Руководство. Разработка панели мониторинга аналитики в режиме реального времени с помощью Azure Cosmos DB для PostgreSQL
Область применения: ![]() Azure Cosmos DB для PostgreSQL (на базе расширения базы данных Citus до PostgreSQL)
Azure Cosmos DB для PostgreSQL (на базе расширения базы данных Citus до PostgreSQL)
В этом руководстве вы узнаете, как использовать Azure Cosmos DB для PostgreSQL:
- Создание кластера
- Использование служебной программы psql для создания схемы
- Сегментирование таблиц по узлам
- Создание примера данных
- выполнение сведения данных;
- выполнение запроса к необработанным и агрегированным данным;
- удаление устаревших данных.
Необходимые компоненты
Если у вас нет подписки Azure, создайте бесплатную учетную запись, прежде чем приступить к работе.
Создание кластера
Войдите в портал Azure и выполните следующие действия, чтобы создать кластер Azure Cosmos DB для PostgreSQL:
Перейдите к разделу Создание кластера Azure Cosmos DB for PostgreSQL на портале Azure.
В форме кластера Create a Azure Cosmos DB for PostgreSQL:
Укажите сведения на вкладке Основные сведения.
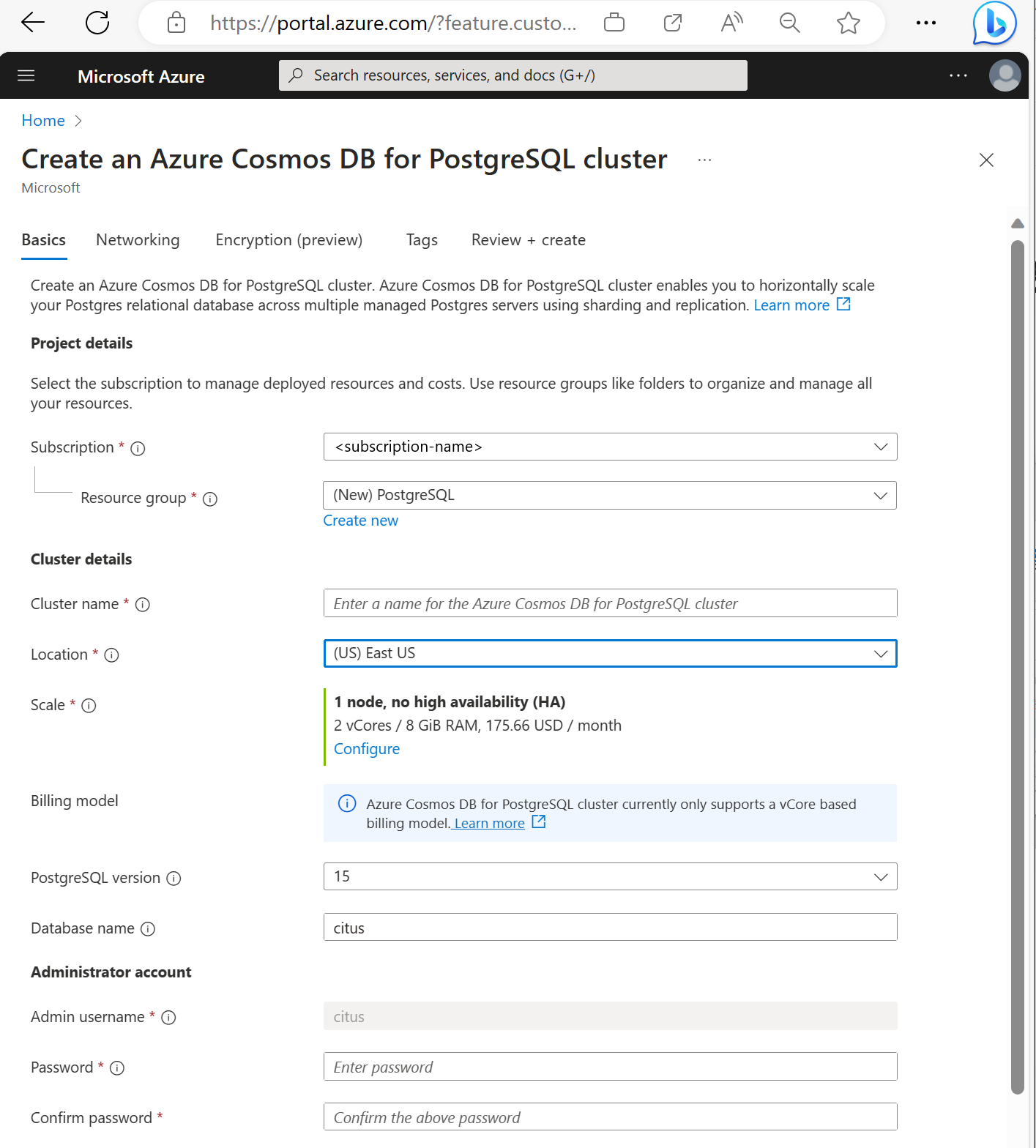
Назначение большинства параметров очевидно из их названия, но примите во внимание следующее:
- Имя кластера определяет DNS-имя, используемое для подключения приложений, в форме
<node-qualifier>-<clustername>.<uniqueID>.postgres.cosmos.azure.com. - Вы можете выбрать основную версию PostgreSQL, например 15. Azure Cosmos DB для PostgreSQL всегда поддерживает последнюю версию Citus для выбранной основной версии Postgres.
- Для имени администратора должно быть установлено значение
citus. - Вы можете оставить имя базы данных по умолчанию citus или определить только имя базы данных. После подготовки кластера невозможно переименовать базу данных.
- Имя кластера определяет DNS-имя, используемое для подключения приложений, в форме
Выберите Далее: Сеть в нижней части экрана.
На экране "Сеть" выберите "Разрешить общедоступный доступ" из служб и ресурсов Azure в этом кластере.
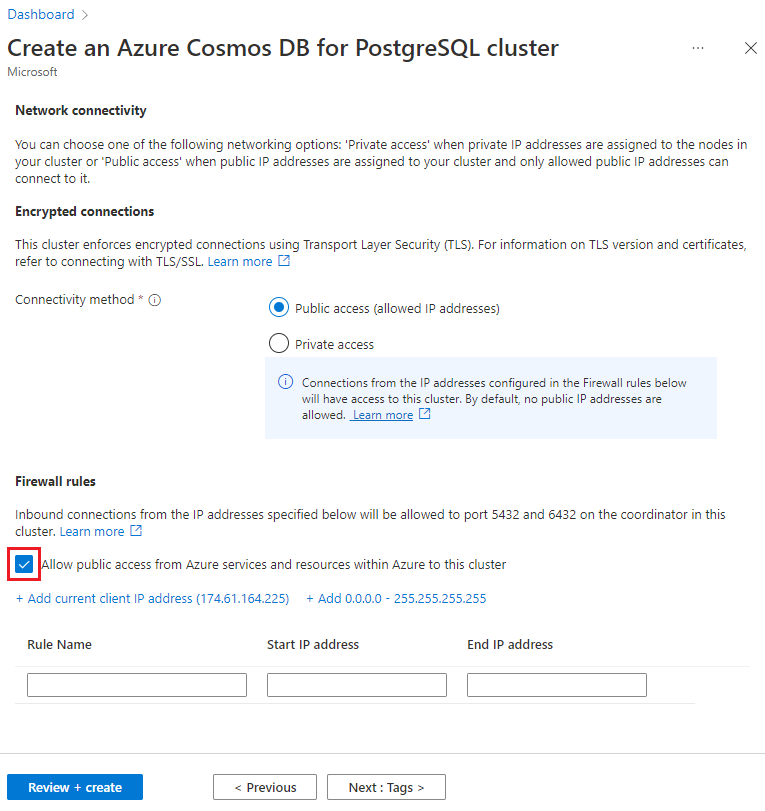
Выберите элемент Просмотр и создание, а по завершении проверки нажмите кнопку Создать, чтобы создать кластер.
Подготовка занимает несколько минут. Вы перейдете на страницу отслеживания развертывания. Когда состояние изменится с Выполняется развертывание на Развертывание выполнено, выберите элемент Перейти к ресурсу.
Использование служебной программы psql для создания схемы
После подключения к Azure Cosmos DB для PostgreSQL с помощью psql можно выполнить некоторые основные задачи. В этом руководстве показано, как выполнить прием данных из средства веб-аналитики и сведение данных для их представления в реальном времени на панели мониторинга.
Давайте создадим таблицу, в которую будут поступать необработанные данные. В окне терминала psql выполните следующие команды:
CREATE TABLE http_request (
site_id INT,
ingest_time TIMESTAMPTZ DEFAULT now(),
url TEXT,
request_country TEXT,
ip_address TEXT,
status_code INT,
response_time_msec INT
);
Кроме того, мы собираемся создать таблицу, в которой будут находиться поминутно агрегированные данные, и таблицу со сведениями о последнем сведении данных. В psql выполните также следующие команды:
CREATE TABLE http_request_1min (
site_id INT,
ingest_time TIMESTAMPTZ, -- which minute this row represents
error_count INT,
success_count INT,
request_count INT,
average_response_time_msec INT,
CHECK (request_count = error_count + success_count),
CHECK (ingest_time = date_trunc('minute', ingest_time))
);
CREATE INDEX http_request_1min_idx ON http_request_1min (site_id, ingest_time);
CREATE TABLE latest_rollup (
minute timestamptz PRIMARY KEY,
CHECK (minute = date_trunc('minute', minute))
);
Созданные таблицы можно отобразить в виде списка с помощью этой команды psql:
\dt
Сегментирование таблиц по узлам
Развертывание Azure Cosmos DB для PostgreSQL сохраняет строки таблиц на разных узлах на основе значения указанного пользователем столбца. Этот столбец определяет, как данные распределяются между узлами.
Назначим столбец распределения ключом сегментирования site_id. Выполните в psql такие функции:
SELECT create_distributed_table('http_request', 'site_id');
SELECT create_distributed_table('http_request_1min', 'site_id');
Внимание
Распространение таблиц или использование сегментирования на основе схем необходимо использовать преимущества функций производительности Azure Cosmos DB для PostgreSQL. Если вы не распределяете таблицы или схемы, рабочие узлы не могут помочь выполнять запросы, связанные с их данными.
Создание примера данных
Теперь наш кластер должен быть готов к приему некоторых данных. Следующие команды можно выполнить локально в psql для постоянного добавления данных.
DO $$
BEGIN LOOP
INSERT INTO http_request (
site_id, ingest_time, url, request_country,
ip_address, status_code, response_time_msec
) VALUES (
trunc(random()*32), clock_timestamp(),
concat('http://example.com/', md5(random()::text)),
('{China,India,USA,Indonesia}'::text[])[ceil(random()*4)],
concat(
trunc(random()*250 + 2), '.',
trunc(random()*250 + 2), '.',
trunc(random()*250 + 2), '.',
trunc(random()*250 + 2)
)::inet,
('{200,404}'::int[])[ceil(random()*2)],
5+trunc(random()*150)
);
COMMIT;
PERFORM pg_sleep(random() * 0.25);
END LOOP;
END $$;
Запрос выполняет вставку примерно восьми строк каждую секунду. Строки сохраняются на разных рабочих узлах, как указано в столбце распределения site_id.
Примечание.
Оставьте выполняться запрос на создание данных и откройте второй сеанс psql для ввода оставшихся команд из этого руководства.
Query
Azure Cosmos DB для PostgreSQL позволяет нескольким узлам параллельно обрабатывать запросы на скорость. Так, база данных вычисляет агрегаты, такие как SUM и COUNT, на рабочих узлах и объединяет результаты в итоговый ответ.
Ниже показан запрос для подсчета веб-запросов в минуту вместе с некоторой статистикой. Попробуйте выполнить его в psql и просмотрите результаты.
SELECT
site_id,
date_trunc('minute', ingest_time) as minute,
COUNT(1) AS request_count,
SUM(CASE WHEN (status_code between 200 and 299) THEN 1 ELSE 0 END) as success_count,
SUM(CASE WHEN (status_code between 200 and 299) THEN 0 ELSE 1 END) as error_count,
SUM(response_time_msec) / COUNT(1) AS average_response_time_msec
FROM http_request
WHERE date_trunc('minute', ingest_time) > now() - '5 minutes'::interval
GROUP BY site_id, minute
ORDER BY minute ASC;
Сведение данных
Предыдущий запрос эффективен на ранних этапах, но его производительность падает по мере масштабирования. Даже при распределенной обработке будет быстрее предварительно вычислить эти данные, чем пересчитывать их каждый раз.
Быстродействие панели мониторинга можно обеспечить за счет регулярного сведения необработанных данных в таблицу агрегированных данных. Вы можете поэкспериментировать с длительностью статистической обработки. Мы использовали таблицу поминутной статистической обработки, но вместо этого вы можете разбить данные на интервалы в 5, 15 или 60 минут.
Для простого сведения мы собираемся поместить ее в функцию plpgsql. Выполните следующие команды в psql для создания функции rollup_http_request.
-- initialize to a time long ago
INSERT INTO latest_rollup VALUES ('10-10-1901');
-- function to do the rollup
CREATE OR REPLACE FUNCTION rollup_http_request() RETURNS void AS $$
DECLARE
curr_rollup_time timestamptz := date_trunc('minute', now());
last_rollup_time timestamptz := minute from latest_rollup;
BEGIN
INSERT INTO http_request_1min (
site_id, ingest_time, request_count,
success_count, error_count, average_response_time_msec
) SELECT
site_id,
date_trunc('minute', ingest_time),
COUNT(1) as request_count,
SUM(CASE WHEN (status_code between 200 and 299) THEN 1 ELSE 0 END) as success_count,
SUM(CASE WHEN (status_code between 200 and 299) THEN 0 ELSE 1 END) as error_count,
SUM(response_time_msec) / COUNT(1) AS average_response_time_msec
FROM http_request
-- roll up only data new since last_rollup_time
WHERE date_trunc('minute', ingest_time) <@
tstzrange(last_rollup_time, curr_rollup_time, '(]')
GROUP BY 1, 2;
-- update the value in latest_rollup so that next time we run the
-- rollup it will operate on data newer than curr_rollup_time
UPDATE latest_rollup SET minute = curr_rollup_time;
END;
$$ LANGUAGE plpgsql;
Используйте функцию, чтобы выполнить сведение данных.
SELECT rollup_http_request();
Используя неагрегированные данные, можно выполнить запрос к таблице сведения для получения такого же отчета, как и ранее. Выполните приведенный ниже запрос:
SELECT site_id, ingest_time as minute, request_count,
success_count, error_count, average_response_time_msec
FROM http_request_1min
WHERE ingest_time > date_trunc('minute', now()) - '5 minutes'::interval;
Удаление устаревших данных
Сведение позволяет быстрее обрабатывать запросы, но нам также нужно удалять устаревшие данные, чтобы избежать расходов на хранение постоянно растущего объема данных. Определите, как долго требуется хранить данные разной степени детализации и используйте стандартные запросы для удаления данных с истекшим сроком хранения. В следующем примере мы решили хранить необработанные данные за один день, а поминутно агрегированные данные — за один месяц.
DELETE FROM http_request WHERE ingest_time < now() - interval '1 day';
DELETE FROM http_request_1min WHERE ingest_time < now() - interval '1 month';
В рабочей среде эти запросы можно реализовать в виде функции и вызывать ее каждую минуту с помощью задания cron.
Очистка ресурсов
На предыдущих шагах вы создали ресурсы Azure в кластере. Если вы не ожидаете, что эти ресурсы потребуются в будущем, удалите кластер. Нажмите кнопку "Удалить" на странице обзора кластера. При появлении всплывающего запроса подтвердите имя кластера и нажмите кнопку " Удалить ".
Следующие шаги
В этом руководстве вы узнали, как подготовить кластер. Вы подключились к ней с помощью psql, создали схему и выполнили распределение данных. Вы научились выполнять запросы к необработанным данным и регулярно агрегировать их, выполнять запрос к таблице агрегированных данных и удалять устаревшие данные.
- Сведения о типах узлов кластера
- Определение оптимального начального размера кластера