Использование DISKSPD для тестирования производительности хранилища рабочей нагрузки
Область применения: Azure Stack HCI, версии 22H2 и 21H2; Windows Server 2022, Windows Server 2019
Внимание
Azure Stack HCI теперь является частью Azure Local. Выполняется переименование документации по продукту. Однако старые версии Azure Stack HCI, например 22H2, будут продолжать ссылаться на Azure Stack HCI и не отражают изменение имени. Подробнее.
В этом разделе содержатся рекомендации по использованию DISKSPD для тестирования производительности хранилища рабочей нагрузки. Кластер Azure Stack HCI настроен и готов к работе. Отлично, однако как узнать, будете ли вы получать обещанные метрики производительности, будь то задержка, пропускная способность или операции ввода-вывода в секунду? Именно сейчас можно обратиться к DISKSPD. После чтения этой статьи вы узнаете, как запустить DISKSPD, понять подмножество параметров, интерпретировать выходные данные и получить общее представление о переменных, влияющих на производительность хранилища рабочей нагрузки.
Что такое DISKSPD?
DISKSPD — это средство создания ввода-вывода, средства командной строки для микро-тестирования. Здорово, так что все эти термины означают? Любой пользователь, который настраивает кластер Azure Stack HCI или физический сервер, имеет причину. Это может быть настройка среды веб-размещения или запуск виртуальных рабочих столов для сотрудников. Независимо от того, какой вариант использования в реальном мире может быть, вы, вероятно, хотите имитировать тест перед развертыванием фактического приложения. Однако тестирование приложения в реальном сценарии зачастую сложно. Это место, в котором поставляется DISKSPD.
DISKSPD — это средство, которое можно настроить для создания собственных синтетических рабочих нагрузок и тестирования приложения перед развертыванием. Прохладная вещь о средстве заключается в том, что она дает возможность настраивать и настраивать параметры для создания определенного сценария, который напоминает реальную рабочую нагрузку. DISKSPD может дать вам представление о том, что ваша система способна перед развертыванием. В основном DISKSPD просто выдает кучу операций чтения и записи.
Теперь вы знаете, что такое DISKSPD, но когда его следует использовать? DISKSPD имеет сложное время эмулирования сложных рабочих нагрузок. Но DISKSPD отлично подходит, если рабочая нагрузка не приблизилась к одной потоковой копии файла, и вам потребуется простое средство, которое создает приемлемые базовые результаты.
Краткое руководство. Установка и запуск DISKSPD
Чтобы установить и запустить DISKSPD, откройте PowerShell в качестве администратора на компьютере управления, а затем выполните следующие действия.
Чтобы скачать и развернуть ZIP-файл для средства DISKSPD, выполните следующие команды:
# Define the ZIP URL and the full path to save the file, including the filename $zipName = "DiskSpd.zip" $zipPath = "C:\DISKSPD" $zipFullName = Join-Path $zipPath $zipName $zipUrl = "https://github.com/microsoft/diskspd/releases/latest/download/" +$zipName # Ensure the target directory exists, if not then create if (-Not (Test-Path $zipPath)) { New-Item -Path $zipPath -ItemType Directory | Out-Null } # Download and expand the ZIP file Invoke-RestMethod -Uri $zipUrl -OutFile $zipFullName Expand-Archive -Path $zipFullName -DestinationPath $zipPathЧтобы добавить каталог DISKSPD в
$PATHпеременную среды, выполните следующую команду:$diskspdPath = Join-Path $zipPath $env:PROCESSOR_ARCHITECTURE if ($env:path -split ';' -notcontains $diskspdPath) { $env:path += ";" + $diskspdPath }Запустите DISKSPD с помощью следующей команды PowerShell. Замените квадратные скобки соответствующими параметрами.
diskspd [INSERT_SET_OF_PARAMETERS] [INSERT_CSV_PATH_FOR_TEST_FILE] > [INSERT_OUTPUT_FILE.txt]Ниже приведен пример команды, которую можно выполнить:
diskspd -t2 -o32 -b4k -r4k -w0 -d120 -Sh -D -L -c5G C:\ClusterStorage\test01\targetfile\IO.dat > test01.txtПримечание.
