моделей в качестве конечных точек REST, которые обновляются автоматически на основе доступности версий моделей и их этапов. Он использует кластер с одним узлом, который выполняется под собственной учетной записью в пределах того, что теперь называется классической вычислительной плоскости. Эта плоскость вычислений включает виртуальную сеть и связанные с ней вычислительные ресурсы, такие как кластеры для записных книжек и заданий, профессиональные и классические хранилища SQL, а также устаревшие конечные точки обслуживания моделей.
При включении обслуживания моделей для определенной зарегистрированной модели Azure Databricks автоматически создает для модели уникальный кластер и развертывает в нем все неархивные версии модели. Azure Databricks перезапускает кластер при возникновении ошибки и завершает его работу при отключении для модели функции обслуживания моделей. Обслуживание моделей автоматически синхронизирует данные с реестром моделей и развертывает новые зарегистрированные версии модели. Для запроса развернутых версий модели можно использовать стандартные запросы REST API. Azure Databricks использует стандартный способ проверки подлинности для запросов к модели.
Пока эта служба доступна как предварительная версия, Databricks рекомендует использовать ее при низкой пропускной способности для некритических приложений. Целевая пропускная способность — 200 запросов в секунду, а целевая доступность — 99,5 %, хотя эти показатели не гарантируются. Кроме того, существует ограничение на полезные нагрузки в 16 МБ на запрос.
Каждая версия модели развертывается с помощью функции развертывания моделей MLflow и выполняется в среде Conda, заданной зависимостями.
Примечание.
- Кластер сохраняется, пока включено обслуживание, даже если нет ни одной активной версии модели. Чтобы завершить работу обслуживающего кластера, отключите обслуживание для зарегистрированной модели.
- Кластер считается универсальным, и на него распространяется действие всех цен на универсальные рабочие нагрузки.
- Глобальные скрипты инициализации не выполняются в кластерах, обслуживающих модели.
Внимание
Корпорация Anaconda Inc. обновила свои условия предоставления услуг для каналов anaconda.org. В соответствии с новыми условиями предоставления услуг для использования пакетов и распространения Anaconda может потребоваться коммерческая лицензия. Дополнительные сведения см. в часто задаваемых вопросах о коммерческом выпуске Anaconda. Использование любых каналов Anaconda регулируется условиями предоставления услуг Anaconda.
Модели MLflow, зарегистрированные до выхода версии 1.18 (Databricks Runtime 8.3 ML или более ранней версии), по умолчанию регистрировались с каналом conda defaults (https://repo.anaconda.com/pkgs/) в качестве зависимости. Из-за этого изменения условий предоставления услуг компания Databricks прекратила использовать канал defaults для моделей, зарегистрированных с помощью MLflow 1.18 и более поздних версий. По умолчанию теперь регистрируется канал conda-forge, который указывает на управляемый сообществом сайт https://conda-forge.org/.
Если вы зарегистрировали модель до выхода MLflow версии 1.18 и не исключили канал defaults из среды conda для модели, эта модель может иметь зависимость от канала defaults, которая, возможно, не предполагалась.
Чтобы узнать, имеет ли модель эту зависимость, можно проверить значение channel в файле conda.yaml, который упакован с зарегистрированной моделью. Например, conda.yaml модели с зависимостью от канала defaults может выглядеть так:
channels:
- defaults
dependencies:
- python=3.8.8
- pip
- pip:
- mlflow
- scikit-learn==0.23.2
- cloudpickle==1.6.0
name: mlflow-env
Так как Databricks не может определить, разрешено ли вам использовать репозиторий Anaconda для взаимодействия с моделями, Databricks не требует от пользователей вносить какие-либо изменения. Если вы используете репозиторий Anaconda.com с помощью Databricks в соответствии с условиями Anaconda, вам не нужно предпринимать никаких действий.
Если вы хотите изменить канал, используемый в среде модели, можно повторно зарегистрировать модель в реестре моделей с новым conda.yaml. Это можно сделать, указав канал в параметре conda_envlog_model().
Дополнительные сведения об API log_model() см. в документации по MLflow для варианта модели, с которым вы работаете, например log_model для scikit-learn.
