Преобразование утверждения в потоке данных для сопоставления
ОБЛАСТЬ ПРИМЕНЕНИЯ:  Фабрика данных Azure Azure Synapse Analytics
Фабрика данных Azure Azure Synapse Analytics
Совет
Попробуйте использовать фабрику данных в Microsoft Fabric, решение для аналитики с одним интерфейсом для предприятий. Microsoft Fabric охватывает все, от перемещения данных до обработки и анализа данных в режиме реального времени, бизнес-аналитики и отчетности. Узнайте, как бесплатно запустить новую пробную версию !
Потоки данных доступны в конвейерах как Фабрики данных Azure, так и Azure Synapse. Эта статья относится к потокам данных для сопоставления. Если вы не знакомы с преобразованиями, см. вводную статью Преобразование данных с помощью потока данных для сопоставления.
Преобразование Assert позволяет создавать пользовательские правила внутри потоков данных сопоставления для проверки качества данных и проверки данных. Вы можете создавать правила, определяющие, соответствуют ли значения ожидаемому домену значений. Кроме того, можно создать правила, которые проверяют уникальность строк. Преобразование Assert помогает определить, соответствует ли каждая строка в данных набору критериев. Преобразование Assert также позволяет задать пользовательские сообщения об ошибках, если правила проверки данных не выполнены.
Настройка
На панели конфигурации преобразования утверждений выберите тип утверждения, укажите уникальное имя утверждения, необязательное описание и определите выражение и необязательный фильтр. Панель предварительного просмотра данных указывает, какие строки завершили сбой утверждений. Кроме того, можно протестировать каждый тег строки в нисходящем направлении, используя isError() и hasError() для строк, которые не прошли утверждение.
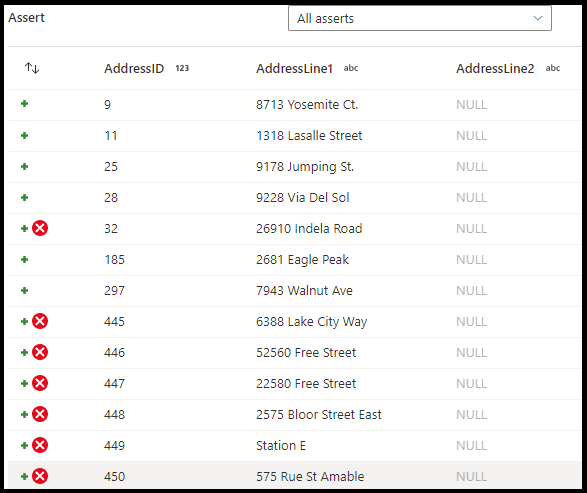
Тип утверждения
- Ожидается значение true: результат выражения должен быть логическим значением true. Используйте этот параметр для проверки диапазонов значений домена в данных.
- Ожидается уникальный экземпляр: задайте столбец или выражение в качестве правила уникальности данных. Используйте этот параметр для тега повторяющихся строк.
- Ожидается: этот параметр доступен только при выборе второго входящего потока. Существует просматривает оба потока и определяет, существуют ли строки в обоих потоках на основе указанных столбцов или выражений. Чтобы добавить второй поток для операции EXISTS, выберите
Additional streams.
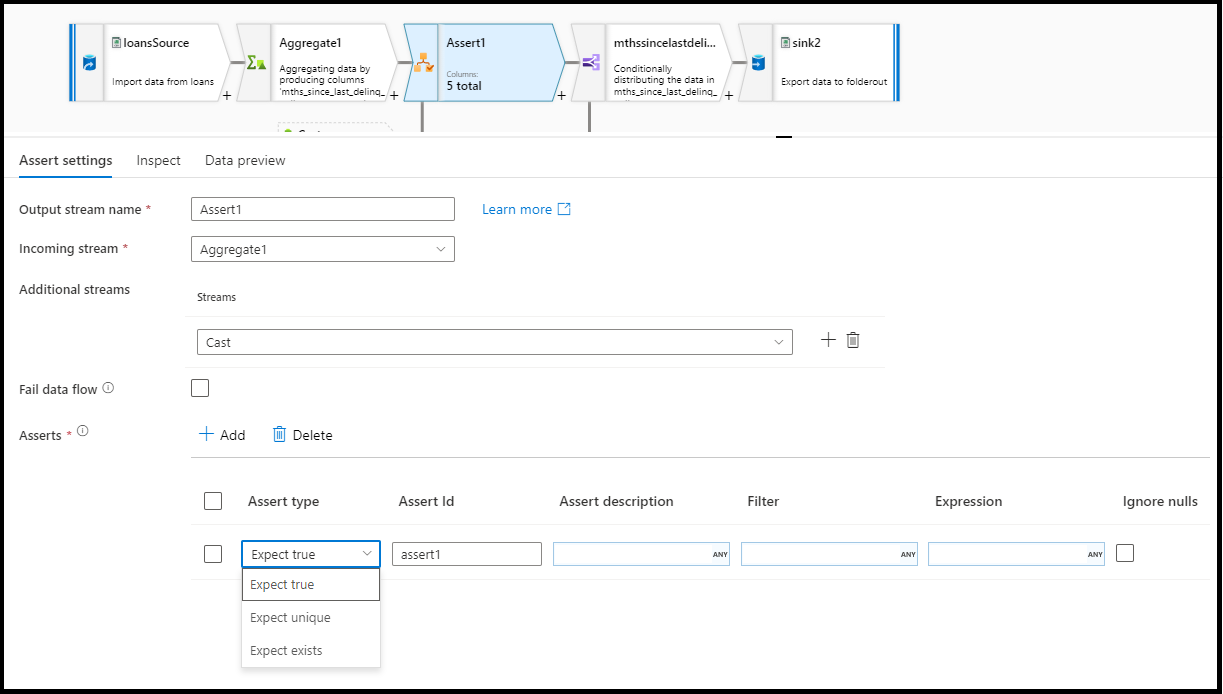
Сбой потока данных
Выберите fail data flow, если вы хотите, чтобы действие потока данных завершилось сбоем сразу же после нарушения правила утверждения.
ИД утверждения
Идентификатор assert — это свойство, в котором вы вводите (строковое) имя для утверждения. Вы можете использовать идентификатор позже в потоке данных с помощью hasError() или вывода кода сбоя утверждения. ИД утверждений должны быть уникальными в пределах каждого потока данных.
Описание утверждения
Введите строковое описание для утверждения. Здесь также можно использовать выражения и значения столбцов контекста строк.
Фильтр
Фильтр — это необязательное свойство, с помощью которого можно ограничить утверждение только подмножеством строк по значению выражения.
Expression
Введите вычисляемое выражение для каждого утверждения. Для каждого преобразования утверждения можно использовать несколько утверждений. Для каждого типа утверждения требуется выражение, которое ADF необходимо оценить, чтобы проверить, передается ли утверждение.
Игнорировать значения NULL
По умолчанию преобразование утверждения включает NULLs в вычислении утверждений строк. С помощью этого свойства можно пропускать значения NULL.
Направление сбоев утверждения строки
При сбое утверждения можно при необходимости направить эти строки с ошибками в файл в Azure с помощью вкладки "Ошибки" в преобразовании приемника. Кроме того, для преобразования приемника можно не выводить строки с ошибками утверждения, игнорируя строки ошибок.
Примеры
source(output(
AddressID as integer,
AddressLine1 as string,
AddressLine2 as string,
City as string,
StateProvince as string,
CountryRegion as string,
PostalCode as string,
rowguid as string,
ModifiedDate as timestamp
),
allowSchemaDrift: true,
validateSchema: false,
isolationLevel: 'READ_UNCOMMITTED',
format: 'table') ~> source1
source(output(
CustomerID as integer,
AddressID as integer,
AddressType as string,
rowguid as string,
ModifiedDate as timestamp
),
allowSchemaDrift: true,
validateSchema: false,
isolationLevel: 'READ_UNCOMMITTED',
format: 'table') ~> source2
source1, source2 assert(expectExists(AddressLine1 == AddressLine1, false, 'nonUS', true(), 'only valid for U.S. addresses')) ~> Assert1
Скрипт потока данных
Примеры
source1, source2 assert(expectTrue(CountryRegion == 'United States', false, 'nonUS', null, 'only valid for U.S. addresses'),
expectExists(source1@AddressID == source2@AddressID, false, 'assertExist', StateProvince == 'Washington', toString(source1@AddressID) + ' already exists in Washington'),
expectUnique(source1@AddressID, false, 'uniqueness', null, toString(source1@AddressID) + ' is not unique')) ~> Assert1
Связанный контент
- Используйте Преобразование выбора для выбора и проверки столбцов.
- Используйте Преобразование производного столбца для преобразования значений столбцов.