Перенос данных из MongoDB в учетную запись Azure Cosmos DB для MongoDB с помощью Azure Databricks
Область применения: ![]() MongoDB
MongoDB
Это руководство по миграции является частью серии по переносу баз данных из MongoDB в API Azure Cosmos DB для MongoDB. Как показано ниже, критически важные этапы миграции — это подготовка к миграции, миграция и действия после миграции.

Перенос данных с помощью Azure Databricks
Azure Databricks — это предложение "платформа как услуга" (PaaS) для Apache Spark. Она позволяет выполнять автономную миграцию крупных наборов данных. Azure Databricks можно использовать для автономной миграции баз данных из MongoDB в Azure Cosmos DB для MongoDB.
В этом учебнике рассматривается следующее.
Предоставление кластера Azure Databricks
Добавление зависимостей
Создание и запуск записной книжки Scala или Python
Оптимизация производительности миграции
Устранение ошибок, которые могут возникать во время миграции и приводить к ограничению скорости
Необходимые компоненты
Для работы с этим руководством вам потребуется следующее:
- Выполните необходимые действия перед миграцией, например оцените пропускную способность и выберите ключ сегмента.
- Создайте учетную запись Azure Cosmos DB для MongoDB.
Предоставление кластера Azure Databricks
Вы можете выполнить инструкции по подготовке кластера Azure Databricks. Мы рекомендуем выбрать среду выполнения Databricks версии 7.6, которая поддерживает Spark 3.0.
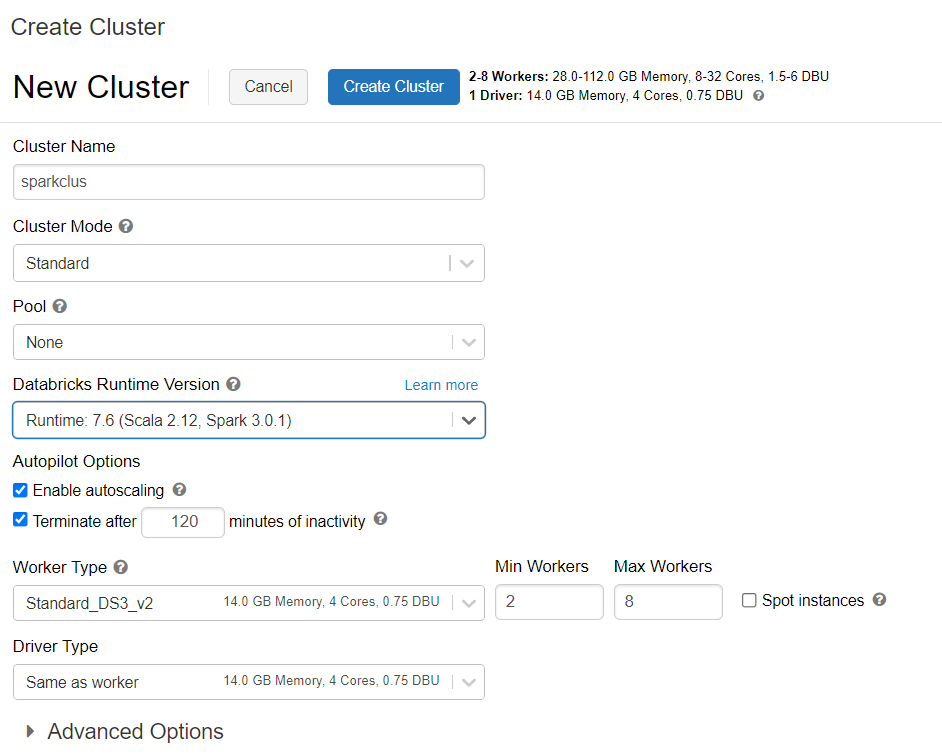
Добавление зависимостей
Добавьте соединитель MongoDB для Spark в кластер, чтобы подключиться как к собственным конечным точкам MongoDB, так и к конечным точкам Azure Cosmos DB для MongoDB. В кластере щелкните Библиотеки>Установить новую>Maven и добавьте координаты Maven org.mongodb.spark:mongo-spark-connector_2.12:3.0.1.
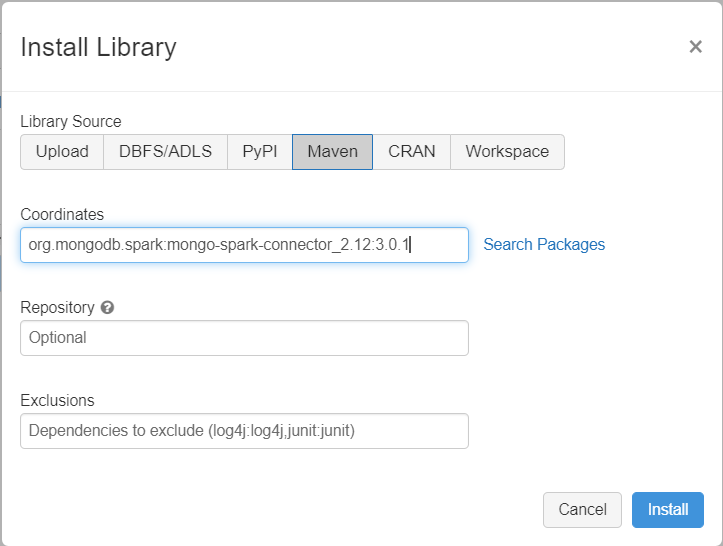
Нажмите кнопку Установить, а затем перезапустите кластер после завершения установки.
Примечание.
После установки библиотеки MongoDB Connector for Spark обязательно перезапустите кластер Databricks.
После этого вы сможете создать записную книжку Scala или Python для миграции.
Создание записной книжки Scala для миграции
Создайте записную книжку Scala в Databricks. Перед выполнением следующего кода обязательно укажите правильные значения переменных:
import com.mongodb.spark._
import com.mongodb.spark.config._
import org.apache.spark._
import org.apache.spark.sql._
var sourceConnectionString = "mongodb://<USERNAME>:<PASSWORD>@<HOST>:<PORT>/<AUTHDB>"
var sourceDb = "<DB NAME>"
var sourceCollection = "<COLLECTIONNAME>"
var targetConnectionString = "mongodb://<ACCOUNTNAME>:<PASSWORD>@<ACCOUNTNAME>.mongo.cosmos.azure.com:10255/?ssl=true&replicaSet=globaldb&retrywrites=false&maxIdleTimeMS=120000&appName=@<ACCOUNTNAME>@"
var targetDb = "<DB NAME>"
var targetCollection = "<COLLECTIONNAME>"
val readConfig = ReadConfig(Map(
"spark.mongodb.input.uri" -> sourceConnectionString,
"spark.mongodb.input.database" -> sourceDb,
"spark.mongodb.input.collection" -> sourceCollection,
))
val writeConfig = WriteConfig(Map(
"spark.mongodb.output.uri" -> targetConnectionString,
"spark.mongodb.output.database" -> targetDb,
"spark.mongodb.output.collection" -> targetCollection,
"spark.mongodb.output.maxBatchSize" -> "8000"
))
val sparkSession = SparkSession
.builder()
.appName("Data transfer using spark")
.getOrCreate()
val customRdd = MongoSpark.load(sparkSession, readConfig)
MongoSpark.save(customRdd, writeConfig)
Создание записной книжки Python для миграции
Создайте записную книжку Python в Databricks. Перед выполнением следующего кода обязательно укажите правильные значения переменных:
from pyspark.sql import SparkSession
sourceConnectionString = "mongodb://<USERNAME>:<PASSWORD>@<HOST>:<PORT>/<AUTHDB>"
sourceDb = "<DB NAME>"
sourceCollection = "<COLLECTIONNAME>"
targetConnectionString = "mongodb://<ACCOUNTNAME>:<PASSWORD>@<ACCOUNTNAME>.mongo.cosmos.azure.com:10255/?ssl=true&replicaSet=globaldb&retrywrites=false&maxIdleTimeMS=120000&appName=@<ACCOUNTNAME>@"
targetDb = "<DB NAME>"
targetCollection = "<COLLECTIONNAME>"
my_spark = SparkSession \
.builder \
.appName("myApp") \
.getOrCreate()
df = my_spark.read.format("com.mongodb.spark.sql.DefaultSource").option("uri", sourceConnectionString).option("database", sourceDb).option("collection", sourceCollection).load()
df.write.format("mongo").mode("append").option("uri", targetConnectionString).option("maxBatchSize",2500).option("database", targetDb).option("collection", targetCollection).save()
Оптимизация производительности миграции
Производительность миграции можно регулировать с помощью указанных ниже конфигураций.
Количество рабочих и ядер в кластере Spark: больше рабочих ролей означает больше сегментов вычислений для выполнения задач.
maxBatchSize: значение
maxBatchSizeуправляет скоростью сохранения данных в целевую коллекцию Azure Cosmos DB. Если значение параметра maxBatchSize слишком велико для пропускной способности коллекции, это может привести к возникновению ошибок, связанных с ограничением скорости.Вам потребуется настроить количество рабочих ролей и параметр maxBatchSize в зависимости от количества исполнителей в кластере Spark, потенциального размера (и в связи с этим от стоимости единицы запроса) каждого записываемого документа и предельных значений пропускной способности для целевой коллекции.
Совет
maxBatchSize = Пропускная способность коллекции / (Стоимость единицы запроса для 1 документа * Количество рабочих ролей Spark * Количество ядер ЦП на рабочую роль)
Средство для работы с разделами MongoDB Spark и параметр partitionKey: по умолчанию используется средство для работы с разделами MongoDefaultPartitioner и значение параметра partitionKey _id. Средство для работы с разделами можно изменить, назначив значение
MongoSamplePartitionerсвойству конфигурации входных данныхspark.mongodb.input.partitioner. Аналогичным образом можно изменить параметр partitionKey, назначив соответствующее имя поля свойству конфигурации входных данныхspark.mongodb.input.partitioner.partitionKey. Правильный значение параметра partitionKey позволяет избежать неравномерного распределения данных (записи большого количества записей для одного и того же значения ключа сегмента).Отключение индексов при переносе данных: при миграции больших объемов данных рассмотрите возможность отключения индексов (особенно индекса с подстановочными знаками) в целевой коллекции. Индексы увеличивают затраты на единицу запроса при записи каждого документа. Высвобождение этих единиц запросов позволяет повысить скорость передачи данных. Вы можете включить индексы по окончании миграции данных.
Устранение неполадок
Ошибка времени ожидания (код ошибки 50)
Может появиться 50 код ошибки для операций с базой данных Azure Cosmos DB для MongoDB. Ошибки времени ожидания могут возникать в указанных ниже сценариях.
- Нехватка пропускной способности, выделенной для базы данных: убедитесь, что для целевой коллекции выделена достаточная пропускная способность.
- Неравномерное распределение данных при большом объеме данных. Если необходимо перенести большой объем данных в определенную таблицу, но данные распределены неравномерно, могут возникнуть ограничения скорости, даже если для вашей таблицы предусмотрено несколько единиц запросов. Система равномерно делит единицы запросов между физическими разделами, а чрезмерно неравномерное распределение данных может привести к "узким местам" при выполнении запросов к одному сегменту. Неравномерное распределение данных означает наличие большого количества записей для одного и того же значения ключа сегмента.
Ограничение скорости (код ошибки 16500)
Может появиться код ошибки 16500 для операций с базой данных Azure Cosmos DB для MongoDB. Это ошибки ограничения скорости, которые могут возникать в старых учетных записях или учетных записях, для которых отключена функция повтора попыток на стороне сервера.
- Функция повтора попыток на стороне сервера: вы можете включить функцию повтора попыток на стороне сервера (SSR), чтобы сервер автоматически повторял операции, для которых ограничена скорость.
Оптимизация после переноса
По завершении миграции данных можно подключиться к Azure Cosmos DB и управлять этими данными. После миграции можно выполнить другие действия, например оптимизировать политику индексирования, обновить уровень согласованности, используемый по умолчанию, или настроить глобальное распределение для вашей учетной записи Azure Cosmos DB. См. подробнее об оптимизации после переноса.
Дополнительные ресурсы
- Если вы планируете ресурсы для миграции в Azure Cosmos DB,
- Если вам известно только количество виртуальных ядер и серверов в существующем кластере баз данных, прочитайте об оценке единиц запроса на основе этих данных.
- Если вам известна стандартная частота запросов для текущей рабочей нагрузки базы данных, ознакомьтесь со статьей о расчете единиц запросов с помощью планировщика ресурсов Azure Cosmos DB