Дополнительные сведения о файлах conda.yaml см. в документации по MLflow.
Требования
- Устаревшая служба моделей MLflow доступна для моделей MLflow Python. Необходимо объявить все зависимости модели в среде conda. См . зависимости модели журнала.
- Чтобы включить обслуживание моделей, необходимо разрешение на создание кластера.
Обслуживание моделей из реестра моделей
Обслуживание моделей доступно в Azure Databricks из реестра моделей.
Включение и отключение обслуживания моделей
Модель включается для обслуживания со страницы зарегистрированной модели.
Откройте вкладку Обслуживание. Если для модели еще не включено обслуживание, появится кнопка Включить обслуживание.
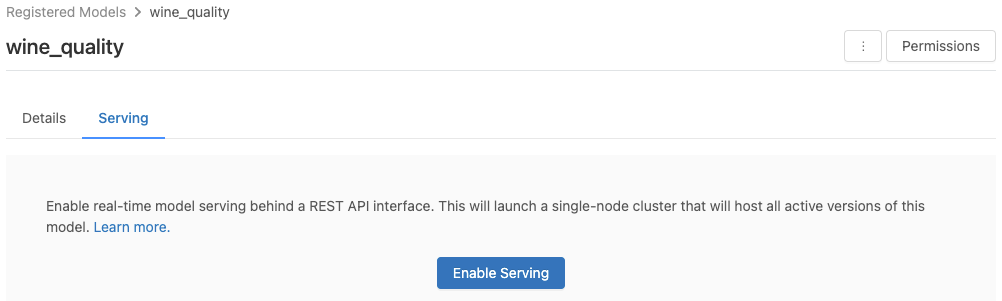
Нажмите кнопку Включить обслуживание. Откроется вкладка "Обслуживание", где будет указано состояние "Ожидание". Через несколько минут состояние изменится на "Готово".
Чтобы отключить модель для обслуживания, нажмите кнопку Остановить.
Проверка обслуживания моделей
