Копирование из базы данных SQL Server в хранилище BLOB-объектов Azure
ОБЛАСТЬ ПРИМЕНЕНИЯ:  Фабрика данных Azure Azure Synapse Analytics
Фабрика данных Azure Azure Synapse Analytics
Совет
Попробуйте использовать фабрику данных в Microsoft Fabric, решение для аналитики с одним интерфейсом для предприятий. Microsoft Fabric охватывает все, от перемещения данных до обработки и анализа данных в режиме реального времени, бизнес-аналитики и отчетности. Узнайте, как бесплатно запустить новую пробную версию !
В этом руководстве вы создадите конвейер фабрики данных, в котором данные из базы данных SQL Server копируются в хранилище BLOB-объектов Azure, с помощью пользовательского интерфейса службы "Фабрика данных Azure". Вы создадите и будете использовать локальную среду выполнения интеграции, которая перемещает данные между локальным и облачным хранилищами данных.
Примечание.
В этой статье не содержится подробного введения в фабрику данных. Дополнительные сведения см. в статье Введение в фабрику данных Azure.
Вот какие шаги выполняются в этом учебнике:
- Создали фабрику данных.
- Создание локальной среды выполнения интеграции.
- Создадите SQL Server и связанные службы Azure.
- Создадите SQL Server и наборы данных больших двоичных объектов Azure.
- Создадите конвейер с действием копирования для перемещения данных.
- Запуск конвейера.
- Осуществили мониторинг выполнения конвейера.
Предварительные требования
Подписка Azure.
Если у вас еще нет подписки Azure, создайте бесплатную учетную запись Azure, прежде чем начинать работу.
Роли в Azure
Чтобы создать экземпляры фабрики данных, нужно назначить учетной записи пользователя, используемой для входа в Azure, роль участника, владельца либо администратора подписки Azure.
Чтобы просмотреть существующие разрешения в подписке, перейдите на портал Azure. Сначала в верхнем правом углу выберите имя пользователя, а затем — Разрешения. Если у вас есть доступ к нескольким подпискам, выберите соответствующую подписку. Примеры инструкций по назначению пользователю роли см. в статье Назначение ролей Azure с помощью портала Azure.
SQL Server 2014, 2016 и 2017
В этом руководстве используйте базу данных SQL Server в качестве исходного хранилища данных. Конвейер фабрики данных, созданный в рамках этого руководства, копирует данные из этой базы данных SQL Server (источника) в хранилище BLOB-объектов (приемник). Затем создайте таблицу с именем emp в базе данных SQL Server и вставьте в нее несколько примеров записей.
Запустите SQL Server Management Studio. Если она еще не установлена на вашем компьютере, скачайте ее со страницы Скачивание SQL Server Management Studio (SSMS).
Подключитесь к экземпляру SQL Server с помощью учетных данных.
Создайте пример базы данных. В представлении в виде дерева щелкните правой кнопкой мыши элемент Базы данных и выберите пункт Новая база данных.
В окне Новая база данных введите имя базы данных и нажмите кнопку ОК.
Чтобы создать таблицу emp и вставить в нее примеры данных, запустите приведенный ниже сценарий запроса к базе данных. В представлении в виде дерева щелкните правой кнопкой мыши созданную базу данных и выберите пункт Новый запрос.
CREATE TABLE dbo.emp ( ID int IDENTITY(1,1) NOT NULL, FirstName varchar(50), LastName varchar(50) ) GO INSERT INTO emp (FirstName, LastName) VALUES ('John', 'Doe') INSERT INTO emp (FirstName, LastName) VALUES ('Jane', 'Doe') GO
Учетная запись хранения Azure
В этом руководстве используйте учетную запись хранения Azure общего назначения (хранилища BLOB-объектов) в качестве целевого (принимающего) хранилища данных. Если у вас нет учетной записи хранения Azure общего назначения, см. инструкции по созданию учетной записи хранения. Конвейер фабрики данных, созданный в рамках этого руководства, копирует данные из базы данных SQL Server (источника) в хранилище BLOB-объектов (приемник).
