Доступ к Azure Data Lake Storage с помощью сквозного руководства учетных данных идентификатора Microsoft Entra (устаревшая версия)
Внимание
Поддержка этой документации прекращена, она может больше не обновляться.
Сквозное руководство по учетным данным устарело, начиная с Databricks Runtime 15.0 и будет удалено в будущих версиях Databricks Runtime. Databricks рекомендует выполнить обновление до каталога Unity. Каталог Unity помогает упростить защиту и управление данными благодаря централизованному управлению и проверке доступа к данным во множестве рабочих областей в вашей учетной записи. См. статью Что такое Unity Catalog?
Для обеспечения повышенной безопасности и системы управления обратитесь к группе учетных записей Azure Databricks, чтобы отключить сквозное руководство учетных данных в учетной записи Azure Databricks.
Примечание.
Эта статья содержит упоминания термина whitelisted (включено в список разрешений), который больше не используется в Azure Databricks. Когда этот термин будет удален из программного обеспечения, мы удалим его из статьи.
Вы можете автоматически пройти проверку подлинности для доступа к Azure Data Lake Storage 1-го поколения из Azure Databricks (ADLS 1-го поколения) и ADLS 2-го поколения из кластеров Azure Databricks с помощью того же удостоверения идентификатора Microsoft Entra, который вы используете для входа в Azure Databricks. Когда вы включаете в своем кластере сквозную передачу учетных данных Azure Data Lake Storage, команды, которые вы запускаете в этом кластере, могут читать и записывать данные в Azure Data Lake Storage без необходимости настройки учетных данных субъекта-службы для доступа к хранилищу.
Сквозная передача учетных данных Azure Data Lake Storage поддерживается только для Azure Data Lake Storage 1-го и 2-го поколения. Хранилище BLOB-объектов Azure ее не поддерживает.
В этой статье рассматриваются следующие вопросы:
- Включение сквозной передачи учетных данных для стандартных кластеров и кластеров с высокой степенью параллелизма.
- Настройка сквозной передачи учетных данных и инициализация ресурсов хранилища в учетных записях ADLS.
- Доступ к ресурсам ADLS напрямую при включенной сквозной передаче учетных данных.
- Доступ к ресурсам ADLS через точку подключения при включенной сквозной передаче учетных данных.
- Поддерживаемые функции и ограничения при использовании сквозной передачи учетных данных.
В статью включены записные книжки, в которых приведены примеры использования сквозной передачи учетных данных для учетных записей хранения ADLS 1-го поколения и ADLS 2-го поколения.
Требования
- План "Премиум". Дополнительные сведения об обновлении плана "Стандартный" до плана "Премиум" см. в статье Обновление или переход на использование более ранней версии рабочей области Azure Databricks.
- Учетная запись хранения Azure Data Lake Storage 1-го или 2-го поколения. Для работы со сквозной передачей учетных данных учетные записи хранения Azure Data Lake Storage 2-го поколения должны использовать иерархическое пространство имен. Инструкции по созданию новой учетной записи ADLS 2-го поколения, в том числе о включении иерархического пространства имен, см. в статье Создание учетной записи хранения.
- Правильно настроенные разрешения пользователей для Azure Data Lake Storage. Администратор Azure Databricks должен убедиться, что у пользователей есть необходимые роли, например "Участник для данных BLOB-объектов хранилища", для чтения и записи данных, хранящихся в Azure Data Lake Storage. См. статью о назначении роли Azure для доступа к большим двоичным объектам и данным очереди с помощью портала Azure.
- Сведения о привилегиях администраторов рабочих областей в рабочих областях, которые включены для сквозного руководства, и просмотрите существующие назначения администратора рабочей области. Администраторы рабочей области могут управлять операциями для своей рабочей области, включая добавление пользователей и субъектов-служб, создание кластеров и делегирование других пользователей администраторам рабочей области. Задачи управления рабочими областями, такие как управление владением заданиями и просмотр записных книжек, могут предоставлять косвенный доступ к данным, зарегистрированным в Azure Data Lake Storage. Администратор рабочей области — это привилегированная роль, которую следует тщательно распределить.
- Для сквозной передачи учетных данных нельзя использовать кластер, настроенный с учетными данными ADLS, например учетными данными субъекта-службы.
