Подсистема приема данных, не зависящая от данных
В этой статье объясняется, как реализовать сценарии независимой от типа данных загрузки с использованием комбинации PowerApps, Azure Logic Apps и задач копирования, управляемых метаданными в фабрике данных Azure.
Сценарии не зависящего от данных механизма приема обычно сосредоточены на том, чтобы пользователи без технических навыков (не являющиеся инженерами по данным) могли публиковать ресурсы данных в озеро данных (Data Lake) для дальнейшей обработки. Для реализации этого сценария необходимо иметь возможности подключения, которые позволяют:
- Регистрация ресурса данных
- Подготовка рабочих процессов и запись метаданных
- Планирование приема
Вы можете увидеть, как взаимодействуют эти возможности:
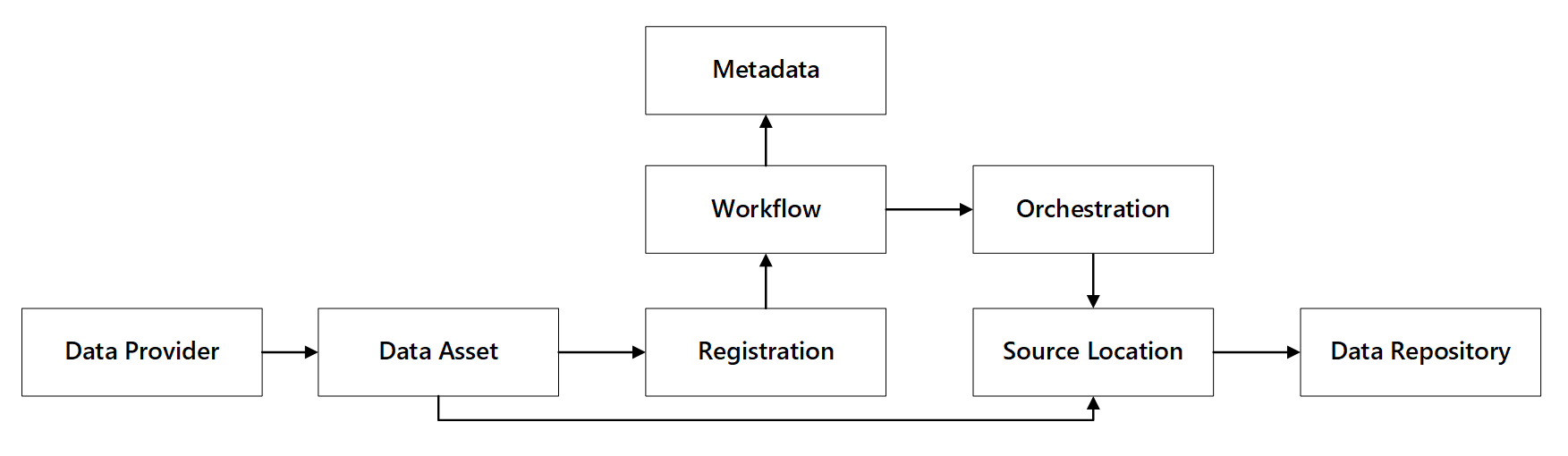
Рис. 1. Взаимодействие возможностей регистрации данных.
