Настраивайте приложения и базы данных для повышения производительности в управляемом экземпляре SQL Azure.
Область применения:![]() Управляемый экземпляр SQL Azure
Управляемый экземпляр SQL Azure
После того, как вы выявили проблему с производительностью, с которой столкнулись с управляемым экземпляром SQL Azure, эта статья поможет вам в следующем:
- Настройте приложение и примените некоторые рекомендации, которые могут увеличить производительность.
- Настройте базу данных, изменив индексы и запросы, чтобы повысить эффективность работы с данными.
В этой статье предполагается, что вы ознакомились с обзором мониторинга и настройки и мониторингом производительности с помощью хранилища запросов. Кроме того, в этой статье предполагается, что у вас нет проблем с производительностью, связанной с использованием ресурсов ЦП, которые можно устранить, увеличив размер вычислительных ресурсов или уровень служб, чтобы предоставить дополнительные ресурсы управляемому экземпляру SQL.
Примечание.
Аналогичные рекомендации в База данных SQL Azure см. в разделе "Настройка приложений и баз данных для производительности в База данных SQL Azure".
Настройка приложения
В традиционной локальной среде SQL Server процесс изначального планирования загрузки часто отделен от процесса запуска приложения в рабочей среде. Сначала приобретаются лицензии на оборудование и продукт, а затем настраивается производительность. При использовании SQL Azure рекомендуется объединить процессы настройки и запуска приложения. Модель оплаты за мощность по запросу позволяет оптимизировать ваше приложение для использования минимальных ресурсов, необходимых в данный момент, вместо избыточного оснащения оборудования на основе предположительных планов будущего роста приложения, которые часто оказываются ошибочными.
Некоторые пользователи могут предпочесть не настраивать приложение, а вместо этого выделить больше ресурсов оборудования, чем это необходимо. Этот подход может подойти, если вы не желаете изменять ключевое приложение в период высокой нагрузки. Но настройка приложения может свести к минимуму требования к ресурсам и снизить ежемесячные счета.
Рекомендации и антипаттерны в разработке приложений для управляемого экземпляра Azure SQL
Хотя уровни служб Управляемый экземпляр SQL Azure предназначены для повышения стабильности производительности и прогнозируемости приложения, некоторые рекомендации помогут вам настроить приложение, чтобы лучше использовать ресурсы на уровне вычислительных ресурсов. Многие приложения получают значительный прирост производительности после простого перехода на более высокий объем вычислительных ресурсов или уровень служб, в то время как для лучшей работы других приложений на новом уровне требуется дополнительная настройка.
Для повышения производительности приложений со следующими характеристиками необходима дополнительная настройка:
Приложения с низкой производительностью из-за "болтливого" поведения.
Разговорчивые приложения выполняют избыточные операции доступа к данным, чувствительные к задержкам в сети. Возможно, в такие приложения понадобится внести изменения, сократив число операций доступа к данным в базе данных. Например, производительность приложения можно улучшить за счет пакетной обработки нерегламентированных запросов или перемещения запросов в хранимые процедуры. Для получения дополнительной информации см. Пакетные запросы.
Базы данных с интенсивной рабочей нагрузкой, которые не могут работать на одном компьютере.
Базам данных, которые превышают ресурсы наивысшего уровня 'Премиум', может потребоваться масштабирование рабочей нагрузки. Дополнительные сведения см. в разделах Сегментирование баз данных и Функциональное секционирование.
Приложения с неоптимальными запросами
Приложения с плохо настроенными запросами могут не воспользоваться более высоким размером вычислительных ресурсов. Это включает запросы, которые не содержат предложения WHERE, имеют недостающие индексы или устаревшую статистику. Эти приложения выигрывают от стандартных методов оптимизации производительности запросов. Дополнительные сведения см. в разделах Отсутствующие индексы и Настройка запросов и указания на них.