Внимание
Невозможно выполнить проверку подлинности в Azure Data Lake Storage с помощью учетных данных идентификатора Microsoft Entra, если вы находитесь за брандмауэром, который не был настроен для разрешения трафика на идентификатор Microsoft Entra. Брандмауэр Azure блокирует доступ к Active Directory по умолчанию. Чтобы разрешить доступ, настройте тег службы AzureActiveDirectory. Аналогичные сведения для сетевых виртуальных модулей можно найти по тегу AzureActiveDirectory в файле JSON "Диапазоны IP-адресов и теги служб Azure". Дополнительные сведения см. в статье Теги службы Брандмауэра Azure.
Рекомендации по ведению журналов
Вы можете регистрировать идентификаторы, передаваемые в хранилище ADLS, в журналах диагностики службы хранилища Azure. Регистрация идентификаторов позволяет связывать запросы ADLS с отдельными пользователями из кластеров Azure Databricks. Включите ведение журнала диагностики в учетной записи хранения, чтобы начать получать эти журналы:
- Azure Data Lake Storage 1-го поколения — следуйте инструкциям в разделе Включение ведения журнала диагностики для учетной записи Data Lake Storage 1-го поколения.
- Azure Data Lake Storage 2-го поколения — настройте с помощью команды PowerShell
Set-AzStorageServiceLoggingProperty. В качестве версии укажите 2,0, так как формат записи журнала 2.0 включает имя участника-пользователя в запросе.
Включение сквозной передачи учетных данных Azure Data Lake Storage для кластера с высокой степенью параллелизма
Кластеры с высокой степенью параллелизма могут совместно использоваться несколькими пользователями. Вместе со сквозной передачей учетных данных Azure Data Lake Storage эти кластеры поддерживают только Python и SQL.
Внимание
Включение сквозной передачи учетных данных Azure Data Lake Storage для кластера с высоким уровнем параллелизма блокирует все порты в кластере, за исключением портов 44, 53 и 80.
- При создании кластера задайте для параметра Cluster Mode (Режим кластера) значение High Concurrency (Высокая степень параллелизма).
- В разделе Advanced Options (Дополнительные параметры) выберите Enable credential passthrough for user-level data access and only allow Python and SQL commands (Включить сквозную передачу учетных данных для доступа к данным на уровне пользователя и разрешить только команды Python и SQL).

Включение сквозной передачи учетных данных Azure Data Lake Storage для стандартного кластера
Стандартные кластеры со сквозной передачей учетных данных ограничены одним пользователем. Стандартные кластеры поддерживают Python, SQL, Scala и R. В Databricks Runtime 10.4 LTS и более поздних версиях поддерживается sparklyr.
Необходимо назначить пользователя при создании кластера, но кластер может изменяться пользователем с разрешениями CAN MANAGE в любое время, чтобы заменить исходного пользователя.
Внимание
Пользователь, назначенный кластеру, должен иметь по крайней мере разрешение CAN ATTACH TO для кластера, чтобы выполнять команды в кластере. Администраторы рабочей области и создатель кластера имеют разрешения CAN MANAGE, но не могут выполнять команды в кластере, если они не являются назначенным пользователем кластера.
- При создании кластера задайте для параметра Cluster Mode (Режим кластера) значение Standard (Стандартный).
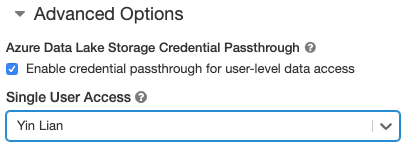
- В разделе Advanced Options (Дополнительные параметры) выберите Enable credential passthrough for user-level data access (Включить сквозную передачу учетных данных для доступа к данным на уровне пользователя) и выберите имя пользователя из раскрывающегося списка Single User Access (Доступ одного пользователя).
Создание контейнера
Контейнеры предоставляют способ организации объектов в учетной записи хранения Azure.
Доступ к Azure Data Lake Storage напрямую с использованием сквозной передачи учетных данных
После настройки сквозной передачи учетных данных Azure Data Lake Storage и создания контейнеров хранилища вы можете получить доступ к данным напрямую в Azure Data Lake Storage 1-го поколения с помощью пути adl:// и в Azure Data Lake Storage 2-го поколения с помощью пути abfss://.
Azure Data Lake Storage 1-го поколения.
