Преобразование "Статистическая обработка" в потоке данных для сопоставления
ОБЛАСТЬ ПРИМЕНЕНИЯ: Фабрика данных Azure Azure Synapse Analytics
Фабрика данных Azure Azure Synapse Analytics
Совет
Попробуйте использовать фабрику данных в Microsoft Fabric, решение для аналитики с одним интерфейсом для предприятий. Microsoft Fabric охватывает все, от перемещения данных до обработки и анализа данных в режиме реального времени, бизнес-аналитики и отчетности. Узнайте, как бесплатно запустить новую пробную версию !
Потоки данных доступны в конвейерах как Фабрики данных Azure, так и Azure Synapse. Эта статья относится к потокам данных для сопоставления. Если вы не знакомы с преобразованиями, см. вводную статью Преобразование данных с помощью потока данных для сопоставления.
Преобразование "Статистическая обработка" — это средство выполнения статистических вычислений над столбцами в потоках данных. С помощью построителя выражений можно определять различные виды статистических выражений, например SUM, MIN, MAX и COUNT, с группировкой по существующим или вычисляемым столбцам.
Группировать по
Выберите существующий столбец или создайте вычисляемый для использования в предложении GROUP BY. Существующий столбец можно выбрать из раскрывающегося списка. Чтобы создать вычисляемый столбец, наведите указатель мыши на предложение GROUP BY и щелкните пункт Вычисляемый столбец. Откроется построитель выражений потока данных. Создав вычисляемый столбец, введите имя выходного столбца в поле Имя. Если нужно добавить еще одно предложение GROUP BY, наведите указатель мыши на уже имеющееся предложение и щелкните значок "плюс".
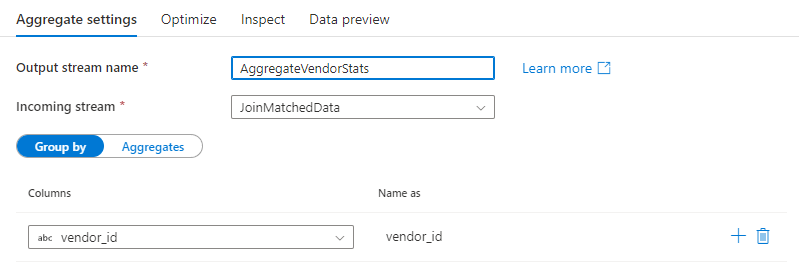
В преобразовании "Статистическая обработка" предложение GROUP BY не является обязательным.
Статистические столбцы
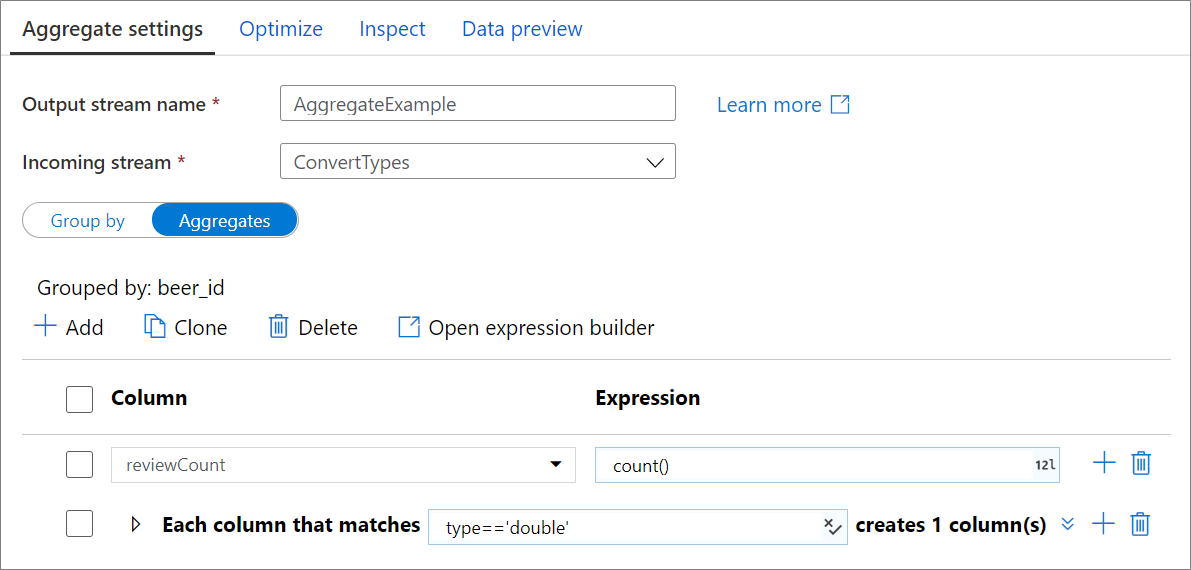
Для построения статистических выражений перейдите на вкладку Статистические выражения. Результат статистических вычислений можно записывать в существующий столбец или в новое именованное поле. Статистическое выражение указывается в текстовом поле справа от селектора имени столбца. Чтобы изменить выражение, щелкните в этом текстовом поле и откройте построитель выражений. Чтобы добавить дополнительные статистические столбцы, нажмите кнопку Добавить над списком столбцов или значок "плюс" рядом с существующим статистическим столбцом. Выберите Добавить столбец или Добавить шаблон столбца. Каждое статистическое выражение должно содержать по крайней мере одну агрегатную функцию.
Примечание.
В режиме отладки построитель выражений не поддерживает предварительный просмотр данных с агрегатными функциями. Для предварительного просмотра результатов преобразования "Статистическая обработка" закройте построитель выражений и просмотрите данные на вкладке "Просмотр данных".
Шаблоны столбцов
Для применения одного и того же статистического агрегата к набору столбцов можно использовать шаблоны столбцов. Это полезно, если нужно сохранить на постоянной основе много столбцов из входной схемы, так как по умолчанию они удаляются. Чтобы входные столбцы сохранялись в ходе статистической обработки, используйте эвристики, например first().
Повторное соединение строк и столбцов
Преобразование "Статистическая обработка" похоже на статистические SQL-запросы SELECT. Столбцы, не входящие в предложение GROUP BY или агрегатные функции, не будут передаваться на выход преобразования статистической обработки. Если вы хотите включить в результаты преобразования другие столбцы, действуйте одним из следующих способов.
- Используйте для включения нужного дополнительного столбца агрегатную функцию, например
last()илиfirst(). - Повторно присоедините столбцы к выходному потоку, используя шаблон самосоединения.
Удаление дублирующихся строк
Часто преобразование статистической обработки используется для удаления или выявления повторяющихся записей в исходных данных. Это называется дедупликацией. Чтобы определить, какую из дублирующихся строк следует сохранить, используйте эвристику на свой выбор с набором ключей в предложении GROUP BY. Распространенные эвристики — first(), last()max() и min(). Чтобы применить правило к каждому столбцу, за исключением столбцов в предложении GROUP BY, используйте шаблоны столбцов.
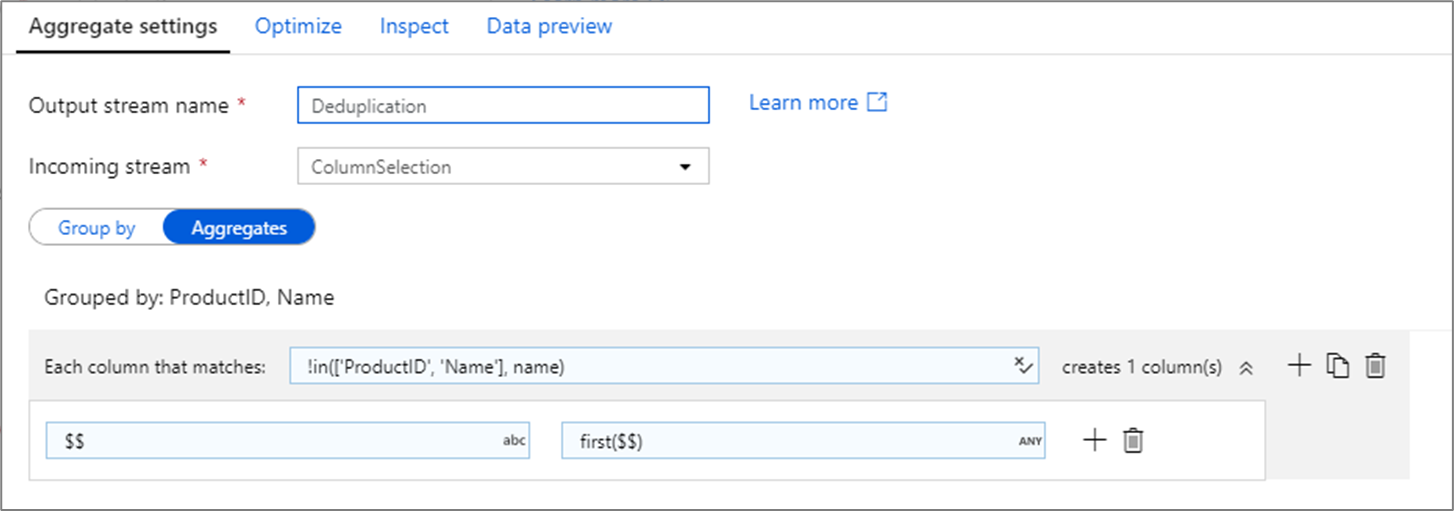
В приведенном выше примере группировка производится по столбцам ProductID и Name. Если в двух строках значения этих двух столбцов одинаковы, строки считаются дубликатами. В этом преобразовании статистической обработки значения, соответствующие первой строке, будут сохранены, а все остальные будут удалены. С помощью синтаксиса шаблона столбцов задается правило, согласно которому все столбцы с именами, отличными от ProductID и Name, сопоставляются с существующим именем столбца и получают значения из соответствующих столбцов первых совпадающих строк. Выходная схема такая же, как и входная.
В сценариях проверки данных функцию count() можно использовать для подсчета дубликатов.
Скрипт потока данных
Синтаксис
<incomingStream>
aggregate(
groupBy(
<groupByColumnName> = <groupByExpression1>,
<groupByExpression2>
),
<aggregateColumn1> = <aggregateExpression1>,
<aggregateColumn2> = <aggregateExpression2>,
each(
match(matchExpression),
<metadataColumn1> = <metadataExpression1>,
<metadataColumn2> = <metadataExpression2>
)
) ~> <aggregateTransformationName>
Пример
В приведенном ниже примере строки из входящего потока MoviesYear группируются по столбцу year. Преобразование создает статистический столбец avgrating, результирующее значение которого — среднее значение столбца Rating. Этому преобразованию статистической обработки присвоено имя AvgComedyRatingsByYear.
В пользовательском интерфейсе это преобразование выглядит следующим образом:
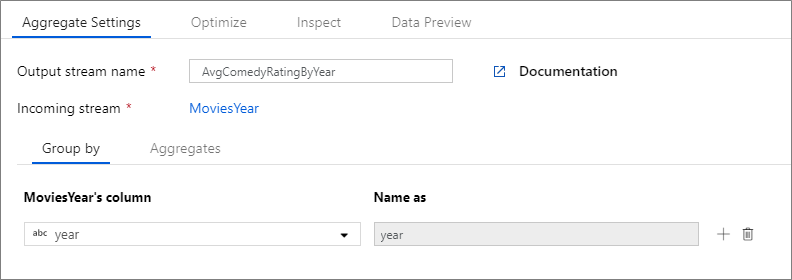
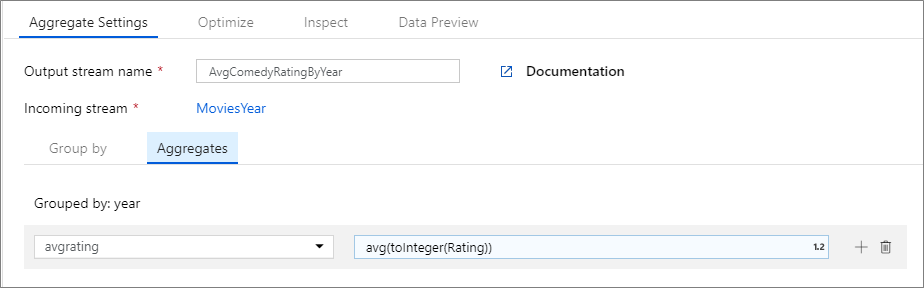
Скрипт потока данных для этого преобразования представлен в следующем фрагменте кода:
MoviesYear aggregate(
groupBy(year),
avgrating = avg(toInteger(Rating))
) ~> AvgComedyRatingByYear
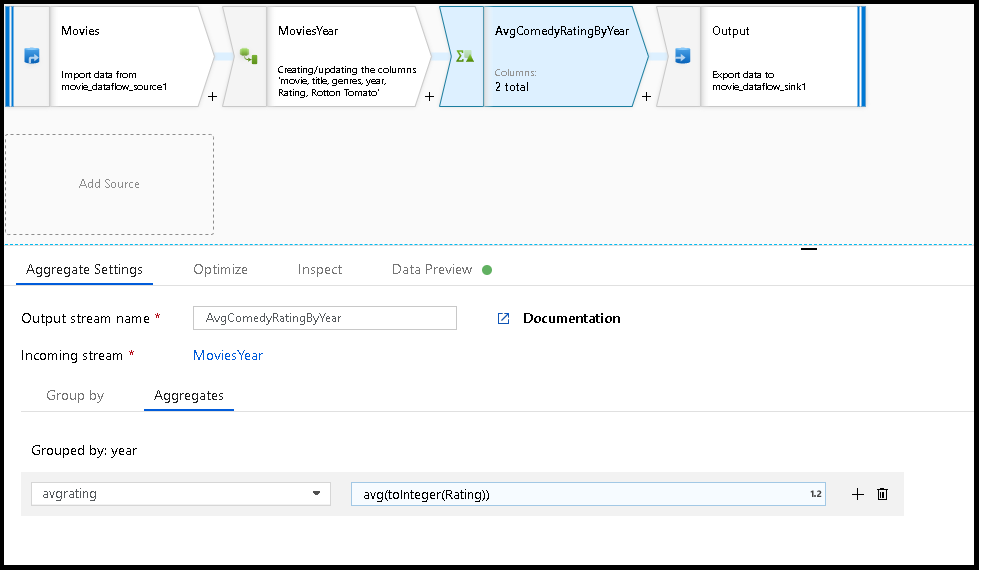
Здесь MoviesYear — производный столбец, определяющий столбцы year и title, AvgComedyRatingByYear — преобразование "Статистическая обработка" для определения среднего рейтинга комедий с группировкой по годам, а avgrating — имя создаваемого столбца для хранения результата статистических вычислений.
MoviesYear aggregate(groupBy(year),
avgrating = avg(toInteger(Rating))) ~> AvgComedyRatingByYear
Связанный контент
- Определение оконных статистических агрегатов с помощью преобразования окна.