Приложения с неоптимальной схемой доступа к данным
Приложениям, в которых есть проблемы параллельного доступа к данным, например взаимоблокировка, нецелесообразно увеличивать объем вычислительных ресурсов. Рекомендуем уменьшить количество круговых путей к базе данных с помощью кэширования данных на стороне клиента, используя службу кэша Azure или другую технологию кэширования. раздел Кэширование на уровне приложения.
Сведения о предотвращении взаимоблокировок в Управляемом экземпляре SQL Azure см. в руководстве по Взаимоблокировкам.
Настройка базы данных
В этом разделе рассматриваются некоторые методы, которые можно использовать для настройки базы данных с целью повышения производительности приложения и использования наименьшего объема вычислительных ресурсов. Некоторые из этих методов соответствуют традиционным рекомендациям по настройке SQL Server, но другие специфичны для Azure SQL Managed Instance. В некоторых случаях можно изучить потребляемые ресурсы для базы данных, чтобы найти области для дальнейшей оптимизации и расширения традиционных методов SQL Server для работы в Azure SQL Managed Instance.
Выявление и добавление отсутствующих индексов
Одна из распространенных проблем производительности баз данных OLTP связана с физической схемой базы данных. Часто схемы базы данных создаются и поставляются без проверки масштабируемости по нагрузке или объему данных. К сожалению, производительность плана запроса, приемлемая при небольшом масштабе, может существенно снижаться при работе с объемом данных производственного уровня. Самый распространенный источник проблем связан с отсутствием индексов, которые позволили бы сортировать и ограничивать данные в запросе. Часто отсутствие индексов проявляется в виде табличного сканирования, в то время как достаточно выполнения поиска по индексу.
В этом примере в выбранном плане запроса используется сканирование, хотя здесь было бы достаточно поиска.
DROP TABLE dbo.missingindex;
CREATE TABLE dbo.missingindex (col1 INT IDENTITY PRIMARY KEY, col2 INT);
DECLARE @a int = 0;
SET NOCOUNT ON;
BEGIN TRANSACTION
WHILE @a < 20000
BEGIN
INSERT INTO dbo.missingindex(col2) VALUES (@a);
SET @a += 1;
END
COMMIT TRANSACTION;
GO
SELECT m1.col1
FROM dbo.missingindex m1 INNER JOIN dbo.missingindex m2 ON(m1.col1=m2.col1)
WHERE m1.col2 = 4;
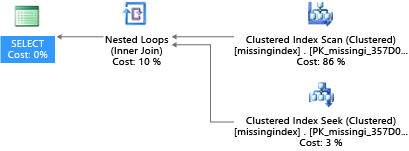
DMV, встроенные в SQL Server с 2005 года, анализируют компиляции запросов, в которых индекс мог бы значительно уменьшить предполагаемые затраты на выполнение запроса. Во время выполнения запроса база данных отслеживает, как часто выполняется каждый план запроса, а также оценивает предполагаемый разрыв между выполняемым планом и планом с существующим индексом. Вы можете использовать эти DMV, чтобы быстро оценить, какие изменения в физическом дизайне базы данных могут улучшить общую стоимость рабочей нагрузки для базы данных и её фактическую рабочую нагрузку.
Этот запрос можно использовать для оценки потенциально отсутствующих индексов:
SELECT
CONVERT (varchar, getdate(), 126) AS runtime
, mig.index_group_handle
, mid.index_handle
, CONVERT (decimal (28,1), migs.avg_total_user_cost * migs.avg_user_impact *
(migs.user_seeks + migs.user_scans)) AS improvement_measure
, 'CREATE INDEX missing_index_' + CONVERT (varchar, mig.index_group_handle) + '_' +
CONVERT (varchar, mid.index_handle) + ' ON ' + mid.statement + '
(' + ISNULL (mid.equality_columns,'')
+ CASE WHEN mid.equality_columns IS NOT NULL
AND mid.inequality_columns IS NOT NULL
THEN ',' ELSE '' END + ISNULL (mid.inequality_columns, '') + ')'
+ ISNULL (' INCLUDE (' + mid.included_columns + ')', '') AS create_index_statement
, migs.*
, mid.database_id
, mid.[object_id]
FROM sys.dm_db_missing_index_groups AS mig
INNER JOIN sys.dm_db_missing_index_group_stats AS migs
ON migs.group_handle = mig.index_group_handle
INNER JOIN sys.dm_db_missing_index_details AS mid
ON mig.index_handle = mid.index_handle
ORDER BY migs.avg_total_user_cost * migs.avg_user_impact * (migs.user_seeks + migs.user_scans) DESC
В этом примере результатом выполнения запроса было предложено следующее:
CREATE INDEX missing_index_5006_5005 ON [dbo].[missingindex] ([col2])
После его создания инструкция SELECT выбирает другой план, в котором используется поиск вместо сканирования, а затем выполняет план более эффективно.