Получение имени и ключа учетной записи хранения и ключа учетной записи
В этом руководстве вы будете использовать имя и ключ своей учетной записи хранения. Чтобы получить имя и ключ учетной записи хранения, сделайте следующее:
Войдите на портал Azure, используя имя пользователя и пароль Azure.
На панели слева выберите Все службы. Отфильтруйте содержимое по ключевому слову хранение, а затем выберите Учетные записи хранения.
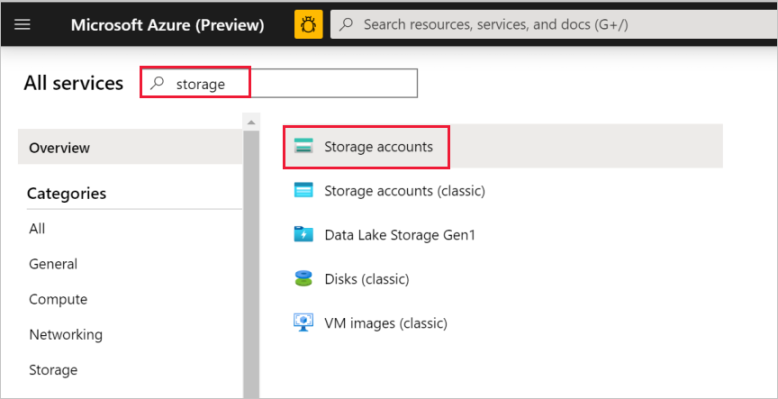
В списке учетных записей хранения найдите с помощью фильтра свою учетную запись хранения (при необходимости). Затем выберите свою учетную запись хранения.
В окне Учетная запись хранения выберите параметр Ключи доступа.
Скопируйте значения полей Имя учетной записи хранения и key1. Затем вставьте их в Блокнот или другой редактор для дальнейшего использования в руководстве.
Создание контейнера adftutorial
В этом разделе вы создадите контейнер больших двоичных объектов с именем adftutorial в хранилище BLOB-объектов.
В окне Учетная запись хранения перейдите на вкладку Обзор и выберите Контейнеры.
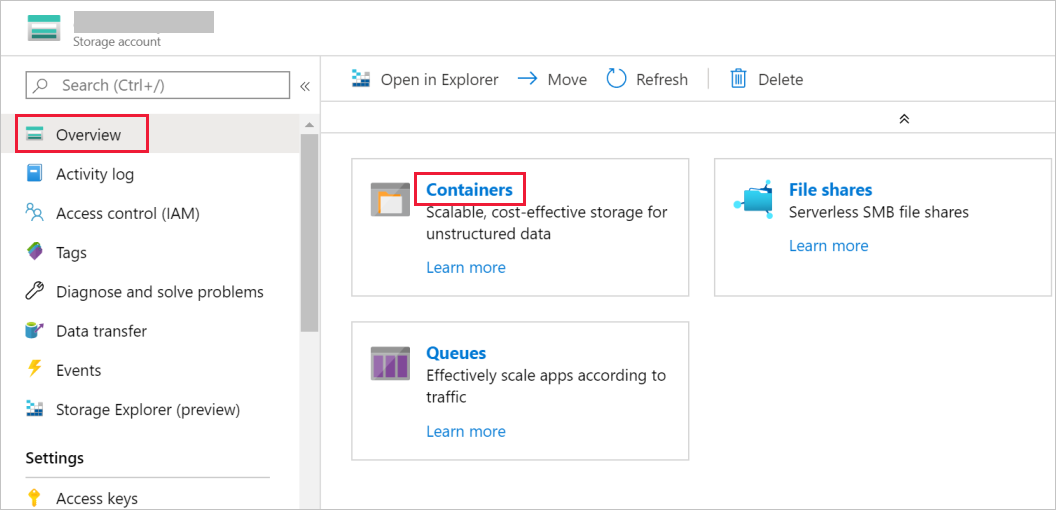
В окне Контейнеры выберите + Container (Создать контейнер).
