Преобразование "Синтаксический анализ" в потоке данных для сопоставления
ОБЛАСТЬ ПРИМЕНЕНИЯ:  Фабрика данных Azure Azure Synapse Analytics
Фабрика данных Azure Azure Synapse Analytics
Совет
Попробуйте использовать фабрику данных в Microsoft Fabric, решение для аналитики с одним интерфейсом для предприятий. Microsoft Fabric охватывает все, от перемещения данных до обработки и анализа данных в режиме реального времени, бизнес-аналитики и отчетности. Узнайте, как бесплатно запустить новую пробную версию !
Потоки данных доступны в конвейерах как Фабрики данных Azure, так и Azure Synapse. Эта статья относится к потокам данных для сопоставления. Если вы не знакомы с преобразованиями, см. вводную статью Преобразование данных с помощью потока данных для сопоставления.
Используйте преобразование "Синтаксический анализ" для анализа текстовых столбцов данных, которые хранятся в виде строк в форме документа. Текущие поддерживаемые типы внедренных документов, которые можно анализировать, представлены JSON, XML и текстами с разделителями.
Настройка
На панели конфигурации анализа преобразования сначала выберите тип данных, содержащихся в столбцах, которые необходимо проанализировать. Также для этого преобразования можно настроить перечисленные ниже параметры конфигурации.

Column
Аналогично производным столбцам и агрегатам, свойство Column — это свойство, в котором можно изменить существующий столбец, выбрав его из раскрывающегося списка. Также можно ввести имя нового столбца. ADF хранит проанализированные исходные данные в этом столбце. В большинстве случаев необходимо определить новый столбец, который анализирует входящее поле строки внедренного документа.
Expression
Используйте построитель выражений, чтобы задать исходные данные для анализа. Задание источника может быть таким же простым, как только выбор исходного столбца с автономными данными, которые вы хотите проанализировать, или создать сложные выражения для анализа.
Примеры выражений
Данные исходной строки:
chrome|steel|plastic- Выражение:
(desc1 as string, desc2 as string, desc3 as string)
- Выражение:
Исходные данные JSON:
{"ts":1409318650332,"userId":"309","sessionId":1879,"page":"NextSong","auth":"Logged In","method":"PUT","status":200,"level":"free","itemInSession":2,"registration":1384448}- Выражение:
(level as string, registration as long)
- Выражение:
Исходные вложенные данные JSON:
{"car" : {"model" : "camaro", "year" : 1989}, "color" : "white", "transmission" : "v8"}- Выражение:
(car as (model as string, year as integer), color as string, transmission as string)
- Выражение:
Исходные данные XML:
<Customers><Customer>122</Customer><CompanyName>Great Lakes Food Market</CompanyName></Customers>- Выражение:
(Customers as (Customer as integer, CompanyName as string))
- Выражение:
Исходный XML-код с данными атрибутов:
<cars><car model="camaro"><year>1989</year></car></cars>- Выражение:
(cars as (car as ({@model} as string, year as integer)))
- Выражение:
Выражения с зарезервированными символами:
{ "best-score": { "section 1": 1234 } }- Приведенное выше выражение не работает, так как символ
best-score-' интерпретируется как операция вычитания. Используйте переменную с нотацией с скобками в таких случаях, чтобы обработчик JSON интерпретировал текст буквально:var bestScore = data["best-score"]; { bestScore : { "section 1": 1234 } }
- Приведенное выше выражение не работает, так как символ
Примечание. Если возникают ошибки, извлекающие атрибуты (в частности, @model) из сложного типа, обходной путь заключается в преобразовании сложного типа в строку, удалите символ @(в частности, replace(toString(your_xml_string_parsed_column_name.cars.car),'@',''), а затем используйте действие преобразования JSON.
Тип выходного столбца
Вот где вы настраиваете целевую схему выходных данных из синтаксического анализа, записанного в один столбец. Самый простой способ задать схему для выходных данных синтаксического анализа — выбрать "Обнаружить тип" в правом верхнем углу построителя выражений. ADF пытается автоматически определить схему из строкового поля, который выполняется синтаксический анализ и задать его для вас в выходном выражении.
