Добавочная загрузка данных из нескольких таблиц в SQL Server в Базу данных SQL Azure с использованием PowerShell
ОБЛАСТЬ ПРИМЕНЕНИЯ:  Фабрика данных Azure Azure Synapse Analytics
Фабрика данных Azure Azure Synapse Analytics
Совет
Попробуйте использовать фабрику данных в Microsoft Fabric, решение для аналитики с одним интерфейсом для предприятий. Microsoft Fabric охватывает все, от перемещения данных до обработки и анализа данных в режиме реального времени, бизнес-аналитики и отчетности. Узнайте, как бесплатно запустить новую пробную версию !
В этом кратком руководстве показано, как создать фабрику данных Azure с конвейером, который загружает разностные данные из нескольких таблиц базы данных SQL Server в Базу данных SQL Azure.
В этом руководстве вы выполните следующие шаги:
- подготовите исходное и конечное хранилища данных;
- Создали фабрику данных.
- Создание локальной среды выполнения интеграции.
- Установка среды выполнения интеграции.
- Создали связанные службы.
- Создали наборы данных источника, приемника и предела.
- создадите и запустите конвейер, а также начнете его мониторинг;
- Проверка результатов.
- Добавление или обновление данных в исходных таблицах.
- Повторный запуск конвейера и выполнение его мониторинга.
- Просмотр окончательных результатов.
Обзор
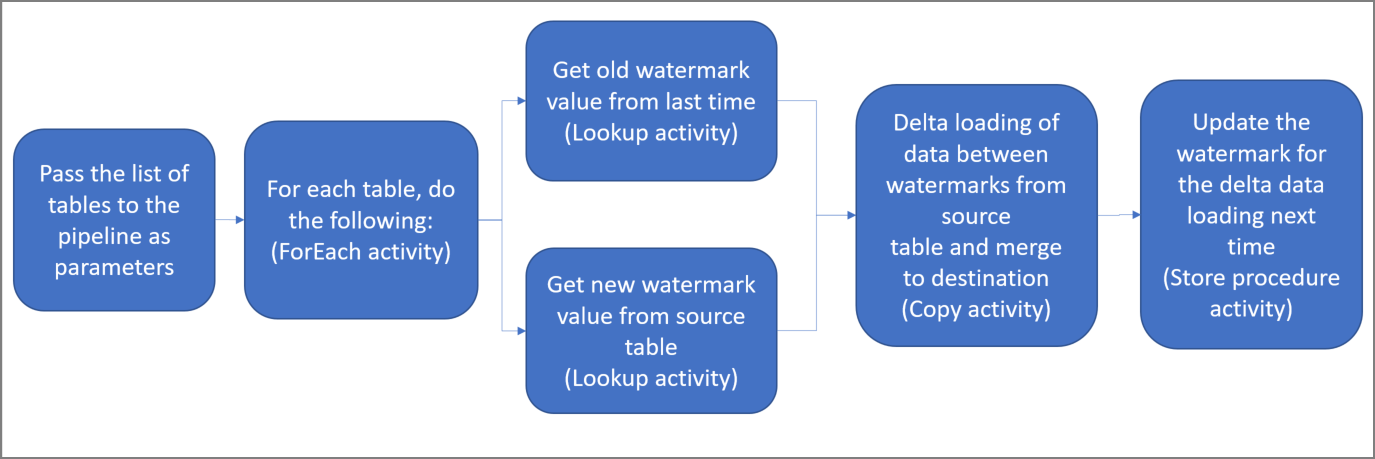
Ниже приведены важные действия для создания этого решения.
Выберите столбец для предела.
Выберите один столбец из каждой таблицы в исходном хранилище данных, который можно использовать для идентификации новых или обновленных записей при каждом запуске. Как правило, данные в этом выбранном столбце (например, последнее_время_изменения или идентификатор) продолжают увеличиваться по мере создания или обновления строк. В качестве предела используется максимальное значение в этом столбце.
Подготовьте хранилище данных для хранения значений предела.
В этом руководстве вы сохраните значение предела в базе данных SQL.
Создайте конвейер, следуя инструкциям ниже.
Создайте действие ForEach, которое выполняет итерацию по списку имен исходной таблицы. Этот список передается в конвейер в качестве параметра. В каждой исходной таблице этот параметр вызывает следующие действия для загрузки разностных данных для этой таблицы.
Создание двух действий поиска. Используйте первое действие поиска для получения последнего значения предела, а второе для получения нового значения предела. Эти значения передаются в действие копирования.
Создайте действие копирования, копирующее строки из исходного хранилища данных со значениями столбцов предела, которые выше значений старого предела и меньше или равно значениям нового. Затем оно копирует разностные данные из исходного хранилища данных в хранилище BLOB-объектов Azure в качестве нового файла.
Создайте действие хранимой процедуры, которое обновляет значение предела для конвейера при последующем выполнении.
Ниже приведена общая схема решения.
Если у вас нет подписки Azure, создайте бесплатную учетную запись, прежде чем приступить к работе.
Необходимые компоненты
- SQL Server. В этом учебнике используйте базу данных SQL Server в качестве исходного хранилища данных.
