Общие сведения о группах отказоустойчивости и рекомендации по их использованию — SQL Azure Управляемый экземпляр
Область применения:![]() Управляемый экземпляр SQL Azure
Управляемый экземпляр SQL Azure
Функция групп аварийного переключения позволяет управлять репликацией и аварийным переключением всех баз данных пользователей в управляемом экземпляре в другой регион в Azure. В этой статье представлен обзор функции группы автоматического переключения с передовыми методами и рекомендациями по использованию с Управляемым экземпляром SQL Azure.
Чтобы приступить к работе с функцией, ознакомьтесь с разделом Настройка группы отработки отказа для управляемого экземпляра Azure SQL.
Обзор
Функция групп переключения при отказе позволяет управлять репликацией и переключением при отказе пользовательских баз данных из управляемого экземпляра в другой управляемый экземпляр в другом регионе Azure. Группы аварийного переключения предназначены для упрощения развертывания и управления базами данных с георепликацией на уровне предприятия.
Дополнительные сведения см. в разделе "Высокий уровень доступности" для Управляемый экземпляр SQL Azure. Сведения о географической отработки отказа RPO и RTO см. в обзоре непрерывности бизнес-процессов.
Перенаправление конечных точек
Группы отработки отказа предоставляют конечные точки прослушивания для чтения и записи, а также для чтения, которые остаются неизменными во время геоотказов. Вам не нужно изменять строку подключения для вашего приложения после геоотказа, поскольку подключения автоматически направляются к текущему первичному серверу. Гео-переключение переводит все вторичные базы данных в группе на основную роль. После завершения георезервирования запись DNS автоматически обновляется для перенаправления конечных точек в новый регион.
Разгрузка рабочих нагрузок, доступных только для чтения
Чтобы снизить объем трафика к основным базам данных, можно также использовать вторичные базы данных в группе отказоустойчивости для разгрузки рабочих нагрузок только для чтения. Используйте слушателя только для чтения, чтобы направить трафик на вторичную базу данных, доступную для чтения.
Восстановление приложения
Добавление региональной избыточности баз данных — это только часть решения для обеспечения полноценной непрерывности бизнес-процессов. Для комплексного восстановления приложения (службы) после катастрофического сбоя необходимо восстановить все компоненты, из которых состоит служба и все зависимые службы. К примерам этих компонентов относятся клиентское программное обеспечение (например, браузер с пользовательским кодом JavaScript), интерфейсные веб-серверы, хранилище и DNS. Важно, чтобы все компоненты были устойчивы к одинаковым сбоям и становятся доступными в течение целевого времени восстановления (RTO) приложения. Следовательно, необходимо определить все зависимые службы и получить сведения о гарантиях и возможностях, которые они предоставляют. Затем необходимо выполнить соответствующие действия, чтобы обеспечить работу службы во время переключения на резервные услуги, на которые она опирается.
Политика отработки отказа
Группы отработки отказа поддерживают две политики отработки отказа:
-
Управление клиентом (рекомендуется). Клиенты могут выполнять отработку отказа группы, когда они замечают непредвиденный сбой, влияющий на одну или несколько баз данных в группе отработки отказа. При использовании таких инструментов командной строки, как PowerShell, Azure CLI или Rest API, значение политики отработки отказа для управляемого клиентом —
manual. -
Управляет Майкрософт - В случае масштабного сбоя, который непосредственно затрагивает основной регион, Майкрософт инициирует переключение всех затронутых групп аварийного переключения, для которых политика аварийного переключения настроена на управление со стороны Майкрософт. Отказоустойчивость под управлением Майкрософт не будет запущена для отдельных групп отказоустойчивости или их подмножеств в пределах региона. При использовании таких средств командной строки, как PowerShell, Azure CLI или Rest API, значение политики отработки отказа для управляемого Microsoft — это
automatic.
Каждая политика переключения на резерв имеет уникальный набор вариантов использования и соответствующие ожидания по вопросам переключения и уровню потерь данных, как показано в следующей таблице.