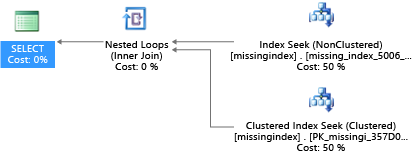
Основная идея заключается в том, что возможности ввода-вывода общей, стандартной системы более ограничены, чем у выделенного серверного устройства. Необходимо минимизировать избыточное количество операций ввода-вывода, чтобы максимально использовать ресурсы для каждого размера вычисления, доступные в рамках уровней сервисов. Улучшение физической схемы базы данных может значительно уменьшить задержку для определенных запросов, улучшить пропускную способность при параллельных запросах, обрабатываемых на единицу масштабирования, и минимизировать затраты, необходимые на выполнение одного запроса.
Дополнительные сведения о настройке индексов с помощью запросов отсутствующих индексов см. в статье Настройка некластеризованных индексов с предложениями отсутствующих индексов.
Настройка запросов и подача подсказок
Оптимизатор запросов в Управляемый экземпляр SQL Azure аналогичен традиционному оптимизатору запросов SQL Server. Большинство рекомендаций по настройке запросов и понимания ограничений модели логики для оптимизатора запросов также применяются к управляемому экземпляру SQL Azure. Если вы настраиваете запросы в Управляемый экземпляр SQL Azure, вы можете воспользоваться дополнительным преимуществом снижения совокупного спроса на ресурсы. Ваше приложение может работать дешевле, чем нетюненый эквивалент, поскольку оно может работать с меньшим объемом вычислительных ресурсов.
Пример, распространенный в SQL Server и также применимый к Управляемому экземпляру Azure SQL, заключается в том, как оптимизатор запросов определяет параметры. Во время компиляции оптимизатор запросов вычисляет текущее значение параметра с целью создания более оптимального плана запроса. Хотя эта стратегия часто может привести к плану запроса, который значительно быстрее, чем план, скомпилированный без известных значений параметров, в настоящее время она работает несовершенно в Azure SQL Managed Instance. (Новая функция интеллектуальной производительности запросов, представленная в SQL Server 2022, под названием Оптимизация плана чувствительности к параметрам, устраняет сценарий, при котором один кэшированный план для параметризованного запроса не является оптимальным для всех возможных входных значений параметров. В настоящее время оптимизация плана чувствительности к параметрам недоступна в Управляемом экземпляре SQL Azure.)
Иногда параметр не подвержен поиску, а иногда он подвержен, но созданный план является неоптимальным для полного набора значений параметров в нагрузке. Microsoft добавляет указания запросов (директивы), чтобы вы могли более точно задавать намерение и изменять поведение по умолчанию при обработке параметров. Вы можете использовать подсказки, если поведение по умолчанию несовершенно для определенной рабочей нагрузки клиента.
В следующем примере показано, как обработчик запросов может создать план, который не соответствует требованиям к производительности и ресурсам. В этом примере также показано, что при использовании указания запроса можно сократить время выполнения запроса и снизить требования к ресурсам для базы данных.
