Преобразование с помощью Azure Databricks
ОБЛАСТЬ ПРИМЕНЕНИЯ:  Фабрика данных Azure Azure Synapse Analytics
Фабрика данных Azure Azure Synapse Analytics
Совет
Попробуйте использовать фабрику данных в Microsoft Fabric, решение для аналитики с одним интерфейсом для предприятий. Microsoft Fabric охватывает все, от перемещения данных до обработки и анализа данных в режиме реального времени, бизнес-аналитики и отчетности. Узнайте, как бесплатно запустить новую пробную версию !
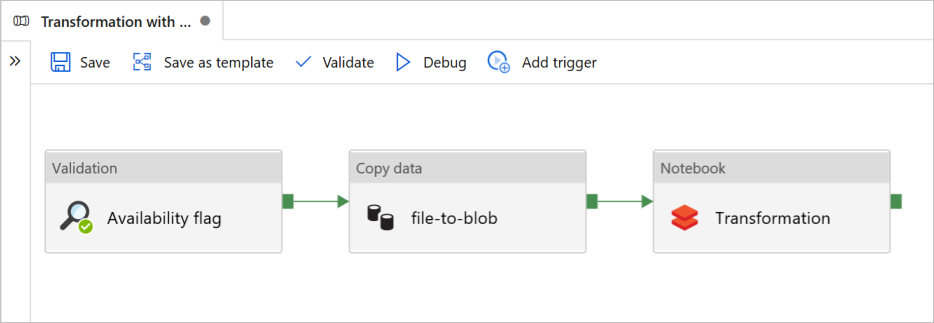
В этом учебнике рассматривается создание комплексного конвейера, который охватывает действия Проверка, Копирование данных и Записная книжка в Фабрике данных Azure.
Проверка гарантирует готовность исходного набора данных к дальнейшему использованию перед запуском задания копирования и аналитики.
Копирование данных дублирует исходный набор данных в хранилище-приемник, которое подключается как DBFS в записной книжке Azure Databricks. Таким образом, Spark может напрямую использовать этот набор данных.
Записная книжка активирует записную книжку Databricks, которая преобразует набор данных. Это действие также добавляет набор данных в обработанную папку или в Azure Synapse Analytics.
Для простоты в этом учебнике рассматривается шаблон, который не создает триггер по расписанию. При необходимости вы можете его добавить.
Необходимые компоненты
Учетная запись хранилища BLOB-объектов Azure с контейнером
sinkdata, который используется в качестве приемника.Запишите имя учетной записи хранения, имя контейнера и ключ доступа. Эти данные понадобятся позже в этом шаблоне.
Рабочая область Azure Databricks.
Импорт записной книжки для преобразования
Чтобы импортировать записную книжку Преобразование в рабочую область Databricks, сделайте следующее:
Войдите в рабочую область Azure Databricks.
Щелкните правой кнопкой мыши папку в рабочей области и выберите "Импорт".
Выберите Import from: URL (Импорт из URL-адреса). В текстовое поле введите
https://adflabstaging1.blob.core.windows.net/share/Transformations.html.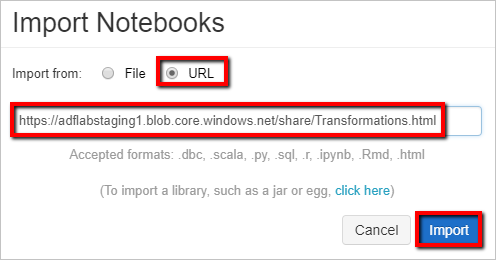
Теперь давайте обновим записную книжку Преобразование, указав сведения о подключении к хранилищу.
В импортированной записной книжке перейдите к команде 5, как показано в приведенном ниже фрагменте кода.
- Замените
<storage name>и<access key>собственными данными для подключения к хранилищу. - Используйте учетную запись хранения с контейнером
sinkdata.
# Supply storageName and accessKey values storageName = "<storage name>" accessKey = "<access key>" try: dbutils.fs.mount( source = "wasbs://sinkdata\@"+storageName+".blob.core.windows.net/", mount_point = "/mnt/Data Factorydata", extra_configs = {"fs.azure.account.key."+storageName+".blob.core.windows.net": accessKey}) except Exception as e: # The error message has a long stack track. This code tries to print just the relevant line indicating what failed. import re result = re.findall(r"\^\s\*Caused by:\s*\S+:\s\*(.*)\$", e.message, flags=re.MULTILINE) if result: print result[-1] \# Print only the relevant error message else: print e \# Otherwise print the whole stack trace.- Замените
Создайте маркер доступа Databricks, чтобы Фабрика данных могла получать доступ к Databricks.
- В рабочей области Azure Databricks выберите имя пользователя Azure Databricks в верхней строке и выберите "Параметры" в раскрывающемся списке.
- Выберите разработчика.
- Рядом с маркерами доступа нажмите кнопку "Управление".