Если у вас нет тестового файла, используйте параметр -c для создания файла. Если этот параметр используется, обязательно укажите имя тестового файла при определении пути. Например: [INSERT_CSV_PATH_FOR_TEST_FILE] = C:\ClusterStorage\CSV01\IO.dat. В примере команды IO.dat имя тестового файла, а test01.txt — имя выходного файла DISKSPD.
Указание ключевых параметров
Ну, это было просто правильно? К сожалению, это больше, чем это. Распакуем то, что мы сделали. Во-первых, существуют различные параметры, с которыми можно приступить, и он может получить конкретный. Однако мы использовали следующий набор базовых параметров:
Примечание.
Параметры DISKSPD чувствительны к регистру.
-t2: это указывает количество потоков на целевой или тестовый файл. Это число часто основано на количестве ядер ЦП. В этом случае два потока использовались для стресса всех ядер ЦП.
-o32: это указывает количество невыполненных запросов ввода-вывода на целевой объект на поток. Это также называется глубиной очереди, и в этом случае 32 использовались для стресса ЦП.
-b4K: это указывает размер блока в байтах, KiB, MiB или GiB. В этом случае размер блока 4K использовался для имитации случайного теста ввода-вывода.
-r4K: это означает случайный ввод-вывод, выровненный по указанному размеру в байтах, KiB, MiB, Gib или блоках (переопределяет параметр -s ). Общий размер 4K байтов использовался для правильного выравнивания размера блока.
-w0: это указывает процент операций, которые являются запросами на запись (-w0 эквивалентно 100 % чтения). В этом случае для простого теста использовались 0 % записей.
-d120: это указывает длительность теста, не включая прохладу или прогреть. Значение по умолчанию составляет 10 секунд, но рекомендуется использовать не менее 60 секунд для любой серьезной рабочей нагрузки. В этом случае было использовано 120 секунд, чтобы свести к минимуму любые выбросы.
-Suw: отключает кэширование программного обеспечения и оборудования (эквивалентно -Sh).
-D: записывает статистику операций ввода-вывода в секунду, например стандартное отклонение, в интервалах миллисекунда (на поток, на целевой объект).
-L: измеряет статистику задержки.
-c5g: задает размер файла образца, используемого в тесте. Его можно задать в байтах, КиБ, МиБ, ГиБ или блоках. В этом случае использовался целевой файл размером 5 ГБ.
Полный список параметров см. в репозитории GitHub.
Общие сведения о среде
Производительность сильно зависит от среды. Итак, что такое наша среда? Наша спецификация включает кластер Azure Stack HCI с пулом носителей и Локальные дисковые пространства (S2D). В частности, существует пять виртуальных машин: DC, node1, node2, node3 и узел управления. Сам кластер представляет собой трехузловой кластер с трехмерной структурой устойчивости. Таким образом, сохраняются три копии данных. Каждый узел в кластере — это виртуальная машина Standard_B2ms с максимальным ограничением ввода-вывода в секунду 1920. В каждом узле есть четыре диска SSD уровня "Премиум" P30 с максимальным ограничением операций ввода-вывода в секунду 5000. Наконец, каждый ssd-диск имеет 1 ТБ памяти.
Вы создаете тестовый файл в едином пространстве имен, которое предоставляет общий том кластера (CSV) (C:\ClusteredStorage) для использования всего пула дисков.
Примечание.
В примере среды отсутствует Hyper-V или вложенная структура виртуализации.
Как вы видите, можно полностью независимо попасть в потолок операций ввода-вывода в секунду или пропускную способность на виртуальной машине или ограничение диска. И поэтому важно понимать размер виртуальной машины и тип диска, так как оба имеют максимальное ограничение операций ввода-вывода в секунду и потолок пропускной способности. Эти знания помогают найти узкие места и понять результаты производительности. Дополнительные сведения о том, какой размер может быть подходящим для рабочей нагрузки, см. в следующих ресурсах:
Основные сведения о выходных данных
Вооружившись пониманием параметров и среды, вы готовы интерпретировать выходные данные. Во-первых, целью предыдущего теста было максимальное количество операций ввода-вывода в секунду без учета задержки. Таким образом, вы можете визуально увидеть, достигается ли ограничение искусственных операций ввода-вывода в секунду в Azure. Если вы хотите графически визуализировать общее число операций ввода-вывода в секунду, используйте Windows Admin Center или Диспетчер задач.