DROP TABLE psptest1;
CREATE TABLE psptest1(col1 int primary key identity, col2 int, col3 binary(200));
DECLARE @a int = 0;
SET NOCOUNT ON;
BEGIN TRANSACTION
WHILE @a < 20000
BEGIN
INSERT INTO psptest1(col2) values (1);
INSERT INTO psptest1(col2) values (@a);
SET @a += 1;
END
COMMIT TRANSACTION
CREATE INDEX i1 on psptest1(col2);
GO
CREATE PROCEDURE psp1 (@param1 int)
AS
BEGIN
INSERT INTO t1 SELECT * FROM psptest1
WHERE col2 = @param1
ORDER BY col2;
END
GO
CREATE PROCEDURE psp2 (@param2 int)
AS
BEGIN
INSERT INTO t1 SELECT * FROM psptest1 WHERE col2 = @param2
ORDER BY col2
OPTION (OPTIMIZE FOR (@param2 UNKNOWN))
END
GO
CREATE TABLE t1 (col1 int primary key, col2 int, col3 binary(200));
GO
Код установки создает таблицу, в которой данные распределены нерегулярно, в таблице t1. Оптимальный план запроса зависит от выбранного параметра. К сожалению, при кэшировании плана запрос не всегда повторно компилируется в зависимости от наиболее подходящего значения параметра. Возможно, что будет кэширован неоптимальный план, который будет использоваться для многих значений, даже если в среднем другой план был бы более удачным выбором. После этого план запроса создает две хранимые процедуры, которые идентичны друг другу, за исключением того, что одна из них содержит специальное указание запроса.
-- Prime Procedure Cache with scan plan
EXEC psp1 @param1=1;
TRUNCATE TABLE t1;
-- Iterate multiple times to show the performance difference
DECLARE @i int = 0;
WHILE @i < 1000
BEGIN
EXEC psp1 @param1=2;
TRUNCATE TABLE t1;
SET @i += 1;
END
Прежде чем приступать ко второй части примера, мы советуем подождать около 10 минут, чтобы в итоговых данных телеметрии результаты были очевидными.
EXEC psp2 @param2=1;
TRUNCATE TABLE t1;
DECLARE @i int = 0;
WHILE @i < 1000
BEGIN
EXEC psp2 @param2=2;
TRUNCATE TABLE t1;
SET @i += 1;
END
Каждая часть этого примера пытается выполнить параметризованную вставку 1000 раз (чтобы создать достаточную нагрузку для использования в качестве тестового набора данных). При выполнении хранимых процедур обработчик запросов проверяет значение параметра, переданное в процедуру во время её первой компиляции ("анализа параметров"). Обработчик кэширует результирующий план и использует его в дальнейшем, даже если значение параметра будет другим. Оптимальный план может подойти не для всех случаев. Иногда нужно указывать оптимизатору, какой план выбрать, чтобы этот план был относительно универсальным, а не просто подходящим для определенного случая, когда впервые происходит компиляция запроса. В этом примере изначальный план создает сканирование, при котором считываются все строки, чтобы найти значение, которое отвечает параметру.

Поскольку мы выполнили процедуру, используя значение 1, результирующий план был оптимальным для значения 1, но был менее оптимальным для всех остальных значений в таблице. Если вы будете выбирать каждый план случайным образом, скорее всего, результат не будет оптимальным, так как план будет выполняться медленнее и задействовать больше ресурсов.
При выполнении теста с параметром SET STATISTICS IO со значением ON логическое сканирование в этом примере будет проходить в фоновом режиме. Вы можете увидеть, что план выполнил 1148 операций чтения (что является неэффективным, если обычно нужно вернуть только одну строку).

Во второй части примера используется указание запроса, которое позволяет дать оптимизатору инструкцию использовать конкретное значение во время компиляции. В этом случае обработчик запросов принудительно игнорирует значение, которое передается в качестве параметра, и вместо этого использует значение UNKNOWN. Это значение со средней частотой в таблице (независимо от искажения распределения). В результате мы получим план на основе поиска, который работает быстрее и использует меньше ресурсов, чем план из части 1 этого примера.
