Аварийное восстановление и географическое распределение в службе устойчивых функций Azure Durable Functions
Корпорация Майкрософт стремится непрерывно поддерживать доступность служб Azure. Но иногда могут происходить незапланированные сбои служб. Если приложению требуется устойчивость, корпорация Майкрософт рекомендует настроить для приложения геоизбыточность. Кроме того, клиентам следует иметь план аварийного восстановления на случай регионального сбоя служб. Важной частью плана аварийного восстановления является подготовка к экстренному переходу на вторичную реплику приложения в случаях, когда основная реплика становится недоступной.
В службе устойчивых функций Azure все состояния сохраняются в службе хранилища Azure. Центр задач — это логический контейнер для ресурсов службы хранилища Azure, которые используются для оркестрации и сущностей. Функции оркестраторов, действий и сущностей могут взаимодействовать друг с другом, только когда они принадлежат к одному центру задач. Этот документ будет возвращаться к определению центров задач при описании сценариев поддержания высокой доступности ресурсов службы хранилища Azure.
Примечание
В приведенном в этой статье руководстве предполагается, что вы используете поставщик службы хранилища Azure по умолчанию для хранения среды выполнения расширения "Устойчивые функции". Однако можно настроить альтернативные поставщики хранилища, хранящие состояние в другом месте, например, в базе данных SQL Server. Для альтернативных поставщиков хранилища могут потребоваться другие стратегии аварийного восстановления и географического распределения. Дополнительные сведения о альтернативных поставщиках хранилища см. в документации по поставщикам хранилища службы "Устойчивые функции".
Оркестрации и сущности можно активировать с помощью клиентских функций, которые сами по себе активируются по протоколу HTTP или одной из других поддерживаемых типов триггеров функций Azure. Их также можно активировать с помощью встроенных API HTTP. Для простоты понимания в этой статье основное внимание будет уделяться сценариям, связанным с хранилищем Azure и триггерами функций на основе HTTP, а также настройкам для повышения доступности и уменьшения времени простоя во время аварийного восстановления. Другие типы триггеров, такие как служебная шина или триггеры Azure Cosmos DB, не будут явно охвачены.
Важно заметить, что эти сценарии основаны на конфигурации "активный — пассивный", так как они ориентированы на использование службы хранилища Azure. В этом шаблоне выполняется развертывание резервной копии (пассивного) приложения-функции в другой регион. Диспетчер трафика будет отслеживать доступность основного (активного) приложения-функции для HTTP. Если основное приложение выйдет из строя, будет выполнена отработка отказа в резервную копию приложения-функции. Дополнительные сведения см. в разделе Метод маршрутизации трафика по приоритету в Диспетчере трафика Azure.
Примечание
- Предложенная конфигурация "активный — пассивный" гарантирует, что у клиента всегда будет возможность активировать новую оркестрацию через протокол HTTP. Тем не менее в результате наличия двух приложений-функций в одном хранилище центра задач фоновая обработка будет распределена между ними. Эта конфигурация возлагает дополнительные затраты на исходящий трафик для дополнительного приложения.
- Основная учетная запись хранения и центр задач создаются в основном регионе и совместно используются обоими приложениями-функциями.
- Все приложения-функции, которые развертываются избыточно, должны совместно использовать одинаковые ключи доступа к функции в случае активации через HTTP. Среда выполнения функций предоставляет API управления, который позволяет потребителям программно добавлять, удалять и обновлять ключи функций. Управление ключами также возможно с помощью API службы Azure Resource Manager.
Сценарий 1. Распределение нагрузки вычислений при использовании общего хранилища
Если в Azure происходит сбой инфраструктуры вычисления, приложение-функция может стать недоступным. Чтобы свести к минимуму вероятность такого простоя, в этом сценарии используются два приложения-функции, развернутые в разных регионах. Диспетчер трафика настроен обнаруживать проблемы в основном приложении-функции и автоматически перенаправлять трафик в приложение-функцию во вторичном регионе. Приложения-функции совместно используют одну учетную запись службы хранилища Azure и центр задач. Таким образом состояние приложений-функций не будет потеряно и работу можно возобновить в обычном режиме. Когда работоспособность в основном регионе восстанавливается, диспетчер траффика Azure автоматически направляет запросы к этому приложению-функции.