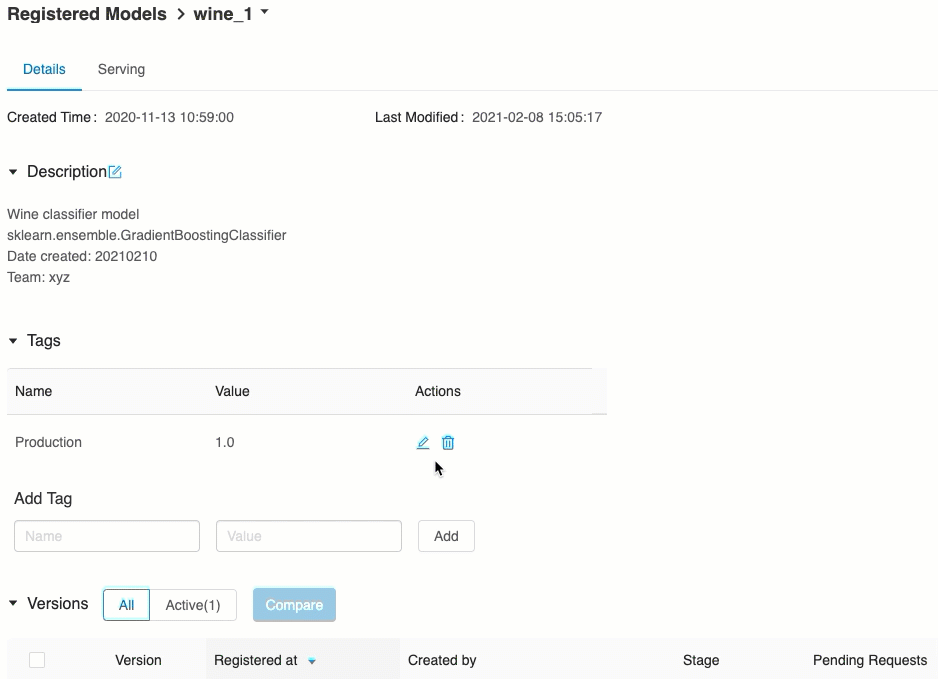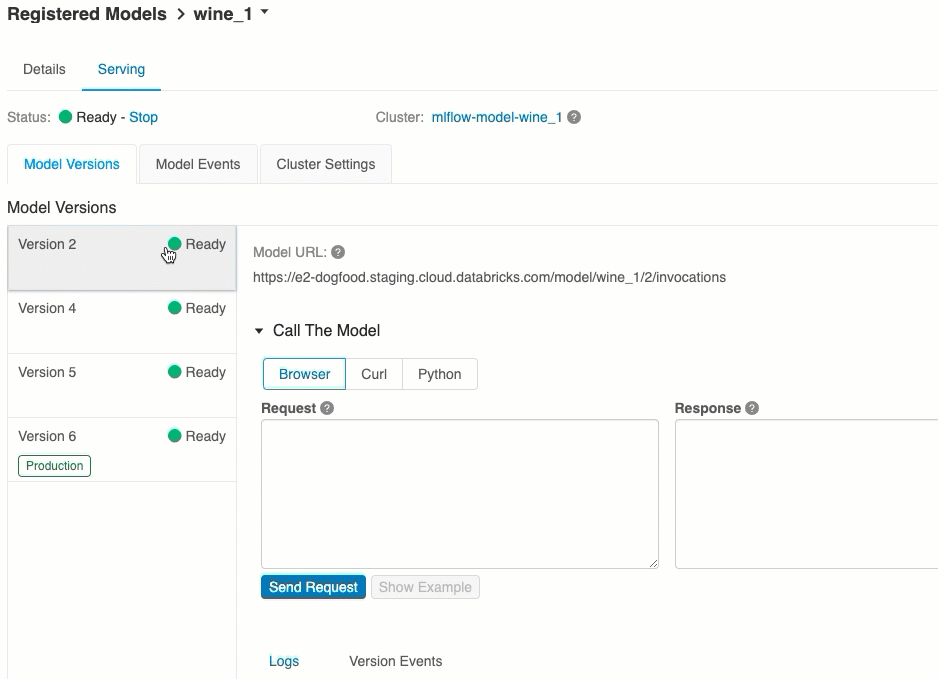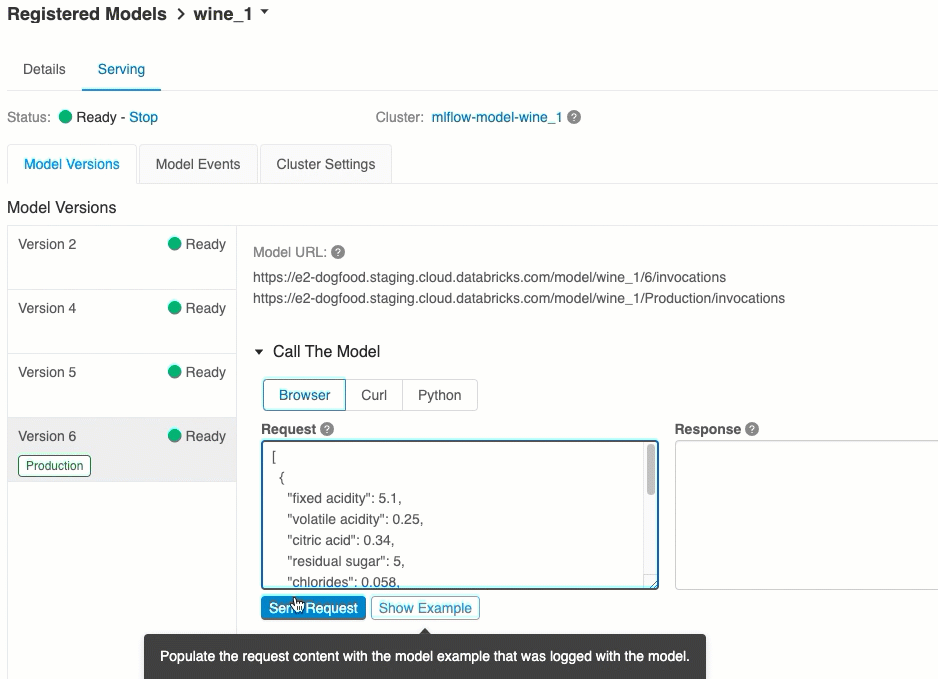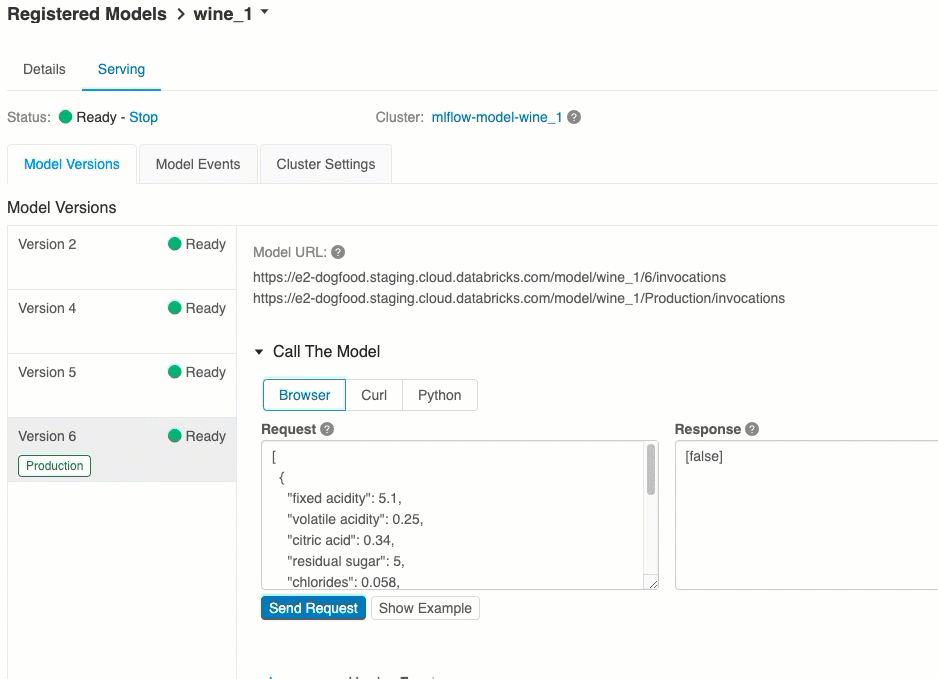
На вкладке Обслуживание можно отправить запрос к обслуживаемой модели и просмотреть ответ.
URL версии модели
Каждой развернутой версии модели назначается один или несколько уникальных URI. Как минимум каждой версии модели назначается URI, создаваемый следующим образом:
<databricks-instance>/model/<registered-model-name>/<model-version>/invocations
Например, чтобы вызвать версию 1 модели, зарегистрированную как iris-classifier, используйте этот URI:
https://<databricks-instance>/model/iris-classifier/1/invocations
Версию модели также можно вызвать по ее этапу. Например, если версия 1 находится на рабочем этапе, ее также можно оценить с помощью этого URI:
https://<databricks-instance>/model/iris-classifier/Production/invocations
Список доступных URI модели отображается в верхней части вкладки "Версии модели" на странице обслуживания.
Управление обслуживаемыми версиями
Развертываются все активные (неархивированные) версии модели, и их можно запросить по URI. Azure Databricks автоматически развертывает новые версии модели при их регистрации и автоматически удаляет старые версии при архивировании.
Примечание.
Все развернутые версии зарегистрированной модели используют один и тот же кластер.
Управление правами доступа к модели
Права доступа к модели наследуются из реестра моделей. Для включения или отключения функции обслуживания требуется разрешение "Управление" для зарегистрированной модели. Любой пользователь с правами на чтение может оценить любую из развернутых версий.
Оценка развернутых версий модели
Оценить развернутую модель можно с помощью пользовательского интерфейса или запроса REST API к URI модели.
Оценка через пользовательский интерфейс
Это самый простой и быстрый способ протестировать модель. Входные данные модели можно вставить в формате JSON и нажать Отправить запрос. Если модель была зарегистрирована с входным примером (как показано на рисунке выше), щелкните Загрузить пример, чтобы загрузить входной пример.