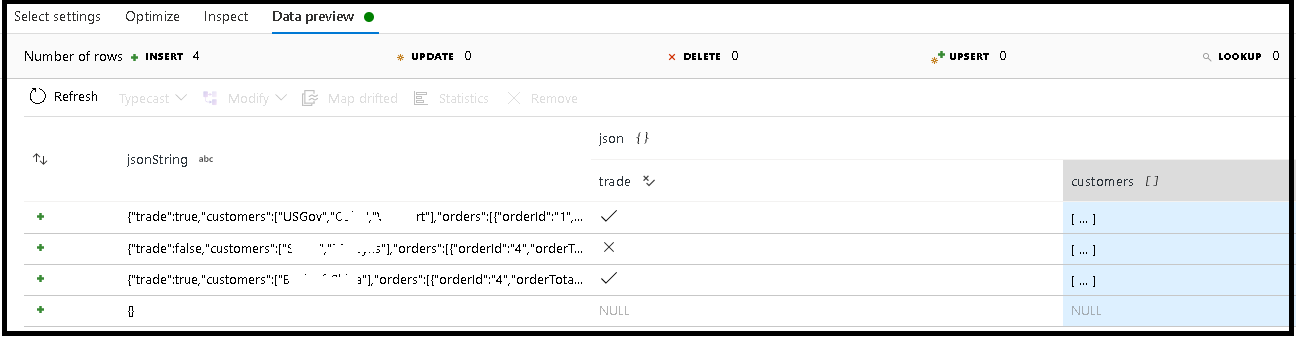
В этом примере мы определили синтаксический анализ входящего поля jsonString, который является обычным текстом, но отформатирован как структура JSON. Мы будем хранить проанализированные результаты в формате JSON в новом столбце с именем json на основе этой схемы:
(trade as boolean, customers as string[])
Чтобы убедиться, что выходные данные сопоставлены правильно, используйте вкладку проверки и предварительный просмотр данных.
Используйте действие "Производный столбец" для извлечения иерархических данных (т. е. your_complex_column_name.car.model в поле выражения).
Примеры
source(output(
name as string,
location as string,
satellites as string[],
goods as (trade as boolean, customers as string[], orders as (orderId as string, orderTotal as double, shipped as (orderItems as (itemName as string, itemQty as string)[]))[])
),
allowSchemaDrift: true,
validateSchema: false,
ignoreNoFilesFound: false,
documentForm: 'documentPerLine') ~> JsonSource
source(output(
movieId as string,
title as string,
genres as string
),
allowSchemaDrift: true,
validateSchema: false,
ignoreNoFilesFound: false) ~> CsvSource
JsonSource derive(jsonString = toString(goods)) ~> StringifyJson
StringifyJson parse(json = jsonString ? (trade as boolean,
customers as string[]),
format: 'json',
documentForm: 'arrayOfDocuments') ~> ParseJson
CsvSource derive(csvString = 'Id|name|year\n\'1\'|\'test1\'|\'1999\'') ~> CsvString
CsvString parse(csv = csvString ? (id as integer,
name as string,
year as string),
format: 'delimited',
columnNamesAsHeader: true,
columnDelimiter: '|',
nullValue: '',
documentForm: 'documentPerLine') ~> ParseCsv
ParseJson select(mapColumn(
jsonString,
json
),
skipDuplicateMapInputs: true,
skipDuplicateMapOutputs: true) ~> KeepStringAndParsedJson
ParseCsv select(mapColumn(
csvString,
csv
),
skipDuplicateMapInputs: true,
skipDuplicateMapOutputs: true) ~> KeepStringAndParsedCsv
Скрипт потока данных
Синтаксис
Примеры
parse(json = jsonString ? (trade as boolean,
customers as string[]),
format: 'json|XML|delimited',
documentForm: 'singleDocument') ~> ParseJson
parse(csv = csvString ? (id as integer,
name as string,
year as string),
format: 'delimited',
columnNamesAsHeader: true,
columnDelimiter: '|',
nullValue: '',
documentForm: 'documentPerLine') ~> ParseCsv
Связанный контент
- Используйте преобразование в плоскую структуру, чтобы свести строки в столбцы.
- Используйте преобразование производного столбца для изменения строк.