| Политика переключения на резервный источник | Область резервного переключения | Вариант использования | Потенциальная потеря данных |
|---|---|---|---|
| Управление клиентом (Рекомендуется) |
Группы резервирования | Одна или несколько баз данных в группе отработки отказа подвержены сбою и становятся недоступными. Вы можете переключиться на резерв. | Да |
| Организуется корпорацией Майкрософт | Все группы переключения при отказе в регионе | Широко распространенный сбой в центре обработки данных, зоне доступности или регионе приводит к недоступности баз данных, а команда службы SQL Microsoft Azure решает выполнить принудительную операцию отказоустойчивости. Используйте этот параметр только в том случае, если вы хотите делегировать ответственность за аварийное восстановление Microsoft, а приложение допускает время простоя (RTO) не менее одного часа. |
Да |
Управляемые клиентом
В редких случаях встроенная доступность или высокий уровень доступности недостаточно, чтобы устранить сбой, и базы данных в группе отработки отказа могут быть недоступны в течение длительности, которая не является приемлемой для соглашения об уровне обслуживания (SLA) приложений, использующих базы данных. Базы данных могут быть недоступны из-за локализованной проблемы, влияющей только на несколько баз данных, или это может быть в центре обработки данных, зоне доступности или на уровне региона. В любом из этих случаев для восстановления непрерывности бизнеса можно инициировать принудительное переключение.
Настройка политики резервирования к управляемой клиентом настоятельно рекомендуется, так как она позволяет вам контролировать момент инициирования переключения на резервный узел и восстановления бизнес-процессов. Вы можете инициировать переключение на резерв, когда заметите непредвиденный сбой, влияющий на одну или несколько баз данных в группе отказоустойчивости.
Организуется корпорацией Майкрософт
С политикой автоматизированной отработки отказа от Microsoft, ответственность за аварийное восстановление передается службе Azure SQL. Чтобы служба SQL Azure начала принудительная отработка отказа, должны выполняться следующие условия:
- Затронуты неполадки центра обработки данных, зоны доступности или уровня региона, вызванные событием стихийных бедствий, изменениями конфигурации, ошибками программного обеспечения или аппаратными компонентами и многими базами данных в регионе.
- Льготный период истек. Так как проверка масштаба и устранение последствий сбоя зависит от человеческих действий, льготный период не может быть установлен ниже одного часа.
При выполнении этих условий служба SQL Azure инициирует принудительный отказ для всех групп переключения на отказ в регионе, для которых задана политика переключения на отказ, управляемая Microsoft.
Внимание
Используйте управляемую клиентом политику отказоустойчивости для тестирования и реализации плана аварийного восстановления. Не полагайтесь на отказоустойчивость, управляемую Microsoft, которая может быть задействована только в чрезвычайных обстоятельствах. Отказоустойчивость, управляемая Microsoft, будет начата для всех групп отработки отказа в регионе, где политика отказа установлена как управляемая Microsoft. Инициировать это невозможно для отдельной группы переключения при отказе. Если вам нужна возможность частичной отработки отказа группы резервирования, используйте политику отказоустойчивости под управлением клиента.
Установите политику отработки отказа, управляемую Майкрософт, только в следующих случаях:
- Вы хотите делегировать ответственность за аварийное восстановление службе SQL Azure.
- Приложение может нормально работать, если база данных будет недоступна в течение как минимум одного часа или более.
- Можно активировать принудительные переключения на резерв некоторое время после истечения льготного периода, так как фактическое время принудительного переключения может существенно различаться.
- Допустимо, что все базы данных в группе отработки отказа могут перейти на резервный сервер, независимо от конфигурации зональной избыточности или статуса доступности. Хотя базы данных, настроенные для избыточности зоны, устойчивы к зональным сбоям и могут не пострадать от сбоя, они всё равно перейдут в режим отработки отказа, если они являются частью группы отработки отказа с политикой отработки отказа, управляемой Microsoft.
- Допустимо проводить принудительную отработку отказа баз данных в группе отработки отказа, не принимая во внимание зависимость приложения от других служб или компонентов Azure, что может привести к снижению производительности или недоступности приложения.
- Допустимо иметь неизвестную потерю данных, так как точное время принудительного переключения невозможно контролировать, и это игнорирует состояние синхронизации резервных баз данных.
- Все основные и вторичные базы данных в группе автоматического переключения и все связи георепликации находятся на одном уровне обслуживания, слое вычислений (выделенный или бессерверный) и размер вычислительных ресурсов (DTU или виртуальные ядра). Если цель уровня обслуживания (SLO) всех баз данных не совпадает, то политика отработки отказа в конечном итоге будет обновлена с управляемой Microsoft на управляемую клиентом через службу Azure SQL.
Когда корпорация Майкрософт инициирует отработку отказа, в журнал действий Azure Monitor добавляется запись с именем операции отработки отказа группы резервирования Azure SQL. Запись содержит имя группы отработки отказа в разделе "Ресурс" и событие, инициированное отображением одного дефиса (-), чтобы указать, что отработка отказа была инициирована корпорацией Майкрософт. Эту информацию также можно найти на странице журнала действий нового основного сервера или экземпляра в портале Azure.