- База данных SQL Azure. Базу данных в службе "База данных SQL Azure" следует использовать в качестве принимающего хранилища данных. Если у вас нет базы данных SQL, создайте ее, следуя указаниям из руководства Создание отдельной базы данных в Базе данных SQL Azure.
Создание исходных таблиц в базе данных SQL Server
Откройте SQL Server Management Studio (SSMS) или Azure Data Studio и подключитесь к базе данных SQL Server.
В Обозревателе сервера (SSMS) или в Области подключения (Azure Data Studio), щелкните правой кнопкой мыши на базу данных и выберите Новый запрос.
Выполните следующую команду SQL в базе данных, чтобы создать таблицы с именами
customer_tableиproject_table.create table customer_table ( PersonID int, Name varchar(255), LastModifytime datetime ); create table project_table ( Project varchar(255), Creationtime datetime ); INSERT INTO customer_table (PersonID, Name, LastModifytime) VALUES (1, 'John','9/1/2017 12:56:00 AM'), (2, 'Mike','9/2/2017 5:23:00 AM'), (3, 'Alice','9/3/2017 2:36:00 AM'), (4, 'Andy','9/4/2017 3:21:00 AM'), (5, 'Anny','9/5/2017 8:06:00 AM'); INSERT INTO project_table (Project, Creationtime) VALUES ('project1','1/1/2015 0:00:00 AM'), ('project2','2/2/2016 1:23:00 AM'), ('project3','3/4/2017 5:16:00 AM');
Создание целевых таблиц в базе данных SQL Azure
Откройте SQL Server Management Studio (SSMS) или Azure Data Studio и подключитесь к базе данных SQL Server.
В Обозревателе сервера (SSMS) или в Области подключения (Azure Data Studio), щелкните правой кнопкой мыши на базу данных и выберите Новый запрос.
Выполните следующую команду SQL в базе данных, чтобы создать таблицы с именами
customer_tableиproject_table.create table customer_table ( PersonID int, Name varchar(255), LastModifytime datetime ); create table project_table ( Project varchar(255), Creationtime datetime );
Создание дополнительной таблицы в Базе данных SQL Azure для хранения значения верхнего предела
Выполните указанную ниже команду SQL для базы данных, чтобы создать таблицу с именем
watermarktableдля хранения значения предела.create table watermarktable ( TableName varchar(255), WatermarkValue datetime, );Вставьте исходные значения предела для обеих исходных таблиц в таблицу значений предела.
INSERT INTO watermarktable VALUES ('customer_table','1/1/2010 12:00:00 AM'), ('project_table','1/1/2010 12:00:00 AM');
Создание хранимой процедуры в Базе данных SQL Azure
Выполните указанную ниже команду, чтобы создать хранимую процедуру в своей базе данных. Эта хранимая процедура обновляет значение предела после каждого запуска конвейера.
CREATE PROCEDURE usp_write_watermark @LastModifiedtime datetime, @TableName varchar(50)
AS
BEGIN
UPDATE watermarktable
SET [WatermarkValue] = @LastModifiedtime
WHERE [TableName] = @TableName
END
Создание типов данных и дополнительных хранимых процедур в Базе данных SQL Azure
Выполните следующий запрос, чтобы создать две хранимые процедуры и два типа данных в своей базе данных. Они используются для объединения данных из исходных в целевые таблицы.
Чтобы упростить начало работы, мы непосредственно используем эти хранимые процедуры, передающие разностные данные в табличной переменной, а затем объединяем их в целевое хранилище. Учтите, что для хранения в табличной переменной не ожидается большое число строк разностных данных (более 100).
Если нужно объединить большое количество строк разностных данных в целевом хранилище, мы рекомендуем с помощью действия копирования сначала скопировать разностные данные во временную "промежуточную" таблицу в целевом хранилище, а затем создать собственную хранимую процедуру, не используя табличную переменную для их объединения из "промежуточной" таблицы в "итоговую".
CREATE TYPE DataTypeforCustomerTable AS TABLE(
PersonID int,
Name varchar(255),
LastModifytime datetime
);
GO
CREATE PROCEDURE usp_upsert_customer_table @customer_table DataTypeforCustomerTable READONLY
AS
BEGIN
MERGE customer_table AS target
USING @customer_table AS source
ON (target.PersonID = source.PersonID)
WHEN MATCHED THEN
UPDATE SET Name = source.Name,LastModifytime = source.LastModifytime
WHEN NOT MATCHED THEN
INSERT (PersonID, Name, LastModifytime)
VALUES (source.PersonID, source.Name, source.LastModifytime);
END
GO
CREATE TYPE DataTypeforProjectTable AS TABLE(
Project varchar(255),
Creationtime datetime
);
GO
CREATE PROCEDURE usp_upsert_project_table @project_table DataTypeforProjectTable READONLY
AS
BEGIN
MERGE project_table AS target
USING @project_table AS source
ON (target.Project = source.Project)
WHEN MATCHED THEN
UPDATE SET Creationtime = source.Creationtime
WHEN NOT MATCHED THEN
INSERT (Project, Creationtime)
VALUES (source.Project, source.Creationtime);
END
Azure PowerShell
Чтобы установить новые модули Azure PowerShell, выполните инструкции из статьи Установка и настройка Azure PowerShell.