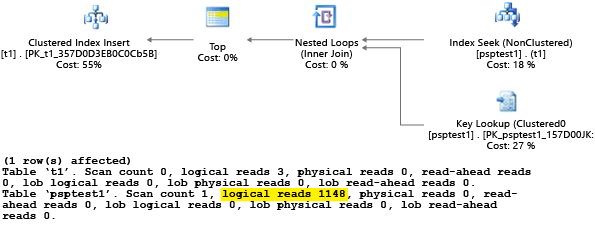
Вы можете увидеть эффект в представлении системного каталога sys.server_resource_stats. Данные собираются, агрегируются и обновляются в течение 5–10 минут. Для каждых 15 секунд отчета выделяется одна строка. Например:
SELECT TOP 1000 *
FROM sys.server_resource_stats
ORDER BY start_time DESC
Вы можете проверить sys.server_resource_stats , использует ли ресурс для теста больше или меньше ресурсов, чем другой тест. При сравнении данных разделите время тестов, чтобы они не были в одном 5-минутном окне в представлении sys.server_resource_stats . Цель расчетов — минимизировать общее использование ресурсов, а не пиковую нагрузку. Обычно оптимизация части кода с целью уменьшения задержки выполнения также приводит к сокращению использования ресурсов. Убедитесь, что изменения, внесенные в приложение, необходимы и не оказывают негативного влияния на пользовательский опыт для тех, кто может использовать подсказки запросов в приложении.
Если рабочая нагрузка содержит ряд повторяющихся запросов, то часто бывает целесообразно отследить и проверить оптимальность планов, так как это позволит уменьшить минимальный размер ресурсов, необходимых базе данных. После утверждения, периодически пересматривайте планы, чтобы убедиться, что они не ухудшились. Дополнительные сведения об указаниях запроса (Transact-SQL) см. в этой статье.
Лучшие практики для архитектуры очень больших баз данных в Azure SQL Managed Instance
В следующих двух разделах рассматриваются два варианта решения проблем с очень большими базами данных в Управляемом экземпляре SQL Azure.
Шардинг между базами данных
Так как Управляемый экземпляр SQL Azure работает на сырьевых оборудованиях, ограничения емкости для отдельной базы данных ниже, чем для традиционной локальной установки SQL Server. Некоторые клиенты используют техники шардинга для распределения операций базы данных по нескольким базам данных, когда операции не помещаются в пределах ограничений одной базы данных в Управляемом экземпляре SQL Azure. Большинство клиентов, использующих методы шардеринга в Управляемом экземпляре SQL Azure, разделяют свои данные по одному измерению на несколько баз данных. При использовании этого подхода необходимо понимать, что часто приложения OLTP выполняют транзакции, которые применимы только к одной строке или небольшой группе строк внутри одной схемы.
Например, если в базе данных есть имя клиента, заказ и детали заказа (например, в базе данных AdventureWorks), эти данные можно разделить на несколько баз данных, сгруппировав клиента с соответствующим заказом и информацией о деталях заказа. Это гарантирует, что данные клиента останутся в пределах отдельной базы данных. Приложение должно разбивать заказчиков по разным базам данных и эффективно распределять нагрузку. С сегментированием клиенты не только могут избежать максимального ограничения размера базы данных, но и Управляемый экземпляр SQL Azure также могут обрабатывать рабочие нагрузки, которые значительно больше ограничений различных размеров вычислительных ресурсов, если каждая отдельная база данных соответствует ограничениям уровня служб.
Несмотря на то что сегментирование баз данных не снижает общую нагрузку для решения, такой подход очень эффективен для поддержки очень больших решений, распределенных по нескольким базам данных. Каждую базу данных можно запускать с разным объемом вычислительных ресурсов для поддержки очень больших "эффективных" баз данных с высокими требованиями к ресурсам.
Функциональное секционирование
Пользователи часто объединяют несколько функций в отдельной базе данных. Например, если приложение содержит логику управления запасами склада, то база данных может содержать логику, связанную с запасами, отслеживанием заказов на покупку, хранимыми процедурами, индексированными или материализованными представлениями для управления ежемесячными отчетами. Такой подход позволяет легко администрировать базы данных и выполнять такие операции, как резервное копирование. Однако в этом случае нужно также изменить размер оборудования, чтобы распределять пиковую нагрузку функций одного приложения.