Терминология и возможности
Группа автоматического переключения (FOG)
Группа отработки отказа позволяет всем пользовательским базам данных в управляемом экземпляре выполнить отработку отказа как единый блок в другой регион Azure в случае недоступности основного управляемого экземпляра из-за сбоя в основном регионе. Так как группы отработки отказа для Управляемого экземпляра SQL содержат все пользовательские базы данных в экземпляре, для экземпляра можно настроить только одну группу отработки отказа.
Внимание
Имя группы отказоустойчивости должно быть уникальным в глобальном масштабе в пределах домена
.database.windows.net.Основной
Управляемый экземпляр, на котором размещаются основные базы данных в группе аварийного восстановления.
Вторичные
Управляемый экземпляр, на котором размещаются вторичные базы данных в группе переключения на резервный ресурс. Дополнительный объект не может находиться в том же регионе Azure, что и основной.
Внимание
Если база данных содержит объекты OLTP в памяти, основной и вторичный экземпляры геореплики должны иметь одинаковые уровни обслуживания, так как объекты OLTP находятся в памяти. Более низкий уровень служб в экземпляре геореплики может привести к проблемам нехватки памяти. В этом случае вторичная реплика может не восстановить базу данных, что приведет к недоступности вторичной базы данных вместе с объектами OLTP, хранящимися в памяти, на гео-вторичной. Это, в свою очередь, может привести к неудачному переключению при отказе. Чтобы избежать этого, убедитесь, что уровень службы гео-вторичной инстанции соответствует уровню службы основной базы данных. Обновления уровня служб могут быть операциями, зависящими от объёма данных, и могут занимать значительное время.
Отработка отказа (без потери данных)
Резервное переключение выполняет полную синхронизацию данных между основной и вторичной базами данных перед тем, как вторичная переключится на основную роль. Это гарантирует отсутствие потери данных. Отказоустойчивость возможна только в том случае, если основной сервер доступен. Фейловер используется в следующих сценариях:
- Проведение учений по аварийному восстановлению в рабочей среде, если потеря данных невозможна
- Перемещение рабочей нагрузки в другой регион
- Верните рабочую нагрузку в основной регион после устранения сбоя (возврат к основному размещению)
Принудительное переключение (потенциальная потеря данных)
Принудительное переключение немедленно переключает вторичную роль на основную, не ожидая недавних изменений, которые будут распространяться из первичной. Эта операция может привести к потенциальной потере данных. Принудительное переключение используется как метод восстановления во время сбоев, когда основной сервер недоступен. Как только сбой будет устранен, прежний основной узел автоматически подключится и станет новым вторичным узлом. Переключение на резерв может выполняться для возврата, возвращая реплики в их исходные первичные и вторичные роли.
Льготный период с потерей данных
Так как данные реплицируются во вторичный с помощью асинхронной репликации, принудительное переключение групп с политиками управления переключением, которые заданы Майкрософт, может привести к потере данных. Вы можете настроить политику отказоустойчивости, чтобы отразить допустимый уровень потери данных для приложения. Настроив
GracePeriodWithDataLossHours, вы можете контролировать длительность ожидания службы SQL Azure перед началом принудительного переключения, что может привести к потере данных.
Зона DNS
Уникальный идентификатор, который автоматически создается при создании нового управляемого экземпляра SQL. Сертификат с несколькими доменами (SAN) для этого экземпляра подготавливается для проверки подлинности клиентских подключений к любому экземпляру в той же зоне DNS. Два управляемых экземпляра в одной группе отработки отказа должны иметь общий доступ к зоне DNS.
Прослушиватель для чтения и записи в группе отказоустойчивости
Запись DNS CNAME, которая указывает на текущий основной. Он создается автоматически при создании группы переключения и позволяет нагрузке чтения и записи автоматически пересоединяться к первичному, когда происходит переключение после отработки отказа. При создании группы переключения на резервный ресурс в управляемом экземпляре SQL формируется DNS-запись CNAME для URL-адреса прослушивателя следующим образом:
<fog-name>.<zone_id>.database.windows.net.Прослушиватель группы отработки отказа (только для чтения)
Запись CNAME DNS, которая указывает на текущий вторичный сервер. Он создается автоматически при создании группы отработки отказа и позволяет рабочей нагрузке SQL только для чтения прозрачно подключаться к вторичной, когда вторичные изменения после отработки отказа. При создании группы отработки отказа в управляемом экземпляре SQL формируется запись CNAME DNS для URL-адреса прослушивателя в следующем виде:
<fog-name>.secondary.<zone_id>.database.windows.net. По умолчанию отказоустойчивость прослушивателя для чтения отключена, так как это гарантирует, что производительность основного сервера не будет затронута, если вторичный сервер не в сети. Однако это также означает, что сеансы только для чтения не смогут подключиться, пока вторичный сервер не будет восстановлен. Если вы не можете терпеть простой для сеансов только для чтения и можете использовать основной ресурс как для трафика только для чтения, так и для чтения и записи за счет потенциального снижения его производительности, тогда можно включить переключение на резерв для прослушивателя только для чтения, настроив свойствоAllowReadOnlyFailoverToPrimary. В этом случае трафик только для чтения автоматически перенаправляется в основной, если вторичный недоступен.Примечание.