На следующей схеме показано, как реализовать этот процесс с помощью сочетания служб Azure:
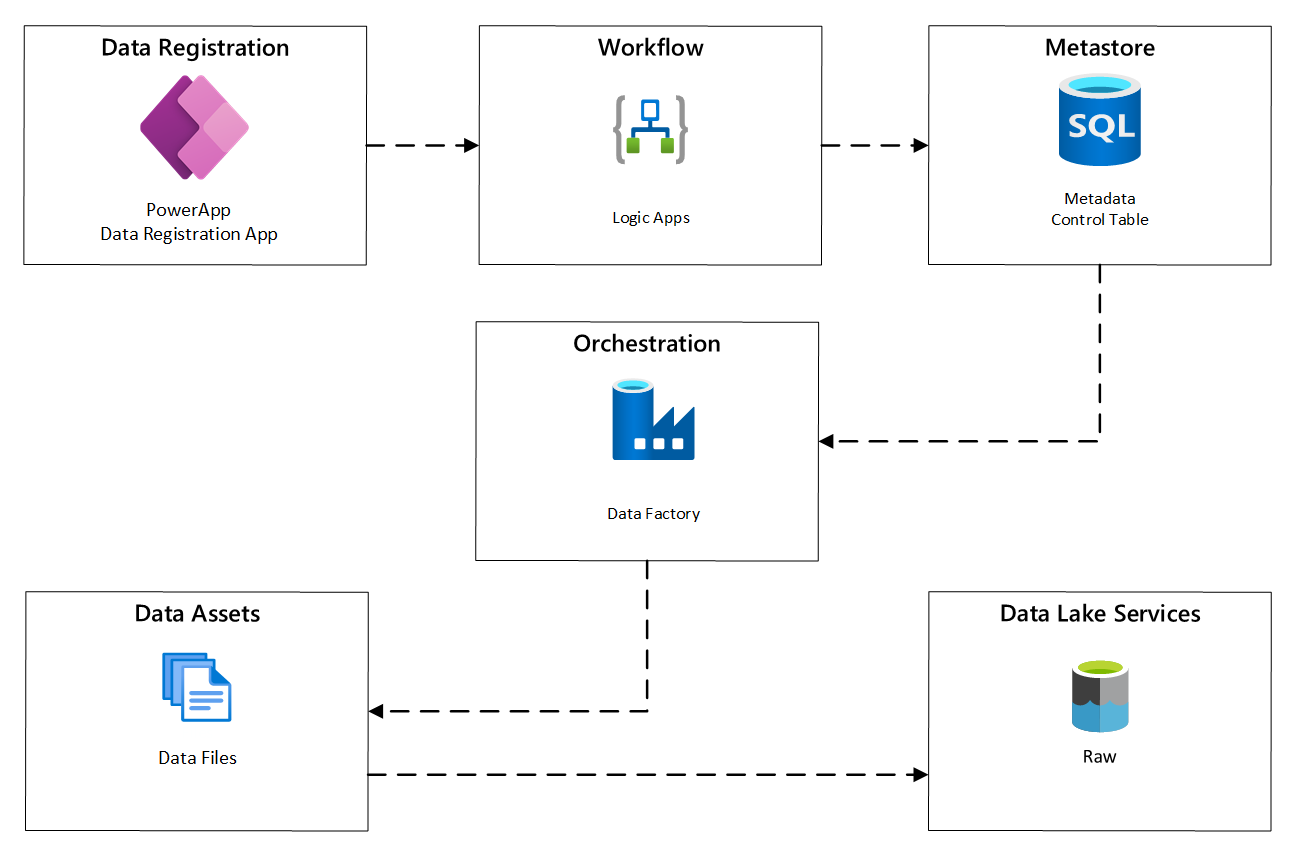
рис. 2. Автоматизированный процесс поглощения.
Регистрация ресурса данных
Чтобы предоставить метаданные, используемые для автоматического приема данных, требуется регистрация ресурса данных. Данные, которые вы захватываете, содержат:
- Технические сведения: имя ресурса данных, исходная система, тип, формат и частота.
- сведения об управлении: владелец, кураторы, видимость для целей обнаружения и чувствительность.
PowerApps используется для записи метаданных, описывающих каждый ресурс данных. Используйте приложение на основе модели, чтобы ввести сведения, которые сохраняются в настраиваемой таблице Dataverse. При создании или обновлении метаданных в Dataverse запускается автоматизированный поток облака, вызывающий дальнейшие шаги обработки.
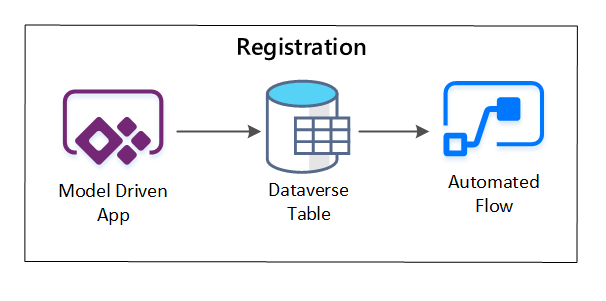
рис. 3. Регистрация актива данных.