Используя архитектуру горизонтального масштабирования в управляемом экземпляре SQL Azure, рекомендуется разделить различные функции приложения на отдельные базы данных. При использовании этого метода каждое приложение масштабируется независимо. По мере повышения нагрузки на приложение (и нагрузки на базу данных) администратор сможет определить объемы вычислительных ресурсов отдельно для каждой функции одного приложения. В предельном случае, такая архитектура позволяет приложению быть больше, чем может обработать одна стандартная машина, поскольку нагрузка распределяется по многим машинам.
Пакетные запросы
Для приложений, которые получают доступ к данным с использованием частых нерегламентированных запросов большого объема, время отклика значительно увеличивается за счет взаимодействия по сети между уровнем приложения и уровнем базы данных. Даже если приложение и база данных находятся в одном центре обработки данных, сетевая задержка между ними может увеличиться пропорционально количеству операций доступа к данным. Чтобы уменьшить количество циклических операций доступа к данным, попробуйте выполнить пакетную обработку нерегламентированных запросов или скомпилировать их в качестве хранимых процедур. Если выполнить пакетную обработку нерегламентированных запросов, несколько запросов будут отсылаться как один большой пакет в базу данных за одну операцию. Выполнив компилирование нерегламентированных запросов в одну хранимую процедуру, можно достигнуть того же результата, что и при пакетной обработке. Использование хранимой процедуры также позволяет расширить возможности кэширования планов запросов в базе данных, чтобы снова использовать хранимую процедуру.
Некоторые приложения требуют большого количества операций записи. Иногда можно уменьшить общую нагрузку операций ввода-вывода на базы данных путем правильной пакетной обработки операций записи. Часто это так же просто, как использование явных транзакций вместо автоматических транзакций в хранимых процедурах и нерегламентированных пакетах. Оценку различных подходов см. в статье Методы пакетирования для приложений баз данных в Azure. Поэкспериментируйте со своей рабочей нагрузкой, чтобы найти оптимальную модель пакетной обработки. Необходимо учитывать, что гарантии согласованности транзакций разных моделей могут немного отличаться. Чтобы определить наиболее оптимальную рабочую нагрузку, которая минимизирует использование ресурсов, необходимо добиться правильного сочетания компромиссов согласованности и производительности.
Кэширование на уровне приложения
Некоторые приложения базы данных имеют нагруженные чтением рабочие нагрузки. Уровни кэширования могут снизить нагрузку на базу данных и потенциально уменьшить объем вычислительных ресурсов, необходимых для поддержки базы данных с помощью использования Управляемого экземпляра SQL Azure. Кэш Azure для Redis Если у вас есть рабочая нагрузка с большим объемом чтения, данные можно считывать один раз (или, возможно, один раз на компьютер уровня приложений в зависимости от того, как он настроен), а затем хранить эти данные за пределами базы данных. Это способ уменьшения нагрузки базы данных (ЦП и операций ввода-вывода), но существует влияние на согласованность транзакций, так как данные, считываемые из кэша, могут быть не синхронизированы с данными в базе данных. Для многих приложений определенный уровень несогласованности приемлем, однако это подходит не для всех рабочих нагрузок. Мы советуем внимательно изучить требования к приложению, прежде чем использовать стратегию кэширования на уровне приложения.
Связанный контент
- Модель приобретения виртуальных ядер — Управляемый экземпляр SQL Azure
- Настройка параметров tempdb для Управляемого экземпляра Azure SQL
- Мониторинг производительности Microsoft Azure SQL Управляемый экземпляр с помощью динамических управляемых представлений
- Настройка некластеризованных индексов с учетом предложений по отсутствующим индексам
- Мониторинг Управляемого экземпляра SQL Azure с помощью Azure Monitor