Справочник по таблицам системы работы
Примечание.
Схема lakeflow ранее была известна как workflow. Содержимое обеих схем идентично. Чтобы сделать схему lakeflow видимой, необходимо включить ее отдельно.
В этой статье описывается, как использовать системные таблицы lakeflow для мониторинга заданий в вашей учетной записи. Эти таблицы включают записи из всех рабочих областей в учетной записи, развернутой в одном облачном регионе. Чтобы просмотреть записи из другого региона, необходимо просмотреть таблицы из рабочей области, развернутой в этом регионе.
Требования
- Схема
system.lakeflowдолжна быть включена администратором учетной записи. См. Включение системных схем таблиц. - Для доступа к этим системным таблицам пользователям необходимо:
- Быть администратором хранилища метаданных и администратором учетной записи или
- Иметь разрешения
USEиSELECTна системные схемы. См. Предоставить доступ к системным таблицам.
Доступные таблицы заданий
Все таблицы системы, связанные с заданиями, располагаются в схеме system.lakeflow. В настоящее время схема содержит четыре таблицы:
| Стол | Описание | Поддерживает потоковую передачу | Бесплатный срок хранения | Включает глобальные или региональные данные |
|---|---|---|---|---|
| задания (общедоступная предварительная версия) | Отслеживает все задания, созданные в учетной записи | Да | 365 дней | Региональный |
| job_tasks (общедоступная предварительная версия) | Отслеживает все задачи, выполняемые в учетной записи | Да | 365 дней | Региональный |
| job_run_timeline (общедоступная предварительная версия) | Отслеживает выполнение задания и связанные метаданные | Да | 365 дней | Региональный |
| job_task_run_timeline (общедоступная предварительная версия) | Отслеживает выполнение задачи задания и связанные метаданные | Да | 365 дней | Региональный |
Подробная справочная информация по схеме
В следующих разделах приведены ссылки на схемы для каждой из системных таблиц, связанных с заданиями.
Схема таблицы заданий
Таблица jobs — это медленно изменяющаяся таблица измерений (SCD2). При изменении строки создается новая строка, логически заменяющая предыдущую.
путь к таблице: system.lakeflow.jobs
| Имя столбца | Тип данных | Описание | Примечания |
|---|---|---|---|
account_id |
строка | Идентификатор учетной записи, к которой принадлежит это задание | |
workspace_id |
строка | Идентификатор рабочей области, к которой принадлежит это задание | |
job_id |
строка | Идентификатор задания | Уникальны только в пределах одной рабочей области |
name |
строка | Указанное пользователем имя задания | |
description |
строка | Предоставленное пользователем описание задания | Это поле пусто, если у вас есть ключи, управляемые клиентом, настроены. Не заполнено для строк, выпущенных до второй половины августа 2024 г. |
creator_id |
строка | Идентификатор основного субъекта, создавшего задание | |
tags |
строка | Предоставленные пользователем пользовательские теги, связанные с этим заданием | |
change_time |
временная метка | Время последнего изменения задания | Часовой пояс, записанный как +00:00 (UTC) |
delete_time |
метка времени | Время удаления задания пользователем | Часовой пояс, записанный как +00:00 (UTC) |
run_as |
строка | Идентификатор пользователя или учетной записи службы, права доступа которой используются для выполнения задания. |
Пример запроса
-- Get the most recent version of a job
SELECT
*,
ROW_NUMBER() OVER(PARTITION BY workspace_id, job_id ORDER BY change_time DESC) as rn
FROM
system.lakeflow.jobs QUALIFY rn=1
схема таблицы рабочих задач
Таблица заданий — это медленно изменяющаяся таблица измерений (SCD2). При изменении строки создается новая строка, логически заменяющая предыдущую.