Создание фабрики данных
Определите переменную для имени группы ресурсов, которую в дальнейшем можно будет использовать в командах PowerShell. Скопируйте текст следующей команды в PowerShell, укажите имя группы ресурсов Azure в двойных кавычках, а затем выполните команду. Например,
"adfrg".$resourceGroupName = "ADFTutorialResourceGroup";Если группа ресурсов уже имеется, вы можете не перезаписывать ее. Назначьте переменной
$resourceGroupNameдругое значение и еще раз выполните команду.Определите переменную для расположения фабрики данных.
$location = "East US"Чтобы создать группу ресурсов Azure, выполните следующую команду:
New-AzResourceGroup $resourceGroupName $locationЕсли группа ресурсов уже имеется, вы можете не перезаписывать ее. Назначьте переменной
$resourceGroupNameдругое значение и еще раз выполните команду.Определите переменную для имени фабрики данных.
Внимание
Измените имя фабрики данных, чтобы сделать его глобально уникальным. Например, ADFIncMultiCopyTutorialFactorySP1127.
$dataFactoryName = "ADFIncMultiCopyTutorialFactory";Чтобы создать фабрику данных, выполните командлет Set-AzDataFactoryV2.
Set-AzDataFactoryV2 -ResourceGroupName $resourceGroupName -Location $location -Name $dataFactoryName
Обратите внимание на следующие аспекты:
Имя фабрики данных должно быть глобально уникальным. Если появляется следующая ошибка, измените имя и повторите попытку.
Set-AzDataFactoryV2 : HTTP Status Code: Conflict Error Code: DataFactoryNameInUse Error Message: The specified resource name 'ADFIncMultiCopyTutorialFactory' is already in use. Resource names must be globally unique.Чтобы создать экземпляры фабрики данных, нужно назначить учетной записи пользователя, используемой для входа в Azure, роль участника, владельца либо администратора подписки Azure.
Чтобы получить список регионов Azure, в которых в настоящее время доступна Фабрика данных, выберите интересующие вас регионы на следующей странице, а затем разверните раздел Аналитика, чтобы найти пункт Фабрика данных: Доступность продуктов по регионам. Хранилища данных (служба хранилища Azure, База данных SQL, Управляемый экземпляр SQL и т. д.) и вычислительные ресурсы (Azure HDInsight и т. д.), используемые фабрикой данных, могут располагаться в других регионах.
Создание локальной среды выполнения интеграции
В этом разделе вы создадите локальную среду выполнения интеграции и свяжете ее с локальным компьютером, на котором находится база данных SQL Server. Локальная среда выполнения интеграции — это компонент, который копирует данные с SQL Server на компьютере в Базу данных SQL Azure.
Создайте переменную для имени среды выполнения интеграции. Используйте уникальное имя и запишите его. Оно будет использоваться далее в этом руководстве.
$integrationRuntimeName = "ADFTutorialIR"Создание локальной среды выполнения интеграции.
Set-AzDataFactoryV2IntegrationRuntime -Name $integrationRuntimeName -Type SelfHosted -DataFactoryName $dataFactoryName -ResourceGroupName $resourceGroupNameПример выходных данных:
Name : <Integration Runtime name> Type : SelfHosted ResourceGroupName : <ResourceGroupName> DataFactoryName : <DataFactoryName> Description : Id : /subscriptions/<subscription ID>/resourceGroups/<ResourceGroupName>/providers/Microsoft.DataFactory/factories/<DataFactoryName>/integrationruntimes/ADFTutorialIRЧтобы получить состояние созданной среды выполнения интеграции, выполните следующую команду. Убедитесь, что свойству State присвоено значение NeedRegistration.
Get-AzDataFactoryV2IntegrationRuntime -name $integrationRuntimeName -ResourceGroupName $resourceGroupName -DataFactoryName $dataFactoryName -StatusПример выходных данных:
State : NeedRegistration Version : CreateTime : 9/24/2019 6:00:00 AM AutoUpdate : On ScheduledUpdateDate : UpdateDelayOffset : LocalTimeZoneOffset : InternalChannelEncryption : Capabilities : {} ServiceUrls : {eu.frontend.clouddatahub.net} Nodes : {} Links : {} Name : ADFTutorialIR Type : SelfHosted ResourceGroupName : <ResourceGroup name> DataFactoryName : <DataFactory name> Description : Id : /subscriptions/<subscription ID>/resourceGroups/<ResourceGroup name>/providers/Microsoft.DataFactory/factories/<DataFactory name>/integrationruntimes/<Integration Runtime name>Чтобы получить ключи проверки подлинности для регистрации локальной среды выполнения интеграции в службе фабрики данных Azure в облаке, выполните следующую команду:
Get-AzDataFactoryV2IntegrationRuntimeKey -Name $integrationRuntimeName -DataFactoryName $dataFactoryName -ResourceGroupName $resourceGroupName | ConvertTo-JsonПример выходных данных:
{ "AuthKey1": "IR@0000000000-0000-0000-0000-000000000000@xy0@xy@xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx=", "AuthKey2": "IR@0000000000-0000-0000-0000-000000000000@xy0@xy@yyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyy=" }Скопируйте один из ключей (без двойных кавычек), используемый для регистрации локальной среды выполнения интеграции, которую вы установите на компьютер на следующих шагах.