- Выберите Создать новый маркер.
- (Необязательно) Введите комментарий, который поможет определить этот маркер в будущем и изменить время существования маркера по умолчанию в течение 90 дней. Чтобы создать маркер без времени существования (не рекомендуется), оставьте поле время существования (дни) пустым (пустым).
- Выберите Создать.
- Скопируйте отображаемый маркер в безопасное расположение и нажмите кнопку "Готово".
Сохраните маркер доступа для дальнейшего использования при создании связанной службы Databricks. Маркер доступа выглядит примерно так dapi32db32cbb4w6eee18b7d87e45exxxxxx.
Как использовать этот шаблон
Перейдите к шаблону Transformation with Azure Databricks (Преобразование с помощью Azure Databricks) и создайте новые связанные службы для следующих подключений:
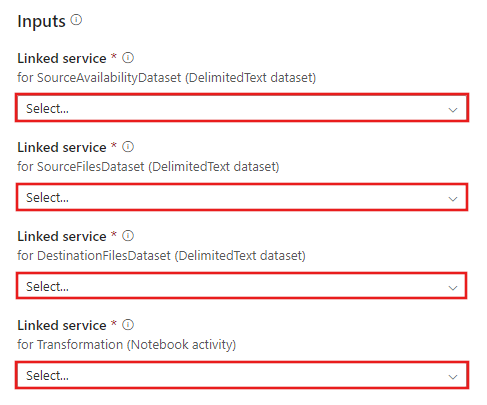
Source Blob Connection (Подключение к исходному BLOB-объекту) используется для доступа к исходным данным.
В этом упражнении вы можете использовать общедоступное хранилище BLOB-объектов, содержащее исходные файлы. Конфигурация приведена на снимке экрана ниже. Для подключения к исходному хранилищу (с доступом только для чтения) используйте следующий URL-адрес SAS:
https://storagewithdata.blob.core.windows.net/data?sv=2018-03-28&si=read%20and%20list&sr=c&sig=PuyyS6%2FKdB2JxcZN0kPlmHSBlD8uIKyzhBWmWzznkBw%3D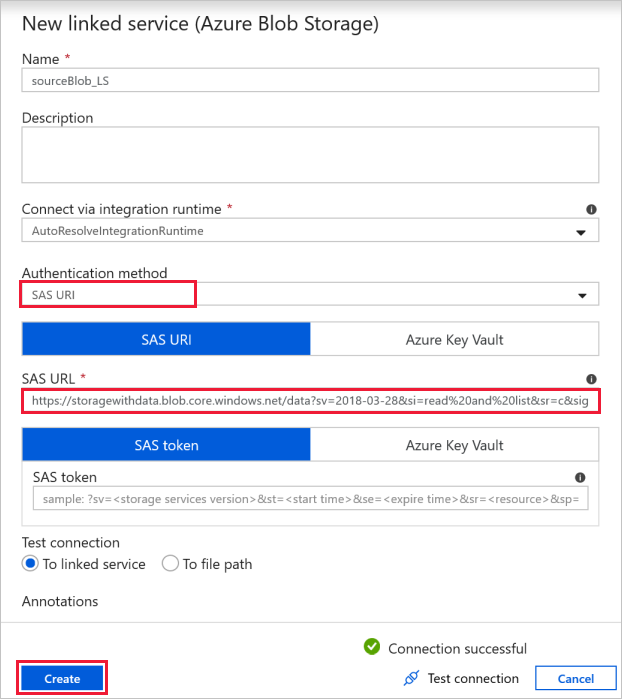
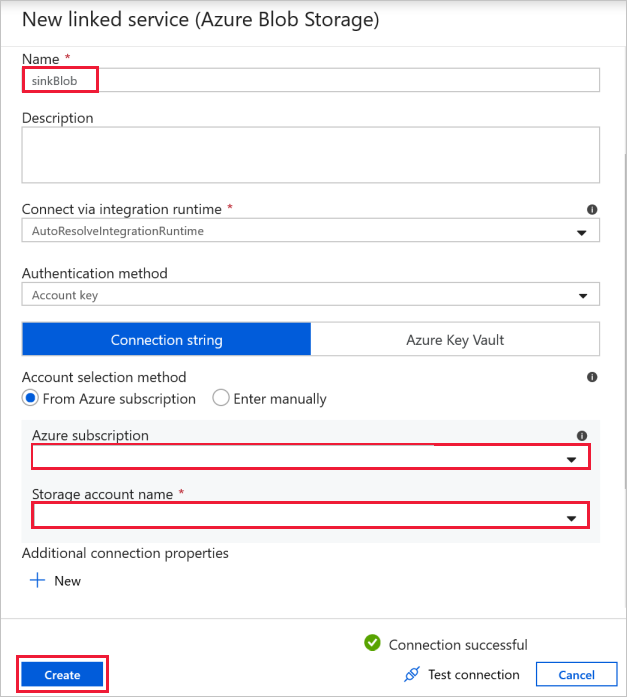
Destination Blob Connection (Подключение к целевому BLOB-объекту) используется для хранения скопированных данных.
В окне New linked service (Новая связанная служба) выберите BLOB-объект в хранилище-приемнике.
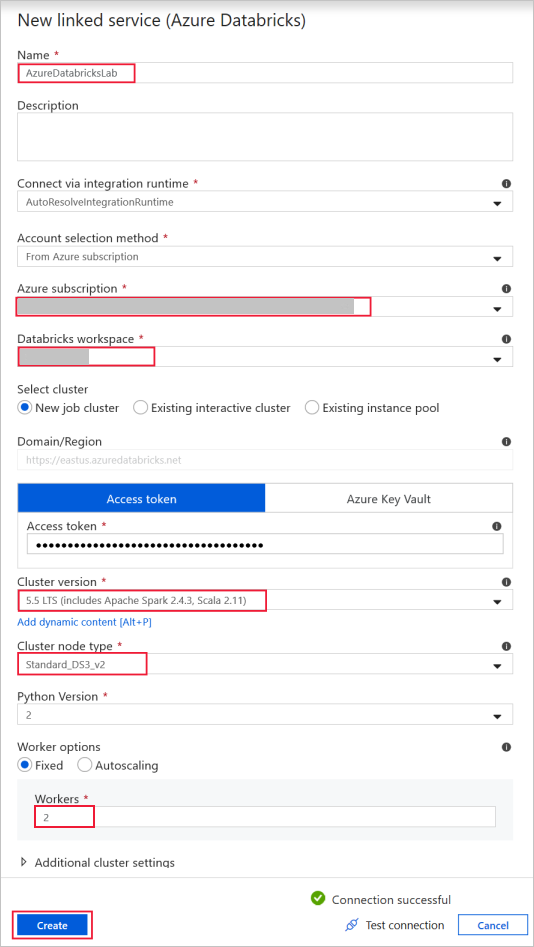
Значение Azure Databricks используется для подключения к кластеру Databricks.
Создайте связанную службу Databricks с помощью созданного ранее ключа доступа. Вы можете выбрать интерактивный кластер, если он существует. В этом примере используется параметр New job cluster (Новый кластер заданий).
Выберите Использовать этот шаблон. Вы увидите созданный конвейер.
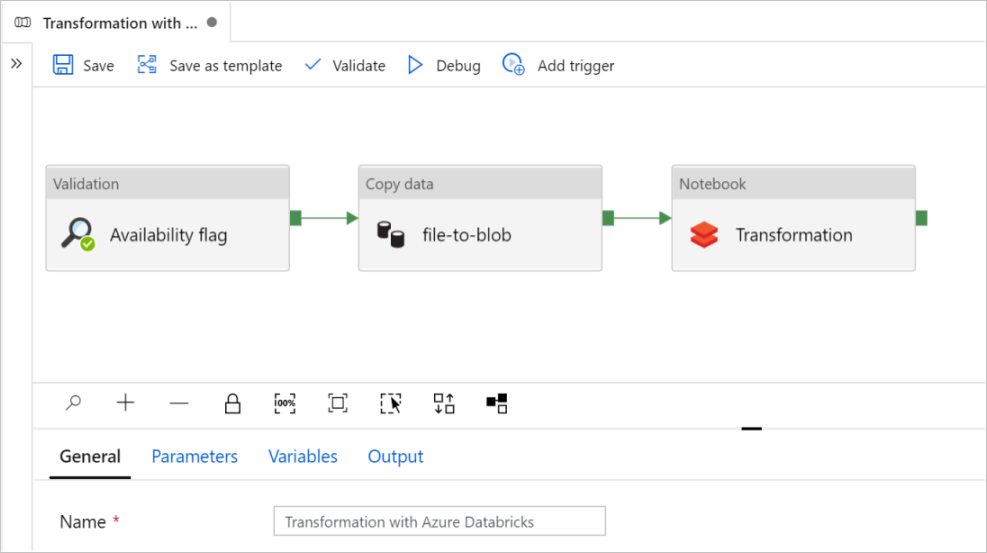
Общие сведения о конвейере и его настройке
В новом конвейере большинство параметров настроены автоматически со значениями по умолчанию. Проверьте конфигурацию конвейера и внесите необходимые изменения.
В поле Availability flag (Флаг доступности) действия Validation (Проверка) убедитесь в том, что параметру Dataset (Набор данных) для исходного набора данных присвоено значение
SourceAvailabilityDataset, которое вы создали раньше.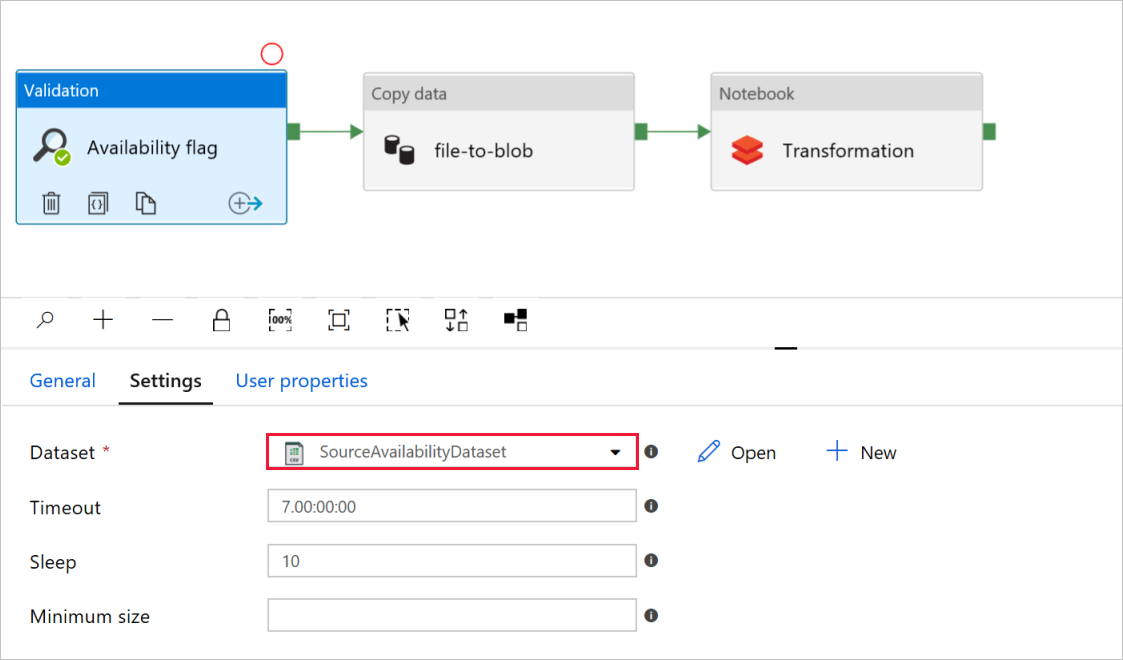
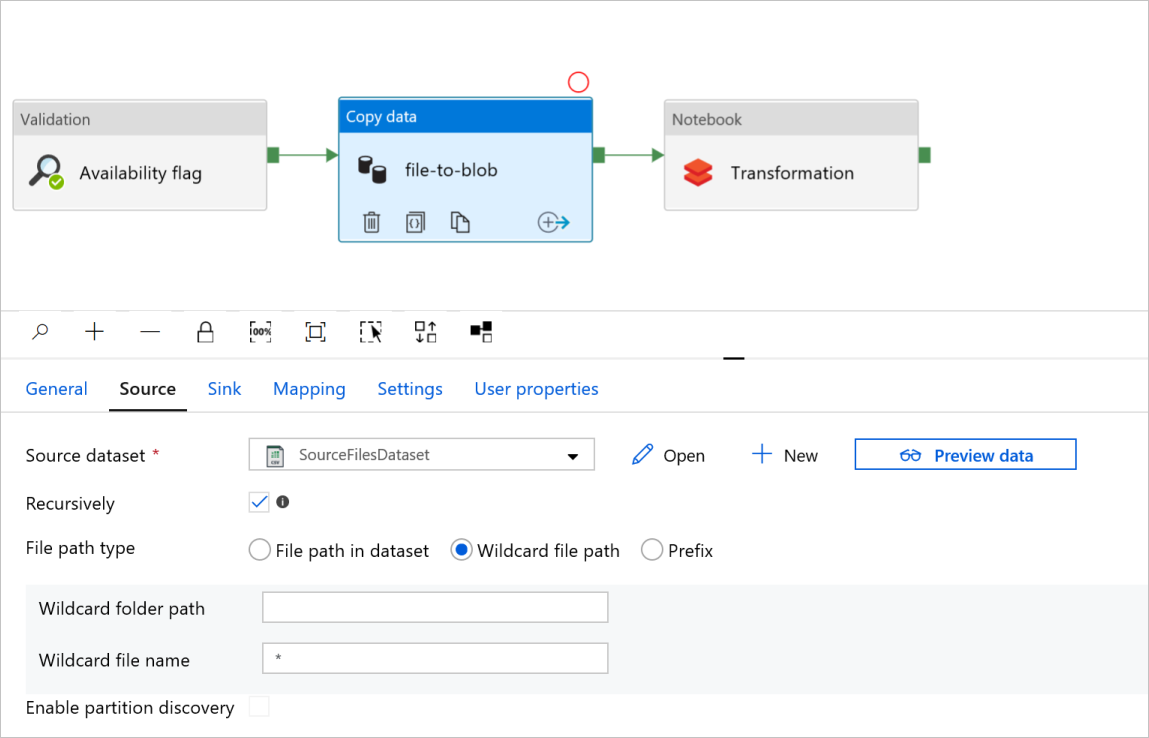
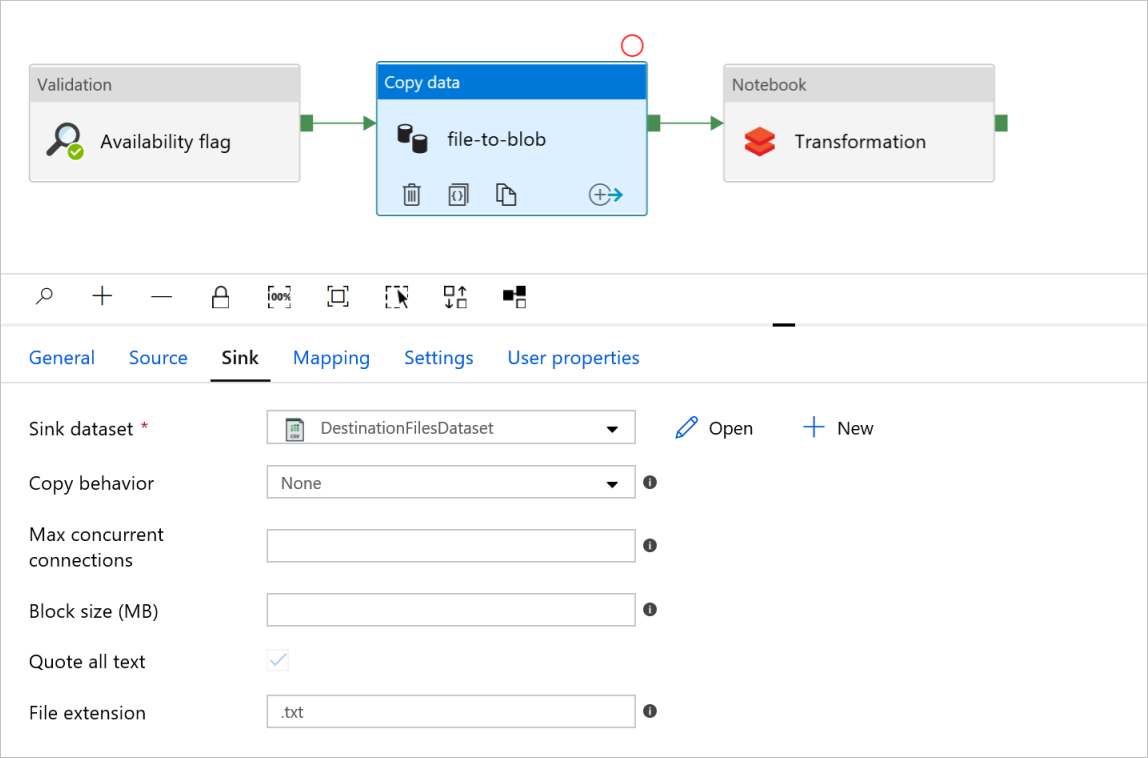
В поле file-to-blob действия Copy data (Копирование данных) проверьте вкладки Source (Источник) и Sink (Приемник). При необходимости измените параметры.
Вкладка "Источник"
Вкладка приемника
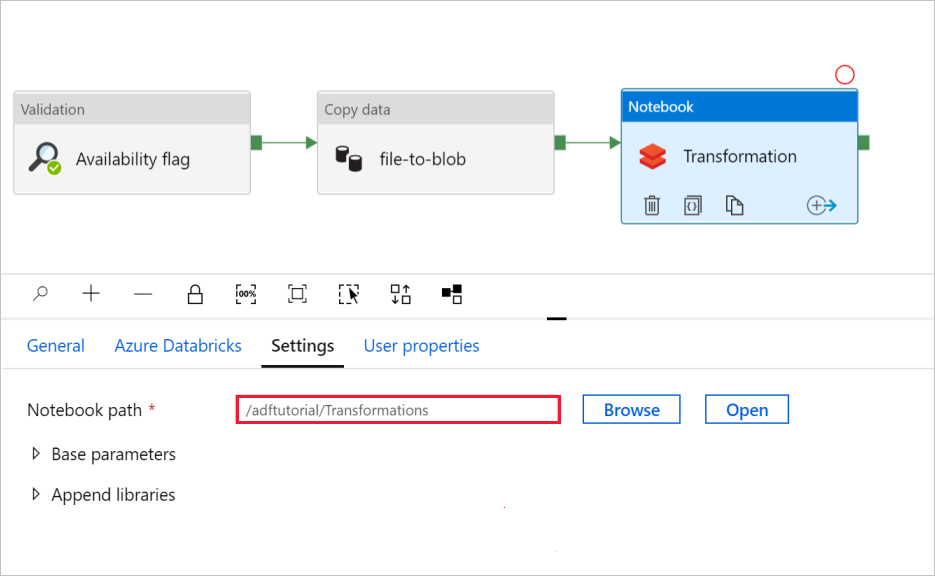
В поле Transformation (Преобразование) действия Notebook (Записная книжка) проверьте и при необходимости обновите пути и параметры.
Связанная служба Databricks должна быть предварительно заполнена значением из предыдущего шага, как показано ниже.
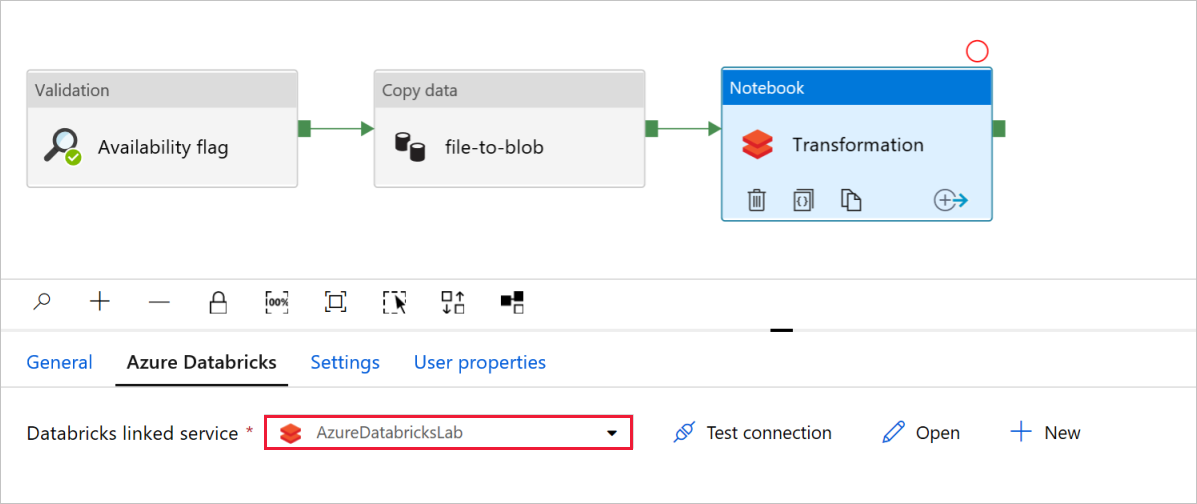
Проверьте параметры действия Notebook (Записная книжка).
Откройте вкладку Settings (Параметры). Проверьте, правильно ли задан путь по умолчанию в поле Notebook path (Путь к записной книжке). Возможно, потребуется открыть и выбрать правильный путь к записной книжке.
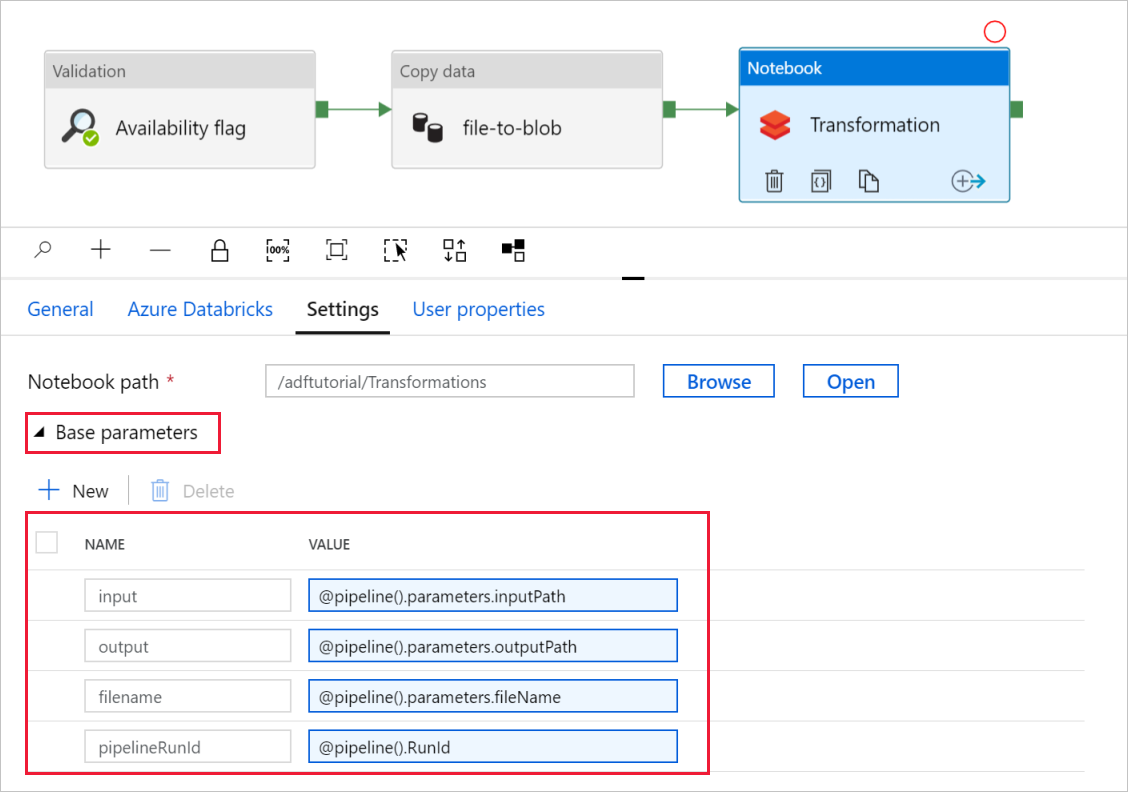
Разверните раздел Base Parameters (Базовые параметры) и убедитесь, что параметры соответствуют приведенным на снимке экрана ниже. Эти параметры передаются в записную книжку Databricks из Фабрики данных.
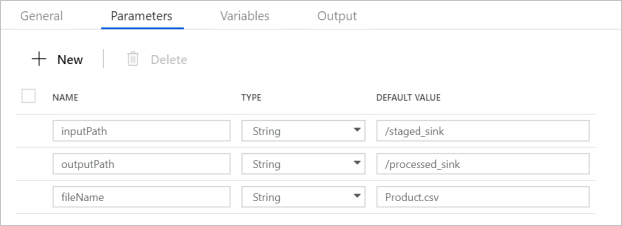
Убедитесь, что параметры конвейера соответствуют показанным на следующем снимке экрана:
Подключитесь к наборам данных.
Примечание.
В приведенных ниже наборах данных путь к файлу был автоматически указан в шаблоне. Если требуются какие-либо изменения, убедитесь, что вы указали путь и для контейнера, и для каталога на случай ошибки подключения.
SourceAvailabilityDataset используется для проверки доступности исходных данных.
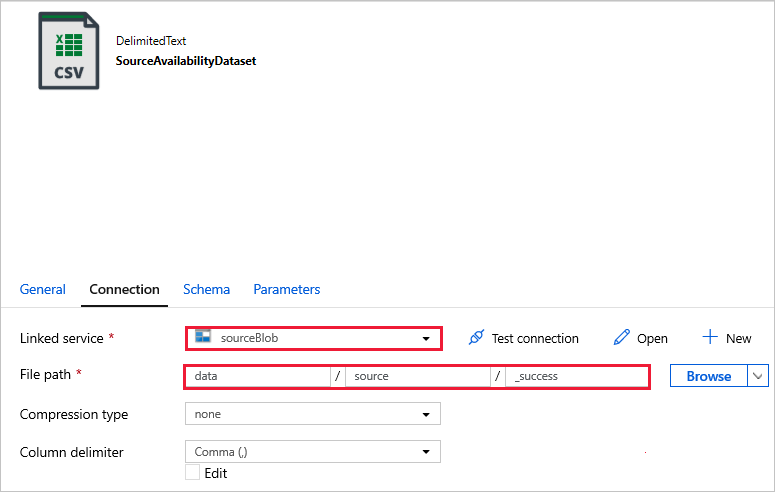
SourceFilesDataset используется для доступа к исходным данным.
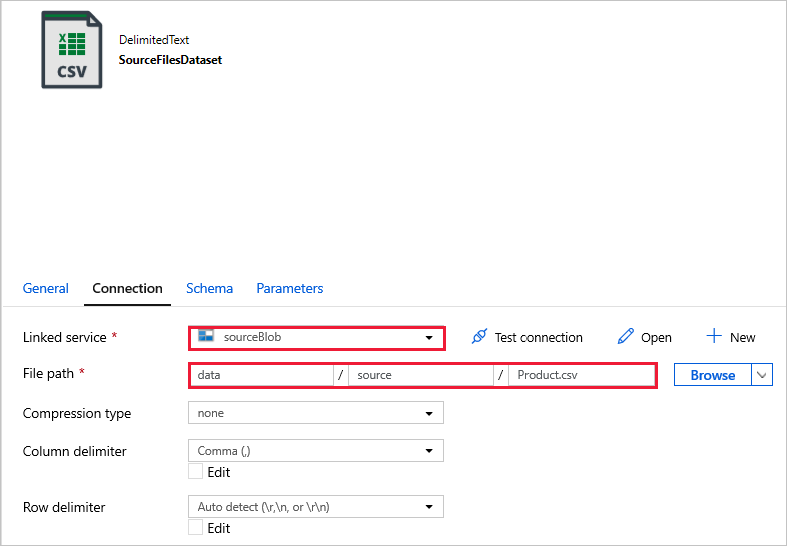
DestinationFilesDataset используется для копирования данных в целевое расположение приемника. Используйте следующие значения.
Linked service (Связанная служба) -
sinkBlob_LS, созданная на предыдущем шаге;File path (Путь к файлу) -
sinkdata/staged_sink.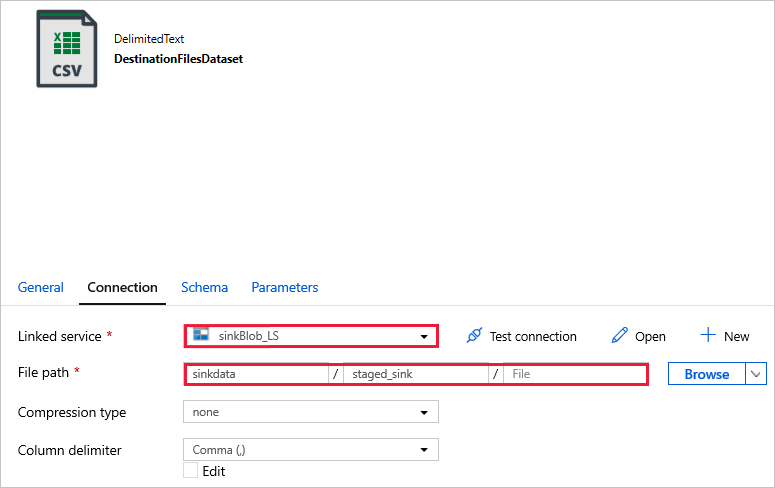
Нажмите Debug (Отладка), чтобы запустить конвейер. Чтобы просмотреть более подробные журналы Spark, можно перейти по ссылке на журналы Databricks.
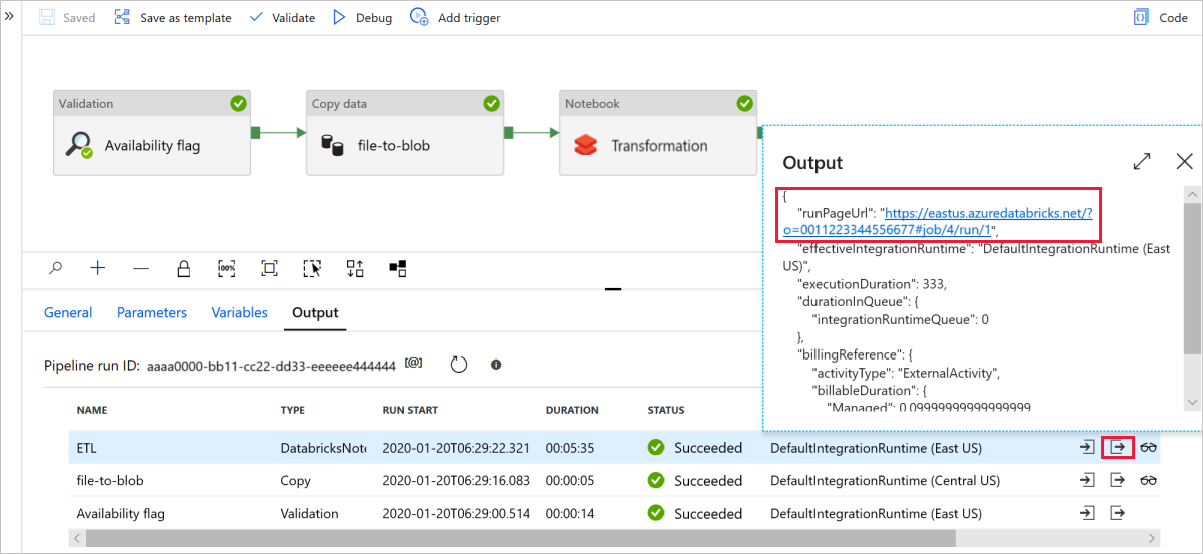
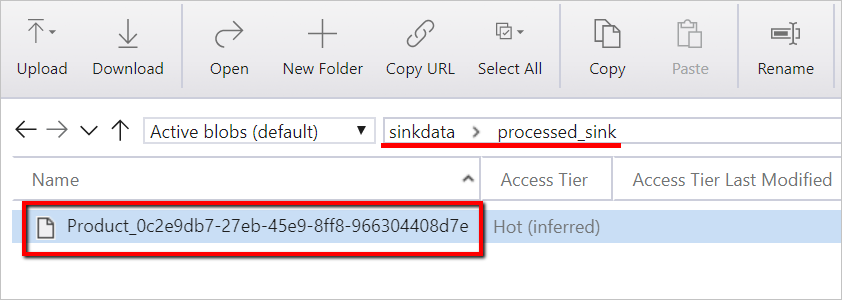
Вы также можете проверить файл данных с помощью Обозревателя службы хранилища Azure.
Примечание.
Для корреляции с запусками конвейера Фабрики данных этот пример добавляет идентификатор запуска конвейера из Фабрики данных в выходную папку. Это помогает отследить файлы, создаваемые при каждом запуске.