На следующей схеме показано, как выглядит процесс DISKSPD в нашей примере. В нем показан пример операции записи 1 MiB с узла, отличного от координатора. Трехсторонняя структура устойчивости, а также операция с узла, отличного от координатора, приводит к двум сетевым прыжкам, снижению производительности. Если вы хотите узнать, что такое узел координатора, не беспокойтесь! Вы узнаете об этом в разделе " Вещи" для рассмотрения . Красные квадраты представляют виртуальную машину и узкие места диска.

Теперь, когда у вас есть визуальное представление, давайте рассмотрим четыре основных раздела выходных данных файла .txt:
Входные параметры
В этом разделе описаны выполняемые команды, входные параметры и дополнительные сведения о тестовом выполнении.
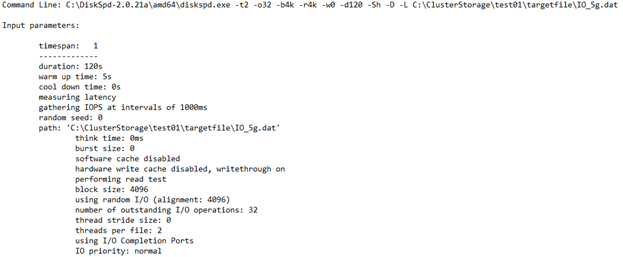
Сведения об использовании ЦП
В этом разделе рассматриваются такие сведения, как время тестирования, количество потоков, количество доступных процессоров и среднее использование каждого ядра ЦП во время теста. В этом случае существует два ядра ЦП, которые в среднем составляли около 4,67 % использования.
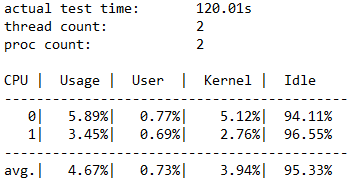
Всего операций ввода-вывода
Этот раздел содержит три подраздела. Первый раздел содержит общие данные о производительности, включая операции чтения и записи. Во втором и третьем разделах операции чтения и записи разделяются на отдельные категории.
В этом примере видно, что общее количество операций ввода-вывода было 234408 в течение 120-секундного периода. Таким образом, операции ввода-вывода в секунду = 234408 /120 = 1953.30. Средняя задержка составила 32,763 миллисекунда, а пропускная способность составила 7,63 МиБ/с. Из предыдущих сведений мы знаем, что 1953.30 операций ввода-вывода в секунду приближается к ограничению 1920 операций ввода-вывода в секунду для нашей виртуальной машины Standard_B2ms. Не верь? При повторном запуске этого теста с помощью различных параметров, таких как увеличение глубины очереди, вы увидите, что результаты по-прежнему ограничены этим числом.
Последние три столбца показывают стандартное отклонение операций ввода-вывода в секунду в 17,72 (от параметра -D), стандартное отклонение задержки в 20,994 миллисекундах (из параметра -L) и пути к файлу.

Из результатов можно быстро определить, что конфигурация кластера ужасна. Вы можете увидеть, что он попал в ограничение виртуальной машины 1920 до ограничения SSD 5000. Если вы были ограничены SSD, а не виртуальной машиной, вы могли бы воспользоваться преимуществами до 20000 операций ввода-вывода в секунду (4 диска * 5000), охватывая тестовый файл на нескольких дисках.