путь к таблице: system.lakeflow.job_tasks
| Имя столбца | Тип данных | Описание | Примечания |
|---|---|---|---|
account_id |
строка | Идентификатор учетной записи, к которой принадлежит это задание | |
workspace_id |
строка | Идентификатор рабочей области, к которой принадлежит это задание | |
job_id |
строка | Идентификатор задания | Уникальны только в пределах одной рабочей области |
task_key |
строка | Ключ ссылки для задачи в задании | Уникально только в пределах одного задания |
depends_on_keys |
массив | Ключи задач всех вышестоящих зависимостей этой задачи | |
change_time |
отметка времени | Время последнего изменения задачи | Часовой пояс, записанный как +00:00 (UTC) |
delete_time |
отметка времени | Время удаления задачи пользователем | Часовой пояс, записанный как +00:00 (UTC) |
Пример запроса
-- Get the most recent version of a job task
SELECT
*,
ROW_NUMBER() OVER(PARTITION BY workspace_id, job_id ORDER BY change_time DESC) as rn
FROM
system.lakeflow.job_tasks QUALIFY rn=1
схема таблицы временной шкалы запуска задания
Таблица временной шкалы выполнения задания является неизменяемой и окончательной в момент её создания.
путь к таблице: system.lakeflow.job_run_timeline
| Имя столбца | Тип данных | Описание | Примечания |
|---|---|---|---|
account_id |
строка | Идентификатор учетной записи, к которой принадлежит это задание | |
workspace_id |
строка | Идентификатор рабочей области, к которой принадлежит это задание | |
job_id |
строка | Идентификатор задания | Этот ключ является уникальным только в одной рабочей области. |
run_id |
строка | Идентификатор выполнения задания | |
period_start_time |
метка времени | Время начала забега или временного периода | Сведения о часовом поясе записываются в конце значения с +00:00, представляющей UTC |
period_end_time |
метка времени | Время окончания запуска или периода времени | Сведения о часовом поясе записываются в конце значения с +00:00, представляющей UTC |
trigger_type |
строка | Тип триггера, который может запустить выполнение | Возможные значения см. в значения типа триггера |
run_type |
строка | Тип выполнения задания | Возможные значения можно найти в разделе Значения типов запуска |
run_name |
строка | Указанное пользователем имя запуска, связанное с этим заданием | |
compute_ids |
массив | Массив, содержащий идентификаторы вычислительных задач для запуска родительского задания | Используется для идентификации кластера заданий, используемого типами выполнения WORKFLOW_RUN. Дополнительные сведения о вычислениях см. в таблице job_task_run_timeline.Не заполнено для строк, эмитированных до конца августа 2024 года. |
result_state |
строка | Результат выполнения задания | Возможные значения см. в разделе Значения состояния результатов |
termination_code |
строка | Код завершения выполнения задания | Возможные значения см. в разделе Значения кода завершения. Не заполнено для строк, выпущенных до конца августа 2024 г. |
job_parameters |
карта | Параметры уровня задания, используемые в выполнении задания | Устаревшие параметры notebook_params не включены в это поле. Не заполнено для строк, выпущенных до конца второй половины августа 2024 г. |
Пример запроса
-- This query gets the daily job count for a workspace for the last 7 days:
SELECT
workspace_id,
COUNT(DISTINCT run_id) as job_count,
to_date(period_start_time) as date
FROM system.lakeflow.job_run_timeline
WHERE
period_start_time > CURRENT_TIMESTAMP() - INTERVAL 7 DAYS
GROUP BY ALL
-- This query returns the daily job count for a workspace for the last 7 days, distributed by the outcome of the job run.
SELECT
workspace_id,
COUNT(DISTINCT run_id) as job_count,
result_state,
to_date(period_start_time) as date
FROM system.lakeflow.job_run_timeline
WHERE
period_start_time > CURRENT_TIMESTAMP() - INTERVAL 7 DAYS
AND result_state IS NOT NULL
GROUP BY ALL
-- This query returns the average time of job runs, measured in seconds. The records are organized by job. A top 90 and a 95 percentile column show the average lengths of the job's longest runs.