Свойство
AllowReadOnlyFailoverToPrimaryдействует только в том случае, если включена политика аварийного переключения Майкрософт, и активировано принудительное аварийное переключение. В этом случае, если свойство имеет значение True, новый основной будет обслуживать как сеансы для чтения и записи, так и сеансы только для чтения.
Архитектура группы резервирования
Группу аварийного переключения необходимо настроить на основном экземпляре, чтобы подключить его к вторичному экземпляру в другом регионе Azure. Все пользовательские базы данных в экземпляре будут реплицированы в резервный экземпляр. Системные базы данных, такие как master и msdb не будут реплицированы.
На следующей схеме показана типичная конфигурация облачного приложения с георезервированием, использующего управляемый экземпляр и группу отказоустойчивости.
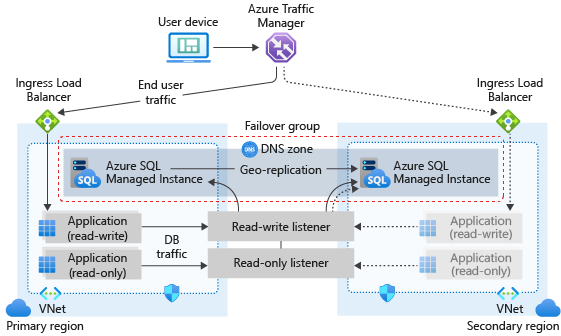
Если ваше приложение использует Управляемый экземпляр SQL в качестве уровня данных, придерживайтесь следующих общих рекомендаций, приведенных в этой статье, при разработке для обеспечения непрерывности бизнес-процессов.
Создание гео-вторичного экземпляра
Чтобы обеспечить непрерывное подключение к основному экземпляру SQL с управлением после переключения на резервный узел, первичный и вторичный экземпляры должны находиться в одной зоне DNS. Это гарантирует, что один и тот же мультидоменный (SAN) сертификат можно использовать для аутентификации клиентских подключений к одному из двух экземпляров в резервной группе. Когда ваше приложение будет готово к развертыванию в рабочей среде, создайте вторичный управляемый экземпляр SQL в другом регионе и убедитесь, что он использует ту же зону DNS, что и основной управляемый экземпляр SQL. Это можно сделать, указав необязательный параметр во время создания. Если вы используете PowerShell или REST API, это имя необязательного параметра DNSZonePartner. Имя соответствующего необязательного поля на портале Azure — Первичный управляемый экземпляр.
Внимание
Первый управляемый экземпляр, созданный в подсети, определяет зону DNS для всех последующих экземпляров в той же подсети. Это означает, что два экземпляра из одной подсети не могут принадлежать разным зонам DNS.
Дополнительные сведения о создании вторичного управляемого экземпляра SQL в той же зоне DNS, что и основной экземпляр, см. в разделе Настройка группы отработки отказа для управляемого экземпляра SQL Azure.
Использование сопряженных регионов
Разверните оба управляемых экземпляра в парные регионы, чтобы обеспечить лучшую производительность. Группы отработки отказа Управляемого экземпляра SQL в сопряженных регионах характеризуются лучшей производительностью, чем группы отработки отказа в несопряженных регионах.
Управляемый экземпляр SQL Azure придерживается безопасной практики развертывания, согласно которой парные регионы Azure, как правило, не развертываются одновременно. Однако не удается предсказать, какой регион будет обновлен первым, поэтому порядок развертывания не гарантируется. Иногда основной экземпляр сначала обновляется, а иногда и вторичный экземпляр обновляется сначала.
В ситуациях, когда Управляемый экземпляр SQL Azure входит в группу переключения при сбое, а экземпляры в группе не находятся в сопряжённых регионах Azure, выберите разные расписания периода обслуживания для основной базы данных и резервной базы данных. Например, выберите окно обслуживания буднего дня для вашей гео-вторичной базы данных и окно обслуживания на выходных для вашей гео-первичной базы данных.