В конечном итоге необходимо решить, какие значения допустимы для конкретной рабочей нагрузки. На следующем рисунке показаны некоторые важные отношения, которые помогут вам рассмотреть компромиссы:
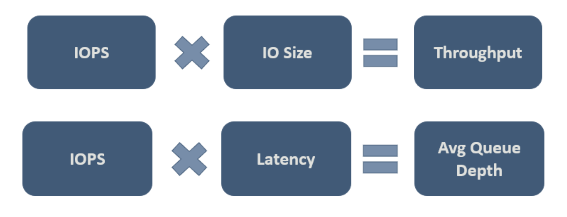
Вторая связь на рисунке важна, и иногда это называется "Маленький закон". Закон вводит идею о том, что существует три характеристики, которые управляют поведением процесса, и что вам нужно только изменить один, чтобы повлиять на остальные два, и таким образом весь процесс. И поэтому, если вы недовольны производительностью вашей системы, у вас есть три измерения свободы влиять на него. Закон Little определяет, что в нашем примере операции ввода-вывода — это "пропускная способность" (входные выходные операции в секунду), задержка — это "время очереди", а глубина очереди — "инвентаризация".
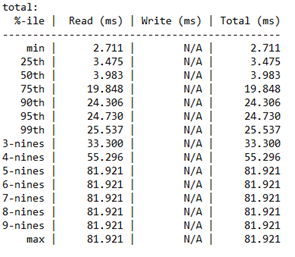
Анализ процентиля задержки
В этом последнем разделе подробно описаны задержки процентиля для каждого типа операции производительности хранилища от минимального значения до максимального значения.
Этот раздел важен, так как определяет качество операций ввода-вывода в секунду. В нем показано, сколько операций ввода-вывода удалось достичь определенного значения задержки. Это до вас, чтобы решить допустимую задержку для этого процентиля.
Кроме того, "девять" относятся к числу девяти. Например, "3-девять" эквивалентен 99-му процентиле. Количество девяти предоставляет количество операций ввода-вывода, выполняемых на этом процентилье. В конечном итоге вы достигнете точки, где больше не имеет смысла принимать значения задержки серьезно. В этом случае можно увидеть, что значения задержки остаются постоянными после "4-девять". На этом этапе значение задержки основано только на одной операции ввода-вывода из 234408 операций.





Следует учесть
Теперь, когда вы начали использовать DISKSPD, рекомендуется получить результаты реальных тестов. К ним относятся внимательное внимание к заданным параметрам, работоспособности дискового пространства и переменным, владения CSV и разнице между DISKSPD и копированием файлов.
DISKSPD и реальный мир
Искусственный тест DISKSPD дает относительно сопоставимые результаты для реальной рабочей нагрузки. Тем не менее, необходимо обратить пристальное внимание на заданные параметры и их соответствие реальному сценарию. Важно понимать, что искусственные рабочие нагрузки никогда не будут идеально представлять реальную рабочую нагрузку приложения во время развертывания.
Подготовка
Перед выполнением теста DISKSPD рекомендуется выполнить несколько действий. К ним относятся проверка работоспособности дискового пространства, проверка использования ресурсов, чтобы другая программа не вмешивалась в тест и подготавливала диспетчер производительности, если требуется собрать дополнительные данные. Тем не менее, поскольку цель этого раздела заключается в быстром получении запуска DISKSPD, он не учитывает особенности этих действий. Дополнительные сведения см. в статье "Тестирование дисковые пространства производительности с помощью искусственных рабочих нагрузок в Windows Server".
Переменные, влияющие на производительность
Производительность хранилища — это деликатная вещь. Это означает, что существует множество переменных, которые могут повлиять на производительность. И поэтому, скорее всего, вы можете столкнуться с числом, которое не соответствует вашим ожиданиям. Ниже перечислены некоторые переменные, влияющие на производительность, хотя это не полный список:
- Пропускная способность сети
- Выбор устойчивости
- Конфигурация диска хранилища: NVME, SSD, HDD
- Буфер ввода-вывода
- Cache
- Конфигурация RAID
- Сетевые прыжки
- Скорости спинделя жесткого диска
Владение CSV
Узел называется владельцем тома или узлом координатора (узел, отличный от координатора , будет узлом, который не владеет определенным томом). Каждый стандартный том назначается узлу, а другие узлы могут получить доступ к этому стандартному тому через сетевые прыжки, что приводит к снижению производительности (более высокая задержка).