Рабочий процесс подготовки или запись метаданных
На этапе рабочего процесса подготовки вы проверяете и сохраняете данные, собранные на этапе регистрации в хранилище метаданных. Выполняются как технические, так и бизнес-проверки, в том числе:
- Проверка входного канала данных
- Активация рабочего процесса утверждения
- Обработка логики для активации сохраняемости метаданных в хранилище метаданных
- Аудит активности
схема рабочего процесса регистрации 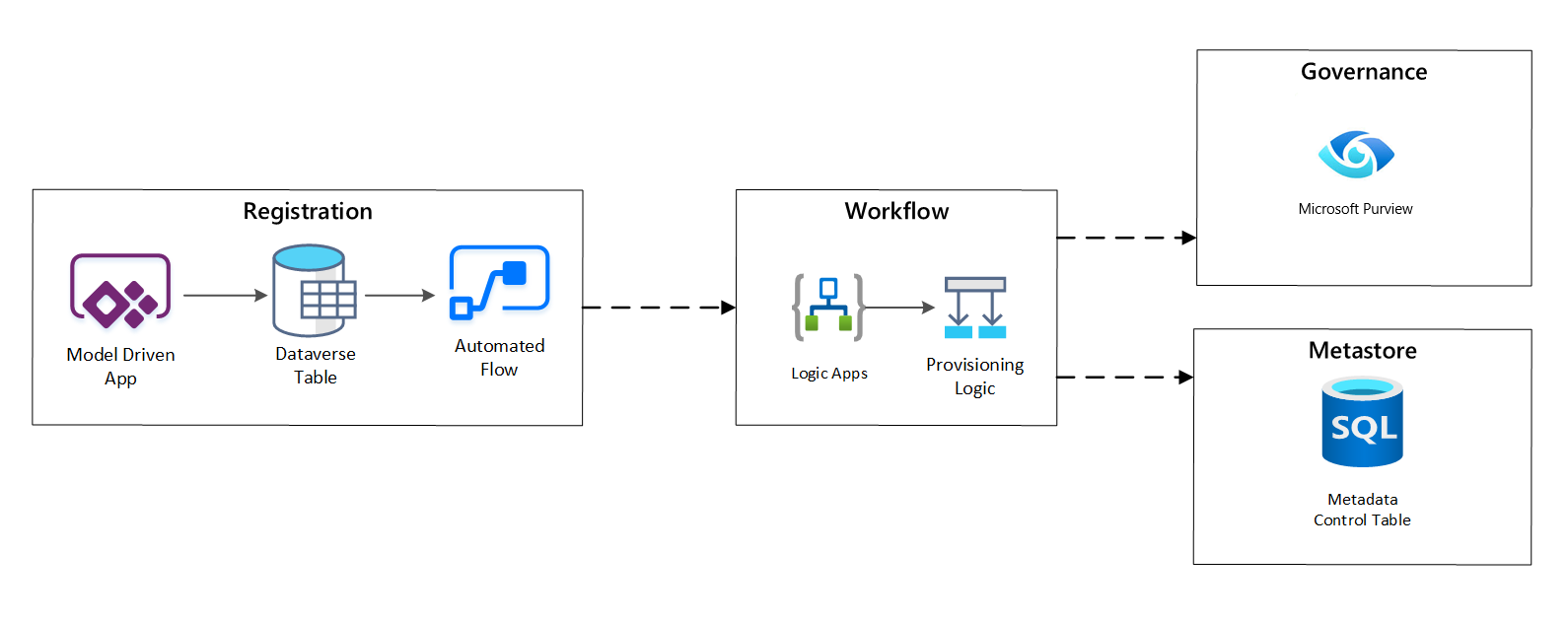
рис. 4. Рабочий процесс регистрации.
После утверждения запросов приема рабочий процесс использует REST API Microsoft Purview для вставки источников в Microsoft Purview.
