Задача Azure DevOps для Azure Data Explorer
Azure DevOps Services включает инструменты для совместной работы в области разработки, в том числе высокопроизводительные конвейеры, бесплатные частные репозитории Git, настраиваемые канбан-доски, а также различные автоматизированные и непрерывно работающие инструменты тестирования. Azure Pipelines — это функционал Azure DevOps для управления непрерывной поставкой и интеграцией для развертывания кода с помощью высокопроизводительных конвейеров, работающих с любым языком, платформой и облаком. Azure Data Explorer — Pipeline Tools — это задача Azure Pipelines, позволяющая создавать конвейеры выпуска и развертывать изменения базы данных в базах данных Azure Data Explorer. Она доступна бесплатно в Visual Studio Marketplace. Это расширение включает следующие основные задачи:
Azure Data Explorer Command для запуска команд администрирования в кластере Azure Data Explorer
Azure Data Explorer Query — выполнение запросов в кластеру Azure Data Explorer и анализ результатов
Azure Data Explorer Query Server Gate — задача без агента для определения выпусков шлюзов в зависимости от результатов запроса
В этом документе описывается простой пример использования задачи Azure Data Explorer — Pipeline Tools для развертывания изменений схемы в базе данных. Полное описание конвейеров непрерывной поставки и непрерывной интеграции см. в документации по Azure DevOps.
Необходимые компоненты
- Подписка Azure. Создайте бесплатную учетную запись Azure.
- Кластер и база данных Azure Data Explorer. Создайте кластер и базу данных.
- Настройка кластера Azure Data Explorer:
- Создайте приложение Microsoft Entra, подготовив приложение Microsoft Entra.
- Предоставьте доступ к приложению Microsoft Entra в базе данных Azure Data Explorer, управляя разрешениями базы данных Azure Data Explorer.
- Настройка Azure DevOps:
- Установка расширения:
Если вы являетесь владельцем экземпляра Azure DevOps, установите расширение из Marketplace, в противном случае обратитесь к владельцу экземпляра Azure DevOps и попросите его установить.

Подготовка содержимого к выпуску
Для выполнения команд администратора в кластере в задаче можно использовать следующие методы:
Использование шаблона поиска для получения нескольких командных файлов из локальной папки агента (источники сборки или артефакты выпуска)

Встроенные команды записи
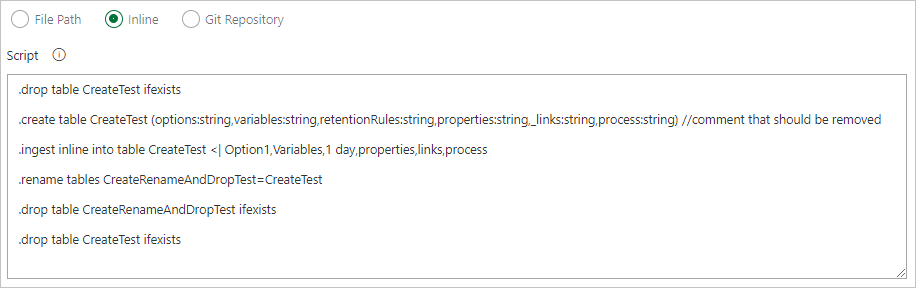
Укажите путь к файлу для получения файлов команд непосредственно из системы управления версиями Git (рекомендуется)
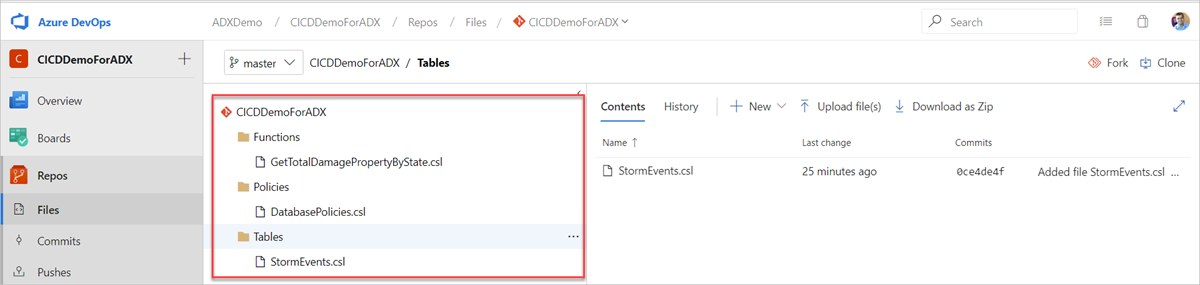
Создайте в репозитории Git следующие образцы папок (Functions, Policies, Tables). Скопируйте файлы из репозитория примеров в соответствующие папки и зафиксируйте изменения. Примеры файлов предоставляются для выполнения следующего рабочего процесса.
Совет
При создании собственного рабочего процесса рекомендуется сделать код идемпотентным. Например, используйте
.create-merge tableвместо.create tableи функцию.create-or-alterвместо функции.create.
Создание конвейера выпуска
Войдите в организацию Azure DevOps.