Аналогичным образом общий том кластера (CSV) также имеет "владельца". Однако CSV-файл является динамическим в том смысле, что он будет переходить и изменять владение каждый раз, когда вы перезапускаете систему (RDP). В результате важно убедиться, что DISKSPD выполняется с узла координатора, который владеет CSV-файлом. В противном случае может потребоваться вручную изменить владение CSV.
Чтобы подтвердить владение CSV, выполните приведенные действия.
Проверьте владение, выполнив следующую команду PowerShell:
Get-ClusterSharedVolumeЕсли владение CSV-файлом неправильно (например, вы находитесь на node1, но Node2 владеет CSV), переместите CSV-файл на правильный узел, выполнив следующую команду PowerShell:
Get-ClusterSharedVolume <INSERT_CSV_NAME> | Move-ClusterSharedVolume <INSERT _NODE_NAME>
Копирование файлов и DISKSPD
Некоторые люди считают, что они могут "тестировать производительность хранилища", копируя и вставляя гигантский файл и измеряя, сколько времени занимает этот процесс. Основная причина этого подхода, скорее всего, потому что это просто и быстро. Идея не является неправильной в том смысле, что она проверяет определенную рабочую нагрузку, но трудно классифицировать этот метод как "тестирование производительности хранилища".
Если ваша реальная цель заключается в тестировании производительности копирования файлов, это может быть совершенно допустимой причиной использования этого метода. Однако если ваша цель заключается в измерении производительности хранилища, рекомендуется не использовать этот метод. Процесс копирования файлов можно рассматривать как использование другого набора параметров (например, очереди, параллелизации и т. д.), характерных для файловых служб.
В следующей краткой сводке объясняется, почему использование копирования файлов для измерения производительности хранилища может не предоставлять нужные результаты:
Копии файлов могут быть не оптимизированы, существует два уровня параллелизма, которые происходят, один внутренний и другой внешний. Если копия файла направляется к удаленному целевому объекту, подсистема CopyFileEx применяет некоторую параллелизацию. Внешне существует несколько способов вызова обработчика CopyFileEx. Например, копии из проводник являются одним потоком, но Robocopy является многопоточным. По этим причинам важно понять, являются ли последствия теста тем, что вы ищете.
Каждая копия имеет две стороны. При копировании и вставки файла можно использовать два диска: исходный диск и целевой диск. Если один из них медленнее, чем другой, вы, по сути, измеряете производительность более медленного диска. Существуют и другие случаи, когда обмен данными между источником, назначением и подсистемой копирования может повлиять на производительность уникальным образом.
Дополнительные сведения см. в статье Использование копирования файлов для измерения производительности хранилища.
Эксперименты и распространенные рабочие нагрузки
В этом разделе приведены несколько других примеров, экспериментов и типов рабочих нагрузок.
Подтверждение узла координатора
Как упоминалось ранее, если виртуальная машина, которую вы тестируете, не владеет CSV, вы увидите снижение производительности (операции ввода-вывода в секунду, пропускную способность и задержку), а не тестирование, когда узел владеет CSV. Это связано с тем, что при каждом выполнении операции ввода-вывода система выполняет сетевой переход к узлу координатора для выполнения этой операции.
Для трехузловой трехмерной зеркальной ситуации операции записи всегда делают сетевой прыжк, так как он должен хранить данные на всех дисках на трех узлах. Таким образом, операции записи делают сетевой прыжок независимо от того, Однако если вы используете другую структуру устойчивости, это может измениться.
Приведем пример:
- Выполнение на локальном узле: diskspd.exe -t4 -o32 -b4k -r4k -w0 -Sh -D -L -L C:\ClusterStorage\test01\targetfile\IO.dat
- Выполнение на нелокальном узле: diskspd.exe -t4 -o32 -b4k -r4k -w0 -Sh -D -L C:\ClusterStorage\test01\targetfile\IO.dat
В этом примере вы можете четко увидеть в результатах следующего рисунка, что задержка снизилась, количество операций ввода-вывода в секунду и пропускная способность увеличилась, когда узел координатора владеет CSV-файлом.