Подробный рабочий процесс для подключения продуктов данных
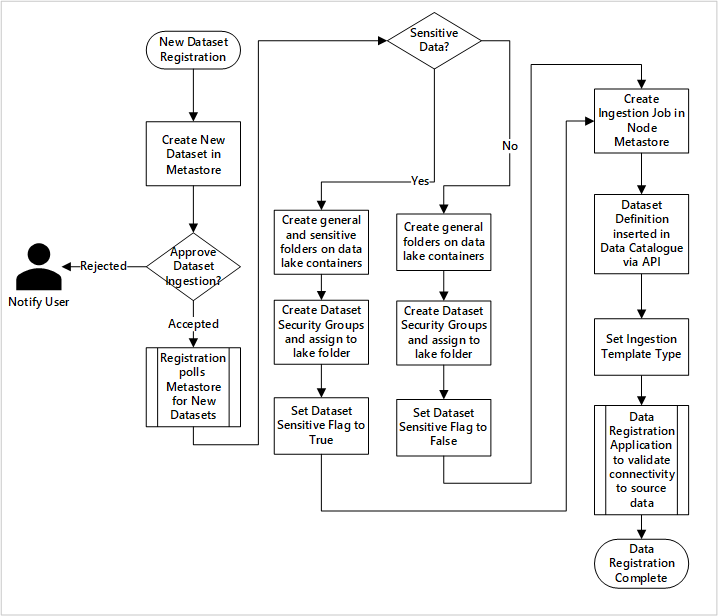
рис. 5. Прием новых наборов данных (автоматизирован).
На рисунке 5 показан подробный процесс регистрации для автоматизации приема новых источников данных:
- Сведения об источнике регистрируются, включая производственные и среду обработки данных.
- Фиксируются ограничения на структуру, формат и качество данных.
- Команды приложений данных следует указать, если данные являются конфиденциальными (Личные данные) Эта классификация управляет процессом создания папок в озере данных для приема необработанных, обогащённых и курируемых данных. Имена источников указывают на необработанные и обогащенные данные, а имена продуктов данных относятся к курируемым данным.
- Основная учетная запись службы и группы безопасности создаются для получения и предоставления доступа к набору данных.
- Задание приема создается в метахранилище Фабрики данных в зоне приземления данных.
- API вставляет определение данных в Microsoft Purview.
- При проверке источника данных и утверждения командой ops подробные сведения публикуются в хранилище метаданных фабрики данных.
Планирование приема
В фабрике данных Azure задачи копирования, управляемые метаданными, обеспечивают функциональность, которая позволяет конвейерам оркестрации управлять строками в таблице управления, хранящейся в базе данных SQL Azure. Средство копирования данных можно использовать для предварительного создания конвейеров, управляемых метаданными.