Откройте Конвейеры>Выпуски в меню слева и выберите Создать конвейер.
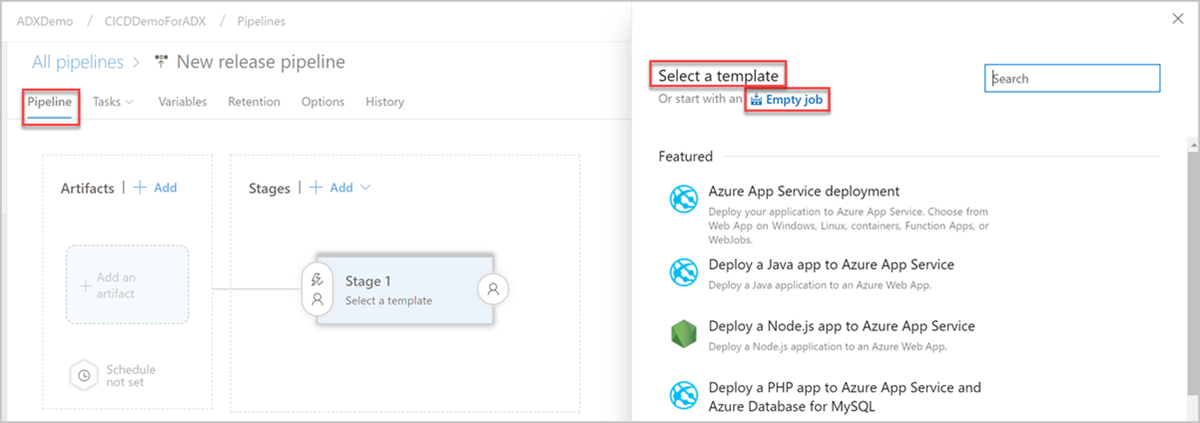
Откроется окно Новый конвейер выпуска. На вкладке Конвейеры в области Выбор шаблона выберите Пустое задание.
Нажмите кнопку Этап. В области Этап добавьте Имя этапа. Щелкните Сохранить, чтобы сохранить конвейер.
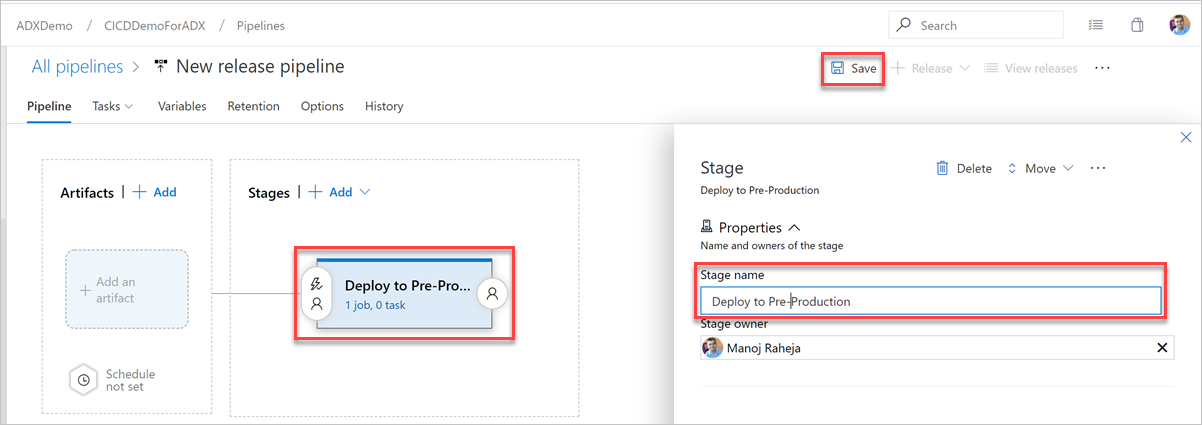
Нажмите кнопку Добавить артефакт. В области "Добавление артефакта" выберите репозиторий, в котором существует код, заполните соответствующие сведения и нажмите кнопку "Добавить". Щелкните Сохранить, чтобы сохранить конвейер.