with job_run_duration as (
SELECT
workspace_id,
job_id,
run_id,
CAST(SUM(period_end_time - period_start_time) AS LONG) as duration
FROM
system.lakeflow.job_run_timeline
WHERE
period_start_time > CURRENT_TIMESTAMP() - INTERVAL 7 DAYS
GROUP BY ALL
)
SELECT
t1.workspace_id,
t1.job_id,
COUNT(DISTINCT t1.run_id) as runs,
MEAN(t1.duration) as mean_seconds,
AVG(t1.duration) as avg_seconds,
PERCENTILE(t1.duration, 0.9) as p90_seconds,
PERCENTILE(t1.duration, 0.95) as p95_seconds
FROM
job_run_duration t1
GROUP BY ALL
ORDER BY mean_seconds DESC
LIMIT 100
-- This query provides a historical runtime for a specific job based on the `run_name` parameter. For the query to work, you must set the `run_name`.
SELECT
workspace_id,
run_id,
SUM(period_end_time - period_start_time) as run_time
FROM system.lakeflow.job_run_timeline
WHERE
run_type="SUBMIT_RUN"
AND run_name = :run_name
AND period_start_time > CURRENT_TIMESTAMP() - INTERVAL 60 DAYS
GROUP BY ALL
-- This query collects a list of retried job runs with the number of retries for each run.
with repaired_runs as (
SELECT
workspace_id, job_id, run_id, COUNT(*) - 1 as retries_count
FROM system.lakeflow.job_run_timeline
WHERE result_state IS NOT NULL
GROUP BY ALL
HAVING retries_count > 0
)
SELECT
*
FROM repaired_runs
ORDER BY retries_count DESC
LIMIT 10;
схема таблицы временной шкалы выполнения рабочего задания
Таблица временной шкалы запуска задачи неизменна и завершена на момент создания.
путь к таблице: system.lakeflow.job_task_run_timeline
| Имя столбца | Тип данных | Описание | Примечания |
|---|---|---|---|
account_id |
строка | Идентификатор учетной записи, к которой принадлежит это задание | |
workspace_id |
строка | Идентификатор рабочей области, к которой принадлежит это задание | |
job_id |
строка | Идентификатор задания | Уникальны только в пределах одной рабочей области |
run_id |
строка | Идентификатор выполнения задачи | |
job_run_id |
строка | Идентификатор запуска задания | Не заполнено для строк, выпущенных до конца августа 2024 г. |
parent_run_id |
строка | Идентификатор родительского запуска | Не заполнено для строк, выпущенных до конца второй половины августа 2024 г. |
period_start_time |
отметка времени | Время начала задачи или периода времени | Сведения о часовом поясе записываются в конце значения с +00:00, представляющей UTC |
period_end_time |
отметка времени | Время окончания задачи или периода времени | Сведения о часовом поясе записываются в конце значения с +00:00, представляющей UTC |
task_key |
строка | Ключ ссылки для задачи в задании | Этот ключ является уникальным только в рамках одного задания |
compute_ids |
массив | Массив compute_ids содержит идентификаторы кластеров заданий, интерактивных кластеров и хранилищ SQL, используемых задачей задания. | |
result_state |
строка | Результат выполнения задания | Возможные значения см. в разделе Значения состояния результатов |
termination_code |
строка | Код завершения выполнения задачи | Возможные значения см. в разделе Значения кода завершения. Не заполнено для строк, выпущенных до конца августа 2024 года. |
распространенные шаблоны соединения
В следующих разделах приведены примеры запросов, которые выделяют часто используемые шаблоны соединения для системных таблиц заданий.