Оценка с помощью запроса REST API
Запрос оценки можно отправить через REST API, используя стандартную проверку подлинности. В приведенных ниже примерах демонстрируется проверка подлинности с помощью личного маркера доступа с MLflow 1.x.
Примечание.
В качестве рекомендации по обеспечению безопасности при проверке подлинности с помощью автоматизированных средств, систем, сценариев и приложений Databricks рекомендуется использовать личные маркеры доступа, принадлежащие субъектам-службам, а не пользователям рабочей области. Сведения о создании маркеров для субъектов-служб см. в разделе "Управление маркерами" для субъекта-службы.
Учитывая MODEL_VERSION_URI, например https://<databricks-instance>/model/iris-classifier/Production/invocations (где <databricks-instance> является именем экземпляра Databricks) и маркером REST API Databricks с именем DATABRICKS_API_TOKEN, в следующих примерах показано, как запрашивать обслуживаемую модель:
В следующих примерах отражается формат оценки для моделей, созданных с помощью MLflow 1.x. Если вы предпочитаете использовать MLflow 2.0, необходимо обновить формат данных запроса.
Bash
Фрагмент кода для запроса модели, принимающей на вход кадры данных.
curl -X POST -u token:$DATABRICKS_API_TOKEN $MODEL_VERSION_URI \
-H 'Content-Type: application/json' \
-d '[
{
"sepal_length": 5.1,
"sepal_width": 3.5,
"petal_length": 1.4,
"petal_width": 0.2
}
]'
Фрагмент кода для запроса модели, принимающей на вход тензоры. Входные тензоры должны иметь формат, описанный в документации по API обслуживания TensorFlow.
curl -X POST -u token:$DATABRICKS_API_TOKEN $MODEL_VERSION_URI \
-H 'Content-Type: application/json' \
-d '{"inputs": [[5.1, 3.5, 1.4, 0.2]]}'
Python
import numpy as np
import pandas as pd
import requests
def create_tf_serving_json(data):
return {'inputs': {name: data[name].tolist() for name in data.keys()} if isinstance(data, dict) else data.tolist()}
def score_model(model_uri, databricks_token, data):
headers = {
"Authorization": f"Bearer {databricks_token}",
"Content-Type": "application/json",
}
data_json = data.to_dict(orient='records') if isinstance(data, pd.DataFrame) else create_tf_serving_json(data)
response = requests.request(method='POST', headers=headers, url=model_uri, json=data_json)
if response.status_code != 200:
raise Exception(f"Request failed with status {response.status_code}, {response.text}")
return response.json()
# Scoring a model that accepts pandas DataFrames
data = pd.DataFrame([{
"sepal_length": 5.1,
"sepal_width": 3.5,
"petal_length": 1.4,
"petal_width": 0.2
}])
score_model(MODEL_VERSION_URI, DATABRICKS_API_TOKEN, data)
# Scoring a model that accepts tensors
data = np.asarray([[5.1, 3.5, 1.4, 0.2]])
score_model(MODEL_VERSION_URI, DATABRICKS_API_TOKEN, data)
PowerBI
Чтобы оценить набор данных в Power BI Desktop, выполните указанные ниже действия.
Откройте набор данных, который требуется оценить.
Перейдите в раздел преобразования данных.
Щелкните правой кнопкой мыши на левой панели и выберите создать новый запрос.
Выберите Просмотр > Расширенный редактор.
Замените текст запроса приведенным ниже фрагментом кода, подставив соответствующие значения
DATABRICKS_API_TOKENиMODEL_VERSION_URI.(dataset as table ) as table => let call_predict = (dataset as table ) as list => let apiToken = DATABRICKS_API_TOKEN, modelUri = MODEL_VERSION_URI, responseList = Json.Document(Web.Contents(modelUri, [ Headers = [ #"Content-Type" = "application/json", #"Authorization" = Text.Format("Bearer #{0}", {apiToken}) ], Content = Json.FromValue(dataset) ] )) in responseList, predictionList = List.Combine(List.Transform(Table.Split(dataset, 256), (x) => call_predict(x))), predictionsTable = Table.FromList(predictionList, (x) => {x}, {"Prediction"}), datasetWithPrediction = Table.Join( Table.AddIndexColumn(predictionsTable, "index"), "index", Table.AddIndexColumn(dataset, "index"), "index") in datasetWithPredictionПрисвойте запросу желаемое имя модели.