Установка средства среды выполнения интеграции
Если на вашем компьютере уже установлена среда выполнения интеграции, удалите ее в разделе Установка и удаление программ.
Скачайте локальную среду выполнения интеграции на локальный компьютер под управлением Windows. Запустите установку.
На странице приветствия мастера установки Microsoft Integration Runtime нажмите кнопку Далее.
На странице Лицензионное соглашение примите условия использования и лицензионное соглашение и нажмите кнопку Далее.
На странице Конечная папка нажмите кнопку Далее.
На странице Ready to install Microsoft Integration Runtime (Все готово для установки Microsoft Integration Runtime) нажмите кнопку Установить.
На странице Completed the Microsoft Integration Runtime Setup (Мастер установки Microsoft Integration Runtime завершил работу) нажмите кнопку Готово.
На странице Регистрация Integration Runtime (Self-hosted) вставьте ключ, созданный в предыдущем разделе, и выберите Зарегистрировать.
На странице Новый узел среды выполнения интеграции (с локальным размещением) нажмите кнопку Finish (Завершить)
Когда локальная среда выполнения интеграции будет успешно зарегистрирована, вы увидите следующее сообщение:
На странице Регистрация Integration Runtime (Self-hosted) выберите Запустить Configuration Manager.
Когда узел будет подключен к облачной службе, отобразится следующая страница:
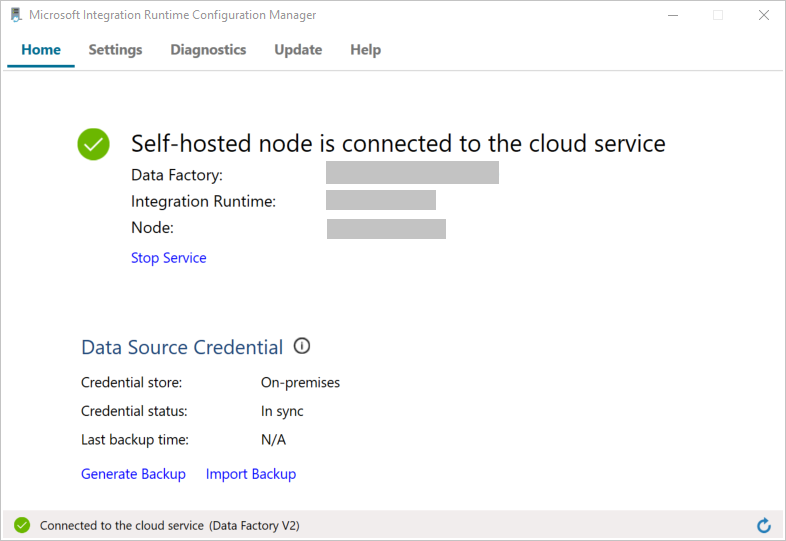
Теперь проверьте возможность подключения к базе данных SQL Server.
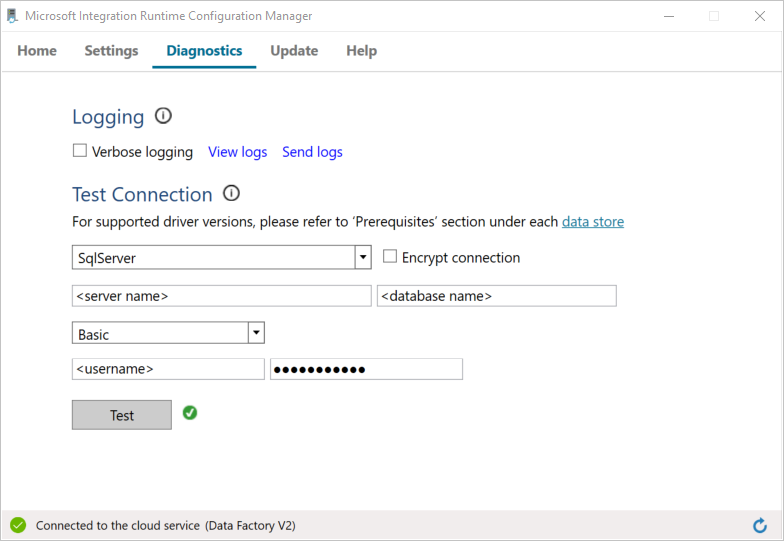
a. На странице Configuration Manager перейдите на вкладку Diagnostics (Диагностика).
b. В качестве типа источника данных выберите SqlServer.
c. Введите имя сервера.
d. Введите имя базы данных.
д) Выберите режим проверки подлинности.
f. Введите имя пользователя.
ж. Введите пароль, связанный с именем пользователя.
h. Нажмите кнопку проверки, чтобы убедиться, что эта среда выполнения интеграции может подключаться к серверу SQL Server. Если подключение установлено успешно, появится зеленый флажок. Если подключение не установлено, появится сообщение об ошибке. Исправьте ошибки и проверьте, может ли среда выполнения интеграции подключаться к SQL Server.
