Получение дополненного поколения (RAG) с виртуальными ядрами Azure Cosmos DB для MongoDB
В быстро развивающейся области генерированного ИИ крупные языковые модели (LLMs), такие как GPT-3.5, преобразовали обработку естественного языка. Однако развивающаяся тенденция в ИИ — это использование векторных хранилищ, которые играют ключевую роль в улучшении приложений ИИ.
В этом руководстве описывается, как использовать Azure Cosmos DB для MongoDB (vCore), LangChain и OpenAI для реализации расширенного поколения (RAG) для повышения производительности ИИ, а также обсуждения LLM и их ограничений. Мы рассмотрим быстро принятую парадигму "получения дополненного поколения" (RAG) и кратко обсудим платформу LangChain, модели Azure OpenAI. Наконец, мы интегрируем эти понятия в реальное приложение. К концу читатели будут иметь твердое понимание этих понятий.
Общие сведения о крупных языковых моделях (LLM) и их ограничениях
Крупные языковые модели (LLMs) — это расширенные модели глубокой нейронной сети, обучаемые на обширных текстовых наборах данных, что позволяет им понять и создать человеческий текст. В то время как революционные в обработке естественного языка, LLM имеют встроенные ограничения:
- Галлюцинации: LLM иногда генерируют фактически неверные или незапланированные сведения, известные как "галлюцинации".
- Устаревшие данные: LLM обучены на статических наборах данных, которые могут не включать последние сведения, ограничивающие их текущую релевантность.
- Нет доступа к локальным данным пользователя: У LLM нет прямого доступа к персональным или локализованным данным, ограничивающим их возможность предоставлять персонализированные ответы.
- Ограничения маркеров: LLM имеют максимальное ограничение маркера для каждого взаимодействия, что ограничивает объем текста, который они могут обрабатывать одновременно. Например, gpt-3.5-turbo OpenAI имеет ограничение маркера 4096.
Использование получения дополненного поколения (RAG)
Получение дополненного поколения (RAG) — это архитектура, предназначенная для преодоления ограничений LLM. RAG использует векторный поиск для получения соответствующих документов на основе входного запроса, предоставляя эти документы в качестве контекста LLM для создания более точных ответов. Вместо того, чтобы полагаться исключительно на предварительно обученные шаблоны, RAG улучшает ответы путем включения актуальной, актуальной информации. Такой подход помогает:
- Свести к минимуму галлюцинации: приземление ответов фактических сведений.
- Убедитесь, что текущая информация: получение последних данных для обеспечения актуальных ответов.
- Использование внешних баз данных: хотя он не предоставляет прямой доступ к личным данным, RAG разрешает интеграцию с внешними, пользовательскими база знаний.
- Оптимизация использования маркеров. Фокусируясь на наиболее релевантных документах, RAG делает использование маркеров более эффективным.
В этом руководстве показано, как можно реализовать RAG с помощью Azure Cosmos DB для MongoDB (vCore) для создания приложения для ответов на вопросы, адаптированное к вашим данным.
Общие сведения об архитектуре приложений
На схеме архитектуры ниже показаны ключевые компоненты реализации RAG:
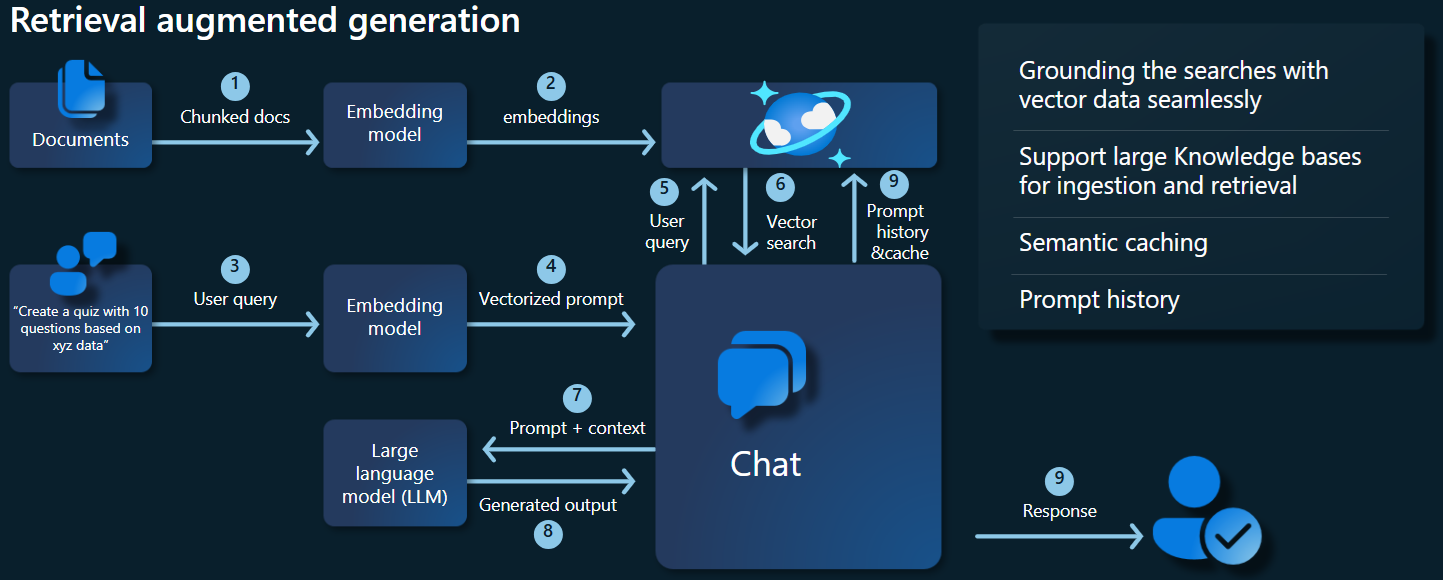
Ключевые компоненты и платформы
Теперь мы обсудим различные платформы, модели и компоненты, используемые в этом руководстве, подчеркивая их роли и нюансы.
Azure Cosmos DB для MongoDB (vCore)
Azure Cosmos DB для MongoDB (vCore) поддерживает семантические поиски сходства, необходимые для приложений, на основе ИИ. Он позволяет представлять данные в различных форматах в виде векторных внедрения, которые можно хранить вместе с исходными данными и метаданными. Используя приблизительный алгоритм ближайших соседей, например иерархический навигации по небольшому миру (HNSW), эти внедрения можно запрашивать для быстрого поиска семантической сходства.
Платформа LangChain
LangChain упрощает создание приложений LLM, предоставляя стандартный интерфейс для цепочек, интеграции нескольких инструментов и сквозных цепочек для общих задач. Это позволяет разработчикам ИИ создавать приложения LLM, использующие внешние источники данных.
Ключевые аспекты LangChain:
- Цепочки: последовательности компонентов, решающих определенные задачи.
- Компоненты: модули, такие как оболочки LLM, векторные оболочки хранилища векторов, шаблоны запросов, загрузчики данных, разделители текста и средства извлечения.
- Модульность: упрощение разработки, отладки и обслуживания.
- Популярность: проект с открытым исходным кодом быстро получает внедрение и развивается в соответствии с потребностями пользователей.
Интерфейс служб приложение Azure
Службы приложений предоставляют надежную платформу для создания удобных веб-интерфейсов для приложений Gen-AI. В этом руководстве используются службы приложение Azure для создания интерактивного веб-интерфейса для приложения.
Модели OpenAI
OpenAI является лидером в исследованиях ИИ, предоставляя различные модели для создания языка, векторизации текста, создания изображений и преобразования звука в текст. В этом руководстве мы будем использовать внедренные и языковые модели OpenAI, важные для понимания и создания языковых приложений.
Внедрение моделей и моделей создания языка
| Категория | Модель внедрения текста | Языковая модель |
|---|---|---|
| Целевые назначения | Преобразование текста в векторные внедрения. | Понимание и создание естественного языка. |
| Function | Преобразует текстовые данные в многомерные массивы чисел, захватывая семантический смысл текста. | Понимает и создает человеческий текст на основе заданных входных данных. |
| Выходные данные | Массив чисел (векторных внедрения). | Текст, ответы, переводы, код и т. д. |
| Пример выходных данных | Каждое внедрение представляет семантический смысл текста в числовой форме с размерностью, определяемой моделью. Например, text-embedding-ada-002 создает векторы с 1536 измерениями. |
Контекстно релевантный и последовательный текст, созданный на основе предоставленных входных данных. Например, gpt-3.5-turbo может создавать ответы на вопросы, переводить текст, писать код и многое другое. |
| Типичные варианты использования | — семантический поиск | - Чат-боты |
| — системы рекомендаций | — автоматическое создание содержимого | |
| — кластеризация и классификация текстовых данных | — перевод на язык | |
| — получение сведений | -Уплотнения | |
| Представление данных | Числовое представление (внедрение) | Текст естественного языка |
| Размерность | Длина массива соответствует количеству измерений в пространстве внедрения, например 1536 измерений. | Обычно представляется в виде последовательности маркеров с контекстом, определяющим длину. |
Основные компоненты приложения
- Azure Cosmos DB для виртуальных ядер MongoDB: хранение и запросы векторных внедрения.
- LangChain: создание рабочего процесса LLM приложения. Использует такие средства, как:
- Загрузчик документов: для загрузки и обработки документов из каталога.
- Интеграция векторного хранилища: для хранения и запроса векторных внедрения в Azure Cosmos DB.
- AzureCosmosDBVectorSearch: оболочка вокруг поиска вектора Cosmos DB
- приложение Azure службы: создание пользовательского интерфейса для приложения Cosmic Food.
- Azure OpenAI: для предоставления моделей LLM и внедрения, включая:
- text-embedding-ada-002: модель внедрения текста, которая преобразует текст в векторные внедрения с 1536 измерениями.
- gpt-3.5-turbo: языковая модель для понимания и создания естественного языка.
Настройка среды
Чтобы приступить к оптимизации расширенного поколения (RAG) с помощью Azure Cosmos DB для MongoDB (vCore), выполните следующие действия:
- Создайте следующие ресурсы в Microsoft Azure:
- Кластер виртуальных ядер Azure Cosmos DB для MongoDB: ознакомьтесь с кратким руководством по началу работы.
- Ресурс Azure OpenAI с:
- Развертывание модели внедрения (например,
text-embedding-ada-002). - Развертывание модели чата (например,
gpt-35-turbo).
- Развертывание модели внедрения (например,
Примеры документов
В этом руководстве мы будем загружать один текстовый файл с помощью документа. Эти файлы должны быть сохранены в каталоге с именем данных в папке src . Содержимое следующего вида:
food_items.json
{
"category": "Cold Dishes",
"name": "Hamachi Fig",
"description": "Hamachi sashimi lightly tossed in a fig sauce with rum raisins, and serrano peppers then topped with fried lotus root.",
"price": "16.0 USD"
},
Загрузка документов
Задайте строка подключения Cosmos DB для MongoDB (vCore), имя базы данных, имя коллекции и индекс:
mongo_client = MongoClient(mongo_connection_string) database_name = "Contoso" db = mongo_client[database_name] collection_name = "ContosoCollection" index_name = "ContosoIndex" collection = db[collection_name]Инициализировать клиент внедрения.
from langchain_openai import AzureOpenAIEmbeddings openai_embeddings_model = os.getenv("AZURE_OPENAI_EMBEDDINGS_MODEL_NAME", "text-embedding-ada-002") openai_embeddings_deployment = os.getenv("AZURE_OPENAI_EMBEDDINGS_DEPLOYMENT_NAME", "text-embedding") azure_openai_embeddings: AzureOpenAIEmbeddings = AzureOpenAIEmbeddings( model=openai_embeddings_model, azure_deployment=openai_embeddings_deployment, )Создайте внедрение из данных, сохраните в базу данных и верните подключение к хранилищу векторов Cosmos DB для MongoDB (vCore).
vector_store: AzureCosmosDBVectorSearch = AzureCosmosDBVectorSearch.from_documents( json_data, azure_openai_embeddings, collection=collection, index_name=index_name, )Создайте следующий векторный индекс HNSW в коллекции (обратите внимание, что имя индекса совпадает с указанным выше).
num_lists = 100 dimensions = 1536 similarity_algorithm = CosmosDBSimilarityType.COS kind = CosmosDBVectorSearchType.VECTOR_HNSW m = 16 ef_construction = 64 vector_store.create_index( num_lists, dimensions, similarity_algorithm, kind, m, ef_construction )
Выполнение векторного поиска с помощью Cosmos DB для MongoDB (vCore)
Подключитесь к хранилищу векторов.
vector_store: AzureCosmosDBVectorSearch = AzureCosmosDBVectorSearch.from_connection_string( connection_string=mongo_connection_string, namespace=f"{database_name}.{collection_name}", embedding=azure_openai_embeddings, )Определите функцию, которая выполняет семантический поиск сходства с помощью векторного поиска Cosmos DB в запросе (обратите внимание, что фрагмент кода — это только тестовая функция).
query = "beef dishes" docs = vector_store.similarity_search(query) print(docs[0].page_content)Инициализация клиента чата для реализации функции RAG.
azure_openai_chat: AzureChatOpenAI = AzureChatOpenAI( model=openai_chat_model, azure_deployment=openai_chat_deployment, )Создайте функцию RAG.
history_prompt = ChatPromptTemplate.from_messages( [ MessagesPlaceholder(variable_name="chat_history"), ("user", "{input}"), ( "user", """Given the above conversation, generate a search query to look up to get information relevant to the conversation""", ), ] ) context_prompt = ChatPromptTemplate.from_messages( [ ("system", "Answer the user's questions based on the below context:\n\n{context}"), MessagesPlaceholder(variable_name="chat_history"), ("user", "{input}"), ] )Преобразует векторное хранилище в средство извлечения, которое может искать соответствующие документы на основе указанных параметров.
vector_store_retriever = vector_store.as_retriever( search_type=search_type, search_kwargs={"k": limit, "score_threshold": score_threshold} )Создайте цепочку извлекателя, которая учитывает журнал бесед, обеспечивая контекстно релевантное получение документов с помощью модели azure_openai_chat и vector_store_retriever.
retriever_chain = create_history_aware_retriever(azure_openai_chat, vector_store_retriever, history_prompt)Создайте цепочку, которая объединяет извлеченные документы в последовательный ответ с помощью языковой модели (azure_openai_chat) и указанного запроса (context_prompt).
context_chain = create_stuff_documents_chain(llm=azure_openai_chat, prompt=context_prompt)Создайте цепочку, которая обрабатывает весь процесс извлечения, интегрируя цепочку извлекателя с учетом журнала и цепочку сочетаний документов. Эту цепочку RAG можно выполнить для получения и создания контекстно точных ответов.
rag_chain: Runnable = create_retrieval_chain( retriever=retriever_chain, combine_docs_chain=context_chain, )
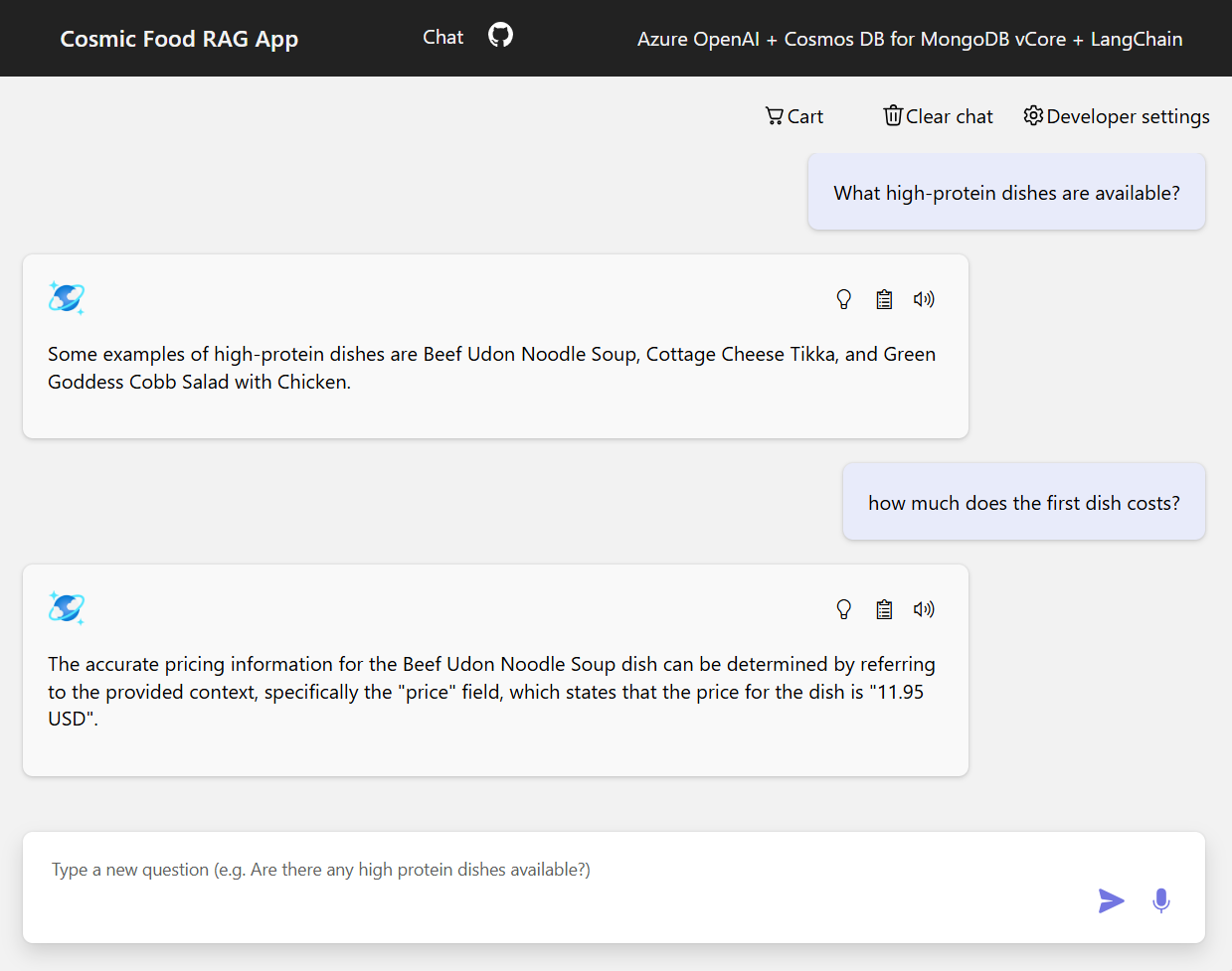
Пример выходных данных
На снимках экрана ниже показаны выходные данные для различных вопросов. Поиск чисто семантического сходства возвращает необработанный текст из исходных документов, а приложение с ответами на вопросы с помощью архитектуры RAG создает точные и персонализированные ответы путем объединения полученного содержимого документа с языковой моделью.
Заключение
В этом руководстве мы изучили, как создать приложение для ответа на вопросы, которое взаимодействует с частными данными с помощью Cosmos DB в качестве векторного хранилища. Используя архитектуру RAG (RAG) для получения дополненного поколения с помощью LangChain и Azure OpenAI, мы показали, как хранилища векторов необходимы для приложений LLM.
RAG является значительным прогрессом в искусственном интеллекте, особенно в обработке естественного языка, и объединение этих технологий позволяет создавать мощные приложения на основе ИИ для различных вариантов использования.