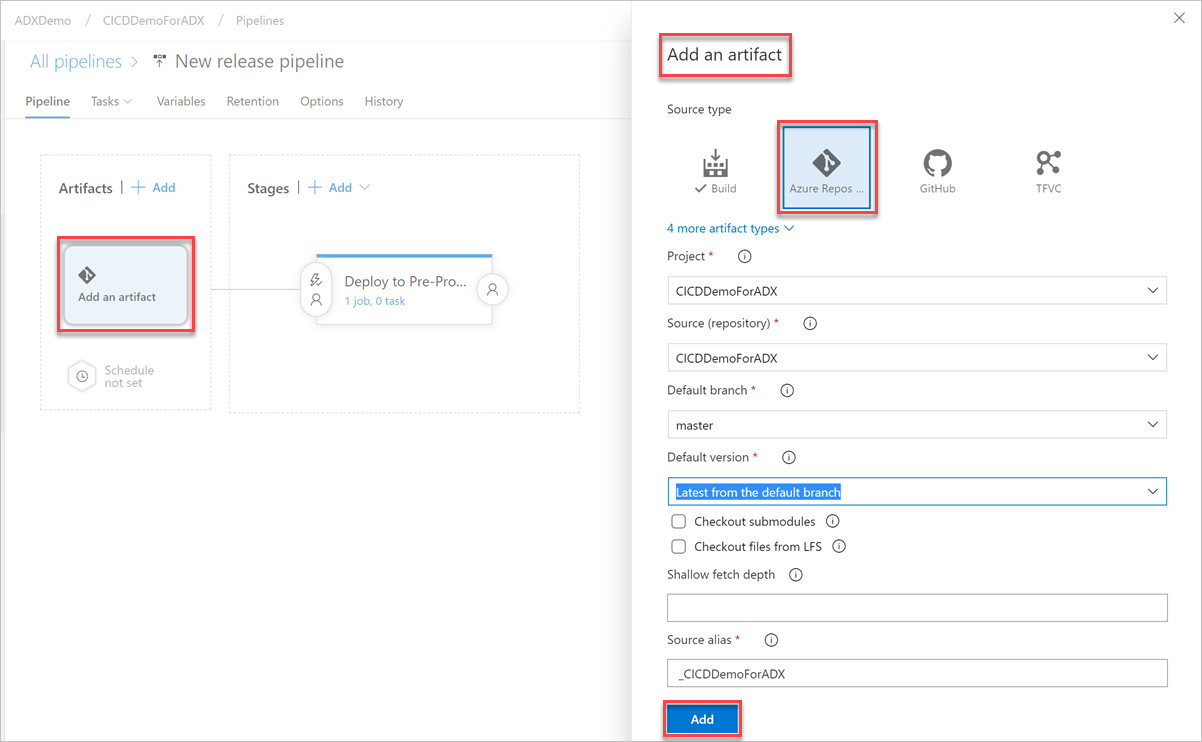
На вкладке "Переменные" выберите + Добавить , чтобы создать переменную для URL-адреса конечной точки, которая используется в задаче. Запишите Имя и Значение конечной точки. Щелкните Сохранить, чтобы сохранить конвейер.
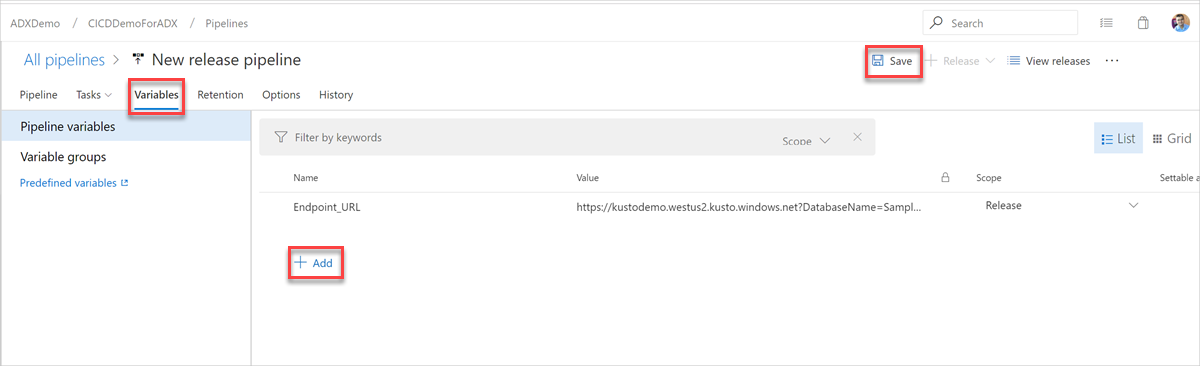
Чтобы найти URL-адрес конечной точки, перейдите на страницу обзора кластера Azure Data Explorer в портал Azure и скопируйте URI кластера. Создайте универсальный код ресурса (URI) переменной в следующем формате
https://<ClusterURI>?DatabaseName=<DBName>. Например: https://kustodocs.westus.kusto.windows.net?DatabaseName=SampleDB
Создание задачи развертывания папок
На вкладке "Конвейер" выберите 1 задание, 0, чтобы добавить задачи.