Включите и оптимизируйте поток трафика георепликации между инстанциями
Подключение между подсетями виртуальной сети, размещающими первичный и вторичный экземпляр, должно быть установлено и поддерживаться для обеспечения непрерывного потока трафика георепликации. Существует несколько способов обеспечить подключение между экземплярами, которые можно выбрать в зависимости от топологии сети и политик:
Глобальный пиринг виртуальных сетей (VNet пиринг) — это рекомендуемый способ установить подключение между двумя экземплярами в группе отработки отказа. Он обеспечивает частное подключение с низкой задержкой и высокой пропускной способностью между пиринговыми виртуальными сетями с помощью инфраструктуры магистральной сети Майкрософт. В обмене данными между пиринговых виртуальных сетей не требуется общедоступный Интернет, шлюзы или дополнительное шифрование.
Начальный засев
При создании группы отработки отказа между управляемыми экземплярами выполняется начальный этап заполнения данных перед началом репликации. Начальный этап заполнения является самой длинной и самой дорогой частью операции. После завершения начального заполнения данные синхронизируются, и только последующие изменения данных реплицируются. Время завершения начального заполнения зависит от размера данных, количества реплицированных баз данных, интенсивности рабочей нагрузки в базах данных-источниках и скорости связи между виртуальными сетями, в которых размещается первичный и вторичный экземпляр, в основном зависит от способа установления подключения. В обычных условиях и при установлении подключения с использованием рекомендуемого пиринга глобальной виртуальной сети, скорость заполнения достигает до 360 ГБ в час для управляемого экземпляра SQL. Инициализация выполняется параллельно для группы пользовательских баз данных — не обязательно одновременно для всех баз данных. При наличии множества баз данных, размещенных в экземпляре, может потребоваться несколько пакетов.
Если скорость соединения между двумя экземплярами ниже необходимой, время для начальной загрузки, вероятно, будет заметно увеличено. Вы можете использовать указанные скорость заполнения, число баз данных, общий размер данных и скорость связи, чтобы определить, как долго будет выполняться начальная фаза заполнения перед началом репликации данных. Например, для одной базы данных размером 100 ГБ начальная фаза загрузки займет около 1,2 часа, если канал связи способен передавать 84 ГБ в час, и если другие базы данных не подвергаются загрузке. Если ссылка может передавать только 10 ГБ в час, то время заполнения базы данных размером 100 ГБ может занять около 10 часов. Если существует несколько баз данных для репликации, заполнение будет выполняться параллельно, и при сочетании со скоростью медленной связи начальная фаза заполнения может занять значительно больше времени, особенно если параллельное заполнение данных из всех баз данных превышает доступную пропускную способность канала.
Внимание
В случае крайне низкой скорости или загруженного канала, что может привести к тому, что начальный этап развертывания займет несколько дней, создание группы отработки отказа может привести к таймауту. Процесс создания будет автоматически отменен через 6 дней.
Управление геоотказоустойчивостью для вторичного экземпляра
Группа переключения при сбое управляет геопереключением при сбое всех баз данных основного управляемого экземпляра. При создании группы каждая база данных в экземпляре будет автоматически геореплицирована в гео-вторичный экземпляр. Нельзя использовать группы отказоустойчивости для инициирования частичной отработки отказа для подмножества баз данных.
Внимание
Если база данных удаляется на первичном управляемом экземпляре, то она также будет автоматически удалена на вторичном управляемом экземпляре с георепликацией.
Используйте слушатель для чтения и записи (основной MI)
Для рабочих нагрузок для чтения и записи используйте в качестве имени сервера <fog-name>.zone_id.database.windows.net. Подключения автоматически направляются к основному. Это имя не меняется после переключения на резервный сервер. Геоотказоустойчивость включает обновление записи DNS, поэтому новые клиентские подключения направляются к новому основному серверу только после обновления кэша DNS клиента. Клиентское приложение сможет повторно подключиться к серверу-источнику, используя тот же сертификат SAN на стороне сервера, поскольку экземпляры первичного и вторичного экземпляра используют общую DNS-зону. Существующие клиентские подключения необходимо завершить, а затем воссоздать, чтобы направить их на новый основной сервер. Прослушиватель чтения и прослушиватель только для чтения не может быть достигнут через общедоступную конечную точку для управляемого экземпляра.
Используйте прослушиватель только для чтения (вторичный MI)
Если у вас есть логически изолированные рабочие нагрузки, предназначенные только для чтения и устойчивые к задержкам данных, вы можете запускать их в дополнительном экземпляре с георепликацией. Чтобы подключиться напрямую к георезервной копии, используйте в качестве имени сервера <fog-name>.secondary.<zone_id>.database.windows.net.