После создания конвейера ваш процесс подготовки ресурсов добавляет записи в таблицу управления для поддержания приема данных из источников, определенных метаданными регистрации активов данных. Конвейеры Azure Data Factory и база данных Azure SQL с хранилищем метаданных таблицы управления могут находиться в каждой зоне приёма данных, чтобы создавать новые источники данных и загружать их в эти зоны приёма данных.
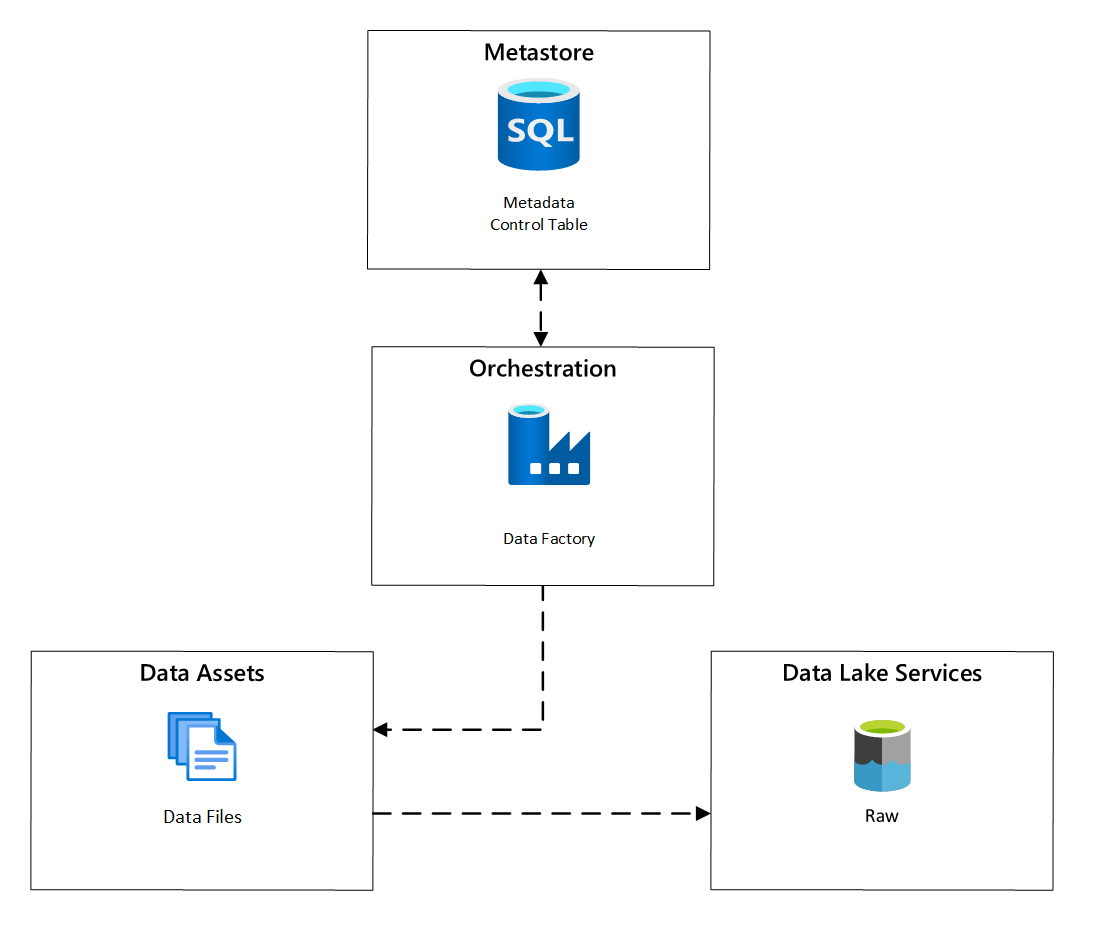
рис. 6. Планирование приема ресурсов данных.
Подробный рабочий процесс приема новых источников данных
На следующей схеме показано, как извлечь зарегистрированные источники данных в хранилище метаданных базы данных SQL Фабрики данных и как данные сначала будут приемированы:
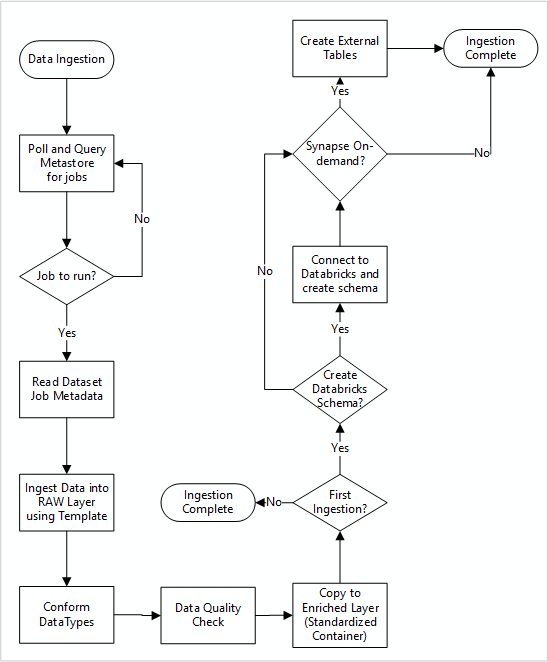
Главный пакет обработки получения данных считывает конфигурации из хранилища метаданных базы данных SQL в Фабрике данных, а затем выполняется итеративно с правильными параметрами. Данные перемещаются из источника в необработанный слой в Azure Data Lake с минимальными или совсем без изменений. Структура данных проверяется на основе вашего хранилища метаданных фабрики данных. Форматы файлов преобразуются в формат Apache Parquet или Avro, а затем копируются в обогащенный слой.
Данные, принимаемые подключаются к рабочей области данных Azure Databricks, а определение данных создается в хранилище метаданных Apache Hive в зоне размещения данных.
Если вам нужно использовать бессерверный пул SQL Azure Synapse для предоставления данных, пользовательское решение должно создавать представления по данным в озере.
Если требуется шифрование на уровне строк или столбцов, пользовательское решение должно размещать данные в озере данных, а затем заносить данные непосредственно во внутренние таблицы в пулах SQL и обеспечивать соответствующую защиту для вычислительных ресурсов пулов SQL.