В окне Создание контейнера в поле Имя введите adftutorial. Затем выберите Создать.
В списке контейнеров выберите adftutorial, который вы только что создали.
Не закрывайте окно контейнераadftutorial. Оно понадобится для проверки выходных данных в конце учебника. Фабрика данных автоматически создает выходную папку в этом контейнере, поэтому ее не нужно создавать.
Создание фабрики данных
На этом этапе вы создадите фабрику данных и запустите пользовательский интерфейс службы "Фабрика данных" для создания конвейера в фабрике данных.
Откройте веб-браузер Microsoft Edge или Google Chrome. Сейчас только эти браузеры поддерживают пользовательский интерфейс фабрики данных.
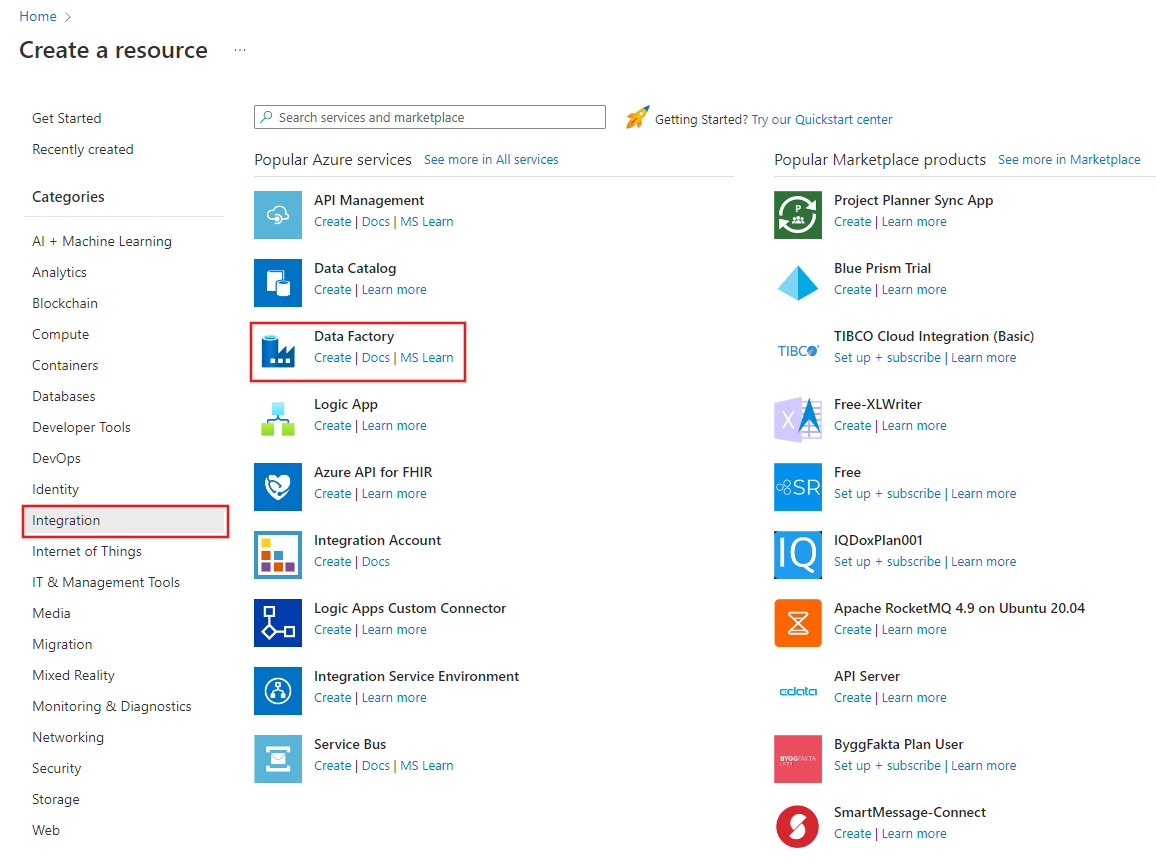
В меню слева выберите Создать ресурс>Интеграция>Фабрика данных:
На странице Новая фабрика данных в поле Имя введите ADFTutorialDataFactory.
Имя фабрики данных должно быть глобально уникальным. Если вы увидите следующее сообщение об ошибке для поля имени, введите другое имя фабрики данных (например, ваше_имя_ADFTutorialBulkCopyDF). Дополнительные сведения о правилах именования артефактов фабрики данных см. в статье Фабрика данных Azure — правила именования.
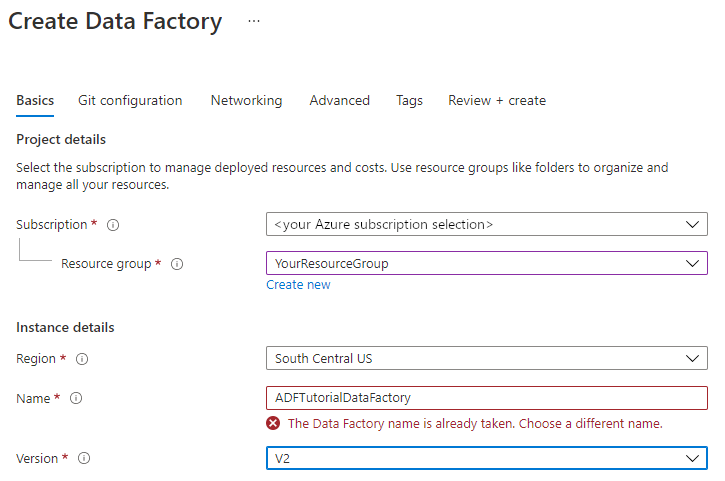
Выберите подписку Azure, в рамках которой вы хотите создать фабрику данных.
Для группы ресурсов выполните одно из следующих действий:
Выберите Использовать существующуюи укажите существующую группу ресурсов в раскрывающемся списке.
Выберите Создать новуюи укажите имя группы ресурсов.
Сведения о группах ресурсов см. в статье Общие сведения об Azure Resource Manager.
В качестве версии выберите V2.
В качестве расположения выберите расположение фабрики данных. В раскрывающемся списке отображаются только поддерживаемые расположения. Хранилища данных (например, служба хранилища и база данных SQL) и вычислительные ресурсы (например, Azure HDInsight), используемые фабрикой данных, могут располагаться в других регионах.
Нажмите кнопку создания.
Когда завершится создание, откроется страница Фабрика данных, как показано на рисунке ниже.

Выберите Открыть на плитке Open Azure Data Factory Studio (Открыть студию Фабрики данных Azure), чтобы запустить пользовательский интерфейс Фабрики данных на отдельной вкладке.
Создание конвейера
На домашней странице пользовательского интерфейса Фабрики данных выберите элемент Orchestrate (Оркестрация). Будет автоматически создан конвейер. Конвейер отобразится в представлении в виде дерева и откроется в редакторе.
На общей панели в разделе Свойства укажите значение SQLServerToBlobPipeline для параметра Имя. Затем сверните панель, щелкнув значок Свойства в правом верхнем углу.
На панели инструментов Действия разверните Move & Transform (Переместить и преобразовать). Перетащите действие копирования на рабочую область конструирования конвейера. Задайте этому действию имя CopySqlServerToAzureBlobActivity.
В окне свойств перейдите на вкладку Источник и выберите + Создать.
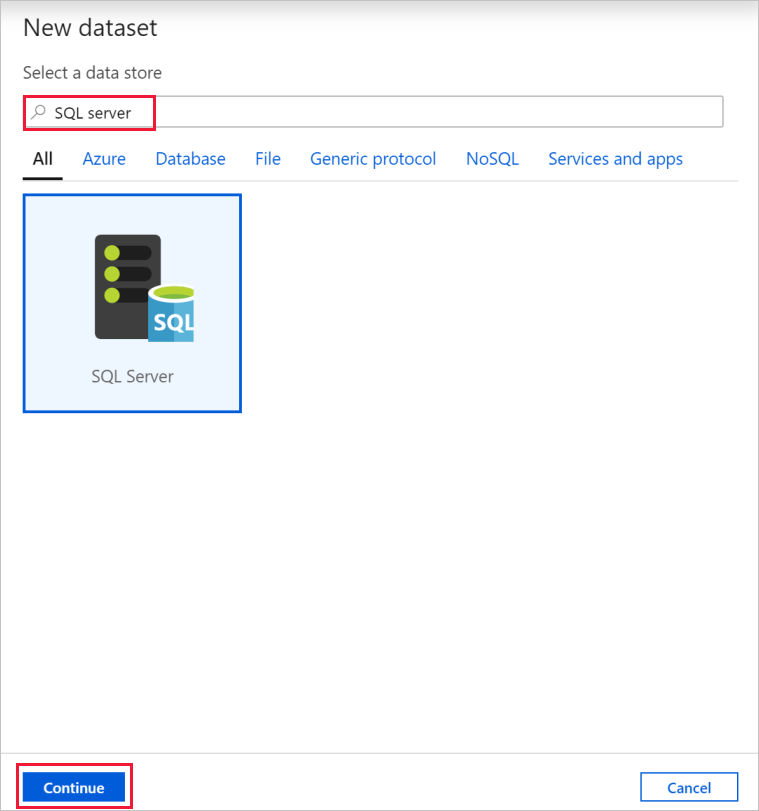
В диалоговом окне Новый набор данных найдите SQL Server. Выберите SQL Server, а затем нажмите кнопку Продолжить.
В диалоговом окне Set Properties (Установка свойств) в поле Имя введите SqlServerDataset. В разделе Связанная служба выберите + Создать. На этом этапе вы создадите подключение к исходному хранилищу данных (база данных SQL Server).
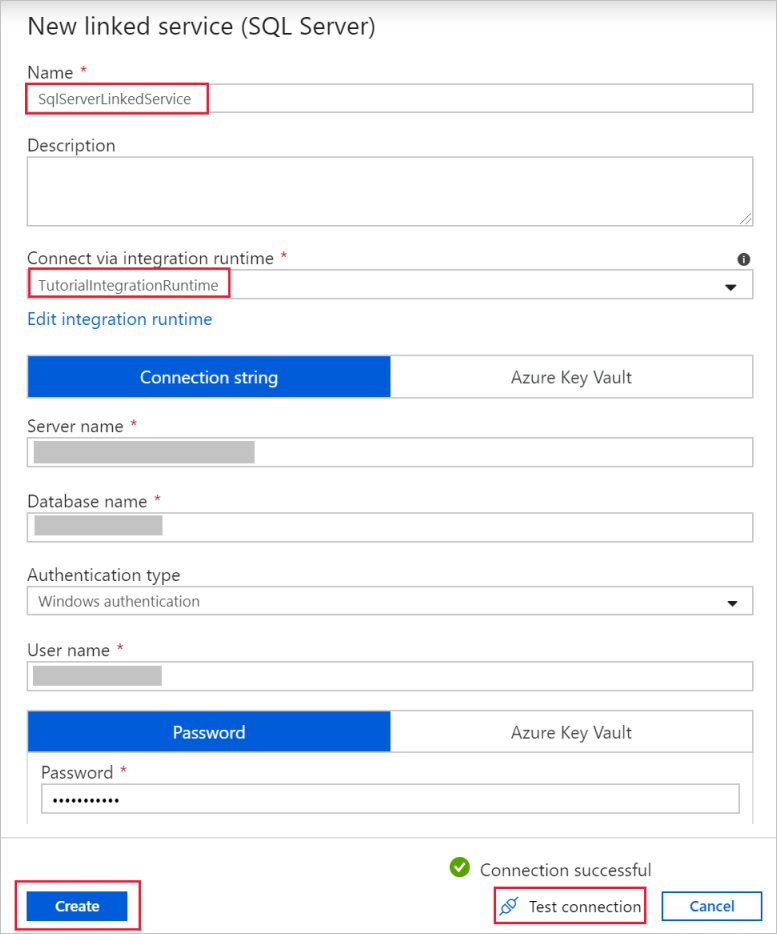
В диалоговом окне New Linked Service (Новая связанная служба) добавьте имяSqlServerLinkedService. В разделе Connect via integration runtime (Подключение через среду выполнения интеграции) выберите +Создать. В этом разделе вы создадите локальную среду выполнения интеграции и свяжете ее с локальным компьютером, на котором находится база данных SQL Server. Локальная среда выполнения интеграции — это компонент, который копирует данные из базы данных SQL Server на компьютере в хранилище BLOB-объектов.