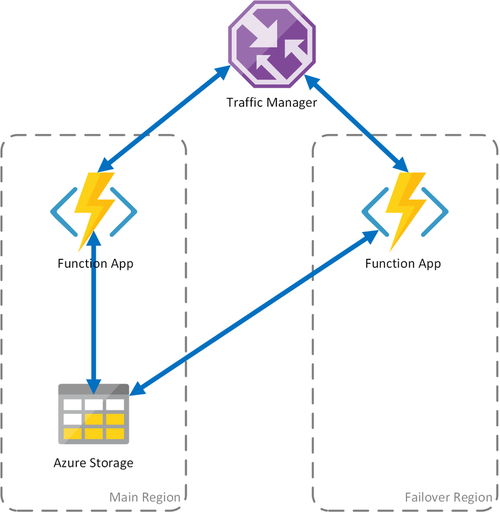
Этот сценарий развертывания обладает несколькими преимуществами:
- Если происходит сбой вычислительной инфраструктуры, работу можно возобновить в регионе отработки отказа без потери состояния.
- Диспетчер трафика выполняет отработку отказа в работоспособное приложение-функцию автоматически.
- Диспетчер трафика автоматически настраивает направление трафика к основному приложению-функции после устранения сбоя.
Тем не менее, при использовании этого сценария учтите следующее:
- Если приложение-функция развертывается с помощью выделенного плана службы приложений, репликация инфраструктуры вычислений в центр обработки данных для отработки отказа увеличит затраты.
- Этот сценарий охватывает сбои в инфраструктуре вычислений, но учетная запись хранилища остается единственной точкой отказа для приложения-функции. При остановке доступа к хранилищу в приложении будет происходить простой.
- При отработке отказа приложения-функции будет увеличена задержка, так как оно будет получать доступ к своей учетной записи хранилища между регионами.
- Доступ приложения к службе хранения не из того региона, в котором он находится, влечет за собой более высокие затраты из-за исходящего трафика.
- Этот сценарий зависит от диспетчера трафика. Учитывая, как работает диспетчер трафика, может потребоваться некоторое время, прежде чем клиентскому приложению, которое потребляет устойчивые функции, снова потребуется запрашивать адрес приложения-функции из диспетчера трафика.
Примечание
Начиная с версии v 2.3.0 расширения службы Устойчивых функций, два приложения-функции могут быть безопасно запущены одновременно с одной и той же учетной записью хранения и конфигурацией центра задач. Первое запущенное приложение получит аренду BLOB-объектов на уровне приложения, которая не позволит другим приложениям украсть сообщения из очередей центра задач. Если первое приложение прекращает работу, срок аренды истекает и аренда может быть получена вторым приложением, которое затем продолжит обрабатывать сообщения центра задач.
До версии 2.3.0 приложения-функции, настроенные для использования одной и той же учетной записи хранения, обрабатывали сообщения и обновляли артефакты хранилища параллельно, что приводило к значительному увеличению задержек и исходящих расходов. Если в первичном приложении и в репликах приложения когда-либо был развернут другой код, даже временно, оркестрации не смогут быть выполнены правильно из-за несогласованности функций оркестрации в двух приложениях. Поэтому рекомендуется, чтобы все приложения, для которых требуется географическое распределение в целях аварийного восстановления, использовали версию расширения 2.3.0 или выше.
Сценарий 2. Распределение нагрузки вычислений при использовании регионального хранилища
В предыдущем сценарии рассматриваются только случаи сбоя в инфраструктуре вычислений. Если происходит сбой службы хранилища, это приведет к сбою приложения-функции. Для обеспечения непрерывной работы устойчивых функций в этом сценарии используется локальная учетная запись хранения для каждого региона, в котором развернуто приложение-функция.
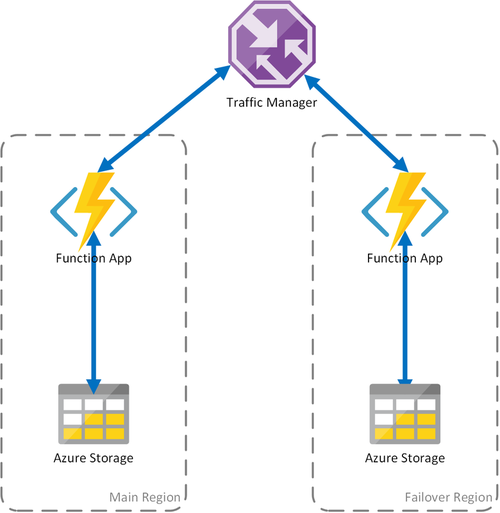
Этот подход добавляет улучшения в предыдущий сценарий:
- При сбое приложения-функции диспетчер трафика выполняет отработку отказа в дополнительный регион. Тем не менее, так как приложение-функция использует собственную учетную запись хранения, устойчивые функции будут продолжать работать.
- Во время отработки отказа отсутствует дополнительная задержка в регионе, куда выполняется отработка отказа, так как приложение-функция и учетная запись хранения находятся в одном расположении.
- Сбой уровня хранилища приведет к сбоям в устойчивых функциях, что, в свою очередь, активирует перенаправление в регион отработки отказа. Опять же, так как приложение-функция и хранилище изолированы в регионе, устойчивые функции будут продолжать работать.
Что следует учитывать при работе с данным сценарием:
- Если приложение-функция развертывается с помощью выделенного плана службы приложений, репликация инфраструктуры вычислений в центр обработки данных для отработки отказа увеличит затраты.
- Текущее состояние не выполняет отработку отказа. Это означает, что существующие оркестрации и сущности будут приостановлены и недоступны до восстановления основного региона.
Подводя итог, компромисс между первым и вторым сценариями заключается в том, что задержка сохраняется и затраты на исходящий трафик сведены к минимуму, но существующие оркестрации и сущности будут недоступны во время простоя. Приемлемость этих компромиссов зависит от требований приложения.
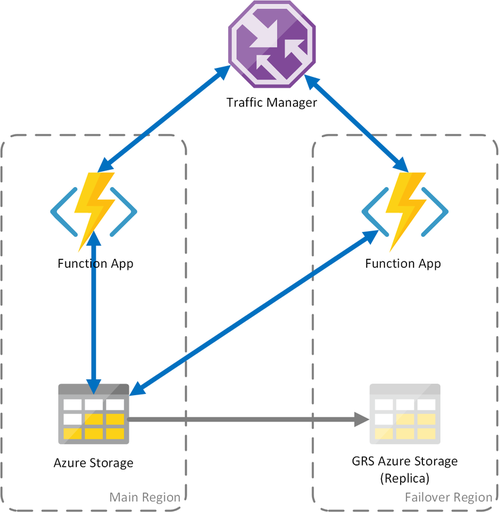
Сценарий 3. Распределение нагрузки вычислений при использовании общего хранилища GRS
Этот сценарий является модификацией первого сценария, использующего общую учетную запись хранения. Основное отличие заключается в том, что учетная запись хранения создается с включенной георепликацией. С функциональной точки зрения этот сценарий предоставляет те же преимущества, что и сценарий 1, но он обеспечивает дополнительные преимущества восстановления данных:
- Геоизбыточное хранилище (GRS) и геоизбыточное хранилище с доступом на чтение (RA-GRS) максимально увеличивают доступность учетной записи хранения.
- При наличии регионального сбоя службы хранилища можно вручную запустить отработку отказа на вторичную реплику. В экстренных ситуациях, когда значительная авария приводит к неработоспособности целого региона, корпорация Майкрософт может инициировать отработку отказа между регионами. В этом случае вам не нужно предпринимать какие-либо действия.
- В этом случае состояние устойчивых функций будет сохранено на момент последней репликации учетной записи хранения, которая происходит каждые несколько минут.
Как и в других сценариях, есть важные сведения, которые нужно учитывать:
- Отработка отказа в реплику может занять некоторое время. До завершения отработки отказа и обновления записей DNS службы хранилища Azure приложение-функция будет испытывать отключение.
- За использование учетных записей хранения с географической репликацией взимается увеличенная плата.
- GRS репликация копирует данные асинхронно. Некоторые последние транзакции могут быть потерны из-за задержки процесса репликации.
Примечание
Как описано в сценарии 1, настоятельно рекомендуется, чтобы приложения-функции, развертываемые с этой стратегией, использовали версию 2.3.0 расширения устойчивых функций или более позднюю.
Дополнительные сведения см. в документации Аварийное восстановление и отработка отказа учетной записи хранения службы хранилища Azure.