На уровне "Критически важный для бизнеса" Управляемый экземпляр SQL поддерживает использование реплик только для чтения для балансировки рабочих нагрузок запросов только для чтения, используя параметр ApplicationIntent=ReadOnly в строке подключения. После настройки вторичного геореплицированного экземпляра, вы можете использовать эту функцию для подключения к реплике только для чтения в основном расположении или в геореплицированном расположении.
- Для подключения к реплике только для чтения в основной локации используйте
ApplicationIntent=ReadOnlyи<fog-name>.<zone_id>.database.windows.net. - Для подключения к реплике только для чтения во вторичном расположении используйте
ApplicationIntent=ReadOnlyи<fog-name>.secondary.<zone_id>.database.windows.net.
Прослушиватель чтения и прослушиватель только для чтения не может быть достигнут через общедоступную конечную точку для управляемого экземпляра.
Возможное ухудшение производительности после переключения на резерв
Типичное приложение Azure использует несколько служб Azure и состоит из нескольких компонентов. Гео-резервное переключение группы инициируется на основе состояния компонентов Azure SQL. Сбой может не влиять на другие службы Azure в основном регионе, а их компоненты могут быть по-прежнему доступны в этом регионе. После перехода базы данных-источника в дополнительный регион задержка между зависимыми компонентами может увеличиться. Обеспечьте избыточность всех компонентов приложения во вторичном регионе и отработку отказа компонентов приложения вместе с базой данных так, чтобы производительность приложения не пострадала из-за более высокой задержки между регионами.
Возможность потери данных после принудительного переключения
При возникновении сбоя в основном регионе последние транзакции могли не быть реплицированы в георезерв, и, возможно, произойдет потеря данных, если выполнено принудительное переключение на резерв.
Обновление DNS
После запуска отработки отказа DNS обновления прослушивателя чтения и записи произойдут автоматически. Эта операция не приведет к потере данных. Однако процесс смены ролей баз данных в обычных условиях может занять до 5 минут. До завершения некоторые базы данных в новом первичном экземпляре по-прежнему будут доступны только для чтения. Если аварийное переключение запускается с помощью PowerShell, операция переключения роли первичной реплики выполняется синхронно. Если он инициируется с помощью портал Azure, пользовательский интерфейс указывает состояние завершения. Если он инициируется с помощью REST API, используйте стандартный механизм опроса Azure Resource Manager для отслеживания завершения.
Внимание
Используйте запланированное вручное переключение, чтобы переместить первичный сервер обратно в исходное расположение после устранения сбоя, который вызвал геопереключение.
Экономия затрат с помощью реплики аварийного восстановления без лицензии
Вы можете сэкономить на затратах на лицензию SQL Server, настроив дополнительный управляемый экземпляр, который будет использоваться только для аварийного восстановления (DR). Сведения о настройке см. статью Настройка резервной реплики без лицензии для управляемого экземпляра SQL Azure.
Если вторичный экземпляр не используется для рабочих нагрузок чтения, корпорация Майкрософт предоставляет бесплатное количество виртуальных ядер, соответствующее основному экземпляру. За вычислительные ресурсы и хранилище, используемые вторичным экземпляром, плата по-прежнему взимается. Группы отработки отказа поддерживают только одну реплику. Реплика должна быть репликой, доступной для чтения, или назначена в качестве реплики только для аварийного восстановления.
Включение сценариев, зависящих от объектов из системных баз данных
Системные базы данных не реплицируются на дополнительный экземпляр в группе переключения при отказе. Для реализации сценариев, которые зависят от объектов из системных баз данных, убедитесь, что на дополнительном экземпляре созданы те же объекты и они синхронизированы с первичным экземпляром.
Например, если вы планируете использовать одни и те же имена входа на вторичном экземпляре, обязательно создайте их с одинаковым идентификатором безопасности.
-- Code to create login on the secondary instance
CREATE LOGIN foo WITH PASSWORD = '<enterStrongPasswordHere>', SID = <login_sid>;
Дополнительные сведения см. в статье Репликация имен входа и заданий агента.
Синхронизация свойств экземпляра и политик хранения
Экземпляры в группе аварийного переключения остаются отдельными ресурсами Azure, и изменения, внесенные в конфигурацию первичного экземпляра, не будут автоматически реплицированы на дополнительный экземпляр. Обязательно выполните все соответствующие изменения как на первичном, так и на дополнительном экземпляре. Например, изменяя избыточность хранилища резервных копий или политики долгосрочного хранения резервных копий для первичного экземпляра, не забудьте также изменить ее для дополнительного экземпляра.