Объедините таблицы заданий и временной шкалы выполнения заданий
Обогащение запуска задания указанием названия задания
with jobs as (
SELECT
*,
ROW_NUMBER() OVER (PARTITION BY workspace_id, job_id ORDER BY change_time DESC) as rn
FROM system.lakeflow.jobs QUALIFY rn=1
)
SELECT
job_run_timeline.*
jobs.name
FROM system.lakeflow.job_run_timeline
LEFT JOIN jobs USING (workspace_id, job_id)
Присоединитесь к хронологии выполнения задания и таблицам использования
Обогатить каждый журнал выставления счетов метаданными выполнения задания
SELECT
t1.*,
t2.*
FROM system.billing.usage t1
LEFT JOIN system.lakeflow.job_run_timeline t2
ON t1.workspace_id = t2.workspace_id
AND t1.usage_metadata.job_id = t2.job_id
AND t1.usage_metadata.job_run_id = t2.run_id
AND t1.usage_start_time >= date_trunc("Hour", t2.period_start_time)
AND t1.usage_start_time < date_trunc("Hour", t2.period_end_time) + INTERVAL 1 HOUR
WHERE
billing_origin_product="JOBS"
вычисление затрат на выполнение задания
Этот запрос присоединяется к системной таблице billing.usage для вычисления затрат на выполнение задания.
with jobs_usage AS (
SELECT
*,
usage_metadata.job_id,
usage_metadata.job_run_id as run_id,
identity_metadata.run_as as run_as
FROM system.billing.usage
WHERE billing_origin_product="JOBS"
),
jobs_usage_with_usd AS (
SELECT
jobs_usage.*,
usage_quantity * pricing.default as usage_usd
FROM jobs_usage
LEFT JOIN system.billing.list_prices pricing ON
jobs_usage.sku_name = pricing.sku_name
AND pricing.price_start_time <= jobs_usage.usage_start_time
AND (pricing.price_end_time >= jobs_usage.usage_start_time OR pricing.price_end_time IS NULL)
AND pricing.currency_code="USD"
),
jobs_usage_aggregated AS (
SELECT
workspace_id,
job_id,
run_id,
FIRST(run_as, TRUE) as run_as,
sku_name,
SUM(usage_usd) as usage_usd,
SUM(usage_quantity) as usage_quantity
FROM jobs_usage_with_usd
GROUP BY ALL
)
SELECT
t1.*,
MIN(period_start_time) as run_start_time,
MAX(period_end_time) as run_end_time,
FIRST(result_state, TRUE) as result_state
FROM jobs_usage_aggregated t1
LEFT JOIN system.lakeflow.job_run_timeline t2 USING (workspace_id, job_id, run_id)
GROUP BY ALL
ORDER BY usage_usd DESC
LIMIT 100
Получение журналов использования для заданий SUBMIT_RUN
SELECT
*
FROM system.billing.usage
WHERE
EXISTS (
SELECT 1
FROM system.lakeflow.job_run_timeline
WHERE
job_run_timeline.job_id = usage_metadata.job_id
AND run_name = :run_name
AND workspace_id = :workspace_id
)
Присоединитесь к таблицам временной шкалы выполнения задания и кластеров
Дополнение выполнения рабочих заданий метаданными кластеров
with clusters as (
SELECT
*,
ROW_NUMBER() OVER (PARTITION BY workspace_id, cluster_id ORDER BY change_time DESC) as rn
FROM system.compute.clusters QUALIFY rn=1
),
exploded_task_runs AS (
SELECT
*,
EXPLODE(compute_ids) as cluster_id
FROM system.lakeflow.job_task_run_timeline
WHERE array_size(compute_ids) > 0
)
SELECT
exploded_task_runs.*,
clusters.*
FROM exploded_task_runs t1
LEFT JOIN clusters t2
USING (workspace_id, cluster_id)
Поиск заданий, выполняющихся на универсальных вычислительных системах
Этот запрос объединяется с системной таблицей compute.clusters, чтобы вернуть последние задания, которые выполняются на общих вычислительных ресурсах, а не на ресурсах для выполнения заданий.
with clusters AS (
SELECT
*,
ROW_NUMBER() OVER(PARTITION BY workspace_id, cluster_id ORDER BY change_time DESC) as rn
FROM system.compute.clusters
WHERE cluster_source="UI" OR cluster_source="API"
QUALIFY rn=1
),
job_tasks_exploded AS (
SELECT
workspace_id,
job_id,
EXPLODE(compute_ids) as cluster_id
FROM system.lakeflow.job_task_run_timeline
WHERE period_start_time >= CURRENT_DATE() - INTERVAL 30 DAY
),
all_purpose_cluster_jobs AS (
SELECT
t1.*,
t2.cluster_name,
t2.owned_by,
t2.dbr_version
FROM job_tasks_exploded t1
INNER JOIN clusters t2 USING (workspace_id, cluster_id)
)
SELECT * FROM all_purpose_cluster_jobs LIMIT 10;
панель мониторинга заданий
На следующей панели мониторинга используются системные таблицы, которые помогут вам приступить к мониторингу заданий и работоспособности операций. Он включает распространенные варианты использования, такие как отслеживание производительности заданий, мониторинг сбоев и использование ресурсов.
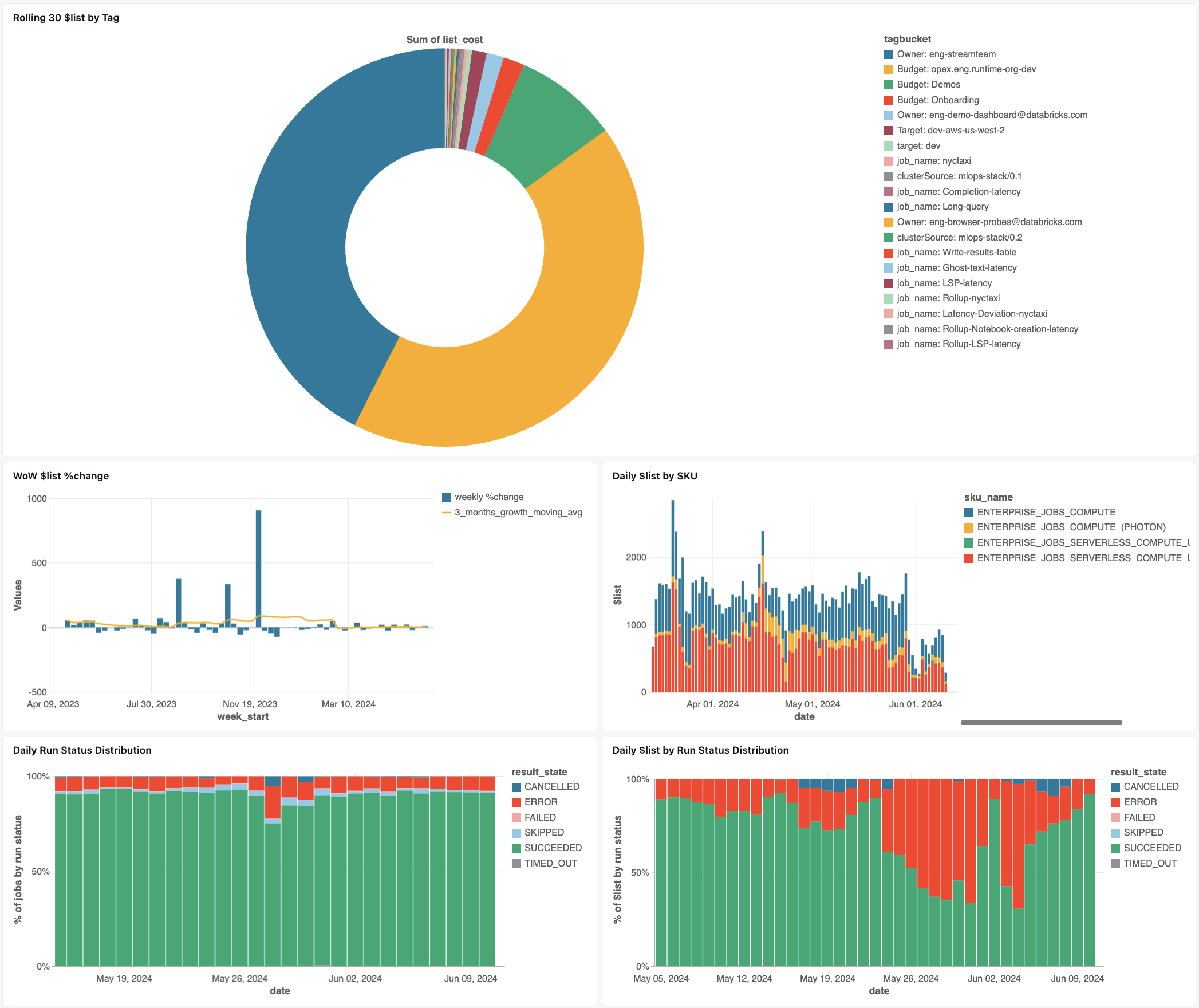
Сведения о скачивании панели мониторинга см. в статье Мониторинг затрат на задание & производительности с помощью системных таблиц
Устранение неполадок
Задание не регистрируется в таблице lakeflow.jobs
Если задание не отображается в системных таблицах:
- Задание не было изменено за последние 365 дней
- Измените любой из полей задания, присутствующих в схеме, чтобы вывести новую запись.