Повторите следующие шаги, чтобы создать задачи команд для развертывания файлов из папок Tables, Functions и Policies:
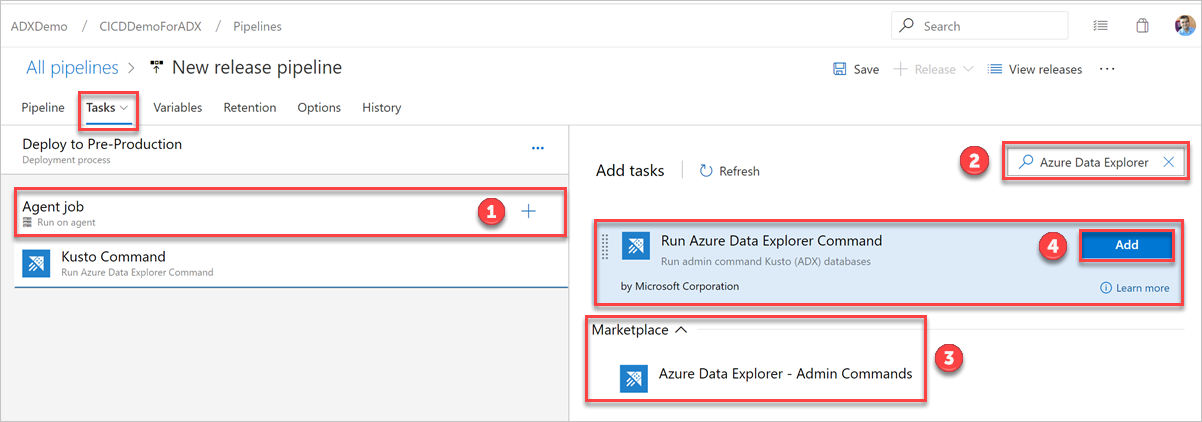
На вкладке Задачи выберите + от Задание агента и выполните поиск Azure Data Explorer.
В разделе Запуск команды Azure Data Explorer выберите Добавить.
Выберите Команда Kusto и обновите задачу, указав следующие сведения:
Отображаемое имя: имя задачи. Например,
Deploy <FOLDER>где<FOLDER>находится имя папки для создаваемой задачи развертывания.Путь к файлу: для каждой папки укажите путь, например
*/<FOLDER>/*.csl, где<FOLDER>— это соответствующая папка для задачи.URL-адрес конечной точки: укажите переменную
EndPoint URL, созданную на предыдущем шаге.Использовать конечную точку службы: выберите этот параметр.
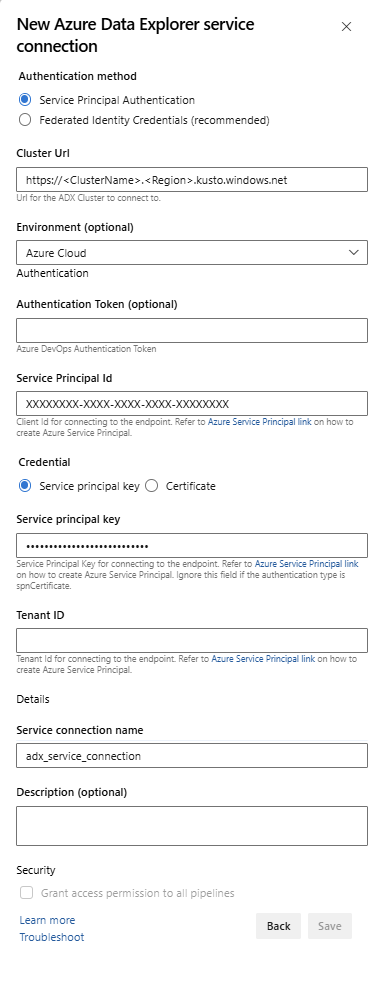
Конечная точка службы: выберите существующую конечную точку службы или создайте новую (+ Создать), указав следующие сведения в окне Добавление подключения к службе Azure Data Explorer:
Параметр Предлагаемое значение метод проверки подлинности Настройте учетные данные федеративного удостоверения (FIC) (рекомендуется) или выберите проверку подлинности субъекта-службы (SPA). Имя подключения Введите имя для обозначения этой конечной точки службы URL-адрес кластера Значение можно найти в разделе обзорной информации о Azure Data Explorer Cluster на портале Azure Идентификатор субъекта-службы Введите идентификатор приложения Microsoft Entra (созданный в качестве предварительных требований) Ключ приложения субъекта-службы Введите ключ приложения Microsoft Entra (созданный в качестве предварительных требований) Идентификатор клиента Microsoft Entra Введите клиент Microsoft Entra (например, microsoft.com или contoso.com)
Установите флажок Разрешить всем конвейерам использовать это подключение, а затем нажмите кнопку ОК.
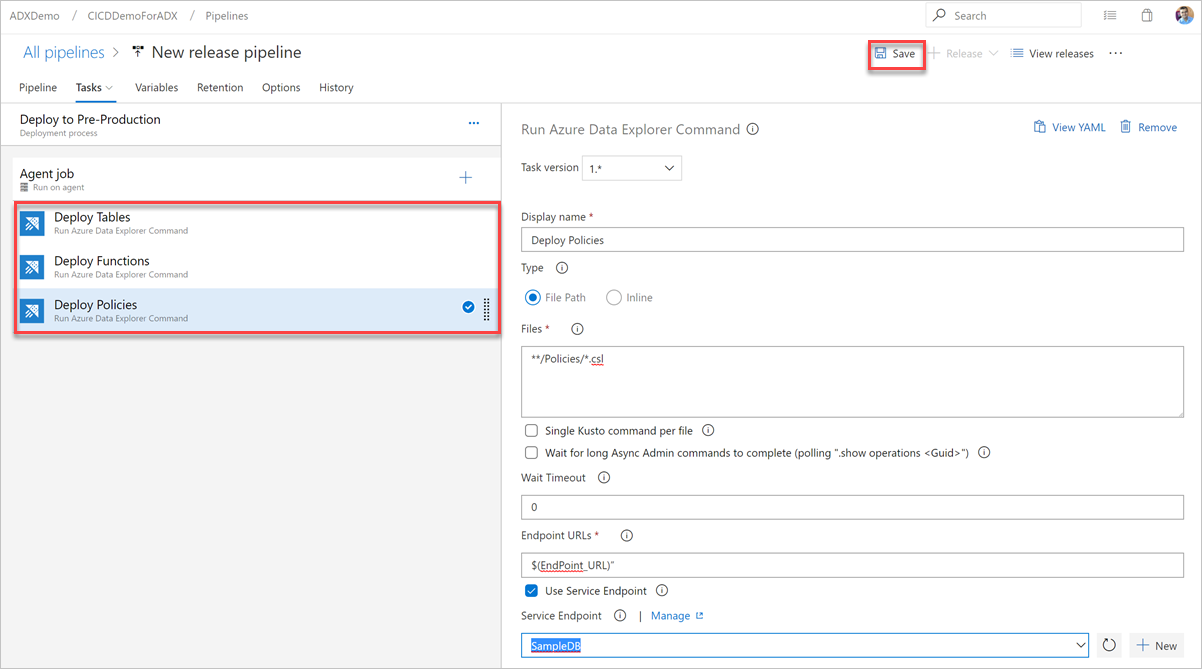
Выберите Сохранить, а затем на вкладке Задачи убедитесь в наличии трех задач: Развертывание таблиц, Развертывание функций и Развертывание политик.
Создание задачи запроса
При необходимости создайте задачу для выполнения запроса к кластеру. Выполнение запросов в конвейере сборки или выпуска можно использовать для проверки набора данных и успешного выполнения или сбоя на основе результатов запроса. Критерии успешного выполнения задач могут быть основаны на пороговом значении счетчика строк или отдельном значении в зависимости от того, что возвращается в ответ на запрос.
На вкладке Задачи выберите + от Задание агента и выполните поиск Azure Data Explorer.
В разделе Запуск запроса Azure Data Explorer выберите Добавить.
Выберите Команда Kusto и обновите задачу, указав следующие сведения:
- Отображаемое имя: имя задачи. Например, Запрос кластера.
- Тип: выберите Встроенный.
- Запрос: введите запрос, который необходимо выполнить.
- URL-адрес конечной точки: укажите переменную
EndPoint URL, созданную ранее. - Использовать конечную точку службы: выберите этот параметр.
- Конечная точка службы: выберите конечную точку службы.
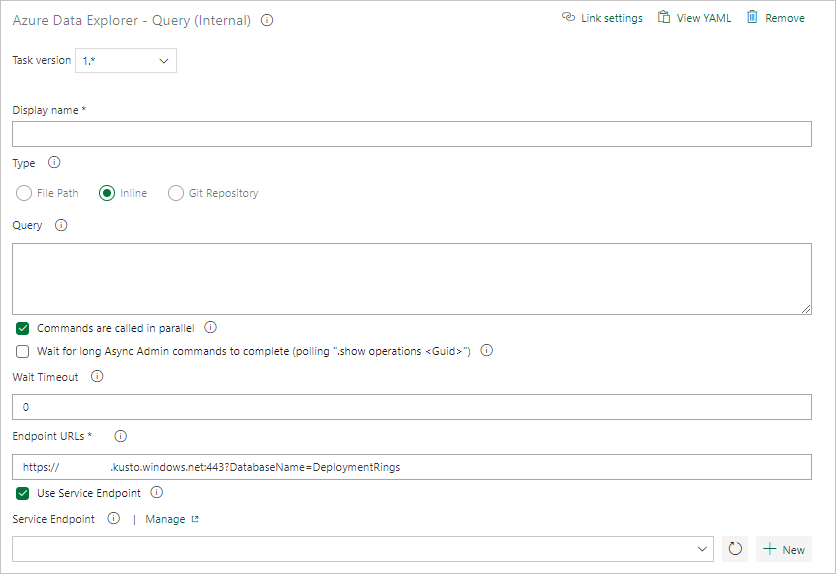
В разделе «Результаты задачи» выберите условия успешного выполнения задачи на основе результатов запроса следующим образом:
Если запрос возвращает строки, выберите Количество строк и укажите нужные критерии.
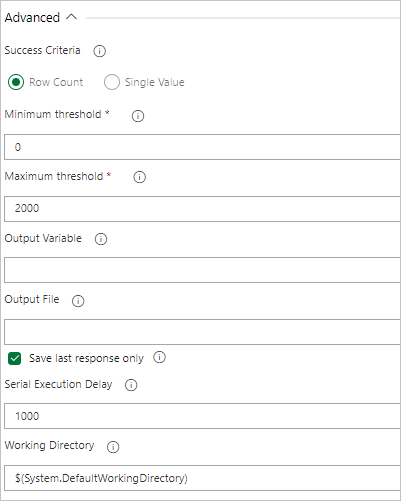
Если запрос возвращает значение, выберите Единственное значение и укажите ожидаемый результат.
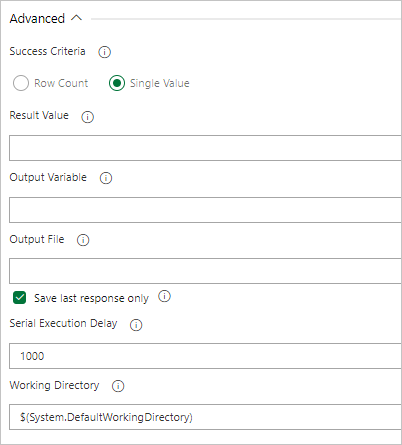
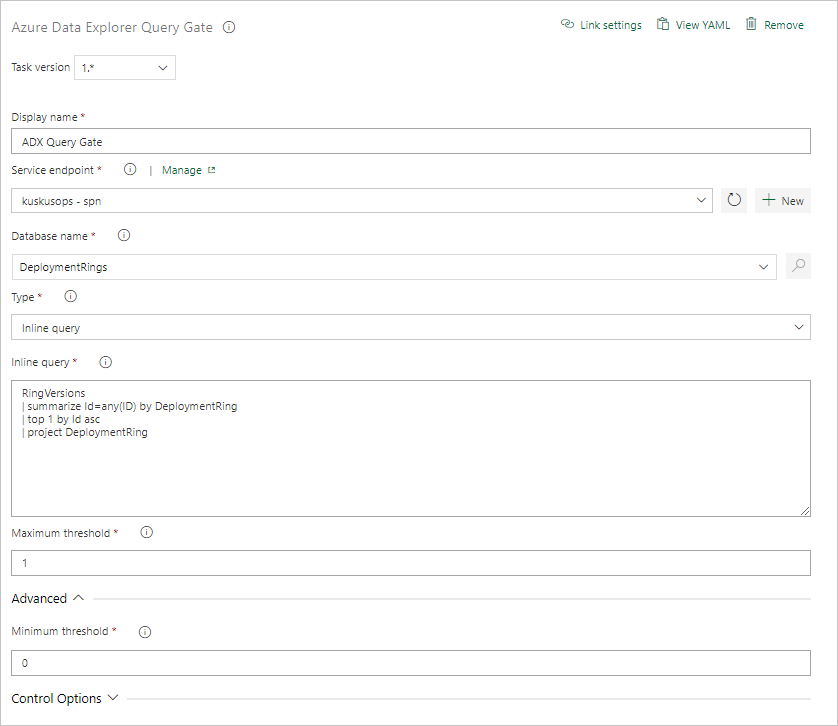
Создание задачи для шлюза сервера запросов
При необходимости создайте задачу для выполнения запроса к кластеру и воротите ход выполнения выпуска, ожидающий число строк результатов запроса. Задача шлюза запросов сервера — это безагентное задание, означающее, что запрос выполняется непосредственно на Azure DevOps Server.
На вкладке Задачи выберите + от Задание без агента и выполните поиск Azure Data Explorer.
В разделе Запуск шлюза сервера запросов Azure Data Explorer выберите Добавить.
Выберите Шлюз сервера запросов Kusto, а затем выберите Тест шлюза сервера.
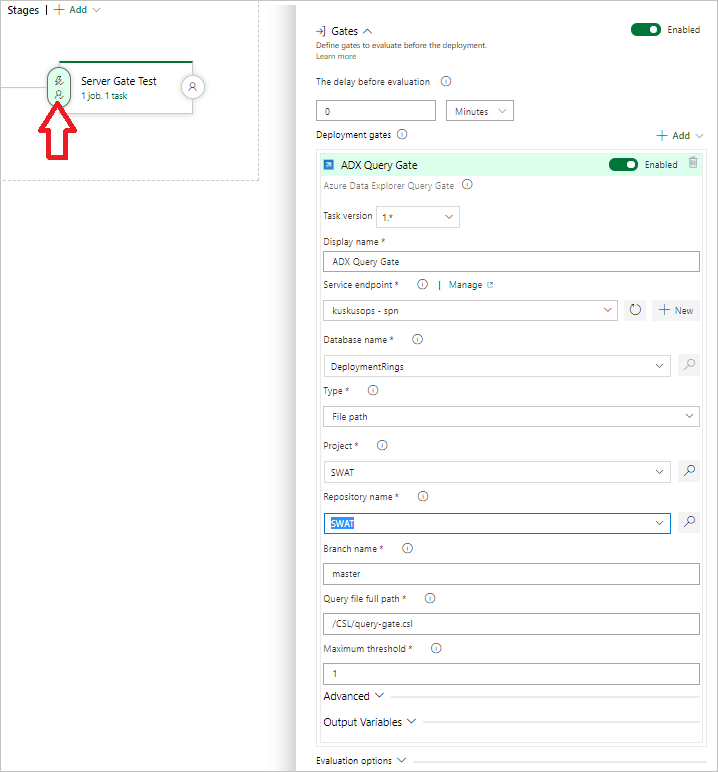
Настройте задачу, указав следующие сведения:
- Отображаемое имя: имя шлюза.
- Конечная точка службы: выберите конечную точку службы.
- Имя базы данных: укажите имя базы данных.
- Тип: выберите Встроенный запрос.
- Запрос: введите запрос, который необходимо выполнить.
- Максимальное пороговое значение: укажите максимальное число строк для критериев успешного выполнения запроса.
Примечание.
При запуске выпуска вы должны увидеть результаты, аналогичные приведенным ниже.
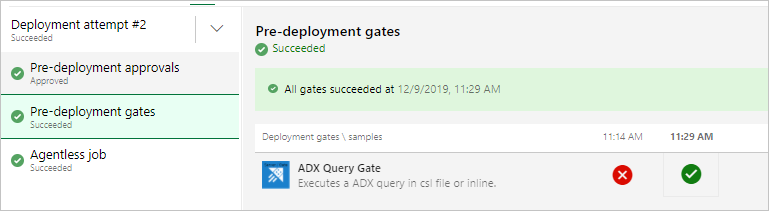
Запуск выпуска
Чтобы создать выпуск, выберите + Выпуск>Создать выпуск.
На вкладке Журналы убедитесь в успешности выполнения развертывания.
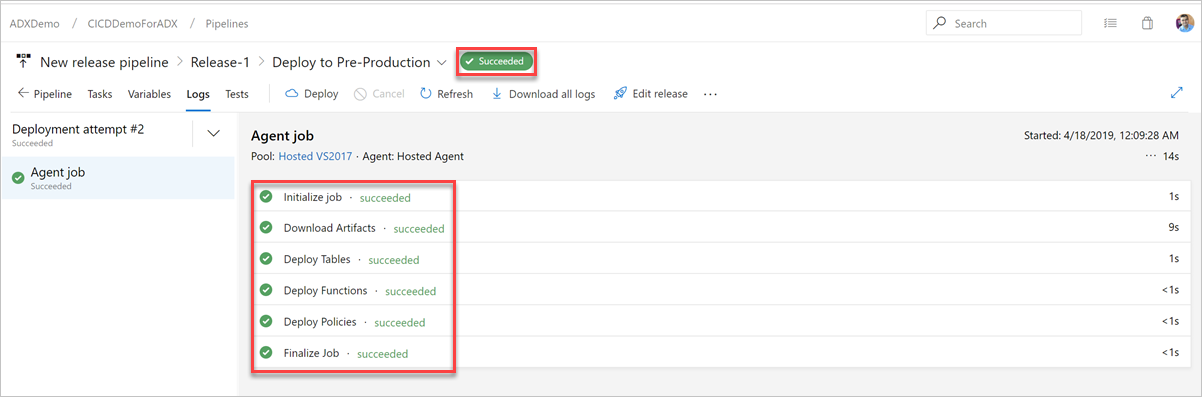
Теперь будет завершено создание конвейера выпуска для предварительного развертывания.
Поддержка бессерверной проверки подлинности для задач DevOps Azure Data Explorer
Расширение поддерживает бессерверную проверку подлинности для кластеров Azure Data Explorer. Бессерверная проверка подлинности позволяет выполнять проверку подлинности в кластерах Azure Data Explorer без использования ключа и более безопасно и проще управлять, чем с помощью ключа.
Использование проверки подлинности федеративных удостоверений (FIC) в подключении службы Azure Data Explorer
В экземпляре DevOps перейдите к подключениям >службы "Параметры>проекта" для нового подключения>к службе Azure Data Explorer.
Выберите федеративные учетные данные удостоверения и введите URL-адрес кластера, идентификатор субъекта-службы, идентификатор клиента, имя подключения к службе и нажмите кнопку "Сохранить".
В портал Azure откройте приложение Microsoft Entra для указанного субъекта-службы.
В разделе "Сертификаты и секреты" выберите федеративные учетные данные.
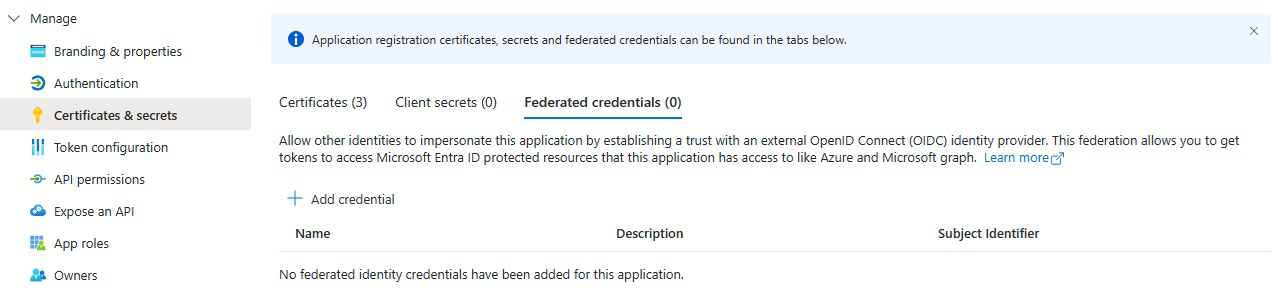
Выберите "Добавить учетные данные", а затем для сценария федеративных учетных данных выберите "Другой издатель" и заполните параметры, используя следующие сведения:
Издатель:
<https://vstoken.dev.azure.com/{System.CollectionId}>где{System.CollectionId}находится идентификатор коллекции вашей организации Azure DevOps. Идентификатор коллекции можно найти следующим образом:- В классическом конвейере выпуска Azure DevOps выберите задание Initialize. Идентификатор коллекции отображается в журналах.
Идентификатор субъекта:
<sc://{DevOps_Org_name}/{Project_Name}/{Service_Connection_Name}>где{DevOps_Org_name}находится имя организации Azure DevOps,{Project_Name}имя проекта и{Service_Connection_Name}имя подключения службы, созданное ранее.Примечание.
Если в имени подключения службы есть пробел, его можно использовать с пробелом в поле. Например:
sc://MyOrg/MyProject/My Service Connection.Имя: введите имя для учетных данных.
Выберите Добавить.
Использование федеративных учетных данных удостоверения или управляемого удостоверения в подключении службы Azure Resource Manager (ARM)
В экземпляре DevOps перейдите к подключениям>службы "Параметры>проекта" для нового подключения>к службе Azure Resource Manager.
В разделе "Проверка подлинности" выберите федерацию удостоверений рабочей нагрузки (автоматически). Кроме того, можно использовать параметр федерации удостоверений рабочей нагрузки вручную (вручную), чтобы указать сведения о федерации удостоверений рабочей нагрузки или использовать параметр "Управляемое удостоверение ". Дополнительные сведения о настройке управляемого удостоверения с помощью службы "Управление ресурсами Azure" см. в статье "Подключения службы Azure Resource Manager (ARM).
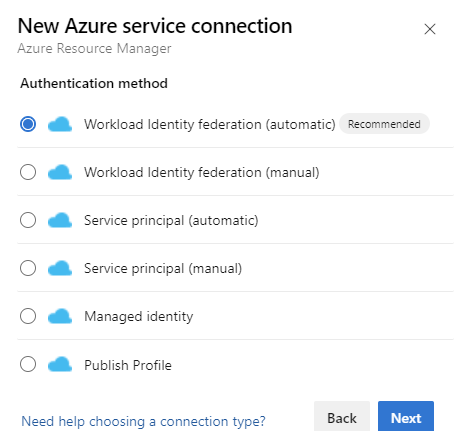
Заполните необходимые сведения, нажмите кнопку "Проверить", а затем нажмите кнопку "Сохранить".
Конфигурация конвейера Yaml
Задачи можно настроить как с помощью веб-интерфейса Azure DevOps, так и с помощью кода Yaml в схеме конвейера.
Пример использования команды администратора
steps:
- task: Azure-Kusto.PublishToADX.PublishToADX.PublishToADX@4
displayName: '<Task Name>'
inputs:
targetType: 'inline'
script: '<inline Script>'
waitForOperation: true
kustoUrls: '$(CONNECTIONSTRING):443?DatabaseName=""'
authType: 'armserviceconn'
connectedServiceARM: '<ARM Service Endpoint Name>'
serialDelay: 1000
continueOnError: true
condition: ne(variables['ProductVersion'], '') ## Custom condition Sample
Пример использования запроса
steps:
- task: Azure-Kusto.PublishToADX.ADXQuery.ADXQuery@4
displayName: '<Task Display Name>'
inputs:
targetType: 'inline'
script: |
let badVer=
RunnersLogs | where Timestamp > ago(30m)
| where EventText startswith "$$runnerresult" and Source has "ShowDiagnostics"
| extend State = extract(@"Status='(.*)', Duration.*",1, EventText)
| where State == "Unhealthy"
| extend Reason = extract(@'"NotHealthyReason":"(.*)","IsAttentionRequired.*',1, EventText)
| extend Cluster = extract(@'Kusto.(Engine|DM|CM|ArmResourceProvider).(.*).ShowDiagnostics',2, Source)
| where Reason != "Merge success rate past 60min is < 90%"
| where Reason != "Ingestion success rate past 5min is < 90%"
| where Reason != "Ingestion success rate past 5min is < 90%, Merge success rate past 60min is < 90%"
| where isnotempty(Cluster)
| summarize max(Timestamp) by Cluster,Reason
| order by max_Timestamp desc
| where Reason startswith "Differe"
| summarize by Cluster
;
DimClusters | where Cluster in (badVer)
| summarize by Cluster , CmConnectionString , ServiceConnectionString ,DeploymentRing
| extend ServiceConnectionString = strcat("#connect ", ServiceConnectionString)
| where DeploymentRing == "$(DeploymentRing)"
kustoUrls: 'https://<ClusterName>.kusto.windows.net?DatabaseName=<DataBaneName>'
authType: 'kustoserviceconn'
connectedServiceName: '<connection service name>'
minThreshold: '0'
maxThreshold: '10'
continueOnError: true