Примечание.
Запишите значения типа проверки подлинности, сервера, базы данных, пользователя и пароль. Они будут использоваться далее в этом руководстве.
Создание связанных служб
Связанная служба в фабрике данных связывает хранилища данных и службы вычислений с фабрикой данных. В рамках этого раздела вы создадите связанные службы для базы данных SQL Server и базы данных в службе "База данных SQL Azure".
Создание связанной службы SQL Server
На этом шаге вы свяжете базу данных SQL Server с фабрикой данных.
Создайте JSON-файл с именемSqlServerLinkedService.json в папке C:\ADFTutorials\IncCopyMultiTableTutorial (создайте локальные папки, если они не существуют) со следующим содержимым. Выберите правильный раздел в зависимости от типа проверки подлинности, который используется для подключения к SQL Server.
Внимание
Выберите правильный раздел в зависимости от типа проверки подлинности, который используется для подключения к SQL Server.
Если используется проверка подлинности SQL, скопируйте следующее определение JSON:
{ "name":"SqlServerLinkedService", "properties":{ "annotations":[ ], "type":"SqlServer", "typeProperties":{ "connectionString":"integrated security=False;data source=<servername>;initial catalog=<database name>;user id=<username>;Password=<password>" }, "connectVia":{ "referenceName":"<integration runtime name>", "type":"IntegrationRuntimeReference" } } }Если используется проверка подлинности Windows, скопируйте следующее определение JSON:
{ "name":"SqlServerLinkedService", "properties":{ "annotations":[ ], "type":"SqlServer", "typeProperties":{ "connectionString":"integrated security=True;data source=<servername>;initial catalog=<database name>", "userName":"<username> or <domain>\\<username>", "password":{ "type":"SecureString", "value":"<password>" } }, "connectVia":{ "referenceName":"<integration runtime name>", "type":"IntegrationRuntimeReference" } } }Внимание
- Выберите правильный раздел в зависимости от типа проверки подлинности, который используется для подключения к SQL Server.
- Замените <integration runtime name> именем своей среды выполнения интеграции.
- Перед сохранением файла замените <servername>, <databasename>, <username> и <password> значениями имени сервера, базы данных, пользователя и пароля для базы данных SQL Server.
- Если в имени учетной записи пользователя или имени сервера необходимо использовать символ косой черты (
\), добавьте escape-символ (\). Например,mydomain\\myuser.
В PowerShell запустите следующий командлет, чтобы перейти к папке C:\ADFTutorials\IncCopyMultiTableTutorial.
Set-Location 'C:\ADFTutorials\IncCopyMultiTableTutorial'Выполните командлет Set-AzDataFactoryV2LinkedService, чтобы создать связанную службу AzureStorageLinkedService. В указанном ниже примере вы передадите значения для параметров ResourceGroupName и DataFactoryName.
Set-AzDataFactoryV2LinkedService -DataFactoryName $dataFactoryName -ResourceGroupName $resourceGroupName -Name "SqlServerLinkedService" -File ".\SqlServerLinkedService.json"Пример выходных данных:
LinkedServiceName : SqlServerLinkedService ResourceGroupName : <ResourceGroupName> DataFactoryName : <DataFactoryName> Properties : Microsoft.Azure.Management.DataFactory.Models.SqlServerLinkedService
Создание связанной службы Базы данных SQL
Создайте JSON-файл с именемAzureSQLDatabaseLinkedService.json в папке C:\ADFTutorials\IncCopyMultiTableTutorial и добавьте в него следующее содержимое. (Создайте папку ADF, если она еще не существует.) Замените <имя> сервера, имя> базы данных, <<имя> пользователя и <пароль> именем базы данных SQL Server, именем базы данных, именем пользователя и паролем перед сохранением файла.
{ "name":"AzureSQLDatabaseLinkedService", "properties":{ "annotations":[ ], "type":"AzureSqlDatabase", "typeProperties":{ "connectionString":"integrated security=False;encrypt=True;connection timeout=30;data source=<servername>.database.windows.net;initial catalog=<database name>;user id=<user name>;Password=<password>;" } } }В PowerShell выполните командлет Set-AzDataFactoryV2LinkedService, чтобы создать связанную службу AzureSQLDatabaseLinkedService.
Set-AzDataFactoryV2LinkedService -DataFactoryName $dataFactoryName -ResourceGroupName $resourceGroupName -Name "AzureSQLDatabaseLinkedService" -File ".\AzureSQLDatabaseLinkedService.json"Пример выходных данных:
LinkedServiceName : AzureSQLDatabaseLinkedService ResourceGroupName : <ResourceGroupName> DataFactoryName : <DataFactoryName> Properties : Microsoft.Azure.Management.DataFactory.Models.AzureSqlDatabaseLinkedService
Создайте наборы данных.
На этом шаге вы создадите наборы данных для представления источника данных, назначение данных и место для хранения предела.