Python
spark.read.format("csv").load("adl://<storage-account-name>.azuredatalakestore.net/MyData.csv").collect()
R
# SparkR
library(SparkR)
sparkR.session()
collect(read.df("adl://<storage-account-name>.azuredatalakestore.net/MyData.csv", source = "csv"))
# sparklyr
library(sparklyr)
sc <- spark_connect(method = "databricks")
sc %>% spark_read_csv("adl://<storage-account-name>.azuredatalakestore.net/MyData.csv") %>% sdf_collect()
- Замените
<storage-account-name>на имя учетной записи хранения ADLS 1-го поколения.
Azure Data Lake Storage 2-го поколения
Python
spark.read.format("csv").load("abfss://<container-name>@<storage-account-name>.dfs.core.windows.net/MyData.csv").collect()
R
# SparkR
library(SparkR)
sparkR.session()
collect(read.df("abfss://<container-name>@<storage-account-name>.dfs.core.windows.net/MyData.csv", source = "csv"))
# sparklyr
library(sparklyr)
sc <- spark_connect(method = "databricks")
sc %>% spark_read_csv("abfss://<container-name>@<storage-account-name>.dfs.core.windows.net/MyData.csv") %>% sdf_collect()
- Замените
<container-name>на имя контейнера в учетной записи хранения ADLS 2-го поколения. - Замените
<storage-account-name>на имя учетной записи хранения ADLS 2-го поколения.
Подключение Azure Data Lake Storage к DBFS с использованием сквозной передачи учетных данных
Вы можете подключить учетную запись Azure Data Lake Storage или папку внутри нее к DBFS?. Такое подключение является лишь указателем на Data Lake Store, то есть данные никогда не синхронизируются в локальную среду.
При подключении данных с помощью отказоустойчивого кластера с помощью сквозного руководства учетных данных Azure Data Lake Storage любые данные чтения или записи в точку подключения используют учетные данные идентификатора Microsoft Entra. Эта точка подключения будет видна другим пользователям, но только пользователи, у которых есть доступ для чтения и записи:
- имеют доступ к базовой учетной записи хранения Azure Data Lake Storage;
- используют кластер с включенным сквозным режимом учетных данных Azure Data Lake Storage.
Azure Data Lake Storage 1-го поколения.
Чтобы подключить ресурс Azure Data Lake Storage 1-го поколения или папку внутри него, используйте следующие команды:
Python
configs = {
"fs.adl.oauth2.access.token.provider.type": "CustomAccessTokenProvider",
"fs.adl.oauth2.access.token.custom.provider": spark.conf.get("spark.databricks.passthrough.adls.tokenProviderClassName")
}
# Optionally, you can add <directory-name> to the source URI of your mount point.
dbutils.fs.mount(
source = "adl://<storage-account-name>.azuredatalakestore.net/<directory-name>",
mount_point = "/mnt/<mount-name>",
extra_configs = configs)
Scala
val configs = Map(
"fs.adl.oauth2.access.token.provider.type" -> "CustomAccessTokenProvider",
"fs.adl.oauth2.access.token.custom.provider" -> spark.conf.get("spark.databricks.passthrough.adls.tokenProviderClassName")
)
// Optionally, you can add <directory-name> to the source URI of your mount point.
dbutils.fs.mount(
source = "adl://<storage-account-name>.azuredatalakestore.net/<directory-name>",
mountPoint = "/mnt/<mount-name>",
extraConfigs = configs)
- Замените
<storage-account-name>на имя учетной записи хранения ADLS 2-го поколения. - Замените
<mount-name>на имя предполагаемой точки подключения в DBFS.
Azure Data Lake Storage 2-го поколения
Чтобы подключить файловую систему Azure Data Lake Storage 2-го поколения или папку внутри нее, используйте следующие команды:
Python
configs = {
"fs.azure.account.auth.type": "CustomAccessToken",
"fs.azure.account.custom.token.provider.class": spark.conf.get("spark.databricks.passthrough.adls.gen2.tokenProviderClassName")
}
# Optionally, you can add <directory-name> to the source URI of your mount point.
dbutils.fs.mount(
source = "abfss://<container-name>@<storage-account-name>.dfs.core.windows.net/",
mount_point = "/mnt/<mount-name>",
extra_configs = configs)
Scala
val configs = Map(
"fs.azure.account.auth.type" -> "CustomAccessToken",
"fs.azure.account.custom.token.provider.class" -> spark.conf.get("spark.databricks.passthrough.adls.gen2.tokenProviderClassName")
)
// Optionally, you can add <directory-name> to the source URI of your mount point.
dbutils.fs.mount(
source = "abfss://<container-name>@<storage-account-name>.dfs.core.windows.net/",
mountPoint = "/mnt/<mount-name>",
extraConfigs = configs)
- Замените
<container-name>на имя контейнера в учетной записи хранения ADLS 2-го поколения. - Замените
<storage-account-name>на имя учетной записи хранения ADLS 2-го поколения. - Замените
<mount-name>на имя предполагаемой точки подключения в DBFS.