Откройте расширенный редактор запросов для своего набора данных и примените функцию модели.
Отслеживание обслуживаемых моделей
На странице обслуживания отображаются индикаторы состояния для обслуживающего кластера, а также отдельные версии модели.
- Чтобы проверить состояние обслуживающего кластера, используйте вкладку события модели, в которой отображается список всех событий обслуживания для этой модели.
- Чтобы проверить состояние одной версии модели, откройте вкладку Версии модели и прокрутите экран, чтобы просмотреть вкладки Журналы и События версии.
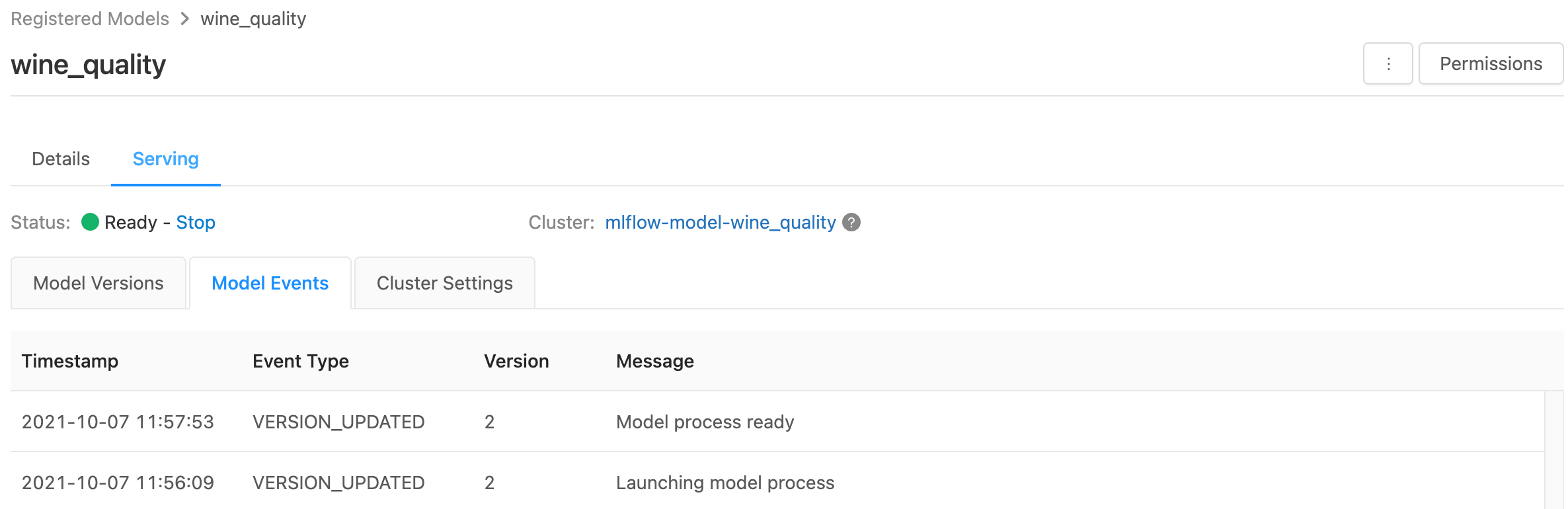
Настройка обслуживающего кластера
Чтобы настроить обслуживающий кластер, используйте вкладку Параметры кластера на вкладке Обслуживание.