- Работа была создана в другом регионе
- Недавнее создание рабочих мест (задержка обновления таблицы)
Не удаётся обнаружить работу в таблице job_run_timeline
Не все запуски заданий отображаются везде. Хотя записи JOB_RUN отображаются во всех таблицах, связанных с работой, WORKFLOW_RUN (запуски рабочих процессов записной книжки) записываются только в job_run_timeline, а SUBMIT_RUN (однократно отправленные запуски) записываются только в обе временные таблицы. Эти запуски не заполняются другими таблицами системы заданий, такими как jobs или job_tasks.
Подробные сведения о том, где каждый тип выполнения отображается и доступен, см. в таблице
задание не отображается в таблице billing.usage
В system.billing.usageusage_metadata.job_id заполняется только для заданий, которые выполняются при вычислении заданий или бессерверных вычислениях.
Кроме того, работа WORKFLOW_RUN не имеет собственной usage_metadata.job_id или usage_metadata.job_run_id атрибуции в system.billing.usage.
Вместо этого их использование вычислительных ресурсов приписывается родительскому блокноту, который запустил их.
Это означает, что когда записная книжка запускает рабочий процесс, все затраты на вычисления относятся к использованию родительской записной книжки, а не выделяются как отдельное задание рабочего процесса.
См. источник данных об использовании метаданных для получения дополнительной информации.
Рассчитать стоимость задания, выполняющегося на универсальных вычислительных ресурсах
Точное вычисление стоимости для заданий, выполняющихся на назначенном вычислительном ресурсе, невозможно с точностью 100%. При выполнении задания на интерактивном вычислительном ресурсе общего назначения одновременно могут работать несколько типов нагрузок, таких как блокноты, запросы SQL или другие задания. Так как ресурсы кластера совместно используются, нет прямого сопоставления 1:1 между затратами на вычисления и выполнением отдельных заданий.
Для точного отслеживания затрат на задания Databricks рекомендует выполнять задания на выделенных вычислительных ресурсах или бессерверных вычислительных ресурсах, где usage_metadata.job_id и usage_metadata.job_run_id позволяют точное распределение затрат.
Если необходимо использовать все целевые вычислительные ресурсы, можно:
- Отслеживайте общее использование и затраты кластера в
system.billing.usageна основеusage_metadata.cluster_id. - Отслеживайте метрики среды выполнения заданий отдельно.
- Учитывайте, что любая оценка затрат будет приблизительной из-за общих ресурсов.
Дополнительные сведения о присвоении затрат см. в Справочнике по метаданным об использовании.
Эталонные значения
В следующем разделе содержатся ссылки на выбор столбцов в таблицах, связанных с заданиями.