Создание исходного набора данных
Создайте файл JSON с именем SourceDataset.json в той же папке со следующим содержимым:
{ "name":"SourceDataset", "properties":{ "linkedServiceName":{ "referenceName":"SqlServerLinkedService", "type":"LinkedServiceReference" }, "annotations":[ ], "type":"SqlServerTable", "schema":[ ] } }Действие копирования в конвейере использует SQL-запрос для загрузки данных, вместо того чтобы загружать всю таблицу.
Выполните командлет Set-AzDataFactoryV2Dataset, чтобы создать набор данных SourceDataset.
Set-AzDataFactoryV2Dataset -DataFactoryName $dataFactoryName -ResourceGroupName $resourceGroupName -Name "SourceDataset" -File ".\SourceDataset.json"Вот пример выходных данных командлета:
DatasetName : SourceDataset ResourceGroupName : <ResourceGroupName> DataFactoryName : <DataFactoryName> Structure : Properties : Microsoft.Azure.Management.DataFactory.Models.SqlServerTableDataset
Создание набора данных приемника
Создайте файл JSON с именем SinkDataset.json в той же папке со следующим содержимым. Элемент tableName динамически задается конвейером в среде выполнения. Действие ForEach в конвейере выполняет итерацию по списку имен таблиц и передает имя таблицы для этого набора данных в каждой итерации.
{ "name":"SinkDataset", "properties":{ "linkedServiceName":{ "referenceName":"AzureSQLDatabaseLinkedService", "type":"LinkedServiceReference" }, "parameters":{ "SinkTableName":{ "type":"String" } }, "annotations":[ ], "type":"AzureSqlTable", "typeProperties":{ "tableName":{ "value":"@dataset().SinkTableName", "type":"Expression" } } } }Выполните командлет Set-AzDataFactoryV2Dataset, чтобы создать набор данных SinkDataset.
Set-AzDataFactoryV2Dataset -DataFactoryName $dataFactoryName -ResourceGroupName $resourceGroupName -Name "SinkDataset" -File ".\SinkDataset.json"Вот пример выходных данных командлета:
DatasetName : SinkDataset ResourceGroupName : <ResourceGroupName> DataFactoryName : <DataFactoryName> Structure : Properties : Microsoft.Azure.Management.DataFactory.Models.AzureSqlTableDataset
Создание набора данных для предела
На этом шаге вы создадите набор данных для хранения значения верхнего предела.
Создайте файл JSON с именем WatermarkDataset.json в той же папке со следующим содержимым:
{ "name": " WatermarkDataset ", "properties": { "type": "AzureSqlTable", "typeProperties": { "tableName": "watermarktable" }, "linkedServiceName": { "referenceName": "AzureSQLDatabaseLinkedService", "type": "LinkedServiceReference" } } }Выполните командлет Set-AzDataFactoryV2Dataset, чтобы создать набор данных WatermarkDataset.
Set-AzDataFactoryV2Dataset -DataFactoryName $dataFactoryName -ResourceGroupName $resourceGroupName -Name "WatermarkDataset" -File ".\WatermarkDataset.json"Вот пример выходных данных командлета:
DatasetName : WatermarkDataset ResourceGroupName : <ResourceGroupName> DataFactoryName : <DataFactoryName> Structure : Properties : Microsoft.Azure.Management.DataFactory.Models.AzureSqlTableDataset
Создание конвейера
Этот конвейер принимает список имен таблиц в качестве параметра. Действие ForEach выполняет итерацию по списку имен таблиц, а затем выполняет следующие операции:
Использует действие поиска, чтобы получить старое значение предела (начальное значение или значение, используемое в последней итерации).
Использует действие поиска, чтобы получить новое значение предела (максимальное значение в столбце предела в исходной таблице).
Использует действие копирования, чтобы скопировать данные между двумя значениями пределов из исходной в целевую базу данных.
Использует действие хранимой процедуры, чтобы обновить старое значение предела для использования на первом шаге следующей итерации.