Рабочая нагрузка "Обработка транзакций в сети" (OLTP)
Запросы рабочих нагрузок для обработки транзакций в Сети (OLTP) (обновление, вставка, удаление) сосредоточены на задачах, ориентированных на транзакцию. По сравнению с оперативной аналитической обработкой (OLAP), OLTP зависит от задержки хранения. Так как каждая операция выдает мало операций ввода-вывода, то, что вы заботитесь о том, сколько операций в секунду вы можете поддерживать.
Вы можете разработать тест рабочей нагрузки OLTP, чтобы сосредоточиться на случайной, небольшой производительности ввода-вывода. Для этих тестов сосредоточьтесь на том, насколько далеко можно отправить пропускную способность при сохранении допустимых задержек.
Базовый вариант разработки для этого теста рабочей нагрузки должен содержать как минимум:
- Размер блока 8 КБ => напоминает размер страницы, который SQL Server использует для своих файлов данных
- 70 % чтение, 30 % Запись => напоминает типичное поведение OLTP
Рабочая нагрузка по оперативной аналитической обработке (OLAP)
Рабочие нагрузки OLAP сосредоточены на извлечении и анализе данных, что позволяет пользователям выполнять сложные запросы для извлечения многомерных данных. В отличие от OLTP, эти рабочие нагрузки не учитывает задержку хранения. Они подчеркивают очередь многих операций, не заботясь о пропускной способности. В результате рабочие нагрузки OLAP часто приводят к более длительной обработке.
Вы можете разработать тест рабочей нагрузки OLAP, чтобы сосредоточиться на последовательной производительности операций ввода-вывода. Для этих тестов сосредоточьтесь на томе данных, обрабатываемых в секунду, а не на количестве операций ввода-вывода в секунду. Требования к задержке также менее важны, но это является субъективным.
Базовый вариант разработки для этого теста рабочей нагрузки должен содержать как минимум:
Размер блока 512 КБ => напоминает размер ввода-вывода, когда SQL Server загружает пакет из 64 страниц данных для сканирования таблицы с помощью метода предварительного чтения.
1 поток на файл => в настоящее время необходимо ограничить тестирование одним потоком на каждый файл, так как проблемы могут возникнуть в DISKSPD при тестировании нескольких последовательных потоков. Если вы используете несколько потоков, например два, и параметр -s , потоки начинаются недетерминированно, чтобы выдавать операции ввода-вывода на вершине друг друга в одном расположении. Это связано с тем, что каждый из них отслеживает собственное последовательное смещение.
Существует два решения для устранения этой проблемы:
Первое решение включает использование параметра -si . При использовании этого параметра оба потока совместно используют одно взаимоблокированное смещение, чтобы потоки совместно выпускали единый последовательный шаблон доступа к целевому файлу. Это позволяет использовать не один пункт в файле более одного раза. Тем не менее, поскольку они по-прежнему гонки друг с другом, чтобы выдать свою операцию ввода-вывода в очередь, операции могут поступать из порядка.
Это решение хорошо работает, если один поток становится ограниченным ЦП. Может потребоваться включить второй поток на втором ядре ЦП, чтобы обеспечить больше операций ввода-вывода хранилища в систему ЦП для дальнейшего его насыщения.
Второе решение включает использование смещения> -T<. Это позволяет указать размер смещения (интервал между операциями ввода-вывода) между операциями ввода-вывода, выполняемыми в одном целевом файле различными потоками. Например, потоки обычно начинаются с смещения 0, но эта спецификация позволяет расстояние между двумя потоками, чтобы они не перекрывались друг с другом. В любой многопоточной среде потоки, скорее всего, будут находиться на разных участках рабочего целевого объекта, и это способ имитации этой ситуации.
Следующие шаги
Дополнительные сведения и подробные примеры оптимизации параметров устойчивости см. также: