Модель приложений аналитики в режиме реального времени в Azure Cosmos DB для PostgreSQL
Область применения: ![]() Azure Cosmos DB для PostgreSQL (на базе расширения базы данных Citus до PostgreSQL)
Azure Cosmos DB для PostgreSQL (на базе расширения базы данных Citus до PostgreSQL)
Размещение больших таблиц с помощью ключа сегмента
Чтобы выбрать ключ сегмента для приложения операционной аналитики в реальном времени, следуйте приведенным ниже рекомендациям:
- Выбор столбца, распространенного в больших таблицах
- Выберите столбец, который является естественным измерением в данных или центральным элементом приложения. Некоторые примеры:
- В финансовом мире приложение, которое анализирует тенденции безопасности, вероятно, будет использовать
security_id. - В рабочей нагрузке аналитики пользователей, где требуется проанализировать метрики использования веб-сайта, подходящим столбцом распределения будет
user_id.
- В финансовом мире приложение, которое анализирует тенденции безопасности, вероятно, будет использовать
Путем совместного размещения больших таблиц можно отправлять SQL-запросы к рабочим узлам параллельно. Отправка запросов позволяет избежать перетасовки данных между узлами по сети. Можно эффективно выполнять такие операции, как JOIN, агрегаты, свертки, фильтры, LIMIT.
Чтобы визуализировать параллельные распределенные запросы в совместно размещенных таблицах, рассмотрим эту схему:
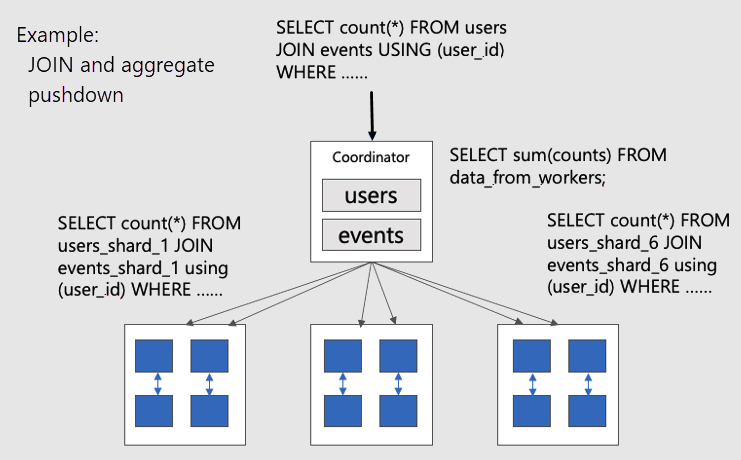
Таблицы users и events сегментируются по user_id, поэтому связанные строки для одного и того же идентификатора пользователя размещаются на одном рабочем узле. SQL JOIN может происходить без извлечения информации между рабочими узлами.
Оптимальная модель данных для приложений в реальном времени
Давайте продолжим работу с примером приложения, которое анализирует посещения и метрики веб-сайта пользователя. Существует две таблицы фактов, users (пользователи) и events (события), и меньшие таблицы измерений.
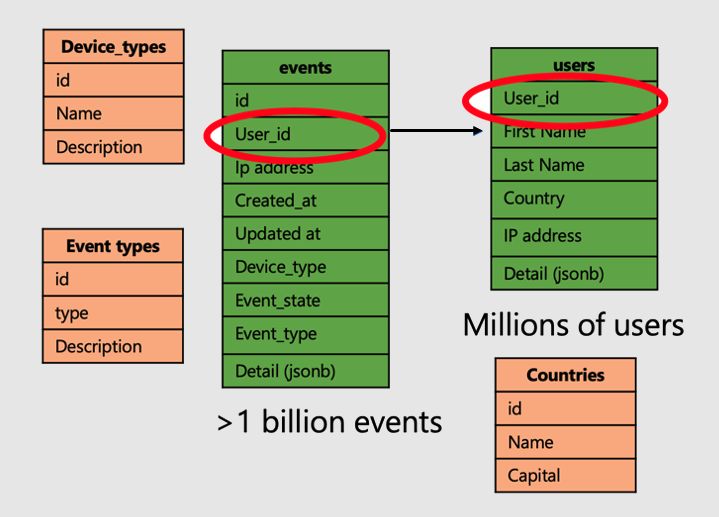
Чтобы применить суперсилу распределенных таблиц в Azure Cosmos DB для PostgreSQL, выполните следующие действия.
- Распределение больших таблиц фактов в общем столбце. В нашем случае пользователи и события распределяются по
user_id. - Пометьте таблицы небольших и измерений (
device_typescountriesи event_types) в качестве ссылочных таблиц. - Не забудьте включить столбец распределения в ограничения первичного, уникального и внешнего ключа в распределенных таблицах. Включение столбца может потребовать создания составных ключей. Необходимо обновить ключи для ссылочных таблиц.
- При присоединении больших распределенных таблиц используйте ключ сегмента.
-- Distribute the fact tables
SELECT create_distributed_table('users', 'user_id');
SELECT create_distributed_table('products', 'user_id', colocate_with => 'users');
-- Turn dimension tables into reference tables, with synchronized copies
-- maintained on every worker node
SELECT create_reference_table('countries');
-- similarly for device_types and event_types...
Следующие шаги
Мы закончили изучение моделирования данных для масштабируемых приложений. Следующим шагом является подключение и запрос базы данных с использованием выбранного языка программирования.