В диалоговом окне Integration Runtime Setup (Настройка среды выполнения интеграции) выберите Независимый, а затем щелкните Продолжить.
В поле "Имя" введите TutorialIntegrationRuntime. Затем выберите Создать.
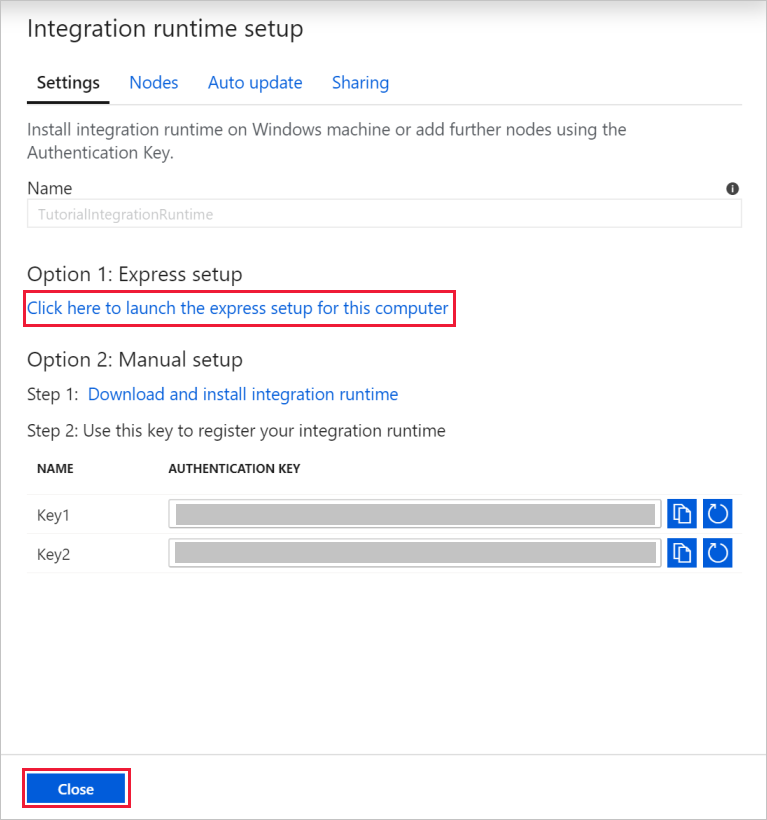
Для параметров, выберите элемент Click here to launch the express setup for this computer (Щелкните здесь, чтобы запустить экспресс-установку для этого компьютера). Это действие устанавливает среду выполнения интеграции на локальном компьютере и регистрирует ее с использованием фабрики данных. Кроме того, вы можете использовать режим установки вручную: скачайте файл установки, запустите его и примените ключ для регистрации среды выполнения интеграции.
В окне Экспресс-установка Integration Runtime (Self-hosted) выберите Закрыть по завершении процесса.
Убедитесь, что в диалоговом окне New Linked Service (SQL Server) (Новая связанная служба) для поля Connect via integration runtime (Подключение через среду выполнения интеграции) выбран вариант TutorialIntegrationRuntime. Затем выполните следующие действия:
a. В поле Имя введите SqlServerLinkedService.
b. В поле Имя серверавведите имя экземпляра SQL Server.
c. В поле Имя базы данных введите имя базы данных, которая содержит таблицу emp.
d. В поле Тип проверки подлинности, выберите нужный тип аутентификации, который будет использоваться в фабрике данных для подключения к базе данных SQL Server.