Захваченные метаданные
При использовании автоматического приема данных можно запрашивать связанные метаданные и создавать панели мониторинга:
- Отслеживайте задания и последние метки времени загрузки данных для продуктов данных, связанных с их функциями.
- Отслеживайте доступные продукты данных.
- Рост объёмов данных.
- Получайте обновления в режиме реального времени о сбоях заданий.
Для отслеживания можно использовать операционные метаданные:
- Задания, шаги задания и их зависимости.
- История и показатели эффективности работы.
- Рост объема данных.
- Сбои заданий.
- Изменения исходных метаданных.
- Бизнес-функции, зависящие от продуктов данных.
Обнаружение данных с помощью REST API Microsoft Purview
REST API Microsoft Purview следует использовать для регистрации данных во время первоначального приема. Вы можете использовать API для отправки данных в каталог данных вскоре после их получения.
Дополнительные сведения см. в том, как использовать REST API Microsoft Purview.
Регистрация источников данных
Используйте следующий вызов API для регистрации новых источников данных:
PUT https://{accountName}.scan.purview.azure.com/datasources/{dataSourceName}
параметры URI для источника данных:
| Имя | Обязательно | Тип | Описание |
|---|---|---|---|
accountName |
Верно | Струна | Имя учетной записи Microsoft Purview |
dataSourceName |
Правда | Струна | Имя источника данных |
Использование REST API Microsoft Purview для регистрации
В следующих примерах показано, как использовать REST API Microsoft Purview для регистрации источников данных с полезной нагрузкой:
Зарегистрировать источник данных Azure Data Lake Storage 2-го поколения:
{
"kind":"AdlsGen2",
"name":"<source-name> (for example, My-AzureDataLakeStorage)",
"properties":{
"endpoint":"<endpoint> (for example, https://adls-account.dfs.core.windows.net/)",
"subscriptionId":"<azure-subscription-guid>",
"resourceGroup":"<resource-group>",
"location":"<region>",
"parentCollection":{
"type":"DataSourceReference",
"referenceName":"<collection-name>"
}
}
}
Регистрация источника данных базы данных SQL:
{
"kind":"<source-kind> (for example, AdlsGen2)",
"name":"<source-name> (for example, My-AzureSQLDatabase)",
"properties":{
"serverEndpoint":"<server-endpoint> (for example, sqlservername.database.windows.net)",
"subscriptionId":"<azure-subscription-guid>",
"resourceGroup":"<resource-group>",
"location":"<region>",
"parentCollection":{
"type":"DataSourceReference",
"referenceName":"<collection-name>"
}
}
}
Заметка
<collection-name>— это текущая коллекция, которая существует в учетной записи Microsoft Purview.
Создать сканирование
Узнайте, как создать учетные данные для проверки подлинности источников в Microsoft Purview перед настройкой и запуском проверки.
Используйте следующий вызов API для сканирования источников данных:
PUT https://{accountName}.scan.purview.azure.com/datasources/{dataSourceName}/scans/{newScanName}/
параметры URI для сканирования:
| Имя | Обязательно | Тип | Описание |
|---|---|---|---|
accountName |
Верно | Струна | Имя учетной записи Microsoft Purview |
dataSourceName |
Правда | Струна | Имя источника данных |
newScanName |
Правда | Струна | Имя новой проверки |
Использование REST API Microsoft Purview для сканирования
В следующих примерах показано, как использовать REST API Microsoft Purview для проверки источников данных с полезными данными:
Сканировать источник данных Azure Data Lake Storage 2-го поколения:
{
"name":"<scan-name>",
"kind":"AdlsGen2Msi",
"properties":
{
"scanRulesetType":"System",
"scanRulesetName":"AdlsGen2"
}
}
Сканировать источник данных базы данных SQL:
{
"name":"<scan-name>",
"kind":"AzureSqlDatabaseMsi",
"properties":
{
"scanRulesetType":"System",
"scanRulesetName":"AzureSqlDatabase",
"databaseName": "<database-name>",
"serverEndpoint": "<server-endpoint> (for example, sqlservername.database.windows.net)"
}
}
Используйте следующий вызов API для сканирования источников данных:
POST https://{accountName}.scan.purview.azure.com/datasources/{dataSourceName}/scans/{newScanName}/run