значения типа триггера
Возможные значения для столбца trigger_type:
CONTINUOUSCRONFILE_ARRIVALONETIMEONETIME_RETRY
значения типов запуска
Возможные значения для столбца run_type:
| Тип | Описание | Расположение пользовательского интерфейса | Конечная точка API | Системные таблицы |
|---|---|---|---|---|
JOB_RUN |
Стандартное выполнение задания | Интерфейс заданий и их выполнения | /jobs и /jobs/выполняет конечные точки | задания, задачи, график выполнения заданий, временная шкала выполнения задачи |
SUBMIT_RUN |
Однократное выполнение через POST /jobs/runs/submit | Только пользовательский интерфейс запуска заданий | Только конечные точки /jobs/запуска | Хронология выполнения работы, хронология выполнения задачи |
WORKFLOW_RUN |
Запуск рабочего процесса из записной книжки |
Невидимый | Недоступно | хронология выполнения работы |
значения состояния результата
Возможные значения для столбца result_state:
| Государство | Описание |
|---|---|
SUCCEEDED |
Запуск успешно завершён |
FAILED |
Завершение процесса произошло с ошибкой |
SKIPPED |
Запуск никогда не осуществлялся, так как условие не было выполнено |
CANCELLED |
Выполнение было отменено по запросу пользователя |
TIMED_OUT |
Запуск был остановлен после достижения лимита времени |
ERROR |
Выполнение завершено с ошибкой |
BLOCKED |
Запуск был заблокирован из-за вышестоящей зависимости |
значения кода завершения
Возможные значения для столбца termination_code:
| Код завершения | Описание |
|---|---|
SUCCESS |
Забег успешно завершён |
CANCELLED |
Запуск был отменен платформой Databricks во время выполнения; например, если была превышена максимальная продолжительность работы. |
SKIPPED |
Запуск никогда не выполнялся, например, если выполнение вышестоящей задачи завершилось сбоем, условие зависимости не выполнялось или не было материальных задач для выполнения. |
DRIVER_ERROR |
При взаимодействии с драйвером Spark произошла ошибка. |
CLUSTER_ERROR |
Сбой выполнения из-за ошибки в кластере |
REPOSITORY_CHECKOUT_FAILED |
Не удалось завершить покупку из-за ошибки при взаимодействии с внешним поставщиком услуг. |
INVALID_CLUSTER_REQUEST |
Сбой выполнения, так как он выпустил недопустимый запрос для запуска кластера |
WORKSPACE_RUN_LIMIT_EXCEEDED |
Рабочая область достигла лимита на максимальное количество одновременно активных процессов. Рассмотрите возможность планирования запусков в течение более крупного интервала времени |
FEATURE_DISABLED |
Сбой произошел, потому что была попытка получить доступ к функции, недоступной для рабочей области. |
CLUSTER_REQUEST_LIMIT_EXCEEDED |
Число запросов на создание, запуск и обновление кластера превысило выделенное ограничение скорости. Рассмотрите возможность распределения выполнения на более длительный период времени |
STORAGE_ACCESS_ERROR |
Сбой выполнения из-за ошибки при доступе к клиентскому BLOB-хранилищу |
RUN_EXECUTION_ERROR |
Запуск был завершен сбоем задач |
UNAUTHORIZED_ERROR |
Сбой выполнения из-за проблемы с разрешением при доступе к ресурсу |
LIBRARY_INSTALLATION_ERROR |
Сбой выполнения при установке запрошенной пользователем библиотеки. Причины могут включать в себя, но не ограничены следующими: предоставленная библиотека недействительна, недостаточное количество разрешений для установки библиотеки и т. д. |
MAX_CONCURRENT_RUNS_EXCEEDED |
Запланированное выполнение превышает ограничение максимального числа одновременных запусков, установленных для задания. |
MAX_SPARK_CONTEXTS_EXCEEDED |
Выполнение запланировано в кластере, который уже достиг максимального количества контекстов, которые можно создать. |
RESOURCE_NOT_FOUND |
Ресурс, необходимый для выполнения запуска, не существует |
INVALID_RUN_CONFIGURATION |
Сбой выполнения из-за недопустимой конфигурации |
CLOUD_FAILURE |
Сбой выполнения из-за проблемы с поставщиком облачных служб |
MAX_JOB_QUEUE_SIZE_EXCEEDED |
Выполнение было пропущено из-за достижения предела размера очереди на уровне задания |