Создание конвейера
Создайте JSON-файл с именем IncrementalCopyPipeline.json в той же папке со следующим содержимым:
{ "name":"IncrementalCopyPipeline", "properties":{ "activities":[ { "name":"IterateSQLTables", "type":"ForEach", "dependsOn":[ ], "userProperties":[ ], "typeProperties":{ "items":{ "value":"@pipeline().parameters.tableList", "type":"Expression" }, "isSequential":false, "activities":[ { "name":"LookupOldWaterMarkActivity", "type":"Lookup", "dependsOn":[ ], "policy":{ "timeout":"7.00:00:00", "retry":0, "retryIntervalInSeconds":30, "secureOutput":false, "secureInput":false }, "userProperties":[ ], "typeProperties":{ "source":{ "type":"AzureSqlSource", "sqlReaderQuery":{ "value":"select * from watermarktable where TableName = '@{item().TABLE_NAME}'", "type":"Expression" } }, "dataset":{ "referenceName":"WatermarkDataset", "type":"DatasetReference" } } }, { "name":"LookupNewWaterMarkActivity", "type":"Lookup", "dependsOn":[ ], "policy":{ "timeout":"7.00:00:00", "retry":0, "retryIntervalInSeconds":30, "secureOutput":false, "secureInput":false }, "userProperties":[ ], "typeProperties":{ "source":{ "type":"SqlServerSource", "sqlReaderQuery":{ "value":"select MAX(@{item().WaterMark_Column}) as NewWatermarkvalue from @{item().TABLE_NAME}", "type":"Expression" } }, "dataset":{ "referenceName":"SourceDataset", "type":"DatasetReference" }, "firstRowOnly":true } }, { "name":"IncrementalCopyActivity", "type":"Copy", "dependsOn":[ { "activity":"LookupOldWaterMarkActivity", "dependencyConditions":[ "Succeeded" ] }, { "activity":"LookupNewWaterMarkActivity", "dependencyConditions":[ "Succeeded" ] } ], "policy":{ "timeout":"7.00:00:00", "retry":0, "retryIntervalInSeconds":30, "secureOutput":false, "secureInput":false }, "userProperties":[ ], "typeProperties":{ "source":{ "type":"SqlServerSource", "sqlReaderQuery":{ "value":"select * from @{item().TABLE_NAME} where @{item().WaterMark_Column} > '@{activity('LookupOldWaterMarkActivity').output.firstRow.WatermarkValue}' and @{item().WaterMark_Column} <= '@{activity('LookupNewWaterMarkActivity').output.firstRow.NewWatermarkvalue}'", "type":"Expression" } }, "sink":{ "type":"AzureSqlSink", "sqlWriterStoredProcedureName":{ "value":"@{item().StoredProcedureNameForMergeOperation}", "type":"Expression" }, "sqlWriterTableType":{ "value":"@{item().TableType}", "type":"Expression" }, "storedProcedureTableTypeParameterName":{ "value":"@{item().TABLE_NAME}", "type":"Expression" }, "disableMetricsCollection":false }, "enableStaging":false }, "inputs":[ { "referenceName":"SourceDataset", "type":"DatasetReference" } ], "outputs":[ { "referenceName":"SinkDataset", "type":"DatasetReference", "parameters":{ "SinkTableName":{ "value":"@{item().TABLE_NAME}", "type":"Expression" } } } ] }, { "name":"StoredProceduretoWriteWatermarkActivity", "type":"SqlServerStoredProcedure", "dependsOn":[ { "activity":"IncrementalCopyActivity", "dependencyConditions":[ "Succeeded" ] } ], "policy":{ "timeout":"7.00:00:00", "retry":0, "retryIntervalInSeconds":30, "secureOutput":false, "secureInput":false }, "userProperties":[ ], "typeProperties":{ "storedProcedureName":"[dbo].[usp_write_watermark]", "storedProcedureParameters":{ "LastModifiedtime":{ "value":{ "value":"@{activity('LookupNewWaterMarkActivity').output.firstRow.NewWatermarkvalue}", "type":"Expression" }, "type":"DateTime" }, "TableName":{ "value":{ "value":"@{activity('LookupOldWaterMarkActivity').output.firstRow.TableName}", "type":"Expression" }, "type":"String" } } }, "linkedServiceName":{ "referenceName":"AzureSQLDatabaseLinkedService", "type":"LinkedServiceReference" } } ] } } ], "parameters":{ "tableList":{ "type":"array" } }, "annotations":[ ] } }Выполните командлет Set-AzDataFactoryV2Pipeline, чтобы создать конвейер IncrementalCopyPipeline.
Set-AzDataFactoryV2Pipeline -DataFactoryName $dataFactoryName -ResourceGroupName $resourceGroupName -Name "IncrementalCopyPipeline" -File ".\IncrementalCopyPipeline.json"Пример выходных данных:
PipelineName : IncrementalCopyPipeline ResourceGroupName : <ResourceGroupName> DataFactoryName : <DataFactoryName> Activities : {IterateSQLTables} Parameters : {[tableList, Microsoft.Azure.Management.DataFactory.Models.ParameterSpecification]}
Запуск конвейера
Создайте файл параметров с именем Parameters.json в той же папке со следующим содержимым:
{ "tableList": [ { "TABLE_NAME": "customer_table", "WaterMark_Column": "LastModifytime", "TableType": "DataTypeforCustomerTable", "StoredProcedureNameForMergeOperation": "usp_upsert_customer_table" }, { "TABLE_NAME": "project_table", "WaterMark_Column": "Creationtime", "TableType": "DataTypeforProjectTable", "StoredProcedureNameForMergeOperation": "usp_upsert_project_table" } ] }Запустите конвейер IncrementalCopyPipeline, выполнив командлет Invoke-AzDataFactoryV2Pipeline. Замените заполнители собственными именами группы ресурсов и фабрики данных.
$RunId = Invoke-AzDataFactoryV2Pipeline -PipelineName "IncrementalCopyPipeline" -ResourceGroup $resourceGroupName -dataFactoryName $dataFactoryName -ParameterFile ".\Parameters.json"
Мониторинг конвейера
Войдите на портал Azure.
Выберите Все службы, выполните поиск по фразе Фабрики данных и выберите Фабрики данных.
Найдите и выберите в списке свою фабрику данных, чтобы открыть страницу Фабрика данных.
На странице Фабрика данных выберите Открыть на плитке Открыть студию Фабрики данных Azure, чтобы запустить пользовательский интерфейс Фабрики данных на отдельной вкладке.
На домашней странице Фабрики данных Azure выберите слева Монитор.
Вы можете увидеть все запуски конвейеров и их состояние. Обратите внимание, что в следующем примере состояние выполнения конвейера имеет значение Успешно. Чтобы проверить параметры, переданные в конвейер, щелкните ссылку в столбце Параметры. Если произошла ошибка, вы увидите ссылку в столбце Ошибка.

Если щелкнуть ссылку в столбце Действия, вы увидите все выполняемые действия в конвейере.
Выберите All Pipeline Runs (Все запуски конвейера), чтобы вернуться к представлению Pipeline Runs (Запуски конвейера).
Проверьте результаты.
В SQL Server Management Studio выполните следующие запросы в целевой базе данных SQL. Так вы проверите, что данные скопированы из исходных таблиц в целевые.
Запрос
select * from customer_table
Выходные данные
===========================================
PersonID Name LastModifytime
===========================================
1 John 2017-09-01 00:56:00.000
2 Mike 2017-09-02 05:23:00.000
3 Alice 2017-09-03 02:36:00.000
4 Andy 2017-09-04 03:21:00.000
5 Anny 2017-09-05 08:06:00.000
Запрос
select * from project_table
Выходные данные
===================================
Project Creationtime
===================================
project1 2015-01-01 00:00:00.000
project2 2016-02-02 01:23:00.000
project3 2017-03-04 05:16:00.000
Запрос
select * from watermarktable
Выходные данные
======================================
TableName WatermarkValue
======================================
customer_table 2017-09-05 08:06:00.000
project_table 2017-03-04 05:16:00.000
Обратите внимание, что значения предела для обеих таблиц обновились.
Добавление данных в исходные таблицы
Выполните следующий запрос в исходной базе данных SQL Server, чтобы обновить имеющуюся строку в таблице customer_table. Вставьте новую строку в таблицу project_table.
UPDATE customer_table
SET [LastModifytime] = '2017-09-08T00:00:00Z', [name]='NewName' where [PersonID] = 3
INSERT INTO project_table
(Project, Creationtime)
VALUES
('NewProject','10/1/2017 0:00:00 AM');
Повторный запуск конвейера
Теперь снова запустите конвейер. Для этого выполните следующую команду PowerShell:
$RunId = Invoke-AzDataFactoryV2Pipeline -PipelineName "IncrementalCopyPipeline" -ResourceGroup $resourceGroupname -dataFactoryName $dataFactoryName -ParameterFile ".\Parameters.json"Чтобы отслеживать выполнение конвейера, следуйте инструкциям из раздела Мониторинг конвейера. Когда конвейер находится в состоянии Выполняется, отображается ссылка на другое действие в столбце Действия, с помощью которой можно отменить выполнение конвейера.
Выберите Обновить, чтобы обновить список, пока конвейер не будет выполнен.
(Необязательно.) Щелкните ссылку View Activity Runs (Просмотреть выполнения действий) в области Действия, чтобы просмотреть все выполнения действий, связанные с этим запуском конвейера.
Просмотр окончательных результатов
В SQL Server Management Studio выполните следующие запросы в целевой базе данных SQL Azure. Так вы проверите, что обновленные и новые данные скопированы из исходных таблиц в целевые.
Запрос
select * from customer_table
Выходные данные
===========================================
PersonID Name LastModifytime
===========================================
1 John 2017-09-01 00:56:00.000
2 Mike 2017-09-02 05:23:00.000
3 NewName 2017-09-08 00:00:00.000
4 Andy 2017-09-04 03:21:00.000
5 Anny 2017-09-05 08:06:00.000
Обратите внимание на новые значения в столбцах Name и LastModifytime для строки под номером 3 в столбце PersonID.
Запрос
select * from project_table
Выходные данные
===================================
Project Creationtime
===================================
project1 2015-01-01 00:00:00.000
project2 2016-02-02 01:23:00.000
project3 2017-03-04 05:16:00.000
NewProject 2017-10-01 00:00:00.000
Обратите внимание, что запись NewProject добавлена в таблицу project_table.
Запрос
select * from watermarktable
Выходные данные
======================================
TableName WatermarkValue
======================================
customer_table 2017-09-08 00:00:00.000
project_table 2017-10-01 00:00:00.000
Обратите внимание, что значения предела для обеих таблиц обновились.
Связанный контент
В этом руководстве вы выполнили следующие шаги:
- подготовите исходное и конечное хранилища данных;
- Создали фабрику данных.
- Создание локальной среды выполнения интеграции (IR).
- Установка среды выполнения интеграции.
- Создали связанные службы.
- Создали наборы данных источника, приемника и предела.
- создадите и запустите конвейер, а также начнете его мониторинг;
- Проверка результатов.
- Добавление или обновление данных в исходных таблицах.
- Повторный запуск конвейера и выполнение его мониторинга.
- Просмотр окончательных результатов.
Перейдите к следующему руководству, чтобы узнать о преобразовании данных с помощью кластера Spark в Azure: