Использование секционированного графа в Azure Cosmos DB
Область применения: ![]() Гремлин
Гремлин
Одной из ключевых функций API для Gremlin в Azure Cosmos DB является возможность обработки крупномасштабных графов с помощью горизонтального масштабирования. С точки зрения хранилища и пропускной способности контейнеры можно масштабировать независимо друг от друга. В Azure Cosmos DB можно создавать контейнеры, которые можно автоматически масштабировать, чтобы хранить данные графа. Данные автоматически балансируются на основе указанного ключа секции.
Секционирование выполняется внутри контейнера, если контейнер будет хранить больше 20 ГБ или если необходимо выделить более чем 10 000 единиц запросов в секунду (ЕЗ). Данные автоматически секционируются на основе указанного ключа секции. Ключ секции требуется при создании контейнеров графов из портала Azure или с помощью драйверов Gremlin версии 3.x или более поздней. Ключ секции не требуется, если используются версии драйверов Gremlin 2.x или более ранние.
Те же общие принципы использования механизма секционирования Azure Cosmos DB применяются с учетом нескольких оптимизаций, связанных с графом, описанных далее.
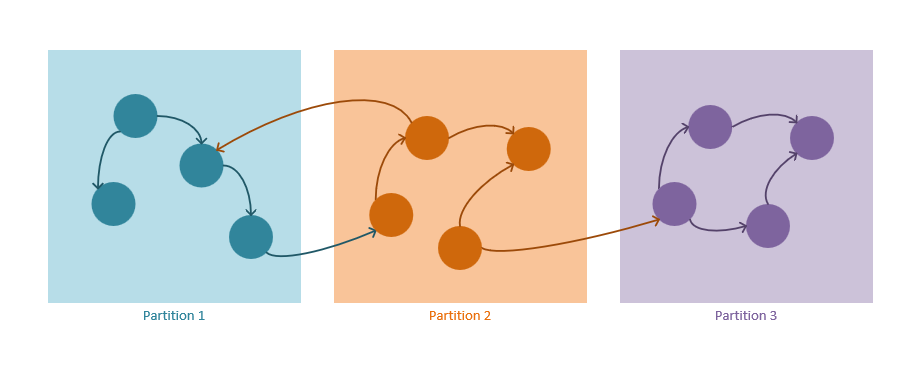
Механизм секционирования Graph
Следующие рекомендации описывают, как действует стратегия секционирования в Azure Cosmos DB.
Вершины и ребра хранятся в виде документов JSON.
Для вершин требуется ключ секции. Этот ключ определяет, в какой секции будет храниться вершина, с использованием алгоритма хэширования. Имя свойства ключа секции определяется при создании нового контейнера и имеет формат
/partitioning-key-name.Ребра будут храниться вместе с их исходной вершиной. Другими словами, для каждой вершины ключ секции определяет их место хранения вместе с ее исходящими ребрами. Оптимизация проводится во избежание межсекционных запросов при использовании кратности
out()в запросах графа.Края содержат ссылки на вершины, на которые они указывают. Все края хранятся с ключами секций и идентификаторами вершин, на которые они указывают. В результате этого вычисления все запросы направления
out()всегда будут секционированными запросами с областью, а не скрытыми межсекционными запросами.В запросах графа необходимо задавать ключ секции. Чтобы воспользоваться всеми преимуществами горизонтального секционирования в Azure Cosmos DB, ключ секции необходимо по возможности указывать всякий раз, когда выбирается одна вершина. Ниже приведены запросы для выбора одной или нескольких вершин в секционированном графе:
/idи/labelне поддерживаются в качестве ключей секций для контейнера в API для Gremlin.Выбор вершины по идентификатору, затем использование шага
.has()для указания свойства ключа секции:g.V('vertex_id').has('partitionKey', 'partitionKey_value')Выбор вершины путем указания кортежа, включая значение ключа секции и идентификатор:
g.V(['partitionKey_value', 'vertex_id'])Выбор набора вершин с их идентификаторами и определение списка значений ключей секций:
g.V('vertex_id0', 'vertex_id1', 'vertex_id2', …).has('partitionKey', within('partitionKey_value0', 'partitionKey_value01', 'partitionKey_value02', …)Использование стратегии секционирования в начале запроса и указание секции для области остальной части запроса Gremlin:
g.withStrategies(PartitionStrategy.build().partitionKey('partitionKey').readPartitions('partitionKey_value').create()).V()
Рекомендации при использовании секционированного графа
Следуйте приведенным ниже рекомендациям, чтобы обеспечить производительность и масштабируемость при использовании секционированных графов с контейнерами с неограниченным хранилищем.
Всегда указывайте значение ключа секции при запросе вершины. Чтобы получить возможность повысить производительность, получите вершины из известной секции. Все последующие операции соседства будут всегда находиться в области видимости секции, поскольку края содержат идентификатор ссылки и ключ секции для целевых вершин.
По возможности используйте исходящее направление при запросе ребер. Как упоминалось выше, ребра хранятся с их исходными вершинами в исходящем направлении. Поэтому, вероятность повторной сортировки межсекционных запросов сведена к минимуму, когда данные и запросы разработаны с ориентацией на этот шаблон. В противоположность этому, запрос
in()всегда будет размноженным.Выберите ключ секции, который равномерно распределяет данные по секциям. Это решение сильно зависит от модели данных решения. Дополнительные сведения о создании соответствующего ключа секции см. в статье Секционирование и масштабирование в Azure Cosmos DB.
Оптимизируйте запросы для получения данных в пределах секции. Оптимальной стратегией секционирования является согласование с шаблонами запросов. Запросы для получения данных из одной секции обеспечивают наилучшую производительность.
Следующие шаги
Затем можно ознакомиться со следующими статьями:
- Дополнительные сведения о секционировании и масштабировании в Azure Cosmos DB.
- Узнайте о поддержке Gremlin в API для Gremlin.
- Сведения об API для Gremlin.