Масштабирование экземпляров
Вы можете увеличить или уменьшить первичный и вторичный экземпляры до другого размера вычислительных мощностей в рамках одного уровня обслуживания или до уровня другой службы. При масштабировании на одном уровне служб рекомендуется сначала масштабировать гео-резервную базу данных, а затем основную. При уменьшении масштаба в пределах одного уровня услуг обратите порядок: сперва выполните масштабирование основного узла, а затем вторичного узла. Когда вы изменяете масштаб экземпляра на другой уровень служб, эта рекомендация применяется автоматически. Последовательность операций применяется при масштабировании уровня служб и виртуальных ядер, а также хранилища.
Рекомендуется использовать именно эту последовательность, чтобы избежать проблемы, когда гео-вторичный экземпляр с уровнем SKU более низкого уровня перегружается и требует повторной начальной загрузки при обновлении или понижении.
Внимание
- Например, в группе отработки отказа изменение уровня служб на другой или из этого уровня общего назначения не поддерживается. Сначала необходимо удалить группу отработки отказа перед изменением любой реплики, а затем повторно создать группу отработки отказа после того, как изменение вступает в силу.
- Существует известная проблема, которая может повлиять на доступность экземпляра, масштабируемого с помощью связанного прослушивателя группы отработки отказа.
Предотвращение потери критически важных данных
Из-за высокой задержки в глобальных сетях георепликация использует механизм асинхронной репликации. Асинхронная репликация делает неизбежной возможность потери данных при отказе первичной реплики. Чтобы защитить эти критические транзакции от потери данных, разработчик приложения может вызвать хранимую процедуру sp_wait_for_database_copy_sync сразу же после фиксации транзакции. Вызов sp_wait_for_database_copy_sync блокирует вызывающий поток до тех пор, пока последняя зафиксированная транзакция не будет передана и зафиксирована в журнале транзакций вторичной базы данных. Однако он не ожидает повторного выполнения передаваемых транзакций на вторичной системе.
sp_wait_for_database_copy_sync ограничен на определенную георепликационную связь. Эту процедуру может вызвать любой пользователь с правами подключения к базе данных-источнику.
Чтобы предотвратить потерю данных во время инициированного пользователем планового геоотказа, репликация автоматически и временно переключается на синхронную репликацию, а затем выполняет отказоустойчивость. Затем репликация переходит обратно в асинхронный режим после завершения геоотказа.
Примечание.
sp_wait_for_database_copy_sync предотвращает потерю данных после георезервирования для конкретных транзакций, но не гарантирует полную синхронизацию для чтения. Вызванная вызовом процедуры sp_wait_for_database_copy_sync задержка может быть продолжительной и зависит от размера еще не переданного журнала транзакций базы данных-источника во время вызова.
Состояние группы отработки отказа
Группа аварийного переключения сообщает о своем состоянии, описывая текущее состояние репликации данных.
- Начальная посадка — начальная посадка выполняется после создания отказоустойчивой группы до тех пор, пока не будут инициализированы все пользовательские базы данных на вторичном экземпляре. Процесс отказоустойчивости не может быть инициирован, пока группа находится в состоянии наполнения, поскольку пользовательские базы данных еще не копируются во вторичный экземпляр.
- Синхронизация — это обычное состояние группы аварийного переключения. Оно означает, что изменения данных на первичном экземпляре асинхронно реплицируются на дополнительный экземпляр. Это состояние не гарантирует, что данные полностью синхронизированы в каждый момент времени. Могут возникнуть изменения данных из основного, которые ещё предстоит реплицировать на вторичный из-за асинхронной природы процесса репликации между экземплярами в группе обеспечения отказоустойчивости. Автоматическое и вручную инициированное переключение при отказе можно начинать, пока группа переключения при отказе находится в состоянии синхронизации.
- Происходит переключение на резерв — этот статус указывает, что автоматический или вручную инициированный процесс переключения на резерв в процессе выполнения. Изменения в группе переключения отказа или дополнительные переключения отказа не могут быть запущены, пока группа переключения отказа находится в этом состоянии.
Возврат к исходной системе
При настройке групп отработки отказа с помощью политики отработки отказа под управлением Microsoft, принудительный переход на георезервный сервер инициируется во время аварийной ситуации в соответствии с определенным льготным периодом. Возврат к старой основной среде должен быть инициирован вручную.
Взаимосовместимость функций
Резервные копии
Полная резервная копия выполняется в следующих сценариях:
- Перед началом начального заполнения при создании группы аварийного переключения.
- После переключения при отказе.
Полная резервная копия — это размер операции с данными, которая не может быть пропущена или отложена, и может занять некоторое время. Время выполнения зависит от размера данных, количества баз данных и интенсивности рабочей нагрузки в базах данных-источниках. Полная резервная копия может заметно задержать начальное заполнение, а также может отложить или предотвратить резервное переключение на новой инстансе вскоре после отказа.
Служба воспроизведения журналов
Базы данных, перенесенные в Управляемый экземпляр SQL Azure с помощью службы воспроизведения журналов (LRS), не могут быть добавлены в группу отработки отказа, пока не будет выполнен переходный шаг. База данных, мигрированная с LRS, находится в состоянии восстановления до завершения перехода, и базы данных в состоянии восстановления не могут быть добавлены в группу аварийного переключения. Попытка создать группу отработки отказа с базой данных в состоянии восстановления задерживает ее создание до завершения восстановления базы данных.
Репликация транзакций
Использование репликации транзакций с экземплярами, находящимися в группе автоматического переключения, поддерживается. Однако при настройке репликации перед добавлением управляемого экземпляра SQL в группу отказоустойчивости, репликация приостанавливается, когда вы начинаете создавать группу отказоустойчивости, и монитор репликации показывает состояние Replicated transactions are waiting for the next log backup or for mirroring partner to catch up. Репликация возобновляется после успешного создания группы переключения при отказе.
Если управляемый экземпляр SQL издателя или распространителя находится в группе аварийного переключения, администратор управляемого экземпляра SQL должен удалить все публикации на старом основном сервере и перенастроить их на новом основном сервере после завершения аварийного переключения. Ознакомьтесь с руководством по репликации транзакций для шага действий, необходимых в этом сценарии.
Разрешения и ограничения
Просмотрите список разрешений и ограничений перед настройкой группы автоматического переключения.
Программное управление группами резервного копирования
Группами отработки отказа можно управлять также программно с использованием Azure PowerShell, Azure CLI и REST API. Изучите настройку группы отработки отказа, чтобы узнать больше.
Тренировки по устранению последствий аварии
Рекомендуемый способ проведения учений по аварийному восстановлению — использовать ручную плановую отработку отказа, как показано в следующем руководстве: Тестовая отработка отказа.
Выполнение проверки с использованием принудительного переключения не рекомендуется, так как эта операция не гарантирует защиту от потери данных. Тем не менее, можно достичь принудительной отработки отказа без потерь данных при условии выполнения следующих условий до её начала:
- Рабочая нагрузка останавливается на основном управляемом экземпляре.
- Все транзакции, длительно выполнявшиеся, завершены.
- Все клиентские подключения к основному управляемому экземпляру были отключены.
- Состояние группы переключения — "Синхронизация".
Убедитесь, что два управляемых экземпляра сменили роли и что состояние группы отработки отказа изменилось с "Отработка отказа выполняется" на "Синхронизация", прежде чем, если потребуется, устанавливать соединения с новым ведущим управляемым экземпляром и начинать рабочую нагрузку чтения и записи.
Чтобы выполнить восстановление без потери данных к исходным ролям управляемого экземпляра, настоятельно рекомендуется использовать вручную запланированную отработку отказа вместо принудительной отработки отказа. Если используется принудительный возврат на исходное состояние:
- Выполните те же действия, что и для резервирования без потери данных.
- Ожидается более длительное время выполнения возврата, если принудительный возврат выполняется вскоре после завершения первоначального принудительного переключения на резерв, так как ему необходимо дождаться завершения невыполненных автоматических операций резервного копирования на бывшем основном управляемом экземпляре.
- Любые невыполненные операции автоматического резервного копирования в управляемом экземпляре, переходящем с первичной на вторичную роль, будут влиять на доступность базы данных этого экземпляра.
- Пожалуйста, используйте статус группы резервного копирования, чтобы определить, изменили ли оба экземпляра свои роли и готовы принять подключения клиентов.
Связанный контент
- Настройка группы отказоустойчивости
- Использование PowerShell для добавления управляемого экземпляра в группу аварийного переключения
- Настройка резервной реплики, не требующей лицензии, для Управляемого экземпляра SQL Azure
- Общие сведения об обеспечении непрерывности бизнес-процессов с помощью Управляемого экземпляра Azure SQL
- Автоматическое резервное копирование в Управляемый экземпляр SQL Azure
- Восстановление базы данных из резервной копии на управляемом экземпляре SQL Azure