Предупреждение
Не следует предоставлять ключи доступа к учетной записи хранения или учетные данные субъекта-службы для проверки подлинности в точке подключения. Это позволит другим пользователям получить доступ к файловой системе, используя эти учетные данные. Цель сквозной передачи учетных данных Azure Data Lake Storage заключается в том, чтобы предотвратить использование этих учетных данных и обеспечить доступ к файловой системе только для пользователей, имеющих доступ к базовой учетной записи Azure Data Lake Storage.
Безопасность
Вы можете безопасно использовать кластеры со сквозной передачей учетных данных Azure Data Lake Storage совместно с другими пользователями. Вы будете изолированы друг от друга и не сможете считывать и использовать учетные данные друг друга.
Поддерживаемые возможности
| Функция | Минимальная версия Databricks Runtime | Примечания. |
|---|---|---|
| Python и SQL | 5.5 | |
| Хранилище Azure Data Lake Storage 1-го поколения | 5.5 | |
%run |
5.5 | |
| Файловая система Databricks | 5.5 | Сквозная передача учетных данных осуществляется только в том силучае, если путь DBFS разрешается в расположение в Azure Data Lake Storage 1-го поколения или 2-го поколения. Для путей DBFS, которые разрешаются в других системах хранения, используйте для указания учетных данных другой метод. |
| Azure Data Lake Storage 2-го поколения | 5.5 | |
| кэширование дисков | 5.5 | |
| API ML PySpark | 5.5 |
Не поддерживаются следующие классы ML: - org/apache/spark/ml/classification/RandomForestClassifier- org/apache/spark/ml/clustering/BisectingKMeans- org/apache/spark/ml/clustering/GaussianMixture- org/spark/ml/clustering/KMeans- org/spark/ml/clustering/LDA- org/spark/ml/evaluation/ClusteringEvaluator- org/spark/ml/feature/HashingTF- org/spark/ml/feature/OneHotEncoder- org/spark/ml/feature/StopWordsRemover- org/spark/ml/feature/VectorIndexer- org/spark/ml/feature/VectorSizeHint- org/spark/ml/regression/IsotonicRegression- org/spark/ml/regression/RandomForestRegressor- org/spark/ml/util/DatasetUtils |
| Широковещательные переменные | 5.5 | В пределах PySpark существует ограничение на размер определяемых пользователем функций Python, так как большие пользовательские функции передаются как широковещательные переменные. |
| Библиотеки с областью действия записной книжки | 5.5 | |
| Scala | 5.5 | |
| SparkR | 6,0 | |
| sparklyr | 10,1 | |
| Организация записных книжек и модульное упорядочивание кода в записных книжках | 6.1 | |
| API ML PySpark | 6.1 | Поддерживаются все классы ML PySpark. |
| Метрики кластера | 6.1 | |
| Databricks Connect | 7.3 | Сквозная передача учетных данных в кластерах уровня "Стандартный". |
Ограничения
Следующие функции не поддерживаются при сквозной передаче учетных данных Azure Data Lake Storage:
-
%fs(вместо этого используйте эквивалентную команду dbutils.fs). - Задания Databricks.
- Справочник по REST API Databricks.
- Каталог Unity.
-
Управление доступом к таблицам. Разрешения, предоставленные сквозной передачей учетных данных Azure Data Lake Storage, можно использовать для обхода детальных разрешений списков управления доступом к таблицам, в то время как дополнительные ограничения этих списков лишают вас некоторых преимуществ сквозной передачи учетных данных. В частности:
- Если у вас есть разрешение На доступ к файлам данных, лежащим в основе определенной таблицы, у вас будут полные разрешения на эту таблицу через API удаленных рабочих столов независимо от ограничений, введенных в них с помощью списков управления доступом к таблицам.
- Вы будете ограничены разрешениями списков управления доступом к таблицам только при использовании API DataFrame. Если вы попытаетесь прочитать файлы непосредственно с помощью API DataFrame, вы увидите предупреждения о том, что у вас нет разрешения
SELECTна доступ к файлам, несмотря на то, что их можно прочитать непосредственно через API RDD. - Чтение из таблиц, созданных в файловой системе, отличной от Azure Data Lake Storage, невозможно, даже если для чтения таблиц имеется разрешение списка управления доступом к таблице.
- Следующие методы объектов SparkContext (
sc) и SparkSession (spark):- Нерекомендуемые методы.
- Такие методы, как
addFile()иaddJar(), позволяющие пользователям без прав администратора вызывать код Scala. - Любой метод, обращающийся к файловой системе, отличной от Azure Data Lake Storage 1-го поколения или 2-го поколения (для доступа к другим файловым системам в кластере с включенной сквозной передачей учетных данных Azure Data Lake Storage используйте другой метод, чтобы указать учетные данные, и просмотрите сведения о доверенных файловых системах в раздел Устранении неполадок).
- Старые API Hadoop (
hadoopFile()иhadoopRDD()). - API потоковой передачи, так как срок действия переданных учетных данных истечет во время работы потока.
-
Подключения DBFS (
/dbfs) доступны только в Databricks Runtime 7.3 LTS и более поздних версиях. Точки подключения с настроенным сквозным руководством учетных данных не поддерживаются через этот путь. - Фабрика данных Azure.
- MLflow на кластерах с высоким уровнем параллелизма.
- Пакет Python azureml-sdk с кластерами с высоким уровнем параллелизма.
- Невозможно продлить время существования маркеров сквозного кода Microsoft Entra с помощью политик времени существования маркера идентификатора Microsoft Entra. Как следствие, при отправке кластеру команды, выполнение которой занимает больше часа, произойдет сбой, если доступ к ресурсу Azure Data Lake Storage будет осуществляться после того, как пройдет час.
- При использовании Hive 2.3 и более поздних версий невозможно добавить секцию в кластер с включенной сквозной передачей учетных данных. Подробнее см. в соответствующей части раздела Устранение неполадок.
Примеры записных книжек
Записные книжки ниже демонстрируют сквозную передачу учетных данных Azure Data Lake Storage для Azure Data Lake Storage 1-го поколения и 2-го поколения.
Записная книжка, демонстрирующая использование сквозного режима учетных данных Azure Data Lake Storage 1-го поколения
Записная книжка, демонстрирующая использование сквозного режима учетных данных Azure Data Lake Storage 2-го поколения
Устранение неполадок
py4j.security.Py4JSecurityException: … нет в списке разрешений
Это исключение возникает при получении доступа к методу, который Azure Databricks не пометил явно как безопасный для транзитных кластеров учетных данных Azure Data Lake Storage. В большинстве случаев это означает, что метод может позволить пользователю в кластере сквозной передачи учетных данных Azure Data Lake Storage получить доступ к учетным данным другого пользователя.
org.apache.spark.api.python.PythonSecurityException: Path … использует недоверенную файловую систему
Это исключение возникает при попытке получить доступ к файловой системе, о безопасности которой кластеру со сквозной передачей учетных данных Azure Data Lake Storage неизвестно. Использование недоверенной файловой системы может позволить пользователю в кластере со сквозной передачей учетных данных Azure Data Lake Storage получить доступ к учетным данным другого пользователя, поэтому мы запрещаем все файловые системы, в безопасности использования которых не уверены.
Чтобы настроить набор доверенных файловых систем в кластере со сквозной передачей учетных данных Azure Data Lake Storage, задайте в ключе конфигурации Spark spark.databricks.pyspark.trustedFilesystems в этом кластере разделенный запятыми список имен классов, которые являются доверенными реализациями org.apache.hadoop.fs.FileSystem.
Добавление секции завершается сбоем с исключением AzureCredentialNotFoundException при включенной сквозной передачей учетных данных
При использовании Hive 2.3-3.1 при попытке добавить секцию в кластер со включенной сквозной передачей учетных данных возникает следующее исключение:
org.apache.spark.sql.AnalysisException: org.apache.hadoop.hive.ql.metadata.HiveException: MetaException(message:com.databricks.backend.daemon.data.client.adl.AzureCredentialNotFoundException: Could not find ADLS Gen2 Token
Чтобы обойти эту ошибку, добавьте секции в кластер без включенной сквозной передачи учетных данных.