д) В полях имени пользователя и пароля введите имя пользователя и пароль. При необходимости в качестве имени пользователя укажите mydomain\myuser.
f. Выберите Test connection (Проверить подключение). Этот шаг позволит проверить подключение Фабрики данных к базе данных SQL Server при помощи созданной в этом процессе локальной среды выполнения интеграции.
ж. Выберите Сохранить, чтобы сохранить связанную службу.
После создания связанной службы откроется страница Задание свойств для SqlServerDataset. Выполните следующие шаги:
a. Убедитесь, что в поле Связанная служба выбрано значение SqlServerLinkedService.
b. В разделе Имя таблицы выберите [dbo].[emp].
c. Нажмите ОК.
Перейдите на вкладку SQLServerToBlobPipeline или выберите элемент SQLServerToBlobPipeline в представлении в виде дерева.
Перейдите на вкладку Приемник в нижней части окна свойств и выберите + Создать.
В диалоговом окне Новый набор данных выберите Хранилище BLOB-объектов Azure. Затем выберите Continue (Продолжить).
В диалоговом окне Выбрать формат выберите тип формата данных. Затем выберите Continue (Продолжить).

В диалоговом окне Set Properties (Установка свойств) введите AzureBlobDataset в качестве имени. Рядом с текстовым полем Связанная служба нажмите кнопку + Создать.
В окне New Linked Service (Azure Blob Storage) (Новая связанная служба (хранилище BLOB-объектов Azure)) в качестве имени введите AzureStorageLinkedService и выберите учетную запись хранения в списке Имя учетной записи хранения. Проверьте подключение, а затем нажмите кнопку Создать, чтобы развернуть связанную службу.
После создания связанной службы откроется страница Set properties (Установка свойств). Нажмите ОК.
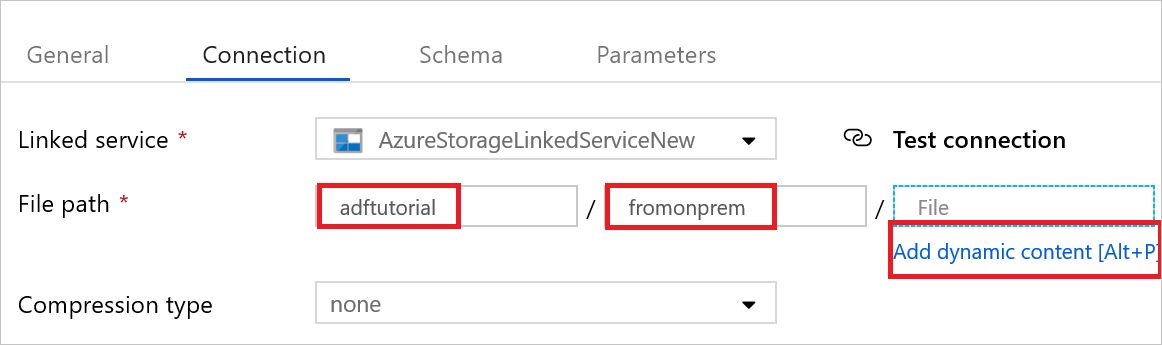
Откройте набор данных приемника. На вкладке Подключение сделайте следующее:
a. Убедитесь, что в списке Связанная служба выбрано значение AzureStorageLinkedService.
b. В поле Путь к файлу введите значение adftutorial/fromonprem для частей Container/ Directory (Контейнер/Каталог). Если указанной папки выходных данных не существует в контейнере adftutorial, она будет автоматически создана в фабрике данных.
c. Для части Файл выберите Добавить динамическое содержимое.
d. Добавьте
@CONCAT(pipeline().RunId, '.txt')и нажмите кнопку Готово. Файл будет переименован в PipelineRunID.txt.Перейдите на вкладку с открытым конвейером или выберите конвейер в представлении в виде дерева. Убедитесь, что в списке Sink Dataset (Целевой набор данных) выбрано значение AzureBlobDataset.