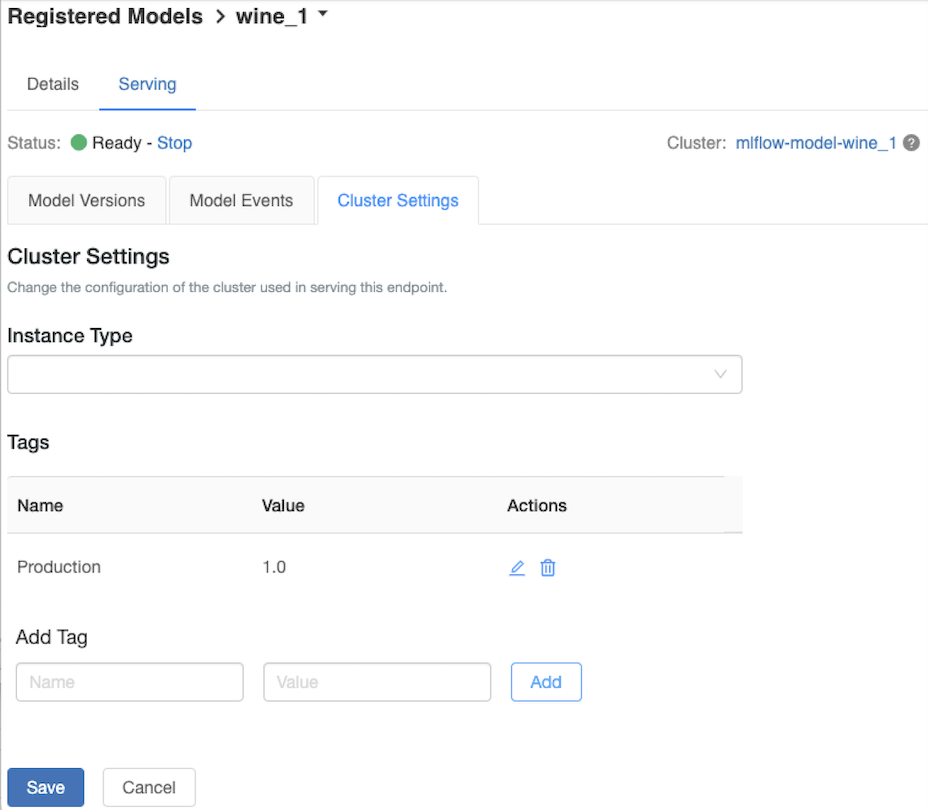
- Чтобы изменить размер памяти и количество ядер обслуживающего кластера, используйте раскрывающееся меню типа экземпляра , чтобы выбрать нужную конфигурацию кластера. После нажатия кнопки Сохранить работа существующего кластера завершается и создается новый кластер с указанными параметрами.
- Чтобы добавить тег, введите имя и значение в поля Добавить тег и нажмите кнопку Добавить.
- Чтобы изменить или удалить существующий тег, щелкните один из значков в столбце действийтаблицы тегов.
Интеграция хранилища компонентов
Устаревшая версия модели может автоматически искать значения функций из опубликованных интернет-магазинов.
.. aws:
Databricks Legacy MLflow Model Serving supports automatic feature lookup from these online stores:
- Amazon DynamoDB (v0.3.8 and above)
- Amazon Aurora (MySQL-compatible)
- Amazon RDS MySQL
.. azure::
Databricks Legacy MLflow Model Serving supports automatic feature lookup from these online stores:
- Azure Cosmos DB (v0.5.0 and above)
- Azure Database for MySQL
Известные ошибки
ResolvePackageNotFound: pyspark=3.1.0
Эта ошибка может возникать, если модель зависит от pyspark и зарегистрирована с помощью Databricks Runtime 8.x.
Если вы видите эту ошибку, укажите версию pyspark явным образом при регистрации журнала модели с помощью параметра conda_env.
Unrecognized content type parameters: format
Эта ошибка может возникать в результате нового формата протокола оценки MLflow 2.0. Если вы видите эту ошибку, скорее всего, используется устаревший формат запроса оценки. Чтобы устранить ошибку, можно:
Обновите формат запроса оценки до поточного протокола.
Примечание.
В следующих примерах отражен формат оценки, представленный в MLflow 2.0. Если вы предпочитаете использовать MLflow 1.x, можно изменить
log_model()вызовы API, чтобы включить в параметр нужную версиюextra_pip_requirementsMLflow. Это гарантирует, что используется соответствующий формат оценки.mlflow.<flavor>.log_model(..., extra_pip_requirements=["mlflow==1.*"])Bash
Запрос модели, принимаюющей входные данные кадра данных pandas.
curl -X POST -u token:$DATABRICKS_API_TOKEN $MODEL_VERSION_URI \ -H 'Content-Type: application/json' \ -d '{ "dataframe_records": [{"sepal_length (cm)": 5.1, "sepal_width (cm)": 3.5, "petal_length (cm)": 1.4, "petal_width": 0.2}, {"sepal_length (cm)": 4.2, "sepal_width (cm)": 5.0, "petal_length (cm)": 0.8, "petal_width": 0.5}] }'Запрос модели, принимаюющей входные данные tensor. Входные тензоры должны иметь формат, описанный в документации по API обслуживания TensorFlow.
curl -X POST -u token:$DATABRICKS_API_TOKEN $MODEL_VERSION_URI \ -H 'Content-Type: application/json' \ -d '{"inputs": [[5.1, 3.5, 1.4, 0.2]]}'Python
import numpy as np import pandas as pd import requests def create_tf_serving_json(data): return {'inputs': {name: data[name].tolist() for name in data.keys()} if isinstance(data, dict) else data.tolist()} def score_model(model_uri, databricks_token, data): headers = { "Authorization": f"Bearer {databricks_token}", "Content-Type": "application/json", } data_dict = {'dataframe_split': data.to_dict(orient='split')} if isinstance(data, pd.DataFrame) else create_tf_serving_json(data) data_json = json.dumps(data_dict) response = requests.request(method='POST', headers=headers, url=model_uri, json=data_json) if response.status_code != 200: raise Exception(f"Request failed with status {response.status_code}, {response.text}") return response.json() # Scoring a model that accepts pandas DataFrames data = pd.DataFrame([{ "sepal_length": 5.1, "sepal_width": 3.5, "petal_length": 1.4, "petal_width": 0.2 }]) score_model(MODEL_VERSION_URI, DATABRICKS_API_TOKEN, data) # Scoring a model that accepts tensors data = np.asarray([[5.1, 3.5, 1.4, 0.2]]) score_model(MODEL_VERSION_URI, DATABRICKS_API_TOKEN, data)PowerBI
Чтобы оценить набор данных в Power BI Desktop, выполните указанные ниже действия.
Откройте набор данных, который требуется оценить.
Перейдите в раздел преобразования данных.
Щелкните правой кнопкой мыши на левой панели и выберите создать новый запрос.
Выберите Просмотр > Расширенный редактор.
Замените текст запроса приведенным ниже фрагментом кода, подставив соответствующие значения
DATABRICKS_API_TOKENиMODEL_VERSION_URI.(dataset as table ) as table => let call_predict = (dataset as table ) as list => let apiToken = DATABRICKS_API_TOKEN, modelUri = MODEL_VERSION_URI, responseList = Json.Document(Web.Contents(modelUri, [ Headers = [ #"Content-Type" = "application/json", #"Authorization" = Text.Format("Bearer #{0}", {apiToken}) ], Content = Json.FromValue(dataset) ] )) in responseList, predictionList = List.Combine(List.Transform(Table.Split(dataset, 256), (x) => call_predict(x))), predictionsTable = Table.FromList(predictionList, (x) => {x}, {"Prediction"}), datasetWithPrediction = Table.Join( Table.AddIndexColumn(predictionsTable, "index"), "index", Table.AddIndexColumn(dataset, "index"), "index") in datasetWithPredictionПрисвойте запросу желаемое имя модели.
Откройте расширенный редактор запросов для своего набора данных и примените функцию модели.
Если запрос оценки использует клиент MLflow, например
mlflow.pyfunc.spark_udf(), обновите клиент MLflow до версии 2.0 или более поздней, чтобы использовать последний формат. Дополнительные сведения об обновленном протоколе оценки модели MLflow в MLflow 2.0.
Дополнительные сведения о форматах входных данных, принимаемых сервером (например, формат для разделения pandas), см. в документации по MLflow.