Чтобы проверить параметры конвейера, выберите Проверка на панели инструментов для этого конвейера. Чтобы закрыть Pipe validation output (Результаты проверки канала), выберите значок >>.
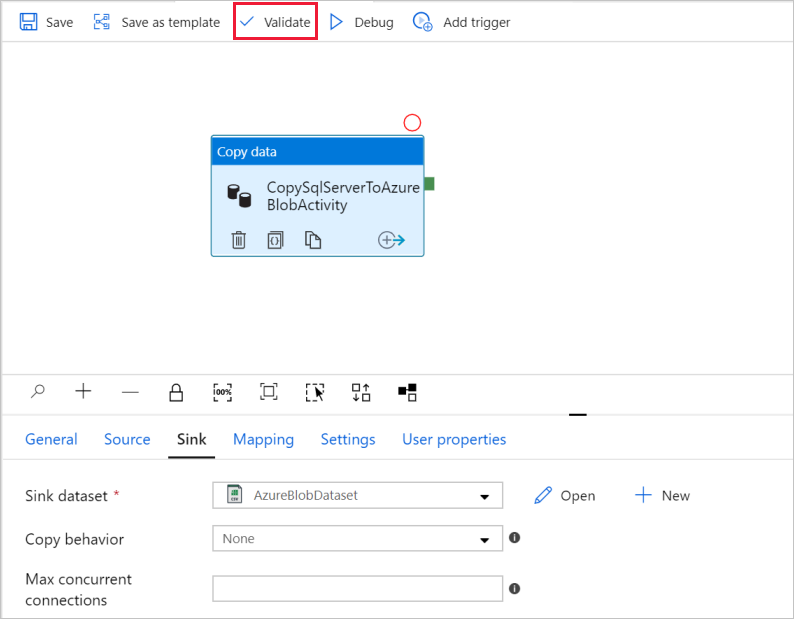
Чтобы опубликовать сущности, созданные в Фабрике данных, выберите Опубликовать все.
Дождитесь всплывающего окна с сообщением Публикация выполнена. Чтобы проверить состояние публикации, выберите ссылку Показать уведомления в верхней части окна. Чтобы закрыть окно уведомлений, выберите Закрыть.
Активация выполнения конвейера
Выберите Добавить триггер на панели инструментов контейнера, а затем Trigger Now (Запустить сейчас).
Мониторинг конвейера
Перейдите на вкладку "Монитор ". Вы увидите конвейер, который вы активировали вручную на предыдущем шаге.
Чтобы просмотреть выполнение действий, связанных с выполнением конвейера, выберите ссылку SQLServerToBlobPipeline в разделе ИМЯ КОНВЕЙЕРА.

На странице выполнения действий выберите ссылку сведений (образ очков), чтобы просмотреть сведения об операции копирования. Выберите Все запуски конвейеров в верхней части окна, чтобы вернуться к представлению "Выполнения конвейеров".
Проверка выходных данных
Конвейер автоматически создает выходную папку с именем fromonprem в контейнере больших двоичных объектов adftutorial. Убедитесь, что в выходной папке отображается файл [pipeline().RunId].txt.
Связанный контент
В этом примере конвейер копирует данные из одного расположения в другое в хранилище BLOB-объектов. Вы научились выполнять следующие задачи:
- Создали фабрику данных.
- Создание локальной среды выполнения интеграции.
- Создавать связанные службы SQL Server и хранилища.
- Создавать наборы данных SQL Server и хранилища BLOB-объектов.
- Создадите конвейер с действием копирования для перемещения данных.
- Запуск конвейера.
- Осуществили мониторинг выполнения конвейера.
Список хранилищ данных, поддерживаемых фабрикой данных, см. в разделе Поддерживаемые хранилища данных и форматы.
Чтобы узнать о копировании данных в пакетном режиме из источника в место назначения, перейдите к следующему руководству: